虚拟桌面呈现设备中的2D显示加速方法与流程
本发明涉及一种虚拟桌面技术,尤其是涉及一种虚拟桌面呈现设备中的2D显示加速方法。
背景技术:
目前的虚拟桌面的客户端设备中的2D图像渲染主要是利用纯软件方法完成。即将从服务器端接收的经无损压缩后的2D图像流一帧一帧的传输到客户端,在客户端软件解压后直接渲染到屏幕上。该方式渲染速度缓慢,且占用大量的内存带宽,对整体性能拖累较大,给用户最直观的感受便是视频播放等高帧率场景下很不流畅。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种虚拟桌面呈现设备中的2D显示加速方法。
本发明的目的可以通过以下技术方案来实现:
一种虚拟桌面呈现设备中的2D显示加速方法,包括:
S1:确定2D图像的一个或多个最小矩形包络,并对所有矩形包络中的图像数据进行压缩;
S2:将压缩后的图像数据,以及对应矩形包络的尺寸和位置发送至客户端;
S3:客户端对压缩后的图像数据进行解压,并由GPU根据解压后的图像数据以及对应矩形包络的尺寸和位置对所述2D图像进行渲染。
所述步骤S1具体包括步骤:
S11:确定2D图像中的所有图像变更区域;
S12:基于图像变更区域确定一个或多个矩形包络,使得所有矩形包络的总面积最小。
所述步骤S3具体包括步骤:
S31:客户端接收压缩后的图像数据后,由CPU对其进行解压,并将解压后的数据存放于系统内存中;
S32:DMA控制器控制系统内存中存放的解压后的图像数据,以及对应矩形包络的尺寸和位置传输至GPU中;
S33:GPU根据解压后的图像数据以及对应矩形包络的尺寸和位置对所述2D图像进行渲染。
所述步骤S32的过程中,DMA控制器接管系统总线的控制权。
所述步骤S32的过程中,DMA控制器和CPU交替访问系统内存。
所述系统内存为物理内存和/或虚拟内存。
矩形包络的尺寸为长宽。
矩形包络的位置为坐标。
与现有技术相比,本发明具有以下优点:
1)采用差异更新策略,对变更的区域,计算其最小矩形包络,并对这些变更的区域才进行计算,渲染过程由GPU进行,解放了CPU,解决虚拟桌面呈现设备的2D图像渲染性能不足的问题,提高设备在高帧率场景下的流畅度,提升用户体验。
2)数据从内存中到GPU中的过程采用了DMA方式,这种方式可以不需要CPU来执行中转,因此CPU可以处理自己的计算任务,不会被拖累,提高了CPU的效率。
3)采用DMA和CPU交替访问系统内存的方式,CPU既不停止主程序的运行,也不进入等待状态,可以更加高效。
附图说明
图1为本发明方法的主要步骤流程示意图;
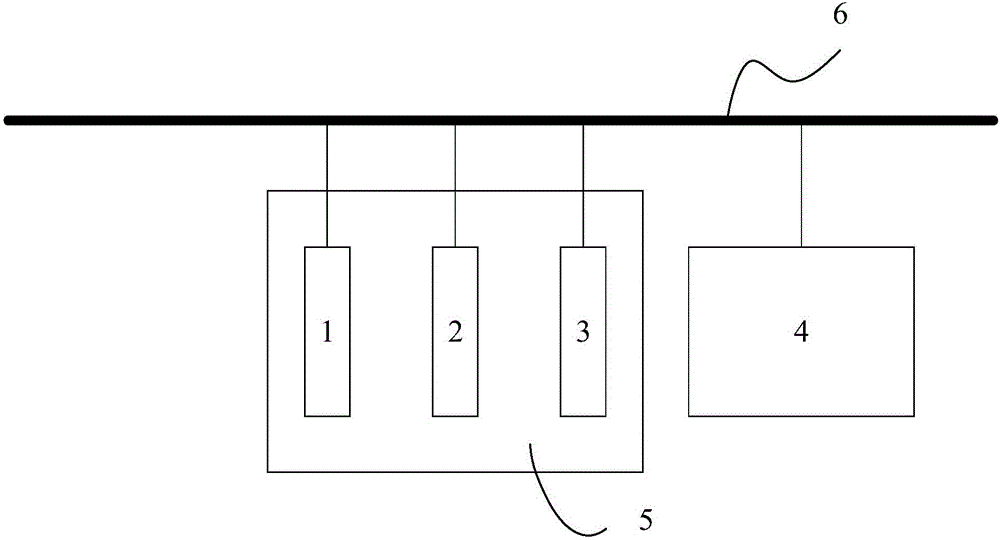
图2为本发明实现系统的组成结构示意图;
其中1、CPU,2、GPU,3、DMA控制器,4、系统内存,5、SoC,6、系统总线。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
为了实现本申请,如图2所示,客户端的SoC 5包含CPU 1、GPU 2以及DMA控制器3,CPU 1、GPU 2以及DMA控制器均与系统总线6连接,此外系统内存4也连接至系统总线6。
一种虚拟桌面呈现设备中的2D显示加速方法,如图1所示,包括:
S1:确定2D图像的一个或多个最小矩形包络,并对所有矩形包络中的图像数据进行压缩,具体包括步骤:
S11:确定2D图像中的所有图像变更区域;
S12:基于图像变更区域确定一个或多个矩形包络,使得所有矩形包络的总面积最小。
最小矩形包络的确定算法不属于本申请的讨论范畴,本领域技术人员可以根据步骤S12中提出的要求自行选择合适的算法。
S2:将压缩后的图像数据,以及对应矩形包络的尺寸和位置发送至客户端,其中矩形包络的尺寸为长宽,位置为坐标;
S3:客户端对压缩后的图像数据进行解压,并由GPU 1根据解压后的图像数据以及对应矩形包络的尺寸和位置对2D图像进行渲染,具体包括步骤:
S31:客户端接收压缩后的图像数据后,由CPU 1对其进行解压,并将解压后的数据存放于系统内存4中,其中,系统内存4为物理内存和/或虚拟内存,具体由操作系统安排控制;
S32:DMA控制器3控制系统内存4中存放的解压后的图像数据,以及对应矩形包络的尺寸和位置传输至GPU 1中,在DMA控制的过程中,DMA控制器3接管系统总线6的控制权,更优的,DMA控制器和CPU 1交替访问系统内存4。
S33:GPU 1根据解压后的图像数据以及对应矩形包络的尺寸和位置对2D图像进行渲染。
本申请主要使用客户端SoC 5内的硬件GPU 2进行2D图形的渲染,该模块会利用DMA的方式直接将2D图像将GPU 2解码完成的数据流输出到客户端虚拟桌面呈现设备上,而不再通过软件方式由CPU 1完成2D图形的解码和渲染。
本申请充分利用客户端设备的GPU硬件加速功能以及DMA控制器的空能来提升2D图形显示速度,将图形数据流由客户端的GPU硬件模块直接渲染,整个过程节省了大量的内存带宽和CPU占用,一方面在计算资源本就紧张的客户端设备上节省下大量的CPU 1计算资源,另一方面也极大地提高了显示速度,硬件拷贝的速度是远快于软件拷贝,实现低成本与高性能的统一。
- 还没有人留言评论。精彩留言会获得点赞!