一种大数据的数据管理系统实现方法与流程
本发明涉及大数据技术领域,具体地说是一种实用性强、大数据的数据管理系统实现方法。
背景技术:
当今已经是数据大爆炸的时代,各个行业面临着大部分的问题:
1、集中管理互联网数据。从无规则、无行业分类的互联网获取到针对性的行业价值的信息。
2、主流的Nutch等很难原生的满足多任务,并且定制采集和加工数据的需求,同时还需要解决大型互联网公司的反爬机制。
3、采集到的互联网数据如何自动收割和语义化存储,并与内部数据做共享与整合。
4、海量数据的存储,快速读写与容灾。
5、集群管理维护难。原有系统没有一个从硬件到软件到服务状态的整体监控和管理系统。
6、数据分享。通过文件方式、数据库等重型方式分享数据。
鉴于此,现提供一种基于大数据的数据管理系统实现方法。
技术实现要素:
本发明的技术任务是针对以上不足之处,提供一种实用性强、大数据的数据管理系统实现方法。
一种大数据的数据管理系统实现方法,其具体实现过程为:
第一步,搭建分布式存储系统,并预留采集系统与该存储系统相连接的接口,让采集后的数据直接存储到该系统里;
第二步,搭建具有MapReduce的分布式计算环境,并部署Nutch爬虫;
第三步,搭建采集系统,并在计算机机器上部署执行节点和收割模块、调度节点、采集适配程序;
第四步,搭建接口系统,该接口系统顺序包括权限认证模块、适配汇总模块、接口程序、数据调度转换模块以及分布式采集库,其中权限认证模块、适配汇总模块、数据调度转换模块分别部署到独立的节点上,接口程序则部署到若干机器上,同时每个机器上的接口程序均对应一内存数据库,该内存数据库的配置文件指向数据调度转换模块。
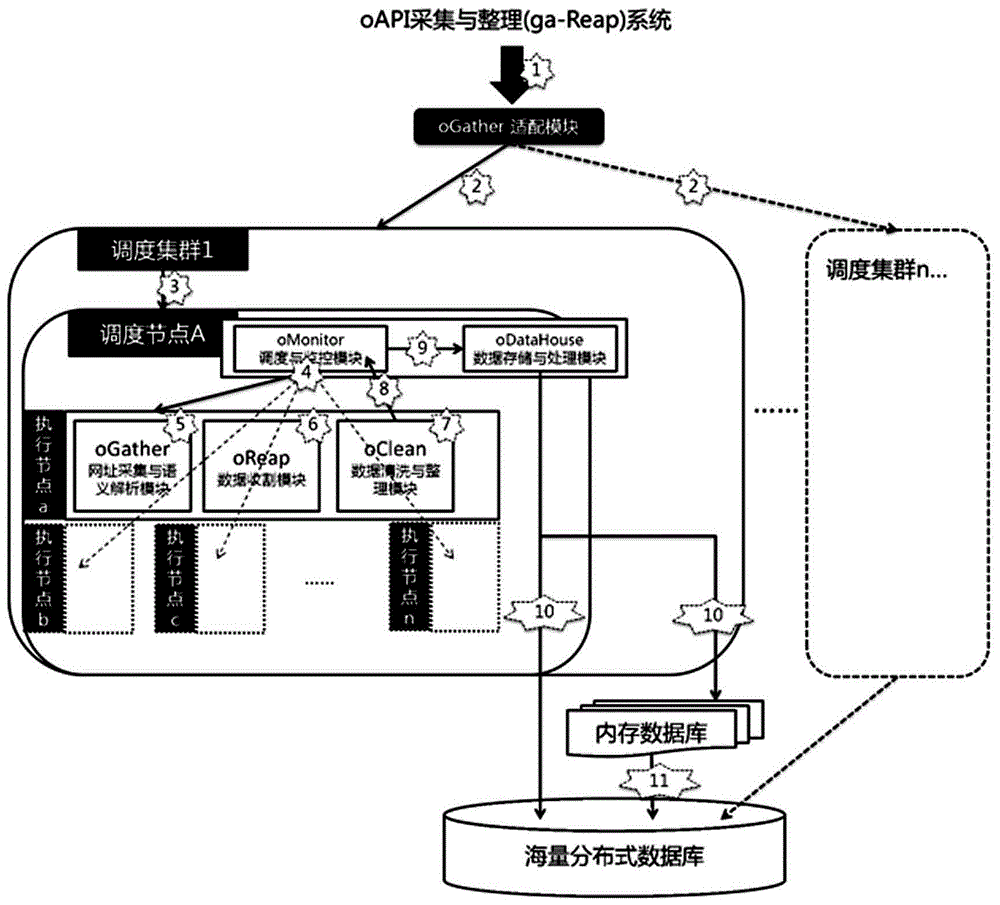
所述采集系统为ga-Reap采集系统,其由主从式数据采集oGather模块、数据异步收割与清洗oReapCln模块组成并部署在执行节点上,负责数据采集、存储、清洗以及整理的过程。
所述接口系统为数据REST接口服务oRest系统,负责将数据分享给用户。
当用户使用该用户管理系统进行数据采集时,首先将需求经过ga-Reap采集系统进行多任务化成为一个任务集合,集合中任意一个任务再按维度细化成子任务,按照主从心跳模式由调度节点分配给执行节点执行采集,对于执行完采集的节点,调度节点主动进行收割,采取分布式存储,并与行业内部组织数据进行整合分析的技术;同时,将采集到的互联网数据通过oRest系统结合权限方式以轻量级方式分享给用户。
数据采集的具体过程为:
步骤1:ga-Reap采集系统根据配置参数,自动匹配行业模板及其采集方法,并回馈给客户以验证是否符合要求;如果不符合,提供给用户自定义数据模型和采集方法,以便a-Reap采集系统按需提供实现数据和内容的交付。
步骤2:确定任务模板,ga-Reap采集系统先接收到这个模板,将模板分解为多个采集任务,并将每个任务分配给调度监控集群;
步骤3:调度节点根据任务进行按维度划分,并负责将各个子任务分配给执行节点,同时监控执行情况,对于异常进行动态迁移到正常执行节点;
步骤4:在执行完成采集以后,执行节点主动心跳状态,ga-Reap采集系统收割模块负责异构收割,对采集数据进行数据预处理,然后收割库归档,以备后续数据分析;
步骤5:第三方用户发送获取数据服务请求时,首先通过权限认证模块进行权限认证,验证是否为合法用户,是否有相应的数据权限;
步骤6:通过适配汇总模块将用户的请求分解并适配到对应主题所在的节点上,在主题节点分为两部分:oRest接口程序和接口依赖的内存库。
步骤7:数据调度转换模块提供内存数据库和分布式数据库的转换和调度。
本发明的一种大数据的数据管理系统实现方法,具有以下优点:
本发明提供的一种大数据的数据管理系统实现方法,基于主从式大数据采集,并以互联网开放接口方式将数据提供给第三方和大众用户的数据管理模式(简称 数据管理),该模式用以填补了市面互联网大数据分享和成果使用的部分短板。解决了互联网非结构数据的采集、采集数据的整理与汇总、以及面向大众的数据开放等难题。通过实现该模式的互联网行业数据采集,让我们看到大众背后的行为;通过叠加政府企业内部组织数据以融合数据,让我们透过数据分析出市场与趋势;通过数据管理的数据开放接口,让大众来分享我们的成果、降低社会协助壁垒,实用性强,适用范围广泛,易于推广。
附图说明
附图1为oRest系统架构图。
附图2为ga-Reap采集系统架构图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
由于各个行业的网站规则不一,用户采集的主题需求不统一等难点,对采集造成了一些困难。因此我们给客户端提供了各个行业的采集模板口径,采集系统和接口服务系统是部署在云服务器上。 如附图1、图2所示,本发明的一种大数据的数据管理系统实现方法,其具体实现过程为:
第一步,搭建分布式存储系统,并预留采集系统与该存储系统相连接的接口,让采集后的数据直接存储到该系统里;
第二步,搭建具有MapReduce的分布式计算环境,并部署Nutch爬虫;
第三步,搭建采集系统,并在计算机机器上部署执行节点和收割模块、调度节点、采集适配程序;
第四步,搭建接口系统,该接口系统顺序包括权限认证模块、适配汇总模块、接口程序、数据调度转换模块以及分布式采集库,其中权限认证模块、适配汇总模块、数据调度转换模块分别部署到独立的节点上,接口程序则部署到若干机器上,同时每个机器上的接口程序均对应一内存数据库,该内存数据库的配置文件指向数据调度转换模块。
所述采集系统为ga-Reap采集系统,其由主从式数据采集oGather模块、数据异步收割与清洗oReapCln模块组成并部署在执行节点上,负责数据采集、存储、清洗以及整理的过程。
所述接口系统为数据REST接口服务oRest系统,负责将数据分享给用户。
当用户使用该用户管理系统进行数据采集时,首先将需求经过ga-Reap采集系统进行多任务化成为一个任务集合,集合中任意一个任务再按维度细化成子任务,按照主从心跳模式由调度节点分配给执行节点执行采集,对于执行完采集的节点,调度节点主动进行收割,采取分布式存储,并与行业内部组织数据进行整合分析的技术;同时,将采集到的互联网数据通过oRest系统结合权限方式以轻量级方式分享给用户。
数据采集的具体过程为:
步骤1:ga-Reap采集系统根据配置参数,自动匹配行业模板及其采集方法,并回馈给客户以验证是否符合要求。如果不符合,提供给用户自定义数据模型和采集方法,以便ga-Reap按需提供实现数据和内容的交付。
步骤2:确定任务模板,ga-Reap采集系统中<适配模块>首先接收到这个模板,将模板分解为多个采集任务(如电商按平台分:天猫、京东),并将每个任务分配给调度监控集群。
步骤3:调度节点根据任务进行按维度划分,并负责将各个子任务分配给执行节点,同时监控执行情况。对于异常进行动态迁移到正常执行节点。调度节点与执行节点依赖MapReduce计算模型。
步骤4:执行节点融合Nutch思路,按独立网址维护采集周期。并纳入ga-Reap语义化采集模块进行采集,该模块可以解决主要反爬宿主的数据采集。
步骤5:在执行完成采集以后,执行节点主动心跳状态,ga-Reap采集系统收割模块负责异构收割。并按照一定的规则进行数据预处理,并进行收割库归档,以备后续数据分析。
步骤6:第三方用户发送获取GoodsAPI的数据服务请求,首先通过oAuth进行权限认证,验证是否为合法用户 ,是否有相应的数据权限。
步骤7:通过oAdapter将用户的请求分解并适配到对应主题所在的节点上,在主题节点分为两部分:oRest接口程序和接口依赖的内存库。
步骤8:oNoSQL提供内存数据库和分布式nosql数据库的转换和调度。
本发明中可以通过结合权限的API接口,做到发布一次到处分享;通过API SDK可以快速进行二次开放定制;可以实现分布式数据采集和处理清洗功能,提供丰富的数据内容。
上述具体实施方式仅是本发明的具体个案,本发明的专利保护范围包括但不限于上述具体实施方式,任何符合本发明的一种大数据的数据管理系统实现方法的权利要求书的且任何所述技术领域的普通技术人员对其所做的适当变化或替换,皆应落入本发明的专利保护范围。
- 还没有人留言评论。精彩留言会获得点赞!