一种基于分布式计算平台改进的k均值聚类方法与流程
本发明涉及一种在机器学习中适用于分布式计算平台Spark改进的k均值聚类方法,属于数据挖掘
技术领域:
。
背景技术:
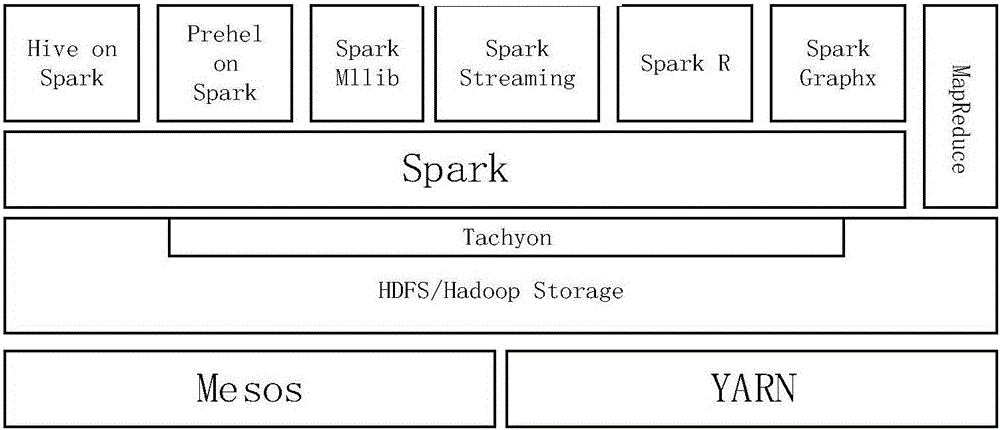
:互联网技术和信息技术的飞速发展导致了信息资源的急剧增长,从而引起严重的信息过载的问题。如何从海量的数据中挖掘出隐含的有用的信息引起人们越来越多的关心,机器学习技术由此产生。聚类分析就是其中相当重要的一部分。它将抽象或者物理的对象的集合组成多个类,使得同一个类的对象之间具有较高的相似度,而不同类的对象之间相似度尽可能的低。在机器学习领域,国内外提出了划分型类聚、密度型类聚、网络型类聚类聚算法。就目前的聚类算法而言还存在如下这些问题:对于初始中心选择敏感,极易陷入局部最优解的问题;对于海量数据和高维数据的处理能力有限的问题等。k均值算法是非常经典的基于划分的聚类算法,由Macqueen在1967年提出的解决聚类问题的经典算法。k均值算法由于其快速简单而被广泛的使用,然而在实际中发现了k均值存在一些问题,如对初始中心敏感,必须给出簇的数目,聚类的结果容易受到噪声的干扰,对海量数据的处理速度,数据的迭代次数多等问题。目前,国内外学者提出一系列对此改的方法,但是这些改进增加了k均值算法的复杂度,增加了数据处理的迭代次数以及对海量数据的处理十分慢。所以本发明提出一种基于分布式计算平台改进的k均值聚类方法来解决上述问题。现有技术一单机版本的通过卡洛斯卡尔算法来对初始中心进行选择后改进的k均值算法。现有技术一的技术方案根据克洛斯卡尔算法对随机选取的k个点求出这k个点的最小生成树权值和,重复n次,然后根据这n次的权值和选取出权值和最大的,最后使用k均值算法进行聚类运算。具体步骤如下:1)从样本中随机选取k个数据向量,对每个数据向量的每一特征进行规范化,使数据向量的每一特征的取值在0~1之间,对这选取的k个数据向量,使用克洛斯卡尔算法,求出最小生成树的权值和,重复这个过程n次,记第i次计算得到的最小生成树权值和为di;2)求出最小生成树权值和中的最大值MAX(d1,d2,...,dn)对应的由k个数据向量组成的点集;3)根据欧式距离公式计算数据向量到k个簇心的距离,根据计算获得k个距离值,取到簇中心距离最小的数据向量放入这个簇心对应的蔟中,然后根据每个簇的所有数据向量求平均值来更新蔟中心,此时,计算上一次k个蔟中心与更新后对应的蔟中心之间的欧式距离,得到k个欧氏距离值,倘若k个欧氏距离值都小于规定的误差阈值或达到迭代次数时,转步骤4),否则继续迭代;4)输出聚类结果。现有技术一的缺点1)对于海量数量和数据向量维度特别的大的时候,单机版本的通过卡洛斯卡尔算法来对初始中心进行选择后改进的k均值算法的处理速度十分的缓慢或者根本无法运行。2)选择初始中心以后进行k均值运算时,没有考虑每个数据向量之间的相似度,直接使用欧氏距离来计算到每个簇心的距离来判定每个数据向量所属的簇,这样会导致实际的误差平方函数的数值增大。现有技术二分布式平台Spark自带的k均值++算法现有技术二的技术方案主要目的是尽量保证初始聚类中心点互相之间距离尽可能的远,具体步骤如下:1)从数据向量集合中随机选一个向量作为聚类的第一个中心点。2)对于数据向量集合中每个向量v,然后计算它与刚选择得到聚类的中心点之间的距离记为D(v)。3)从中选一个新的数据向量作为下一个聚类的中心点,选择准则是:D(v)值越大的点,有更大的概率被选为为聚类的中心点。4)重复步骤2),步骤3)直到k个聚类的中心点都被选出来为止。5)这k个聚类中心点作为聚类的初始中心点来运行k均值算法。现有技术二的缺点由于k均值++没有很好的选择初始中心,没有很好的解决随机选择初始中心带来的迭代次数过多的问题。技术实现要素:发明目的:针对现有技术中存在的问题与不足,本发明提供一种基于分布式计算平台改进的k均值聚类方法。针对现有技术一对海量数据和维数特别大的数据集处理速度慢或者根本无法运算的问题,本发明使用分布式计算平台Spark,可以通过搭建Spark集群来并行化运算,可以大大提高处理速度。针对现有技术一选取最小生成树和中的最大值而没有保证簇心相对均匀分布的问题,本发明提出,如果所选簇心点集中各点之间距离不能保证相差不大,这里需要设置一个阈值,则移除这个簇心点集,从剩下的那些点集中选择最小生成树权值和最大值的对应的点集作为簇心点集,判断此时簇心点集中各点之间距离是否保证相差不大,重复上述过程,这样可以有效地减少迭代次数。针对现有技术一没有考虑每个数据向量之间相关性问题,本发明引入谷本距离来进行计算每个数据向量到簇心的距离来判定每个数据向量应该属于哪个簇,这样选择的k个初始聚类中心可以减少误差平方函数的值,从而可以提高算法的正确率。针对现有技术二一次选取选取没有很好解决随机性的问题,本发明通过克洛斯卡尔来选择初始中心,通过重复n次来尽可能减少随机性所带来的问题,可以较好地减少迭代次数。技术方案:一种基于分布式计算平台改进的k均值聚类方法,由于k均值算法存在随机选取初始中心导致最终簇心局部化最优解,对海量数据处理速度慢,数据迭代次数过多以及没有考虑向量之间的关联关系等问题,所以针对海量数据处理慢的问题引入了分布式计算平台Spark的,针对迭代次数过多的问题,引入卡洛斯卡尔算法,针对没有考虑向量各特征间的相关性,引入谷本距离。首先,通过克洛斯卡尔算法来对随机选取的k个点来构造最小生成树并求出对应的权值和,重复n次,然后按照这n次得到的权值和,从中选取出最大的权值和并且确保由k个点组成的边之间的距离值相差不大,这样可以保证簇心相对均匀分布,最后使用经谷本距离改进后的k均值算法进行聚类运算。其步骤如下:1)从样本中随机选取k个数据向量,对每个数据向量的每一特征进行规范化,使数据向量的每一特征的取值在0~1之间,对选取的k个数据向量,使用克洛斯卡尔算法,求出最小生成树的权值和,重复这个过程n次,记第i次计算得到的最小生成树权值和为di,2)求出最小生成树权值和中的最大值MAX(d1,d2,...,dn)对应的由k个数据向量组成的点集;3)倘若求出的点集的各边的权值相差不大于0.1时,则将该点集作为初始簇中心的k个初始中心,转步骤4);否则排除该点集,转步骤2);4)运行基于分布式计算平台Spark改进后的k均值算法;对每个数据向量的每一特征进行规范化,使数据向量的每一特征的取值在0~1之间,运行过程中根据谷本距离公式计算每个数据向量到k个簇中心的距离,根据计算得到的k个距离值,将数据向量放入到距离最小的这个簇心所对应的蔟中,然后通过每个簇中所有数据向量求平均值来更新蔟中心,此时,计算上一次k个蔟中心与更新后对应的蔟中心之间的欧式距离,得到k个欧氏距离值,倘若k个欧氏距离值都小于规定的误差阈值或达到迭代次数时,转步骤5),否则继续迭代;这里迭代是指迭代簇中心,通过迭代来更新蔟中心;5)输出聚类结果。所述的分布式计算平台Spark,介绍如下:Spark是一个围绕易用性、速度和复杂分析构建的大数据处理框架,在大数据环境下提高了处理数据的实时性,并且保证了高可伸缩性和高容错性,此外可以将Spark部署由大量廉价机器之上来形成集群。所述的克洛斯卡尔最小生成树算法,具体描述如下:克洛斯卡尔算法的基本思想为:选择无向加权连通图G中权值最小,并且不和已经选择的边形成的环的边,并将其添加到边集E中;否则就选择下一条边,知道边集E中有n-1跳变为止(图G中有n个顶点)。在无向加权连通图G=(V,E)中,V={V1,V2,...,Vn}是n个顶点构成的集合,E={e1,e2,...,em}是m条边构成的集合,W={W1,W2,...,Wm}是每条边对应的权值。构造生成树记住T=G{e1,e2,...,en-1}。算法实现步骤:1)初始化顶点集边集所有边的权值WT=0。2)将所有的边的权值按照从小到大进行排序,记为E'。3)选择没有在边集E中,权值最小,不和边集E中的边构成环,并且WT+Weij<<Wr+We′ij的边eij(e0是连接顶点i和j的边,Wij是eij的权值,e'ij是么有选择的边中的其它任何一边,W'是边e'ij的权值),将顶点i,j中没有在点集A中的点添加到A中,并将边eij添加到边集E中;否则不选择这条边。4)重复第3步直到顶点集有n个顶点,边集中有n-1条边。所述的最小生成树,具体描述如下:在一个无向加权连通图所有生成树中,各边代价之和最小的那棵生成树称为该连通图的最小生成树。所述的k均值算法,具体描述如下:本发明所论述的k均值算法是在Spark中SparkMllib这个子工程中实现的,在本发明的实现过程中,需要修改k均值的源码实现,并且需要重新编译整个Spark项目(25个子项目)。k均值算法实现步骤:1)随机选取k个中心点。2)计算所有数据向量到k个初始聚类的中心点的距离,将每个数据向量划分到距离最近的中心点所在的簇中。3)计算每个聚类簇中各点的平均值,并作为新的中心点。4)重复步骤2),3),直到这k个簇点不再变化或者收敛或者达到所设定的迭代次数。所述的误差平方函数H定义为H=Σi=1kΣj=1ni||Xij-mi||2---(1)]]>其中Xij表示第i个类的第j个样本,i=1,2,...,k;j=1,2,...,ni,ni表示第i个类簇中的样本数,mi表示第i个的聚类中心。所述的特征的规范化,定义为:特征的规范化可以通过将每个特征转换为标准得分来完成,对每个特征取平均值,用每个特征减去平均值,然后除以特征的标准差,计算公式如下:normalizedij=featureij-μjσj---(2)]]>其中normalizedij表示第i个数据向量的第j个特征的规划化后的值,featureij表示第i个数据向量的第j个特征值,μj表示所有数据向量的第j个特征的平均值,σj表示所有数据向量的第j个特征的标准差。所述的聚类簇中心更新的计算公式,定义为:ki=1miΣj=1miXij---(3)]]>其中i=1,2,...,k,Ki表示第i个聚类蔟中心,Xij为第i簇中第j个样本。所述的欧式距离计算公式,定义为数据向量N=(n1,n2,...,np)和M=(m1,m2,...,mp)之间的距离d(m,n)为d(m,n)=(m1-n1)2+(m2-n2)2+...+(mp-np)2---(4)]]>其中m1,m2,...,mp是数据向量M的1维至p维数据集,n1,n2,...,np是数据向量N的1维至p维数据集。谷本距离,定义为:两个n维向量(a1,a2,...,an)和(b1,b2,...,bn)之间的谷本距离d,公式为:d=1-(a1b1+a2b2+...+anbn)(a12+a22+...+an2)+(b12+b22+...+bn2)-(a1b1+a2b2+...+anbn)---(5).]]>有益效果:与现有技术相比,基于分布式计算平台改进的k均值聚类方法,通过使用KDDCup1999数据集(KDDCup是一项数据挖掘竞赛,这是1999年竞赛的数据集,网址:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html)进行测试,实验证明本发明的Spark集群TKKM算法比SKKM算法的有更短的运算时间和更大处理海量数据的能力,比Spark集群SKKM算法在数据向量之间具有相关性方面有更高的准确率,比Spark自带的k均值++算法有更少的迭代次数。附图说明图1是k均值算法的迭代过程,其中(a)为随机初始化三个簇中心,(b)为经过一次迭代以后,(c)为经过二次迭代以后,(d)为经过三次迭代以后;图2是Spark生态系统图;图3是Spark的任务执行图;图4是基于分布式计算平台改进的k均值聚类方法流程图;图5是克洛斯卡尔算法构造最小生成树的过程图;图6是随着簇的个数增加,平方误差函数的值H的变化图。具体实施方式下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。基本思想:本发明是一种基于分布式计算平台改进的k均值聚类方法,由于k均值算法存在随机选取初始中心导致最终簇心局部化最优解,对海量数据处理速度慢,数据迭代次数过多以及没有考虑向量之间的关联关系等问题,所以针对对海量数据处理慢的问题引入了分布式计算平台Spark的,针对迭代次数过多的问题,引入卡洛斯卡尔算法,针对没有考虑向量各特征间的相关性,引入谷本距离。首先,根据克洛斯卡尔算法对随机选取的k个点求出这k个点的最小生成树权值和,重复n次,然后根据这n次的权值和选取出权值和最大并保证k个点的各边的权值相差不大,这样可以保证簇心相对均匀分布,最后使用经谷本距离改进后的k均值算法进行聚类运算。其步骤如下:1)从样本中随机选取k个数据向量,对每个数据向量的每一特征进行规范化,使数据向量的每一特征的取值在0~1之间,对选取的k个数据向量,使用克洛斯卡尔算法,求出最小生成树的权值和,重复这个过程n次,记第i次计算得到的最小生成树权值和为di,2)求出最小生成树权值和中的最大值MAX(d1,d2,...,dn)对应的由k个数据向量组成的点集;3)倘若求出的点集的各边的权值相差不大于0.1时,则将该点集作为初始簇中心的k个初始中心,转步骤4);否则排除该点集,转步骤2);4)然后运行基于分布式计算平台Spark改进后的k均值算法:对每个数据向量的每一特征进行规范化,使数据向量的每一特征的取值在0~1之间,运行过程中根据谷本距离公式计算每个数据向量到k个簇中心的距离,根据计算得到的k个距离值,将数据向量放入到距离最小的这个簇心所对应的蔟中,然后通过每个簇中所有数据向量求平均值来更新蔟中心,此时,计算上一次k个蔟中心与更新后对应的蔟中心之间的欧式距离,得到k个欧氏距离值,倘若k个欧氏距离值都小于规定的误差阈值或达到迭代次数时,转步骤5),否则继续迭代;5)输出聚类结果。分布式计算平台Spark,介绍如下:Spark是一个围绕易用性、速度和复杂分析构建的大数据处理框架,在大数据环境下提高了处理数据的实时性,并且保证了高可伸缩性和高容错性,此外可以将Spark部署由大量廉价机器之上来形成集群。克洛斯卡尔最小生成树算法,具体描述如下:克洛斯卡尔算法的基本思想为:选择无向加权连通图G中权值最小,并且不和已经选择的边形成的环的边,并将其添加到边集E中;否则就选择下一条边,知道边集E中有n-1跳变为止(图G中有n个顶点)。在无向加权连通图G=(V,E)中,V={V1,V2,...,Vn}是n个顶点构成的集合,E={e1,e2,...,em}是m条边构成的集合,W={W1,W2,...,Wm}是每条边对应的权值。构造生成树记住T=G{e1,e2,...,en-1}。算法实现步骤:1)初始化顶点集边集所有边的权值WT=0。2)将所有的边的权值按照从小到大进行排序,记为E'。3)选择没有在边集E中,权值最小,不和边集E中的边构成环,并且WT+Weij<<Wr+We′ij的边eij(e0是连接顶点i和j的边,Wij是eij的权值,e'ij是么有选择的边中的其它任何一边,W'是边e'ij的权值),将顶点i,j中没有在点集A中的点添加到A中,并将边eij添加到边集E中;否则不选择这条边。4)重复第3步直到顶点集有n个顶点,边集中有n-1条边。最小生成树,具体描述如下:在一个无向加权连通图所有生成树中,各边代价之和最小的那棵生成树称为该连通图的最小生成树。所述的k均值算法,具体描述如下:本发明的k均值算法是在Spark中SparkMllib这个子工程中实现的,在本发明的实现过程中,需要修改k均值的源码实现,并且需要重新编译整个Spark项目(25个子项目)。k均值算法实现步骤:1)随机选取k个中心点。2)计算所有数据向量到k个初始聚类的中心点的距离,将每个数据向量划分到距离最近的中心点所在的簇中。3)计算每个聚类簇中各点的平均值,并作为新的中心点。4)重复步骤2),3),直到这k个簇点不再变化或者收敛或者达到所设定的迭代次数。误差平方函数H定义为H=Σi=1kΣj=1ni||Xij-mi||2---(1)]]>其中Xij表示第i个类的第j个样本,i=1,2,...,k;j=1,2,...,ni,ni表示第i个类簇中的样本数,mi表示第i个的聚类中心。特征的规范化,定义为:特征的规范化可以通过将每个特征转换为标准得分来完成,对每个特征取平均值,用每个特征减去平均值,然后除以特征的标准差,计算公式如下:normalizedij=featureij-μjσj---(2)]]>其中normalizedij表示第i个数据向量的第j个特征的规划化后的值,featureij表示第i个数据向量的第j个特征值,μj表示所有数据向量的第j个特征的平均值,σj表示所有数据向量的第j个特征的标准差。聚类簇中心更新的计算公式,定义为:ki=1miΣj=1miXij---(3)]]>其中i=1,2,...,k,Ki表示第i个聚类蔟中心,Xij为第i簇中第j个样本。欧式距离计算公式,定义为数据向量N=(n1,n2,...,np)和M=(m1,m2,...,mp)之间的距离d(m,n)为d(m,n)=(m1-n1)2+(m2-n2)2+...+(mp-np)2---(4)]]>其中m1,m2,...,mp是数据向量M的1维至p维数据集,n1,n2,...,np是数据向量N的1维至p维数据集。谷本距离,定义为:两个n维向量(a1,a2,...,an)和(b1,b2,...,bn)之间的谷本距离d,公式为:d=1-(a1b1+a2b2+...+anbn)(a12+a22+...+an2)+(b12+b22+...+bn2)-(a1b1+a2b2+...+anbn)---(5).]]>本发明所使用的数据集基本特征如表1所示。表1数据集基本特征本发明所使用的平台是分布式计算平台Spark,在实验中Spark是以Spark集群的方式,基本情况如下表2所示。表2Spark集群的各机器的参数配置和运行进程机器IP内存cpu运行进程192.168.189.1506g2个酷睿i7处理器Master、Slave192.168.189.1513g2个酷睿i7处理器Slave192.168.189.1523g2个酷睿i7处理器Slave这里简记通过卡洛斯卡尔算法改进的k均值算法为SKKM算法。这里简记能运行在Spark集群环境的SKKM算法为Spark集群SKKM算法。这里简记通过谷本距离和克洛斯卡尔算法改进的K均值算法为TKKM算法。这里简记能运行在Spark集群环境的TKKM算法为Spark集群TKKM算法。这里需要说明一下,为了使SKKM算法和TKKM算法能够运行在Spark集群上,需要通过修改Spark机器学习中k均值的源码,然后通过maven来实现对Spark整体工程重新编译。为了能获得更好的性能之前需要选择合适的K值。本发明通过Spark自带的随机初始中心的k均值算法进行选择合适的k值,k从10到120进行,步进为10,评价指标位误差平方函数H,重复20次,实验结果图6所示,此处需要说明一下图6的误差平方函数值缩小了108倍,仅仅是为了显示方便。根据图6所示当k=100时,平方误差函数值H已经趋近平稳,取大于100的k值,反而会增加计算的复杂度。针对现有技术一第一个技术缺点:处理海量数据和很大维度数据向量数据集运算速度慢或无法运算的问题,本发明通过Spark集群的方式解决,本文中通过eclipse运行SKKM算法来模拟单机版,Spark集群运行SKKM算法和TKKM算法,重复20次上述运算,记录每一次运算的时间,取平均值的方式来消除偶然因素的影响。记录结果如下表3。根据表3结果可以看到,当数据量很小的时候,单机版本SKKM算法运行时间比Spark集群SKKM算法及Spark集群TKKM算法短,当数据不断增大时,单机版本SKKM算法的时间开始快速增加,Spark集群SKKM算法和Spark集群TKKM算法的运行时间增加相对缓慢,当数据量超出单机版本运算能力时,Spark集群SKKM算法和Spark集群TKKM算法还能很快完成运算。这边需要说明一下,本发明的是能运行在Spark集群上的TKKM算法,这里之所以运算时间比Spark集群SKKM算法长是因为谷本距离的时间复杂度比欧氏距离的大。当前信息技术快速发展,信息以爆炸式增长,远远超出单机的运算能力,而Spark可以通过不断添加廉价的机器扩展集群大小来满足运算的需求,这就是本发明第一个优势。表3单机和分布式集群运算时间数据样本个数单机SKKM算法Spark集群SKKM算法Spark集群TKKM算法100041s92s92s1000059s105s107s10000070s112s118s1000000136s150s161s100000001045s189s203s20000000内存溢出无法运行265s284s针对现有技术一第二个技术缺点:选择初始中心以后进行k均值运算时,没有考虑每个数据向量之间的相似度。本发明引入谷本距离来计算每个数据向量到每个簇心的距离来决定每个数据向量属于哪个簇,默认使用的是欧氏距离,使用谷本距离的算法是Spark集群TKKM算法,使用欧氏距离的算法是Spark集群SKKM算法,本发明通过误差平方函数H来评价这两个算法在性能上的情况。通过重复20次求平均值来减少误差,结果记录如下表4所示。表4Spark集群SKKM算法和Spark集群TKKM算法的误差平方函数值E算法Spark集群SKKM算法Spark集群TKKM算法误差平方函数值H229.551758969970706164.192648887949918根据表4可以看到,Spark集群TKKM算法的误差平方函数值H比Spark集群SKKM算法的误差平方函数值H降低了,可以看出在数据向量之间存在相关性的数据集上引入谷本距离可以降低k均值算法的误差平方函数值,从而得到更好的聚类结果。针对现有技术二Spark自带的k均值++算法的缺点:由于k均值++没有很好的选择初始中心,没有很好的解决随机选择初始中心带来的迭代次数过多的问题。本发明引入克洛斯卡尔算法,为了消除谷本距离引入带来的影响,本发明还需Spark集群SKKM算法作一个参照。这里使用运算的迭代次数作为指标。重复20次,记录每次的各个算法的迭代次数来消除偶然因素带来的影响。实验结果记录在表5中,这里需要说明一下,记录数据采用四舍五入的方式。表5各种算法在相同环境下的迭代次数算法Spark自带k均值Spark自带k均值++Spark集群SKKMSpark集群TKKM迭代次数143201616根据表5可以看到,Spark自带k均值由于随机选择初始中心,导致迭代次数特别的多,Spark集群SKKM算法与Spark集群TKKM算法的迭代次数基本相当,说明谷本距离的引入对于迭代次数而言并没有增加,Spark集群TKKM算法的迭代次数比Spark自带k均值迭代次数减少了4次,减少了25%,很好的说明Spark集群TKKM算法可以很好的减少运算的迭代次数。综合上面实验结果数据证明本发明的Spark集群TKKM算法比SKKM算法的有更短的运算时间和更大处理海量数据的能力,比Spark集群SKKM算法在数据向量之间具有相关性方面有更高的准确率,比Spark自带的k均值++算法有更少的迭代次数。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1