网络用户行为预测系统的制作方法
本发明涉及移动互联网技术领域,具体涉及网络用户行为预测系统。
背景技术:
用户网络行为分析,是指在获得用户在网络操作行为的相关数据的情况下,对相关数据进行统计分析,从而判断发现网络用户的群体构成和各自的喜好,以及为后续相关操作提供依据。
相关技术中的用户网络行为分析系统,一般包括信息采集模块、信息存储模块、信息挖掘统计模块、系统展现模块。信息采集模块用以采集用户网络行为数据,将采集到的数据汇总上传给信息存储模块;信息存储模块用以存储信息采集模块采集上传的数据,并进行汇总,将汇总后的数据输出到原始数据库中;信息挖掘统计模块用以定期从原始数据库中提取出数据并进行统计、挖掘和分析,具体包括排名统计、用户行为分类、用户分类、用户聚类等,并将分析结果输出到统计数据库中;系统展现输出模块,用以从统计数据库中获取数据,展示用户网络行为分析的结果。上述用户网络行为分析系统,采用的数据大部分是部分媒体的数据或者是小样本的数据,这样无法准确的判别用户的行为,且不支持海量用户移动网络数据的分析挖掘;另外,基于K-means聚类方法的数据统计模块,不能有效避免单一采取随机抽样方法所带来的偶然性,聚类稳定性低。
技术实现要素:
针对上述问题,本发明提供网络用户行为预测系统。
本发明的目的采用以下技术方案来实现:
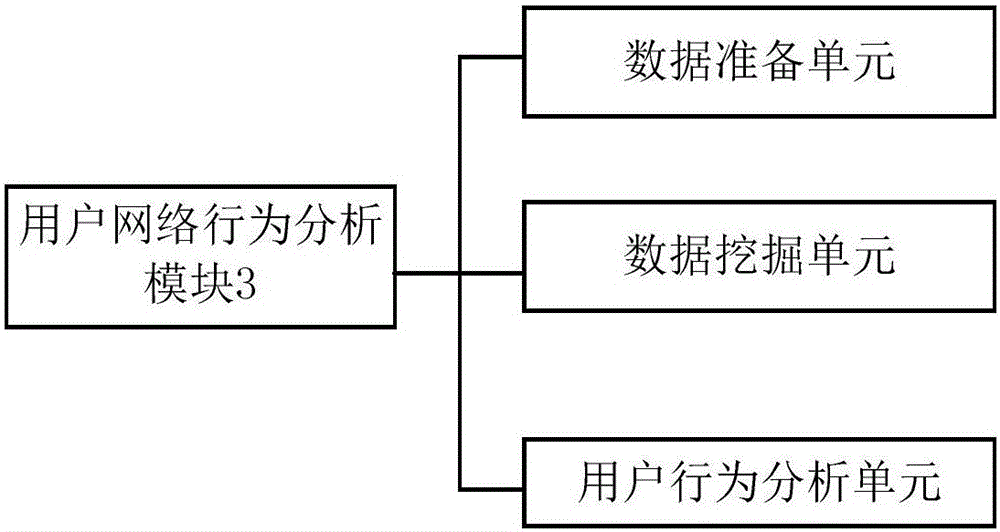
网络用户行为预测系统,包括依次连接的数据集储模块、数据预处理模块、用户网络行为分析模块、数据展现模块;所述数据集储模块用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块;所述用户网络行为分析模块用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块定时向所述数据预处理模块传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
其中,所述设定的比例值T的取值范围为[1.45,1.55]。
本发明的有益效果为:
1、支持海量用户移动网络数据的分析挖掘;
2、设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;
3、设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1是本发明各模块的连接示意图;
图2是本发明用户网络行为分析模块的结构示意图。
附图标记:
数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4。
具体实施方式
结合以下实施例对本发明作进一步描述。
实施例1
参见图1、图2,本实施例网络用户行为预测系统,包括依次连接的数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4;所述数据集储模块1用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块2,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块3;所述用户网络行为分析模块3用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块4用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块3包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块1包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块1定时向所述数据预处理模块2传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
本实施例支持海量用户移动网络数据的分析挖掘;设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高;设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;其中T=1.45,用户行为分析精度相对提高了5%。
实施例2
参见图1、图2,本实施例网络用户行为预测系统,包括依次连接的数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4;所述数据集储模块1用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块2,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块3;所述用户网络行为分析模块3用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块4用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块3包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块1包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块1定时向所述数据预处理模块2传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
本实施例支持海量用户移动网络数据的分析挖掘;设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高;设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;其中T=1.47,用户行为分析精度相对提高了4.8%。
实施例3
参见图1、图2,本实施例网络用户行为预测系统,包括依次连接的数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4;所述数据集储模块1用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块2,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块3;所述用户网络行为分析模块3用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块4用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块3包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块1包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块1定时向所述数据预处理模块2传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
本实施例支持海量用户移动网络数据的分析挖掘;设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高;设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;其中T=1.50,用户行为分析精度相对提高了5%。
实施例4
参见图1、图2,本实施例网络用户行为预测系统,包括依次连接的数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4;所述数据集储模块1用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块2,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块3;所述用户网络行为分析模块3用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块4用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块3包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块1包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块1定时向所述数据预处理模块2传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
本实施例支持海量用户移动网络数据的分析挖掘;设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高;设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;其中T=1.52,用户行为分析精度相对提高了4.5%。
实施例5
参见图1、图2,本实施例网络用户行为预测系统,包括依次连接的数据集储模块1、数据预处理模块2、用户网络行为分析模块3、数据展现模块4;所述数据集储模块1用于通过采集设备采集并存储用户移动互联网的有用数据;所述数据预处理模块2,用于对所述有用数据进行数据清理和清洗,过滤掉包含噪音和异常的数据,形成用户行为分析的有效数据集,并将所述有效数据集传送给用户网络行为分析模块3;所述用户网络行为分析模块3用于对所述有效数据集进行分类整理和分析,并对用户的行为进行分析,输出用户行为分析结果;所述数据展现模块4用于将所述用户行为分析结果展现给用户;所述用户网络行为分析模块3包括依次连接的数据准备单元、数据挖掘单元和用户行为分析单元,所述数据准备单元用于剔除有效数据集中的缺失值和异常值,并进一步进行归一化处理,其中异常值采用统计学中的常用异常点判别方法GESR进行判别;所述数据挖掘单元用于采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,并建立用户分群模型;所述用户行为分析单元用于采用决策树算法对所述分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测并输出用户行为分析结果。
其中,所述数据集储模块1包括通过专有的数据采集设备链接程序开发的采集设备,所述采集设备用于解析、存储所述访问日志和信令日志数据。
其中,所述用户移动互联网的有用数据包括:移动互联网的访问日志数据和信令日志数据中的一种或多种。
其中,所述数据集储模块1定时向所述数据预处理模块2传送最近时段的用户移动互联网的有用数据更新。
其中,所述数据挖掘单元采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,具体为:
1)设所述有效数据集具有n个样本,对n个样本进行向量化,通过夹角余弦函数计算所有样本两两之间的相似度,得到相似度矩阵XS;
2)对相似度矩阵XS的每一行进行求和,计算出每一个样本与整个有效数据集的相似度,设XS=[sim(ai,aj)]n×n,i,j=1,…,n,其中sim(ai,aj)表示样本ai,aj间的相似度,求和公式为:
3)按降序排列XSp,p=1,…,n,设XSp按从大到小排列的前4个值为XSmax,XSmax-1,XSmax-2,XSmax-3,若选择与最大值XSmax相对应的样本作为第一个初始的聚簇中心,否则选择与XSmax,XSmax-1,XSmax-2,XSmax-3对应的四个样本的均值作为第一个初始的簇中心,T为设定的比例值;
4)将最大值为XSmax对应的矩阵中行向量的元素进行升序排列,假设前k-1个最小的元素为XSpq,q=1,…,k-1,选择前k-1个最小的元素XSpq相对应的样本aq作为剩余的k-1个初始的聚簇中心,其中所述k值的设定方法为:设定k值可能取值的区间,通过测试k的不同取值,并对区间内的各个值进行聚类,通过比较协方差,确定聚类之间的显著性差异,从而来探査聚类的类型信息,并最终确定合适的k值;
5)计算剩余样本与各初始的聚簇中心之间的相似度,将剩余样本分发到相似度最高的聚簇中,形成变化后的k个聚簇;
6)计算变化后的聚簇中各样本的均值,将其作为更新后的聚簇中心代替更新前的聚簇中心;
7)若更新前的聚簇中心与更新后的聚簇中心相同,或者目标函数达到了最小值,停止更新,所述目标函数为:
其中,Cl表示k个聚簇中的第l个聚簇,ax为第l个聚簇中的样本,为第l个聚簇的中心。
本实施例支持海量用户移动网络数据的分析挖掘;设置的用户行为分析单元采用决策树算法对分群模型进行标识区分,识别用户身份,并根据标识区分识别结果建立人工神经网络模型,进而对用户行为进行预测,识别效果好,预测精度较高;设置基于改进K-means聚类方法的数据挖掘单元,采用改进K-means聚类方法对由数据准备单元处理过的有效数据集进行聚类,有效避免单一采取随机抽样方法所带来的偶然性,解决原有算法在选取k值以及初始化聚类中心时所存在的问题,提高了聚类稳定性,进一步提高了用户行为分析精度;其中T=1.55,用户行为分析精度相对提高了4.7%。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!