基于少量个性化样本的双网络深度学习方法与流程
本发明涉及通信与数据处理领域,特别涉及基于少量个性化样本的双网络深度学习方法。
背景技术:
随着网络技术的快速发展,数据的容量、个性化和多样性快速增加,而处理数据的算法复杂度却难以改善,依赖个人经验和手工操作来描述数据、标注数据、选择特征、提取特征、处理数据的方法,已经很难满足个性化数据快速增长的需求,如何高效处理个性化数据已经成为一个紧迫的难题。
深度学习方法的研究突破,为解决数据处理问题指明了一个值得探索的方向。深度学习可以从大数据中自动提取特征,并通过海量的样本训练获得很好的处理效果。实际上,大数据的快速增长和深度学习的研究是相辅相成的,一方面大数据的快速增长需要一种高效处理海量数据的方法,另一方面深度学习系统的训练需要海量的样本数据。
但是,个性化数据主要是由网络边缘的用户产生的,目前的方法是先对这些数据进行收集,然后再在云端服务器上对这些数据进行分析和处理。这会产生大量的数据传输,同时,对于终端用户来说,从服务器端得到的响应结果是由全局数据训练出的模型响应得到的,对于个性化用户的响应精度较低。如果在终端进行深度学习网络的构建,则由于终端个性化用户的数据量太少,无法对深度学习网络进行训练,这就是存在于目前网络的大数据两难悖论。
目前apache开发的hadoop架构,百度开发的参数服务器架构,腾讯开发的mariana架构等,都是针对分布式大规模、深度学习系统而做出的一些尝试,通过对模型进行拆分,对数据进行拆分等方式,这些系统在一定程度上解决了大规模数据的处理问题。然而,以上的这些分布式系统是将大规模的模型和数据在多机上进行处理,多机之间存在大量的数据通信,这就导致这些分布式系统目前只能应用于局域网络。而终端用户想要获得响应也必须先将数据传输到中心集群上,然后中心机群再将生成的响应发送给终端用户,因此用户端延迟响应很高。
在广域网络中,存在网络带宽的限制、大数据两难悖论、个性化需求等问题,如果能够解决分布式大数据实时处理系统中的通信代价高、边缘用户数据少的问题,则可以有效地将分布式大数据实时处理系统应用于广域网络,提高网络利用率,改善用户体验。
因此,针对少量个性化样本,有必要提供一种更适合于广域网络的分布式数据处理方法,以解决训练数据和模型参数的传输量大,以及当分布式数据存在个性化信息时,处理精度难以提升的问题。
技术实现要素:
本发明的目的在于克服已有的分布式数据处理方法由于边缘用户样本数据少、从而处理精度难以提升的缺陷,从而提供一种基于少量个性化样本的双网络深度学习方法。
为了实现上述目的,本发明提供了一种基于少量个性化样本的双网络深度学习方法,所述双网络包括重构网络与深度网络,该方法包括:
步骤1)、采集少量个性化样本;其中,所述个性化样本包括样本数据及其标签;
步骤2)、利用个性化样本中的样本数据训练所述重构网络,然后将个性化样本中的标签输入经过训练后的重构网络中,生成新的重构数据及其标签;
步骤3)、基于步骤2)所得到的来自重构网络的新的重构数据及其标签训练所述深度网络;
步骤4)、将待测试的数据输入到经过训练的深度网络中,得到s形函数的输出,再经过一个软最大回归从所述s形函数的输出中选择一个结果作为个性化的响应。
上述技术方案中,所述少量个性化样本的数目记为m,m≈m/j,其中的m为用大数据训练相同精度的深度网络时的样本总数,j为通过一个个性化样本重构出的样本的个数。
上述技术方案中,在步骤2)中,所生成的新的重构数据及其标签的集合表示为{xrk,yrk};其中,
xrk代表任意一个重构数据,yrk为该重构数据对应的标签,k的取值为1≤k≤m×j,m为个性化样本数目,j为通过任一个性化样本重构出的样本的个数;j和个性化样本数目m的关系如下:m值越小,j的取值越大,以保证有足够的重构样本m×j来训练深度网络。
上述技术方案中,所述重构网络为包括贝叶斯网络和无层次神经网络在内的任何一种具有随机重构大量样本功能的学习网络。
上述技术方案中,所述重构网络为具有一次性学习功能的贝叶斯程序学习网络。
上述技术方案中,所述深度网络为包括深度前馈网络、深度置信网、深度玻尔兹曼机、深度卷积网络在内的任何一种具有高精度的深度学习网络。
上述技术方案中,所述步骤4)进一步包括:
步骤4-1)、通过深度网络的隐层计算各神经元的输出,其计算公式为:
其中,yj是第j个神经元的输出,f是一个给定的激活函数,wij是从第i个神经元到第j个神经元的连接权重,xi是来自第i个神经元的输入,bj是偏置权重;
步骤4-2)、计算s形函数的输出;其中,s形函数的表达式为:
所得到的s形函数的输出是一个p维的向量(o1,o2,…,oj,…,op),向量中的每一个元素oj=sigmoid(yj)都是介于0和1之间的实数,这里的p是个性化标签的总数;
步骤4-3)、通过软最大回归从所述s形函数的输出中选择一个结果作为个性化的响应;其中,软最大回归的公式如下:
所述软最大回归表示分别以(softmax(o1),softmax(o2),…,softmax(oj),…,softmax(op))的概率在s形函数的输出(o1,o2,…,oj,…,op)中选中一个oj作为个性化响应。
本发明的优点在于:
本发明通过引入了一个支持一次性学习的辅助重构网络,将少量个性化样本转化为大量数据,从而解决了少量的个性化样本无法直接训练一个高精度深度网络的问题。同时,本发明的方法有效地避免中心和边缘之间的数据传输,它对现有的深度学习系统进行了扩展,可以将其应用到广域网络中,它不仅解决了当分布式数据存在个性化信息时,处理精度难以提升的问题,而且改善现有分布式大数据实时处理系统的传输代价。
附图说明
图1是本发明的基于少量个性化样本的双网络深度学习方法的流程图;
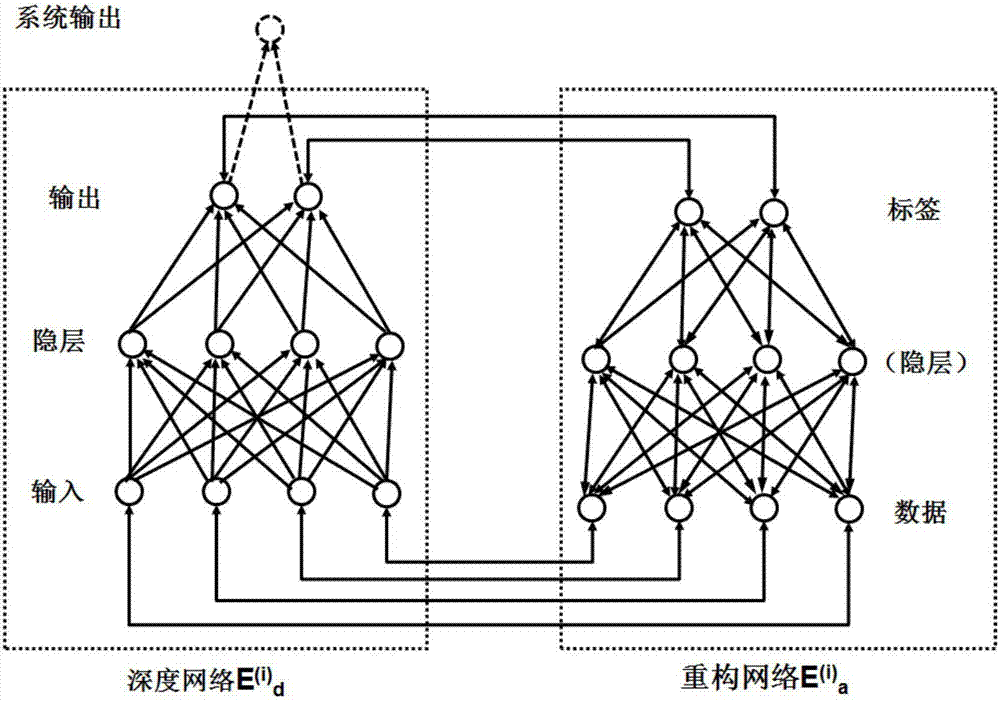
图2是本发明中所涉及的双网络的结构示意图。
具体实施方式
现结合附图对本发明作进一步的描述。
如图1和图2所示,本发明的基于少量个性化样本的双网络深度学习方法,包括:
步骤1)、采集少量个性化样本,作为双网络系统的输入;其中,少量个性化样本的总数记为m,取值范围为m≥1;优选地,m≈m/j,其中的m为用大数据训练相同精度的深度网络时的样本总数,j为通过一个个性化样本重构出的样本的个数。所采集的个性化样本中样本数据的集合可记为
本步骤中,所采集的个性化样本除了样本数据本身以外,还包括该样本所对应的标签。个性化样本标签是指对于任意数据
步骤2)、利用所采集的个性化样本的样本数据来训练双网络中的重构网络(记为
其中,双网络中的重构网络ea(i)可以是任何一种具有随机重构大量样本功能的学习网络,包括贝叶斯网络和无层次神经网络在内;重构网络ea(i)优选为具有一次性学习功能的贝叶斯程序学习网络;所述的贝叶斯程序学习网络先根据背景知识库获得的先验知识对输入数据进行拆分,将输入数据拆分成小的部分和元组,然后将这些小的部分和元组进行重新组合,生成新的重构数据
步骤3)、基于来自重构网络的大量新的重构数据及其标签的集合
其中,双网络中的深度网络ed(i)可以是任何一种具有高精度的深度学习网络,主要包括深度前馈网络、深度置信网、深度玻尔兹曼机、深度卷积网络。
步骤4)、将用于测试的个性化样本或来自外部的新数据输入到经过训练的深度网络ed(i)中,得到s形函数的输出,再经过一个软最大回归从s形函数的输出中选择一个结果,作为个性化的响应。
其中,s形函数的表达式为:
其中,yj是第j个神经元的输出,其值是通过深度网络的隐层计算出来的,具体计算公式如下:
其中,f是一个给定的激活函数,wij是从第i个神经元到第j个神经元的连接权重,xi是来自第i个神经元的输入,bj是偏置权重。
s形函数的输出是一个p维的向量(o1,o2,…,oj,…,op),向量中的每一个元素oj=sigmoid(yj)都是介于0和1之间的实数,这里的p是个性化标签的总数。
其中,软最大回归的公式如下:
所述软最大回归表示分别以(softmax(o1),softmax(o2),…,softmax(oj),…,softmax(op))的概率在(o1,o2,…,oj,…,op)选中一个oj作为个性化响应。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!