对符号序列分配导航目标用的装置、方法和计算机程序与流程
本实施例涉及将导航目标分配给包括多个符号组的符号序列用的装置的领域。
背景技术:
在计算机支持的制图学的范围内,使用多个不同类型的仪表或为此开发的计算机程序,它们可以以不同的方式起作用。例如,传统的解决方案可以包括将用户的输入分配给唯一地理位置或提供至少一个可能的位置选择的程序。然而,这里可能需要,用户的输入立即是唯一的,或至少由于事先存储的参数而可能受到限制。只要在用户方面希望确定到该位置的路由,这时,该解决方案可能不能够进行到达该目标的导航,或这时只是没有充分考虑用户在路由选择方面的要求。可以执行其他解决方案、也就是说到达该位置的导航,但这时可能前提是完全的唯一的或以预先给定的格式进行的导航目标输入,这可能给用户本身带来时间或专心的消耗。例如,这可能在汽车中导航时起妨碍作用,因为汽车驾驶员,例如,在交通负荷大时也许没有足够的时间或专心用于目标给定上。除在汽车中导航以外,上述问题在给定情况下也可能不必要地使程序操作复杂化。
因此,改善将导航目标分配给用户输入的符号序列的概念是值得期望的。
技术实现要素:
这个需求带来带有独立权利要求特征的装置、方法和计算机程序。其他有利的实施方式和扩展是从属权利要求的主题。
按照第一方面,实施例涉及将导航目标分配给包括多个符号组的符号序列用的装置。该装置包括分配模块,它构造成针对该符号序列的解释,进行将至少一个符号组分配给多个信息类别中的第一信息类别。为此,该装置包括存储模块,构造成对于可用不同的特征和符号串描述的多个目标,尤其城市,各自提供多个唯一地分配给目标的不同信息类别的特征。此外,该装置还包括选择模块,构造成当该符号组对应于分配给所选择的目标的第一信息类别的特征时,从多个目标选择所选择的目标。该分配模块还构造成,只有当为该目标的第二信息类别分配与各符号组对应的特征时,才在所选择的目标下进行将来自该符号序列的另外的符号组分配给第二信息类别。以此,在得出导航目标时,可能的是可以首先进行在目标上的限制,使得在给定情况下另外的搜索可以较快进行。这可能导致节省时间和节省计算能力,并这样提高对用户使用的舒适性。
在一些实施例中,该分配模块构造成,进行将该另外的符号组分配给该第二信息类别。此外,该选择模块构造成,当该另外的符号组对应于在限制的领域内为信息类别而存储的存储特征时,不选择目标,而进行将另外的符号组分配给该第二信息类别。它可以允许,若事先无法唯一地求出目标,或出现矛盾的数据,则按照可能的目标进行周围搜索,其中该导航目标处于潜在地位。
在一些实施例中,该分配模块还构造成,只有当该符号组分配给来自信息类别第二子集的第一信息类别时,才将另外的符号组分配给来自信息类别第一子集的第二信息类别。
这可能导致使得几个信息类别只有在已经分配的另外的信息类别前提下才可以分配,和可能排除这样不合逻辑的解释,这可以进一步缩短目标搜索时间。
在一些实施例中,该分配模块还构造成,只有当该符号组直接处于该符号序列内另外的符号组的前面时,才将该另外的符号组分配给来自信息类别第一子集的第二信息类别。这可能导致使得几个信息类别可以跟随仅一个已经分配的其他的信息类别,并可能排除这样不合逻辑的解释,这可以进一步缩短目标搜索时间。
在一些实施例中,该分配模块还构造成,只有当包括该第二信息类别的第一子集不同于包括分配给该符号组的第一信息类别的第二子集时,才将该另外的符号组分配给第二信息类别。这可能导致只有当存在确定的其他的信息类别时,或当它缺失,和可能排除这样不合逻辑的解释时,才可以分配几个信息类别,可以进一步缩短目标搜索时间。
在一些实施例中,该分配模块还构造成,只有当该符号组包括该符号序列的开始符号,或排除该符号序列的结束符号时,才将该符号组分配给来自信息类别子集的第一信息类别。这可以考虑保持其中该符号组应该以确定的信息类别彼此出现的预先定义的顺序,并可能排除这样不合逻辑的解释,这可以进一步缩短目标搜索时间。
在不少实施例中,该装置还包括检验模块,它构造成,为将该符号组或该另外的符号组分配给第一或第二信息类别的正确性确定概率值。这时,概率值是任选的,从最高包括三个要素的数值量中的要素。这里可以通过逻辑运算,对该符号序列的解释进行暂时的打分,使得多个解释彼此在可信性方面可以进行比较。
在一些实施例中,该检验模块还构造成,为根据符号组一个或多个标记的数目、类型或同一性分配该符号组的正确性,确定概率值。这可以使解释另外的分类成为可能,并可能允许比较简单地检查其可信性或其概率。
在一些实施例中,该检验模块还构造成,为在考虑将该第一符号组分配给第一信息类别的情况下分配该另外的符号组的正确性,确定概率值。这可能使根据一定的信息类别的存在对解释进行分类成为可能,并可能允许进一步简化其可信性或其概率的检查。
在一些实施例中,该检验模块还构造成,为在考虑该符号组对该符号序列内该另外的符号组的相对位置情况下分配该另外的符号组的正确性,确定概率值。这可以允许根据在共同符号序列中出现的信息类别的顺序来检查解释的可信性。
在一些实施例中,该装置还包括评估模块,它构造成,在考虑将该符号组分配给该信息类别的情况下确定该符号序列作为导航目标可能的解释。这可以使在概观所有包括于其中的符号组及其信息类别的情况下解释该符号序列成为可能。
在一些实施例中,该评估模块还构造成,在考虑将至少该符号组分配给该信息类别的正确性概率值的情况下,为该符号序列可能的解释确定总概率值。以此共同符号序列不同的解释可以按照其概率或其可信性进行估计。
在一些实施例中,该评估模块还包括排序模块,它构造成,在基于总概率值的顺序中,提供该符号序列的第一可能的解释和该符号序列第二可能的解释。这允许可能按照其概率可能的导航目标清单输出进行排序,这可以使向用户提供总览变得容易。
按照另外的方面,实施例涉及将导航目标分配给包括多个符号组的符号序列用的方法。该方法包括,为了解释该符号序列,进行将至少一个符号组分配给来自多个信息类别的第一信息类别。该方法为此为多个目标,提供各自多个唯一地分配给目标的不同的信息类别的特征。此外,该方法还包括,当该符号组对应于分配给所选择的目标的第一信息类别特征时,选择可以用不同的特征和符号串描述的目标,尤其城市,从多个目标选择的城市。此外该方法还包括,只有当为该目标的第二信息类别分配与各符号组对应的特征时,才在所选择的目标下,进行将该符号序列的另外的符号组分配给第二信息类别。这可以显著地缩短导航目标的搜索时间,因为首先也许可以限于目标,接着,可以将该另外的搜索限制于其上。以此可以较快地向用户提供搜索结果。
此外,其他实施例还创造带有程序代码的程序或计算机程序,该代码用以当其在计算机、处理器或可编程硬件组件,例如,专用集成电路(ASIC)上运行时,执行上述方法。
附图说明
现将参照附图更详细地描述和阐述几个示例性的实施例。附图中:
图1是按照简单的实施例,将导航目标分配给符号序列用的装置的方框图;
图2是按照实施例,执行将导航目标分配给符号序列用的方法的程序体系结构方框图;
图3是按照详细的实施例,分配模式用的逻辑操作步骤的方框图;
图4是按照详细的实施例,将导航目标分配给符号序列用的装置的方框图;而
图5是按照另外的实施例,将导航目标分配给符号序列用的方法流程图。
具体实施方式
现将参照其中显示一些实施例的附图,详细地描述不同的实施例。为了清晰起见,在图中线、层和/或区域的厚度尺寸可能采取夸张的显示。
在下文对表示这些实施例的附图的描述中,相同或类似的组件标以相同的引用符号。另外,概括性的引用符号用于在一个实施例或在一个附图中多次出现,但在一个或多个特征方面共同进行描述的组件和对象。以相同的或概括性的引用符号描述的组件或对象,可以在各个、多个或所有特征方面,例如其尺寸相同,但在某些情况下还形成得不同,只要从该描述没有另外明确或暗含的指出。
尽管对实施例可以用不同的方法进行改变和修改,但附图中的实施例是作为示例显示的,并在这里详细描述。但要澄清,实施例并不打算限于各自公开的形式,而是毋宁说应该覆盖处于本发明范围内的全部功能上的和/或结构上修改、等效和替换。相同的引用符号在所有附图说明中标示相同或相似的要素。
人们注意到,表示为与另外的零件“连接”或“耦合”的零件,可以与该另一零件直接连接或耦合,或可以存在处于中间的零件。反之,当零件表示为与另外的零件“直接连接”或“直接耦合”时,不存在处于中间的零件。为了描述元素的关系所使用的其他概念,应该进行类似的解释(例如,“之间”对“它们直接之间”、“交界”对“直接交界”等等)。
这里使用的术语只用来描述一定的实施例,而不应该限制这些实施例。正如这里使用的,单数形式“一”、“一个”和“该”也包含复数形式,只要上下文不是明确地另有所指。还要澄清,例如,正如这里使用的“包含”、“包括”、“有”和/或“具有”、“包括”和/或“包含”,给出上述特征、整数、步骤、工作进度、元素和/或组件的存在,但不由此排除一个或一个或多个特征、整数、步骤、工作进度、元素、组件和/或组的存在或附加。
只要没有其他定义,这里使用的全部概念(包括技术和科学概念)都具有相同的意义,在该实施例所属的领域上一般技术人员所赋予的。还要澄清,例如,在一般使用的辞典中定义的措辞可以这样解释,除了它们具有与其在有关的技术背景下的一致的意义外,和不以理想化的或过度形式的意义上解释,只要它在这里没有明确定义。
通过实施例可以使符号序列,例如,作为单列地址输入,并要获得存储在数据库上的城市、街道、地址或十字路口作为输出成为可能。以此包括的传统的方法或装置,常常可以只能提供较不强健的,直观或针对用户较不有用的解决方案。
图1表示将导航目标分配给包括多个符号组的符号序列用的装置100的方框图。具体地说,在图1,3和4中使用下列缩写:
ZA:符号序列
ZGm:符号组
ZGn:另外的符号组
ZG:符号序列的主要的符号组
ZGN:符号序列最后的符号组
Z:符号组的标记
IK1:第一信息类别
IK2:第二信息类别
T1:信息类别的第一子集
T2:信息类别的第二子集
Sm,Sn:城市
Mm,Mm1,Mm2,Mn,Mn1,Mn2:唯一地分配给城市的特征
G:限制领域
MG:限制领域内针对信息类的特征
W:概率值
GW,GW1,GW2:总概率值
IN,IN1,IN2:该符号序列作为导航目标的解释
装置100包括分配模块102,构造成针对该符号序列的解释,将至少一个符号组分配给多个信息类中的第一信息类。装置100为此包括存储模块104,它构造成为多个城镇,各自提供明确地分配给城市的多个不同信息类别的特征。此外,装置100还包括选择模块106,它构造成当该符号组对应于分配给该所选择的城市的第一信息类别特征时,从多个城镇选择所选择的城市。
另外,分配模块102还构造成,只有当为该城市的第二信息类别分配与各自符号组对应的特征时,在所选择的城市上将来自该符号序列的另外的符号组分配给第二信息类别。
这时,该符号序列可以包括至少一个符号组。该符号组可以包括至少一个标记。该分配模块102可以在另外的实施例上形成,以便将该符号序列分成多个符号组,或者甚至这些符号组彼此隔开。为此可以首先搜索多个可能性,例如,将符号序列“abcde”分成符号组“ab”和“cde”,或者分成符号组“abcd”和“e”。该信息类别可以是,例如,街道名或城市名、地理术语的缩写、房号、邮政编码或者介词,例如,“und(和)”或“in(在)”。据此一些信息类别可以指示城市,这时可以由选择模块106选择。所选择的城市可以按照该符号序列可能的解释包括该导航目标。该城市具有与该各符号组对应的特征的条件,可以作为特征,例如,涉及该城市所处的国家或者处于该城市的街道。换句话说,可能是这样,首先该符号序列的符号组可以解释为城市,并接着该符号序列的另外的符号组联系该城市进行解释。分配模块102、存储模块104和选择模块106,例如,可以通过数据总线系统(例如汽车上的CAN-总线)连接,或者还由共同硬件组件,例如,处理器所包括。存储模块104可以包括表,带有多个彼此分配的项,或者换句话说,包括数据库。更确切地说,一些实施例在这里与装置100一起描述,但这还可以与方法或计算机程序一起实现来执行该方法。
在一些实施例中,分配模块102构造成,进行将该另外的符号组分配给第二信息类别。此外,该选择模块106构造成,当该另外的符号组对应于为信息类别存储在限制领域内的存储特征时,不选定城市,,而进行将另外的符号组分配给该第二信息类别。在该领域内可以这样使选择一个或者多个城镇成为可能。当由于该符号序列的可能的符号组,不允许求出或者不允许明确地求出城市时,或者还有当可能出现矛盾的解释时,这可能是值得企望的。这时,该参数可以包括,例如,用户当时的位置,或者围绕这个位置的周围半径。该周围半径可以对应于工厂或者用户侧的预先设置,和/或依次扩大。矛盾的输入,例如,彼此不一致的邮政编码和城市名,例如,可以这样地解释,首先这两个信息类别中的解释为城市,和接着围绕所求出的城市进行外围搜索。这时,可以根据该邮政编码,在该邮政编码范围内,但在该城市以外求出有效的目标。
现在更详细地描述对符号序列(输入字符串)解释的概念,和所得的数据库查询分辨为城市、街道、地址或十字路口。通过实现一些实施例可以在汽车导航的背景下实现单列目标给定。例如,该用户可以将要开往的地址所有组成部分(城市、街道、房号等)一个接一个地输入字符串。这时,装在车辆上并为了输入地址可以构造得不连接到服务器的传统的系统,可以依赖层次输入。对于该用户这里可能需要依次给出国家、州、城市、街道和房号。这可能是烦琐的和不直观的,因此可能期望单列的目标给定。但例如,当用户只给出房号或房号和街道时,用传统的方法,这样的数据处理可能需要进行数据量过大的搜索。通过该实施例可以起到可能改善来自目标给定缩短和减少待搜索的数据量的折衷的改善作用。
一些实施例包括多个部分观点。第一部分观点可以是数据库或数据库表(在这里亦称城市索引),用来查找城市,有效地进行城市搜索,还可以允许围绕位置(例如,用户汽车的位置)进行周围搜索。该数据库可以包括明确地分配给城市的不同信息类别的特征,并保存在存储模块106上。第二部分观点可以是符号组分析(亦称Token-Entity-Analyse(标记实体分析)),它解释输入的符号序列,并可以求出哪部分,例如,是城市、街道或房号。这个符号组分析可以通过分配模块102进行。第三部分观点可以是搜索策略,它将符号组分析结果转换为对数据库的查询,并在给定情况下对存在的其他导航数据库的查询。
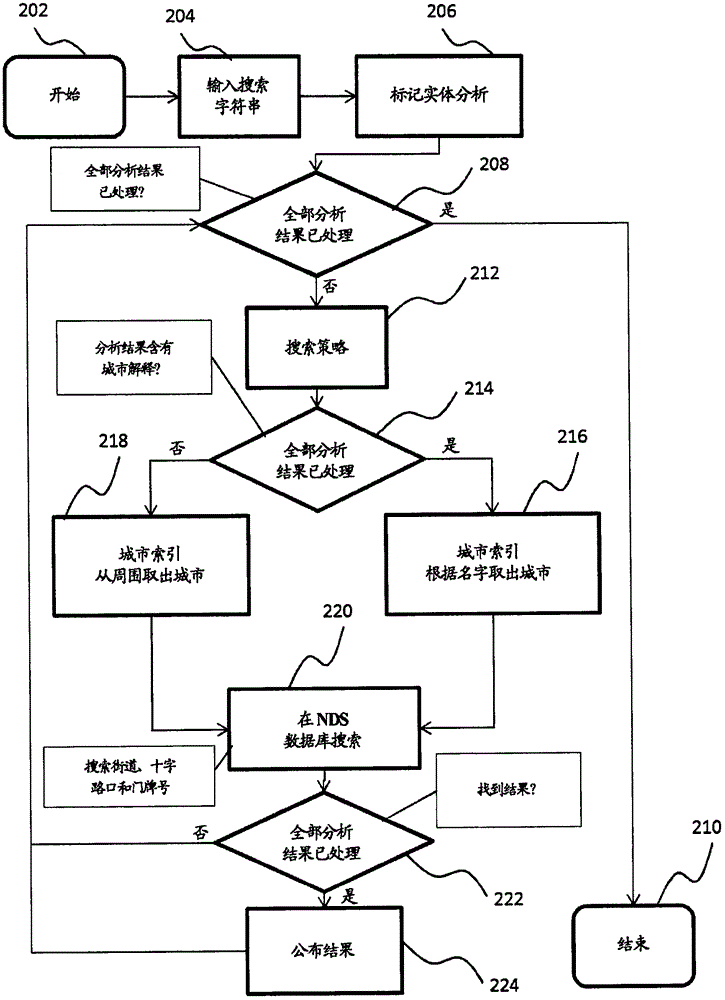
现将在图2说明和更详细地阐述这些部分观点与其他任选的方面的相互作用。图2表示执行按照实施例,将导航目标分配给符号序列用的方法用的程序体系结构方框图。例如,该程序可以借助于所描述的装置运行,或借助于该装置所包括的可编程硬件组件执行。首先以用户输入204序列进行程序的开始202。现在对该符号序列的符号组进行分析206,结果在第一控制步骤208测试是否所有分析结果都处理了。若是如此,则程序可以结束210。若非如此,则可以初始化搜索策略212。在第二控制步骤214可以测试,分析结果是否包括符号组作为城市的解释,或换句话说,该符号组是否分配给明确地指明城市的信息类别。若存在这样的解释,则可以从数据库调出216与城市名对应的城市。若这样的解释不存在,则可以从保存在存储模块104(参见图1)上的数据库再次调出218在处于预先定义的用户位置周围的城市。调出216和再次调出218可以通过选择模块106(参见图1)进行,用以求出至少一个城市。以此可以将另外的搜索限于至少一个城市。
另外的搜索220、例如,可以在导航数据标准(NDS)数据库上进行,并包括搜索街道、十字路口或房号。若所有分析结果均已处理,则可以进行第三控制步骤222,以便求出是否发现结果。若未发现结果,则该程序可以回到第一控制步骤208,而且不是再一次初始化搜索策略212,就是强制结束210。若找到结果,则可以公布224该结果。此后可以再次执行第一控制步骤208,以便求出是否所有分析结果均已处理。
在一些实施例中,可以采用基于标准NDS 2.3.2的数据库。以此搜索街道、十字路口和房号也许可以以传统的方式进行。在城市和市区搜索中,可以按照实施例使用包含各自的数据库所有城市的数据库表。该表亦称城市索引(city index),而且可以基于SQL 3.8.5和基于其中使用的技术FTS(Free Text Search,自由文本搜索),这在某些情况下也许可以使在数据库中高性能地带有占位符的符号序列或符号组搜索成为可能。
该数据库可以具有可以按照下列图示建立的数据库表(城市索引),其中INTEGER表示整数数值,而TEXT表示字符数字的符号结合:
这时,该表的结构可以基于NDS 2.3.2标准FTS-块,以便尽可能保持接近该标准。这时,该内容可以至少部分地重新定义。这时,按照一个实施例是有效的:
名称对象识别符是ID(识别符),可以用来明确地识别更新区域内的城市。它们可以允许有效地(performante)将街道搜索限定在特定的城市上。
MortonCode(莫顿码)包含城市位置(市中心)在分辨程度(详细等级)13上编码为Z-曲线的Z值。这里分辨程度1可以包括整个地图,分辨程度2包括地图片段,例如,带有分辨程度1边长一半,分辨程度3包括地图片段,例如,带有分辨程度2边长一半等等。
更新区域识别符包含该城市所处的更新区域的ID(识别符)。为了更好地处理区域中的更新过程,该地图分为所谓更新区域(Update Regions)。与NameObjektlD(名字对象识别符)一起可能在整个地图上面这样唯一地识别城市。
判据A包含该城市所处的国家,作为缩写(例如,“USA”或“MEX”)。它可以允许有效地限制国家搜索。判据B包含城市名称。它可以允许有效地按照名称搜索城市。判据D包含该城市用逗号分开的邮政编码。它可以允许有效地按照邮政编码搜索城市。判据G包含该城市所处的州,作为缩写(例如,“CA”或“NY”)。它可以允许有效地将搜索限制在州上。判据J包含该城市所处的区块(Kachel),编码为“详细等级”9中Z-曲线的Z-值。这时,该Z-值作为十六进制编码的字符串放置在该数据库中。它允许有效地在位置周围搜索城市,因为从位置和周围的半径可以用简单的公式算出参与的区块。
对于该数据记录包含市区的情况,搜索特征包含市区所属的城市名称。若它包含城市,则可以搜索特征留空。
优先级索引给出,该项指的是城市还是市区。这时,该数值“1”标记城市,而数值“0”标记市区。与搜索特征数值一起,这样还允许在给定情况下区分城市和市区,而不仅在城市名称的基础上进行搜索,而且在市区名称的基础上求出。
语言识别符包含在该项中该名称维持的语言的ID(识别符)。这里例如,“0”代表该城市所处的国家的官方语言(英语为local official)。城市可以在该表中多次出现,各自带有其他语言保持的名称和另外的语言识别符。这样还可以按照外来名称以不同于官方语言的另一语言,例如,以不同于系统语言的另外的语言进行搜索。
这些项判据C、判据E、判据F、判据H、判据I以及例外特征可以在一些实施例中留空。
随后的表表示按照这时所描述的实施例,根据Hollywood und Los Angeles in Kalifornien,USA(在美国,加利福尼亚,荷里活和洛杉矶)
通过用一些实施例的数据库表扩展NDS-2.3.2-数据库,允许可能有效的和消耗减少地在整个地图上搜索城市,视要求而定限制按照城市名、市区名、邮政编码、州、国家或语言以及在位置周围进行搜索。为了保持更小的消耗,该数据库表不仅可以分成更新区域,而且可以在整个地图的共同表中存在。
另外的查询可以按照一些实施例限制在城市上,定向于由该数据库表算出的数据库。这样可以绕过这样的问题,即包括街道的表潜在这样大,以致于不用FTS基于传统的SQL检索,只有在街道名的基础上才可能进行效率不高的搜索。将街道搜索限制在各城市(根据名字对象识别符和更新区域识别符参数从该数据库表)上也许可以带来提高效率的优点,它可以允许用户在诸如汽车的车上电脑等效率有限的平台上较快和比较简单地搜索地址。
按照上述第二部分观点,符号组分析可以用来分析并求出单列输入的符号序列,该符号序列的哪一组成部分,或换句话说,用户的哪一个符号组以多大的概率指的是房号、街道、城市、邮政编码、国家、州等等。这时该搜索策略可以将这个分析结果转化为数据库表的查询,和这样求出传递给用户输入的结果。
用户输入“500 CLIPPER DR″的分析示例,例如,可以提供“房号(500)街道(CLIPFER)街道(DR)”作为第一分析结果;“房号(500)街道(CLIPPER)-城市(DR)”作为第二分析结果,和“街道(500)街道(CLIPPER)-城市(DR)”作为第三分析结果。因为“DR”作为“Drive”(英语“大道”或“街道”)的缩写,在美国是街道名的一般组成部分,所以它最好可以解释为街道。“500”以较高的概率是房号,因为带有500的街道名非常罕见,而且因为它们处于符号序列的起点,在美国这里一般输入房号。可以相应地标记出不大可能的解释(例如,用负号“-”),而且对可能的解释的清单这样排序,使得推荐最可能的结果(尽可能少不可能的解释)。于是,该搜索策略与传统的解决方案相比,较快提供可信的结果,而不全部忽略不大可能的解释。尽管这提供了以后提供的结果。
符号组分析各自的实现可能取决于多个不同的因素,例如所使用的语言,因为例如,一般街道名组成部分可能取决于语言,其中希望采用的文化,因为一般输入地址的格式可能取决于文化。例如,在美国,房号可以在街道前面输入,而在德国则相反,在街道后面输入。
按照一些实施例,借助于符号组分析,首先可以处理符号序列最可信的解释,并这样较快地提供合理的结果。同等地处理所有解释这种一般性做法,尽管可以提供结果,但可能它只在较晚才处理想要的解释,并因此较晚才求出该结果。这从用户的观点看来可能太晚了。
对于北美地区可以按照一些实施例定义并实现一组规则,以便转换符号组分析。接着将对它进行准确描述。在一个实施例中,该规则产生于,在美式风格中的地址房号在前面输入。在进行符号组分析时可以确定,据此应该用符号序列可能是城市或街道等的符号组进行搜索。这时,给出多个可以分配给符号组的信息类别。
信息类别“国家”可以意味着该符号组可能指的是国家。信息类别“州”可以意味着,该符号组可能指的是(联邦)州。信息类别“城市”可以意味着,该符号组可能指的是城市。信息类别“街道”可以意味着,该符号组可能指的是街道。信息类别“十字路口”可以意味着,该符号组可能指的是十字路口。信息类别“房号”可以意味着,该符号组可能指的是房号。信息类别“邮政编码”可以意味着,该符号组指的是可能是邮政编码。信息类别“与操作符”可以意味着,该符号组指的是逻辑与的逻辑关系。信息类别“IN-操作符”可以意味着,该符号组指的是位置前置词,例如,指的是单词“in(在)”。信息类别“NAHE-操作符”可以意味着,该符号组指的是位置前置词,例如,单词“nahe(接近,附近)”(英语near)或“bei(在附近)”(英语around(在附近)。信息类别“INNENSTADT-操作符”可以意味着,该符号组指的是“downtown(商业区)”的概念。
符号序列:“500 clipper dr belmont”的分析结果;例如,可以是房号(500)街道(clipper)街道(dr)城市(belmont)。但分析可能提供任意多个结果。十字路口可以相应地用“bettina ave and thurm ave”搜索,其中第一可能的解释可以是“街道(bettina)街道(ave)与操作符(and)十字路口(thurm)十字路口(ave)”。为了可以特定地在城市中进行搜索,给出IN操作符。这时“clipper dr in belmont”可以相应地解释为街道(clipper)街道(dr)IN操作符(in)城市(belmont)。类似地还可以在城市附近进行搜索。“clipper dr near belmont”可以相应地解释为“街道(clipper)街道(dr)Nahe-操作符(near)城市(belmont)”。为了明确搜索城市,可以采用INNENSTADT-操作符。“downtown los angeles”变为“INNENSTADT操作符(downtown)城市(los)城市(angeles)”。
该规定可以具有至少三个区域。这些区域包括可能性分析、概率分析和排序。这时,可能性分析可以求出符号组的哪一个结合是基本上可能的。这可以在图1所示的装置100上借助于分配模块102进行。
图3表示按照详细的实施例的装置100。在图1中有对应关系的组件,这里不是赘述,而只讨论差异。这时,已经与图1一起使用的缩写有效。此外,虚线框代表任选地存在的组件。
该概率分析可以针对可能的符号组结合在考虑内容的情况下确定概率(或当不可能时为0)。另外,为此装置100还可以包括检验模块108,它构造成,对于将该符号组或另外的符号组分配给第一或第二信息类别的正确性确定各自的概率值。这时例如,该概率值可以是最高包括三个要素的数值量的要素。这时,该概率值各自涉及各符号组,并例如,可以采取“极为可能”(或英语“complete match(完全匹配)”代表准确对应,“不大可能”和任选的还采取“不可能”的数值或作为替代取相应的数值。该分配的正确性可以从用户观点定义,并与用户的意图相应。概率值的确定可以根据基于逻辑规则机构进行。
在一些实施例中,装置100还可以包括评估模块110,构造成在考虑将该符号组分配给该信息类别的情况下确定该符号序列作为导航目标可能的解释。这里考虑该符号序列的所有符号组全部。为此可以出现较多的可能的解释。评估模块110在一些实施例中还构造成,在考虑至少将该符号组分配给该信息类别正确性的概率值的情况下,针对该符号序列可能的解释确定总概率值。该总概率值还可以涉及该整个符号序列解释的正确性。另外,该评估模块110在一些实施例中还包括排序模块112,它构造成根据总概率值为该符号序列第一可能的解释和该符号序列第二可能的解释提供排列顺序,或换句话说,排序。该排序可以给其余剩下的符号组结合确定优先级,这时它们可以按算出的顺序中由该策略进行测试。这时,例如,对于可能的解释该总概率值可以根据在该符号序列内符号组的分配多频繁地由评估模块110估计为“极为可能”,或者该分配多频繁地估计为“不大可能”而算出。这时,可以任选地抛弃估计为“不可能”的分配的解释。此外,检验模块108、评估模块110和排序模块112可以形成为在结构上分离,但电气上连接的组件,但也可以由共同的硬件组件,例如,处理器或集成电路包括。
在可能性分析的范围内,分析哪一个信息类别分配是基本上是可能的。这时,可以彼此考虑信息类别的比率,但可能还没有考虑信息类别的内容。图4表示关于几个可以按照预先给定的规则进行的示例性逻辑运算的总览。可能性分析可以考虑这样的规则,并可以通过分配模块102进行。另外,这时,在一些实施例中,该分配模块还构造成,使另外的符号组,只有当该符号组分配给来自信息类别第二子集的第一信息类别时,才分配信息类别的第一子集中的第二信息类别。换句话说,确定的信息类别只与确定的另外的信息类别结合,或当另外的信息类别已经分配给该符号序列的另外的符号组时,才出现。
在一些实施例中,该分配模块102还构造成,只有当该符号组直接处于该符号序列内另外的符号组前面时,另外的符号组才分配给信息类别第一子集的第二信息类别。换句话说,只有当紧靠在前面的符号组已经分配给确定另外的信息类别时,才分配给确定的信息类别。
在一些实施例中,该分配模块102还构造成,只有当包括该第二信息类别的信息类别第一子集不同于分配给该符号组的第一信息类别所包括的第二子集时,才将该另外的符号组分配给第二信息类别。这一方面可以意味着,几个信息类别的先决条件可以是缺失确定另外的信息类别。另一方面,几个信息类别可以以存在确定另外的信息类别为先决条件。此外,这可以意味着,该确定的信息类别每个符号序列只可以出现一次。
在一些实施例中,分配模块102还构造成,只有当该符号组包括该符号序列的开始符号,或排除该符号序列的结束符号时,才将该符号组分配给该第一信息类别。换句话说,几个信息类别只可以出现在该符号序列的第一位置上或至少不出现在后面的位置。
换句话说再一次可以解释,在将信息类别分配给符号组时,该符号组在该符号序列中的位置或分配给另外的符号组的信息类别具有影响。这导致可能性分析用的几个具体的规则示例。
例如,在该符号序列的开始处,只可以出现“城市”、“街道”、“邮政编码”、“房号”和INNENSTADT操作符。当该符号序列有一个以上的符号组时,在第一位置上还可以出现“州”和“国家”。
例如,每个符号序列最多只可以给出将“街道”符号组与“十字路口”符号组分开的与操作符。“房号”符号组和INNENSTADT操作符不可以出现在带有与操作符的结果中。与操作符不可以是符号序列最后的符号组。
当例如,在结果中仍旧没有给出IN-操作符时,其前面没有NAHE-操作符、“州”、“国家”或INNENSTADT-操作符。这时,第一操作符出现在“城市”、“邮政编码”、“街道”或“十字路口”之后。IN-操作符不可以是符号序列最后的符号组。
当例如,在结果中已经给出准确的IN-操作符时,在第二前面不可以出现NAHE-操作符、“州”、“国家”、或INNENSTADT-操作符。该第二IN-操作符出现在“城市”或“邮政编码”之后,并不可以是符号序列最后的符号组。
例如,不可能有两个以上的IN操作符。
例如,INNENSTADT-操作符只可以作为符号序列的第一或最后的符号组出现,而且在其前面只可以出现“城市”、“邮政编码”、“州”和“国家”。每个结果最多只可以给出INNENSTADT-操作符。
例如,在NAHE-操作符前面只可以出现“房号”、“街道”、与操作符或“十字路口”。NAHE-操作符的紧前面出现“街道”或“十字路口”。每个结果最多只有NAHE操作符。NAHE-操作符不可以是符号序列最后的符号组。
例如“街道”只出现的符号序列的开始,“房号”或另外的“街道”后面。“街道”不可以与INNENSTADT-操作符一起出现。
例如“十字路口”只可以出现在与操作符之后或另外的“十字路口”之后。“十字路口”不可以与INNENSTADT-操作符一起出现。
当例如,在该符号序列仍无IN-操作符给出时,“城市”可以出现在NAHE-操作符、INNENSTADT-操作符、“街道”、“十字路口”、“邮政编码”、“城市”、“州”或“国家”之后。
当例如,至今在该符号序列中给出准确一个IN操作符时,当在这个IN-操作符之前仍旧不给出“城市”符号组或“邮政编码”符号组时,只允许“城市”。
当例如,在该符号序列中至今给出准确两个IN-操作符时,不可能是“城市”。
当例如,至今在该符号序列中仍未给出IN-操作符时,“邮政编码”可以出现在NAHE-操作符、INNENSTADT-操作符、“街道”、“十字路口”、“城市”、“州”或“国家”之后。
当例如至今在该符号序列中给出准确一个IN-操作符时,只有当在这个IN-操作符之前仍不给出“城市”符号组或“邮政编码”符号组时,才允许是“邮政编码”。
当例如,在该符号序列中至今给出准确两个IN-操作符时,不可能有“邮政编码”。
例如,在该符号序列中最多只可以给出一个“邮政编码”符号组。
例如,“州”只允许在IN-操作符、NAHE-操作符、“街道”、“十字路口”、“城市”、“邮政编码”或“国家”之后。每个符号序列最多只可以给出一个“州”。
例如,“国家”只允许出现在IN-操作符、NAHE-操作符、“街道”、“十字路口”、“城市”、“邮政编码”或“州”之后。每个符号序列最多只应该给出一个“国家”。
例如,只有当给出至少一个“街道”符号组、“城市”符号组或“邮政编码”符号组时,才允许有“州”和“国家”。
例如,“房号”只可以作为第一符号组,而且不允许与INNENSTADT-操作符结合。
可以在可能的结果上进行概率分析,通过它可以在其概率上估计该结果。为此,在每个符号组中可以设置“不大可能”标记,以便指出所分配的信息类别是不大可能的。作为替代方案,还可以设有权重为0的结合,可以使得整个结果(该符号序列的整个解释)成为不可能。此外,可以将符号组标记为完全匹配(例如,对于“Los Angeles CA USA”的“la”)。规则可以掌管州的缩写清单或州名清单(“CA=California″,“TX=Texas″,“FL=Florida″等)、国名(“CAN=Canada″,“MEX=Mexico″等),街名前缀(“W=West(西)″,“N=North(北)″,“SE=Southeast(东南)″等)和街名附加语(“ave=Avenue(大道)″,“blvd=Boulevard(林荫大道)″,“st=Street(街)″,“rd=Road(路)″等),以便于分析。
正如图3已经表示的,在一些实施例中,检验模块108还构造成,根据该符号组的一个或多个标记的数目、类型或同一性,为该符号组分配的正确性确定概率值。例如,该类型可以涉及“字母”、“数字”或“特殊符号”一组。以此,例如,考虑5位邮政编码的格式,或确定信息类别的最小长度,可以用于概率分析。一个或多个标记的同一性可以意味着,例如,对于信息类别,只允许确定的文字,例如,对于IN-操作符的单词“in”。
在一些实施例中,检验模块108还构造成,在考虑分配给第一符号组的第一信息类别的情况下,为另外的符号组分配的正确性确定概率值。例如,确定类型的信息类别,出现越频繁,越不太可能。或还可以从哪一种信息类别类型还存在于该符号序列中给出概率,。
在一些实施例中,该检验模块还构造成,在考虑该符号序列内该符号组相对于另外的符号组的位置和信息类别和另外的信息类别的情况下,为另外的符号组分配的正确性确定概率值。例如,该概率值可以取决于该另外的符号组和该符号组是否直接相邻。“直接相邻”可以意味着,两个相关目标之间不出现同一类型的另外的目标。例如,这样可以考虑顺序,例如,按该顺序街道名称处于街道后缀的前面,或在街道前缀的后面。这再次为概率分析得出几个具体的规则示例。
例如,“州”符号组,当它们不对应于街道缩写中的名称或缩写时,可以是不可能的。
例如,“国家”-符号组,当它们不对应于国家缩写中的名称或缩写时,可以是不可能的。
例如,IN-操作符符号组,当它们不对应于In-操作符的输入(字符串)(例如,单词“in”)时,是不可能的。
例如,NAHE-操作符符号组,当它们对于NAHE-操作符不对应于输入(例如,文字“near”(接近)和“around”(在周围)时,是不可能的。
例如,UND-操作符符号组,当它们不对应UND-与操作符输入(“and”、“@”、“&”、“+”、“xts”)时,是不可能的。
例如,INNENSTADT-操作符符号组,当它们不对应于INNENSTADT-操作符的输入(单词“downtown”)时,是不可能的。
例如,“邮政编码”符号组,当它们不具有邮政编码格式(五位数目和加拿大的“Forward Sortation Area(前向排序区)”格式)时,是不可能的。
例如,“房号”符号组,当它们不具有房号可以具有的格式(带有字母作为后缀,例如,“500”、“500a”、“500 1/2”、“500-1001”)数值的和字母数字房号)的尺寸时,是不可能的。
例如,“街道”在“街名前缀”之前和“街道后缀”之后,可以标记为不大可能。
例如,当该符号组是“街名前缀”或“街道后缀”,直接放在“街道后缀”之前或直接在“街名前缀”之后,或出现在“街名前缀”和“街道后缀”之间的任何位置时,“城市”标记为不大可能。
例如,当符号组也可以是房号时,“街道”和“城市”是不大可能的。
例如,当该符号组也可以是“邮政编码”时,“街道”、“城市”和“十字路口”是不可能的。
例如,当该符号组也可以是INNENSTADT-操作符时,“街道”和“城市”是不大可能的。
例如当该符号组是改写的与操作符(“@”、“&”、“+”、“xts”)时,“街道”和“城市”是不可能的。
例如,全名的“州”(“california”而不是“ca”)可以是不大可能的。
例如,全名的“国家”(“mexico”而不是“mex”)可以是不大可能的。
例如,“街道”符号组或“十字路口”符号组带有全名的“街道前缀”(“first”而不是“1st”)可以是不大可能的。
例如,“街道”符号组或“十字路口”符号组带有全写的“街道后缀”(“street”而不是“st”)可以是不大可能的。
例如,分配给完全确定的城市(例如,“la”或“sf”)的“城市”符号组可以标记为极为可能(完全匹配)。
例如,当结果只具有“城市”符号组,但不具有“州”或“国家”,和该“城市”符号组少于三个字母时,作为“城市”符号组的分配给可以标记为不大可能。
当结果具有最多两个全是“城市”符号组的符号组时,例如,所有“城市”符号组可以是不大可能的。
例如,当结果具有三个以上的“街道”符号组时,可以所有“街道”符号组超过1/3是不大可能的。
例如,当结果有三个以上“十字路口”符号组时,全是“十字路口”符号组超过1/3是不大可能的。
例如,当结果包含“州”符号组或“国家”符号组,但没有其他城市限定的符号组(“城市”或“邮政编码”)时,该符号组可以是不大可能的。
可能性分析和概率分析结束之后,对剩余或可能的结果排序。这时,可以使用下列示例性规则。
标记不可能概率较小的结果,可以排序排在标记不可能概率较大的结果之前。
完全匹配概率较大的结果可以排序排在完全匹配概率较小的结果前面。
只有符号组时“邮政编码”可以排序排在“房号”之前。
操作符(UND(和)、IN(在内)和NAHE(接近))较多的结果可以排序排在操作符分类较少的结果之前。
带有“城市”符号组或“邮政编码”符号组的结果,可以在排序排在具有“州”和“国家”,但是不具有“城市”符号组或“邮政编码”符号组的结果之前。
城市限定的符号组(“城市”的、“邮政编码”的、“州”的和“国家”的符号组)的数目不同时,“街道”符号组较多的该结果进一步排在前面。
在城市限定的符号组同样多时,州限定符号组(“州”和“国家”)较多的结果进一步排在前面。
在州限定符号组数目相同时,其“城市”符号组(“城市”符号组和“邮政编码”符号组)总数较大的结果往前排,。
在城市时符号组数目相同时,“街道”符号组较多的结果可以进一步往前排。
实施例的上面已经列出的第三部分观点,除了数据库表和符号组分析以外,可以是搜索策略。通过搜索策略力求将符号组分析结果转换为数据库表和其余的NDS-数据库的查询,在给定情况下后处理和汇集,或还与来自其他来源的结果结合,并公布该结果。这时,该搜索策略,例如,在北美地区设计。但是任选地还适应其他地区。
类似于符号组分析的规则,该搜索策略可以取决于所采用的文化或语言。参照搜索策略的例子,可以实现北美用的下列规则:
该变化过程的结果可以在来自在符号组分析的基础上实际搜索的结果之前公布。
该符号序列在递送给符号组分析之前标准化。例如,这可以意味着,清除该符号序列之前和之后空白符号,符号组之间多个空白符号汇集成唯一的空白符号,清除不必要的标点符号,或该符号序列完全转换为小写字母。这些措施可以使进一步处理变得容易。
符号组分析的结果可以处理成预先给定的顺序。
当要处理的分析结果不包含城市限定的符号组(“城市”、“邮政编码”、“州”、“国家”)时,可以进行周围搜索。为此可以通过数据库表按照输入的地址搜索处于当时汽车位置周围的城市。若该结果包含城市限定的符号组,则可以利用这一点,以便从数据库表加载与此相适应的城市,并在其中搜索输入的地址。
完全相符地适合符号组的结果,可以优先于部分相符的结果,因此首先公布。例如,符号组“clip”与街道“Clip Dr”完全相符,但是对于该街道“Clipper Dr”只是部分地相符。
当在同一城市内城市搜索或街道搜索给出多个结果时,则这些结果可以按一致质量排序。这时,可以考虑,该结果对于该符号组是否完全或部分地相符,是否在该结果中所有单词都与符号组一致,和在该符号序列中是否以该符号组在本身顺序上正如在结果一样地出现。若一致质量相同,则该结果在城市搜索时按到汽车位置的距离升序排序公布。
若在周围搜索时应该处理偶然适合该符号序列的结果的城市,则该城市也可以公布。以此可以用首先作为街道解释的分析结果,在该周围搜索期间“半路”在附近还发现城市。
当在街道中没有发现房号时,它虽然可以公布,但带上房号不存在的标记。以此可以尽管房号错误,该结果还是近似地用于路由计算。
结果中的邮政编码,只有当它对于用户乃有剩余价值时,才可以公布。当他已经将其输入时,或当它们可以用来在同一城市区别同名街道时,才可能如此。
当地址具有多个要指示的邮政编码(例如,在非常长的街道上)时,可以对邮政编码清单进行升序排序,并以“从(最低数目)到(最高数目)”的格式公布。在给定情况下,这可以防止在显示器上不必要的浪费位置。
处理完符号组分析的所有结果之后,只要合理仍旧可以进行模糊搜索。这时,可以对限定城市的符号组(“城市”、“邮政编码”、“州”、“国家”)进行模糊观察,方法是其中在适当的城市四周对要寻找的城市进行更多的搜索(“街道”、“房号”、“十字路口”)。用这种方式方法它可以是可能的,例如,临近位置中找到街道,尽管该用户实际上输入了错误的城市。
此外现将根据具体的应用更详细地描述一些实施例。这些实施例所基于的符号序列的符号组分析(标记实体分析)所用的概念和所使用的规则与上述一致。
根据第一实施例,再次详细的阐述周围搜索、基于所存储的数据库的城市限定的搜索和符号组分析的应用。用户在其汽车上,在Clipper Drive,Belmont,CA(Kalifornien),USA(美国,加利福尼亚,Belmont,Clipper大道)在房号500前的街道上(经度:-122.271699,纬度:37.533058)。他想去往Arlington Road,Redwood City,CA,USA(美国,加州,红树城,Arlington路)房号611。为此他在与该装置耦合的给定装置上作为单列目标给定输入“611Arlington Rd”。
该符号组分析可以按照上述规则进行,并得出包括多个可能的解释的结果:
第一解释叫做“房号(611)街道(arlington)街道(rd)”。
第二解释叫做“房号(611)街道(arlington)城市(rd)”。
第三解释叫做“-街道(611)街道(arlington)街道(rd)”。
第四解释叫做“-街道(611)街道(arlington)-城市(rd)”。
第五解释叫做“-街道(611)-城市(arlington)-城市(rd)”。
第六解释叫做“-城市(611)-城市(arlington)-城市(rd)”。
该搜索策略现在可以依次按这里列出的顺序,对应地搜紊该符号组分析结果。
因为按照第一解释“房号(611)街道(arlington)街道(rd)”的分析结果不包含城市限定的符号组,故可以启动周围搜索。该搜索策略可以为此从数据库表(城市索引)求出围绕当时汽车的位置周围150km的城市,按照到汽车位置的距离的升序排序。这些城市,例如,包括Belmont,San Carlos,San Mateo,Redwood City和245个其他城市。现在可以在249个城市中的每一个依次搜索“Arlington Rd”。在Belmont,San Carlos和San Mateo没有给出这样街道,在Redwood City找到了它。这时,在该街道上可以搜索房号611,同样找到了。因为现在使用了所有符号组,故找到了合理的结果,并可以公布。借此找到了想要的结果。该周围搜索可以用其余的245个城市继续进行,其中允许找到适当的地址Livermoore,Concord,Stockton,Hollister和WestScramento,并同样可以公布。
因为按照第二解释“房号(611)街道(arlington)-城市(rd)”该分析结果包含城市限定的符号组,故该搜索策略可以借助于该数据库表求出所有适合“rd”的城市。这是在墨西哥5市区。这个城市可以以“arlington”搜索街道,但是其中没有找到适当的结果。因为该符号组仍旧没有与此相符的,所以该符号序列的这个解释没有生产合理的结果。
因为按照第三解释“街道(611)街道(arlington)街道(rd)”的分析结果再次不包含城市限定的符号组,故可以再次启动周围搜索,可以搜索这249个城市按照其名称为“611arlington rd”查找街道。因为在这些城市没有给出这样的街道,故该符号序列的解释仍旧没有结果。
在第四解释“-街道(611)街道(arlington)-城市(rd)”上它再次给出城市限定的符号组。可以借助于该数据库表,重新求出所有适合“rd”的城市。这时可以搜索上述的墨西哥5市区找适合“611arlington”的街道。这个搜索仍旧不成功,因此这个解释没有产生合理的结果。
在第五解释“-街道(611)-城市(arlington)-城市(rd)”上,该策略可以在该城市限定的符号组的基础上,借助于数据库表搜索适合“arlington rd”的城市。在北美没有给出这样的城市,由此该符号序列的这个解释仍旧没有结果。
在第六解释“城市(611)-城市(arlington)-城市(rd)”上,该策略可以在城市限定的符号组的基础上,借助于该数据库表,搜索适合“611arlington rd”的城市。在北美没有给出这样的城市,因此该符号序列的这个解释仍旧没有结果。
第二实施例与上述实施例有类似的基本前提,用户只给出希望的其他地址和没有规定房号。据此可以演示用户输入对符号组分析的影响和借此对直至得出要求结果的等待时间的影响。
该用户在其汽车上处于Clipper Drive,Belmont,CA,USA(美国,加州,Belmont,Clipper大道)房号500前的街道上(经度:122.271699,纬度:37.533058)。他想去往Arlington Road,Redwood City,CA.。为此他在该单列目标给定中给出“arlington redwood”。
该符号组分析可以按照上述规则进行,并得出包括多个可能的解释的结果:
第一解释叫做“街道(arlington)街道(redwood)”。
第二解释叫做“街道(arlington)城市(redwood)”。
第三解释叫做“城市(arlington)城市(redwood)”。
现在该搜索策略可以按预先给定的顺序处理该分析结果。
因为按照第一解释“街道(arlington)街道(redwood)”的分析结果不包含城市限定的符号组,故可以启动周围搜索。该策略可以借助于城市索引,求出围绕汽车位置周围150公里的所有城市,按照到汽车位置的距离升序排序。例如,这有249个城市。这可以依次搜索适合“arlington redwood”的街道。没有给出这样的街道,因此按照该符号序列的这种解释搜索没有结果。
在第二解释“街道(arlington)城市(redwood)”中,该策略可以借助于该数据库表,求出所有适合“redwood”的城市,按照到汽车位置的距离升序排序。例如,在美国和加拿大,这有6个城市。现在可以搜索这些城市寻找适合“arlington”的街道。以此在Redwood City,CA,USA可以找到Arlington Rd,并作为结果公布。其他城市不包括适当的街道。
在进行第三解释“城市(arlington)城市(redwood)”时,该策略可以借助于该数据库表,搜索适合“arlington redwood”的城市。在北美没有给出这样的城市,因此按照这种解释搜索没有结果。
因为符号组分析也许没有区分街道和城市符号组的线索,但是可以由此开始,只输入相对罕见的城市符号组,因为,例如,大部分行驶发生在周围150公里的范围内,与城市符号组相比,可以更推荐街道符号组。在该用户实际上给出城市的一种情况下,导致虽然借助于第二解释可以找到结果,但以此在给定情况下只比理想可能更靠后。
第三实施例有类似于第二实施例的基本前提,只是用户给出另外的希望的地址。据此可以演示该用户的输入对该符号组分析的影响,和借此对直至要求的结果的等待时间的影响。
用户在其汽车上,处于Clipper Drive,Belmont,CA,USA(美国,加州,Belmont,Clipper大道)在房号500前的街道上(经度:-122.271699,纬度:37.533058)。他想去往Arlington Road,Redwood City,CA.。为此他在该单列目标给定中给出“arlington rd redwood”。
可以按照上述规则进行该符号组分析,并得出包括多个可能的解释的结果:
第一解释叫做“街道(arlington)街道(rd)城市(redwood)”。
第二解释叫做“街道(arlington)街道(rd)-街道(redwood)”。
第三解释叫做“街道(arlington)-城市(rd)城市(redwood)”。
第四解释叫做“-城市(arlington)-城市(rd)城市(redwood)”。
现在该搜索策略可以根据该符号组分析结果,依次按这里列出的顺序进行搜索。
因为按照第一解释“街道(arlington)街道(rd)城市(redwood)”存在城市限定的符号组,所以该搜索策略可以借助于该数据库表,搜索所有适合“redwood”的城市,按照到汽车位置的距离升序排序。例如,在北美这有6个城市。这可以依次搜索适合“arlington rd”的街道。只有在Redwood City,CA,USA才找到这样的街道并公布。借此找到了想要的结果。
因为该第二解释“街道(arlington)街道(rd)-街道(redwood)”不包含城市限定的符号组,故可以启动周围搜索。为此该策略借助于该数据库表,围绕该汽车位置,例如,在周围150公里求出所有城市,按照到汽车位置的距离升序排序。这可以依次搜索适合“arlington rd redwood”的街道。因为在这些城市中不存在这样的街道,所以按照该符号序列的这种解释搜索仍旧没有结果。
在进行该第三解释“街道(arlington)-城市(rd)城市(redwood)”时,该策略可以借助于该数据库表,搜索适合“rd redwood”的城市。在北美没有给出这样的城市,因此按照这种解释搜索没有结果。
在进行该第四解释“城市(arlington)-城市(rd)城市(redwood)”时,该策略可以借助于该数据库表,搜索适合“arlington rd redwood”的城市。在北美没有给出这样的城市,因此按照这种解释搜索没有结果。
通过应用缩写“rd”,这由符号组分析初步可以解释为街道潜在的最后的符号组,该用户可以使识别其意图成为可能。因此不同于实施例2,该第一解释已经产生这样希望的结果。
参照第四实施例说明,该搜索可以按照十字路口进行。该用户在其汽车上,处于Clipper Drive,Belmont,CA,USA(美国,加州,Belmont,Clipper大道)在房号500前的街道上(经度:-122.271699,纬度:37.533058)。他想去往同一城市的Bettina Ave和Thurm Ave(大路)之间的十字路口。为此他在该单列目标给定中给出“bettina and thurm”。
该符号组分析可以按照上述规则进行,并得出包括多个可能的解释的结果:
第一解释叫做“街道(bettina)与操作符(and)十字路口(thurm)”。
第二解释叫做“街道(bettina)街道(and)街道(thurm)”。
第三解释叫做“街道(bettina)街道(and)城市(thurm)”。
第四解释叫做“街道(bettina)城市(and)城市(thurm)”。
第五解释叫做“城市(bettina)城市(and)城市(thurm)”。
现在该搜索策略可以根据该符号组分析结果依次按这里列出的顺序进行搜索。
因为在该第一解释“街道(bettina)与操作符(and)十字路口(thurm)”中没有给出城市限定的符号组,故可以启动周围搜索。为此该策略可以借助于数据库表,例如,围绕该汽车位置周围150公里求出所有城市,按照到汽车位置的距离升序排序。这些城市可以依次搜索适合“bettina”的街道。若找到这样的街道,则它们可以按照适合“thurm”的十字路口搜索,因为与操作符表明要按照十字路口搜索。在Belmont找到这样的十字路口,并可以将其作为合理的结果公布。在所有其他周围城市没有找到这样的十字路口。
因为在第二解释“街道(bettina)街道(and)街道(thurm)”中没有给出城市限定的符号组,故可以启动周围搜索。为此该策略可以借助于数据库表,例如,围绕该汽车位置周围150公里求出所有城市,按照到汽车位置的距离升序排序。这些城市可以依次搜索适合“bettina and thurm”的街道。这些城市都没有给出这样的街道,因此按照该符号序列的这种解释搜索没有结果。
在第三解释“街道(bettina)街道(and)城市(thurm)”中,该搜索策略可以借助于该数据库表,求出所有适合“thurm”的城市,按照到汽车位置的距离升序排序。例如,在北美这有10个城市和市区。这可以依次搜索适合“bettina and”的街道。因为在这些城市中不存在这样的街道,所以按照该符号序列的这种解释搜索没有结果。
在按照第四解释“街道(bettina)城市(and)城市(thurm)”处理该分析结果时,该搜索策略可以借助于该数据库表,求出所有适合“andthurm”的城市。因为在北美不存在这样的城市,所以按照该符号序列的这种解释搜索没有结果。
在第五解释“城市(bettina)城市(and)城市(thurm)”中,该搜索策略可以借助于该数据库表,求出所有适合“bettina and thurm”的城市。因为在北美不存在这样的城市,所以按照该符号序列的这种解释搜索没有结果。
根据第五实施例可以说明按照城市搜索。该用户在其汽车上,处于Clipper Drive,Belmont,CA,USA在房号500前的街道上(经度:-122.271699,纬度:37.533058)。他想去往Miami,FL,USA(美国,弗罗里达州,迈亚密)。为此他在该单列目标给定中给出“miami fl”。
该符号组分析可以按照上述规则进行,并得出包括多个可能的解释的结果:
第一解释叫做“城市(miami)州(fl)”。
第二解释叫做“街道(miami)街道(fl)”。
第三解释叫做“街道(miami)城市(fl)”。
第四解释叫做“街道(miami)-州(fl)”。
第五解释叫做“-城市(miami)-城市(fl)”。
现在该搜索策略可以根据该符号组分析结果依次按这里列出的顺序进行搜索。
因为在该第一解释“城市(miami)州(fl)”中存在城市限定的符号组,故该搜索策略可以求出所有处于Florida(佛罗里达),其州为“fl”,而其名称为“miami”的城市。例如,这有11个城市和市区。这在该公布之前仍旧可以按一致质量排序。下面该希望的“Miami,FL,USA”由于最优的一致质量,可以作为第一结果公布。
在第二解释“街道(miami)街道(fl)”中由于缺少城市限定的符号组,可以启动周围搜索。为此该策略可以求出,例如,周围150公里的所有城市,按照到汽车位置的距离升序排序。可以按照其名称适合“miami fl”的街道序列搜索这些城市。因为在这些城市中不存在这样的街道,所以按照该符号序列的这种解释搜索没有结果。
在该第三解释“街道(miami)城市(fl)”中,该策略可以借助于该数据库表,搜索其名称适合“fl”的城市,按照到汽车位置的距离升序排序。这可以按此搜索其名称为“miami”的街道。例如,在美国和墨西哥这有6个街道。这作为合理的结果公布。
在第四解释“街道(miami)-州(fl)”中,该策略可以求出所有处于佛罗里达,其州为“fl”的城市,按照到汽车位置的距离升序排序。这可以依次搜索其名称为“miami”的街道。这有大量街道,它们全都作为合理的结果公布。
在第五解释“-城市(miami)-城市(fl)”中,该搜索策略可以借助于该数据库表求出所有其名称适合“fl”的城市。因为在北美不存在这样的城市,所以按照该符号序列的这种解释搜索没有结果。
图5表示将导航目标分配给包括多个符号组的符号序列的方法300。方法300包括进行310将至少一个符号组分配给来自多个信息类别中的第一信息类别,以便解释该符号序列。为此,方法300包括为多个城市提供310各自多个唯一地分配给城市的不同信息类别的特征。此外,方法300还包括当该符号组对应于分配给该所选择的城市的第一信息类别的特征时,从多个城市选择330所选择的城市。此外,方法300还包括只有当对于该城市的该第二信息类别分配给与各符号组相应的特征时,才在所选择的城市下进行340将来自该符号序列的另外的符号组分配给第二信息类别。
实施例有可能可以在周围搜索全局的城市清单,这按照到当前位置的距离排序,并顺序地处理这些城市,以便尽管目的平台可能效率有限,但仍在缩短的时间内提供第一和极为可能的结果。通过该符号序列的符号组分析在给定情况下可以赋予极为可能的解决方案较高的优先级,并迅速地提供极为可能的结果。
实施例可以在汽车中应用的情况下和地址搜索中同样地优化。实施例为此可以考虑人的一般输入行为和这样事实,即人们在汽车中每次行驶通常只经过确定的距离。这时,用户可以与汽车一起处在给出的位置上,而且在物理上向所找到的地点移动。反之传统的解决方案定向于,在整个世界上同样地寻找地址(和其他目标),因为该主要目标可能并不一定在物理上达到所找到的目标。然而,这些解决方案可能使移动应用情况改善更加困难。此外,该方法或该装置的实施例潜在地可以应用于输入地址的其他应用情况,其中人们想要在物理上从其当前的位置向所找到的地址移动,因此,例如,骑自行车、步行、坐火车、坐公共汽车或轨道车辆或者还用于可移动的仪器。
在以上的描述、后面的权利要求和附图所公开的特征,不仅可以单独地,而且可以任意结合,以便在其不同的配置下实施实施例是有意义的并加以实现。
尽管一些方面是与装置一起描述的,但应理解这些方面也是对相应方法的描述,使得装置的方框或元件,也应理解为相应的工艺步骤或作为方法步骤的特征。与此类似地,与工艺步骤或作为工艺步骤一起描述的方面,也是对相应装置的相应方框或细节或特征的描述。
视所确定的实施要求而定,本发明的实施例可以用硬件或软件实现。该实现可以在应用数字存储介质,例如软盘、DVD、蓝光盘、CD、ROM、PROM、EPROM、EEPROM或闪存、硬盘或其他磁学或光学储存器的情况下进行,其上存储电子可读的控制信号,它可以与或与可编程硬件组件这样地共同作用,执行各该方法。
可编程硬件组件可以用处理器、计算机处理器(CPU=Central Processing Unit(中央处理单元))、图形处理器(GPU=Graphics Processing Unit(图形处理单元))、计算机、计算机系统、专用集成电路(ASIC=Application-Specific integrated circuit(专用集成电路))、集成电路(IC=integrated circuit(集成电路))、单芯片系统(SOC=System an Chip(芯片上的系统))、可编程逻辑器件或带有微处理器的现场可编程门阵列(FPGA=Field Programmable Gate Array))形成。
因此,该数字存储介质可以是机器可读的或计算机可读的。因此一些实施例还包括具有电子可读的控制信号的信息载体,它能够与可编程计算机系统或可编程硬件组件共同作用,以执行这里描述的方法。实施例以此是信息载体(或数字存储介质或计算机可读介质),其上记录了执行这里描述的方法用的程序。
一般地说该实施例可以实现为带有程序代码或作为数据的程序、固件、计算机程序或计算机程序产品,其中当该程序在处理器或可编程硬件组件上运行时,该程序代码或该数据能有效地执行该方法。该程序代码或该数据还可以,例如,存储在机器可读的载体或信息载体上。此外,该程序代码或该数据还可以作为源代码、机器码或字节代码以及作为其他中间码存在。
另外,另外的实施例是代表或描述执行这里描述的方法用的程序的数据流、信号序列或一序列的信号。数据流、信号序列或一序列信号可以,例如,配置得通过数据通信连接,例如,通过互联网或其他网络传输。实施例还是这样代表数据的信号序列,它适宜于通过网络或数据通信连接发送,其中该数据描述该程序。
按照一个实施例,程序在其执行期间可以以此转化为方法,读出该存储位置或在其中写入一个或多个数据,以此在某些情况下在晶体管结构、放大器结构或在其他电学、光学、磁学或按照其他工作原理工作的组件中引起开关过程或或其他过程。相应地可以通过读出存储位置数据,由程序掌控、确定或测量的数值、传感器值或其他信息。因此,程序可以通过读出一个或多个存储位置,掌握,或测量量值、数值、测量参数和其他信息,以及通过在一个或多个存储位置写入,使动作起作用、引起或执行之以及控制其他仪表、机器和组件。
上述实施例只用来阐明本发明的原理。显然,其他技术人员会明白这里描述的安排和细节的修改和改变。因而,本发明有意只受后附权利要求书保护范围的限制,而不受在描述和阐明这些实施例时呈现的特定细节限制。
附图标记列表
100 装置
102 分配模块
104 存储模块
106 选择模块
108 检验模块
110 评估模块
112 排序模块
202 程序开始
204 输入
206 分析
208 第一控制步骤
210 程序结束
212 搜索策略
214 第二控制步骤
216 调出
218 另外的调出
220 另外的搜索
222 第三控制步骤
224 公布
300 方法
310 进行(分配)
320 提供
330 选择
340 进行(分配)
- 还没有人留言评论。精彩留言会获得点赞!