一种并行程序的集合通信函数建模方法与流程
本发明涉及并行程序的集合通信函数建模方法。
背景技术:
并行程序的执行时间分为计算和通信两部分时间,其中计算时间即指令执行时间,通信时间是通信函数的调用时间。研究中指令执行时间通过动态统计指令条数以及各类机器指令的执行时间获得,通信时间是研究的重点。科学程序的并行通常是基于MPI(Message-Passing Interface,MPI)接口实现,MPI定义了可以被程序语言调用的函数库。通过插桩获得通信函数的信息,建立通信函数的时间模型,最终统计得到通信时间。通信函数分为点对点通信和集合通信,通过分析LogGP模型可知点对点通信时间关于通信量是分段线性的,集合通信的通信时间模型是研究重点。
技术实现要素:
本发明的目的是为了解决现有技术对通信时间数据获取不准确、耗费大量时间金钱的缺点,而提出一种并行程序的集合通信函数建模方法。
一种并行程序的集合通信函数建模方法具体过程为:
步骤一、在实验平台下测量集合通信函数N次,获得集合通信函数在不同的并行度和数据量下的通信时间数据;
所述N取值范围为1000-10000;
步骤二、用基于BP反向传播算法的人工神经网络对集合通讯函数在不同的并行度和数据量下的通信时间数据进行拟合,得到相应的通信函数的神经网络模型。
本发明的有益效果为:
将实验数据分为训练集和测试集,其中70%作为训练集,30%作为测试集。多次混合交叉实验,每次实验把输入数据打乱,重新选取训练集和测试集。上述神经网络结构对通信数据的拟合效果如图6、图7、图8和图9所示;采用图6到图9的4个例子验证人工神经网络对不同集合通讯的拟合效果;
拟合结果采用相关系数量化,相关系数是反映变量之间密切程度的统计指标。其中皮尔卡逊相关系数r描述的是两个变量间线性相关的强弱程度,r的范围为[-1,1],当r>0时,两个变量是正相关的。r的绝对值越大,相关性越强。如表2。
表2 相关系数
相关系数能反映数据之间相关关系,用均方根误差(RMSE)量化测量的精密度,如表3。
表3 RMSE
解决了现有技术对通信时间数据获取准确率低、耗费大量时间金钱的缺点,本发明提出一种并行程序的集合通信函数建模方法,提高了通信时间数据获取的准确率,节约了时间和金钱。
附图说明
图1为本发明流程图;
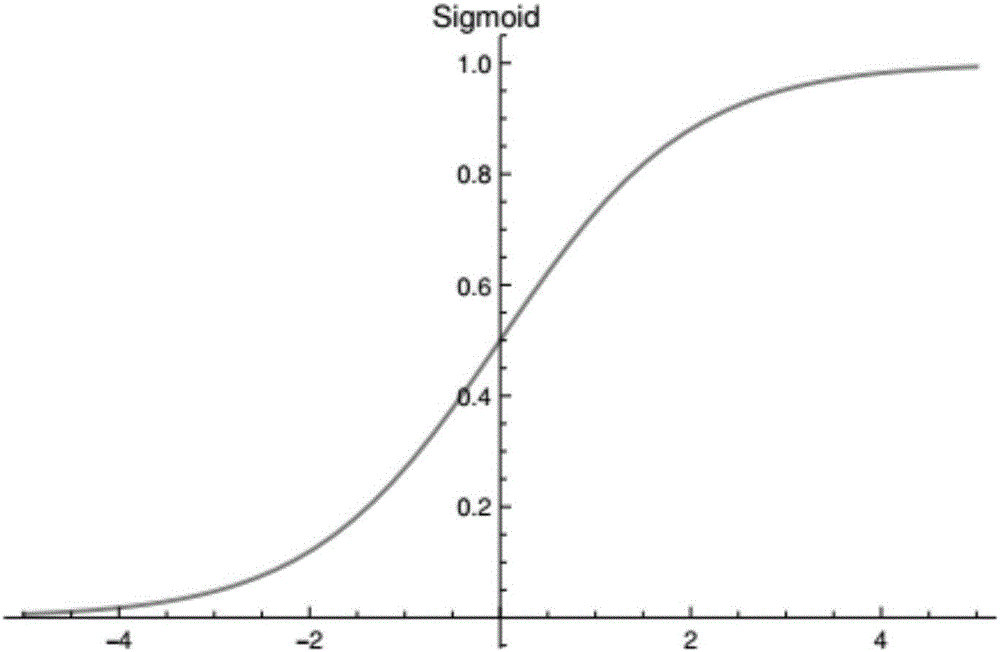
图2为Sigmoid激活函数的函数特性示意图,Sigmoid为一种S型函数,具有S型生长曲线;
图3为Tanh激活函数的函数特性示意图,Tanh为一种双曲正切函数;
图4为Relu激活函数的函数特性示意图,Relu为人工神经网络中一种比较流行的激活函数,它不会随着输入参数的逐渐增加而趋于饱和;
图5为Softplus激活函数的函数特性示意图,Softplus为一种Relu函数的近似平滑函数;
图6为MPI_ALLreduce模型拟合效果效果图,横坐标true value为真实值,纵坐标为Predicted value为预测值,MPI_ALLreduce为全局归约函数;
图7为MPI_reduce模型拟合效果效果图,MPI_reduce为归约函数;
图8为MPI_Bcast模型拟合效果效果图,MPI_Bcast为广播函数;
图9为MPI_Gather模型拟合效果效果图,MPI_Gather为收集函数。
具体实施方式
具体实施方式一:结合图1说明本实施方式,本实施方式的一种并行程序的集合通信函数建模方法具体过程为:
步骤一、在实验平台下测量集合通信函数N次,获得集合通信函数在不同的并行度和数据量下的通信时间数据;
所述N取值范围为1000-10000;
步骤二、用基于BP(Error Back Propagation)反向传播算法的人工神经网络对集合通讯函数在不同的并行度和数据量下的通信时间数据进行拟合,得到相应的通信函数的神经网络模型。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤二中用基于BP(Error Back Propagation)反向传播算法的人工神经网络对集合通讯函数在不同的并行度和数据量下的通信时间数据进行拟合,得到相应的通信函数的神经网络模型;具体过程为:
BP反向传播算法的流程为:
正向传播过程首先接收输入信号,逐层经过各神经元之间的权重以及激活函数作用到达输出层,获得当前迭代后的输出值;
根据误差定义方式计算本轮迭代的误差;
根据一定的规则将误差从输出层反向传播到输入层,并逐层调节权重以减少误差。重复上述过程直到达到迭代次数或误差小于规定精度,训练结束;
BP算法,误差反向传播(Error Back Propagation,BP)算法。BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
给定样本集{(x1,r1),(x2,r2),…(xq,rq)},神经网络模型输出值为y=(y1,y2…yq),神经网络模型参数为W、b,W为权值,b为阈值。
x1、x2、xq为特征值,q为正整数;r1、r2、rq为真实值,y1、y2、yq为神经网络模型输出值;
常见的计算神经网络模型输出值偏离真实值误差大小的表达形式如下:
用l表示层数,其范围为[1,nl],nl表示最终输出层;其中Sl表示第l层神经元个数,表示第l层的第i个神经元的前向输出值,是第l层的第i个神经元的输入值,其中wij为权重值,为第l-1层的第j个神经元的前向输出值;
nl为正整数;1≤i≤Sl;w∈W
残差表示该节点对最终输出值产生的影响;f(z)表示神经元的激活函数;
步骤二一、数据预处理;
步骤二二、激活函数的选择;
步骤二三、根据步骤二一和步骤二二利用BP反向传播算法进行权重和阈值的更新。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤二一中数据预处理;具体过程为:
不同的并行度和数据量下的通信时间数据是在某一并行度下,变化数据量测量的通信时间或者是在某个数据量下,变化并行度测量的通信时间;
不同的并行度和数据量下的通信时间数据是聚集的、不均匀的,这对训练有非常大的影响,因此将不同的并行度和数据量下的通信时间数据传到网络训练之前需要先打乱不同的并行度和数据量下的通信时间数据;
第一个隐藏层的神经元的参数值更新与输入值成比例,如果某一维过大,那么参数更新值就很大,反之,参数更新值小。那么不同特征就被赋予不同的“重要性”。因为通信函数的两个特征的数据范围差距较大,例如并行度的范围是(4,64),数据量的范围是(100,1000000)。对不同的并行度和数据量下的通信时间数据进行归一化,归一化公式如下:
max、min分别指某一维数据中的最大值、最小值,经过归一化,人工神经网络的输入特征的范围为(0,1);x′为归一化后的某一维数据,x为归一化前的某一维数据;
所述某一维为并行度、数据量或通信时间。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤二二中激活函数的选择;具体过程为:实验最初阶段选择常见的Sigmoid激活函数,但效果非常差,出现了不收敛的情况。根据BP算法的推倒可以知道,误差在反向传播时,各层都会乘以激活函数的一阶导数和当前层神经元输入值。Sigmoid函数的导数f′(z)=f(z)(1-f(z)),f′(z)∈(0,1)。神经元的输入值的范围也是(0,1)或者(-1,1)。这样经过每一层误差是成倍衰减的,梯度会不停的衰减直到消失导致网络不能收敛。经过多次实验最终
选择Relu激活函数,因此反向传播中梯度可以很好地流动。
Relu激活函数形式为:
f(z)=max(0,z)
式中,z为Relu激活函数输入值,Relu激活函数梯度为1,并且只有一端饱和。
Softplus可以看做是Relu的平滑版本,除了实现单侧抑制外,Relu函数使神经元具备了稀疏激活性。这种性质意味着该函数只有在深层并且具有多个节点的网络结构中发挥作用。可以选择不同节点线性组合,减少了对非线性映射机制的依赖,网络结构更加灵活。
激活函数将数据范围从一个空间转变到另一个空间来实现非线性。激活函数的串联和并联结构通过改变参数呈现对任意非线性函数的逼近。常见的激活函数有Sigmoid、Tanh、Relu、Softplus等等。
如图2-图5所示为激活函数的函数特性示意图,从上到下,从左到右分别为Sigmoid、Tanh、Relu、Softplus。
Sigmoid函数形式为:
函数输出范围是[0,1]。Sigmoid函数从数学角度上讲,数据过大或过小时该函数值趋于常数,此时函数导数为0。函数作用真正有效的部分是中间区域。类比到人脑的结构,人们往往对忽略事物的大部特征而只保留感兴趣的。因此将重点特征推向中央。
Tanh函数形式为:
函数的输出范围是[-1,1]。Tanh函数在数学角度上看是连续可微分的,数据的作用类似Sigmoid函数,真正有效部分是中间区域。
Softplus函数形式为:
f(z)=log(1+exp(z))
使用指数函数作为激活函数导致梯度过大,因此加上log缓解上升的趋势,加1是保证非负性。从生物学的角度,神经学家认为人脑接收信号后处理更接近Softplus函数。与上述两个函数将输出值固定在某一范围不同的是,该函数将保留一侧数据的兴奋边界,抑制另一侧。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤二三中根据步骤二一和步骤二二利用BP反向传播算法进行权重和阈值的更新;具体步骤如下:
(1)前向传播很简单,用l表示第几层,其范围为[1,2,3,…,nl],nl表示神经网络模型的最终输出层;逐层计算2,3,…nl的激活值,最终可以得到神经网络模型的输出结果,表示为hW,b(x),nl为正整数;;
(2)当l为第nl层时,对nl层的所有神经元中的某一神经元i,首先根据误差公式获得误差,利用误差对第nl层的第i个神经元的输入加权和求偏导:
式中,W为权向量,b为阈值,q是通信函数在不同的并行度和数据量下的通信时间数据中的样本数量,0为正整数;是第nl层的第i个神经元的输入加权和,其中表示第l-1层第j个神经元与第l层第i个神经元之间的权重值,为第l-1层的第j个神经元的前向输出值;表示第l层的第i个神经元的前向输出值;1≤i≤Sl;wij∈W;Sl为第l层的神经元个数,为正整数;l为正整数;Sl-1第l-1层的神经元个数,为正整数;ri为真实值;yi为神经网络模型的输出值;残差δi(l)表示l层的神经元对最终输出值产生的影响;表示神经元的激活函数;
(3)当l=nl-1,nl-2,nl-3,…,2中任一层时,第l层的第i个节点的残差计算方法为
式中,Sl+1为第l+1层的神经元个数,为正整数;为第l层权向量;残差表示l+1层的该神经元对最终输出值产生的影响;1≤j≤Sl;
(4)计算权值和阈值更新需要的偏导数,即
式中,为第l层的第j个神经元的前向输出值;bi(l)为神经网络模型第l层的第i个神经元阈值;
在调节参数的过程中还出现了输入样本对输出没有影响,即无论输入何种样本输出值是一样的。原因是因为权重参数W过大,因此在误差公式后面加上L2正则项
其中,w表示正则项的参数,λ是正则项系数,q是样本数量;L2为高斯先验;对J(W,b)求偏导后,将改为
在W更新时,实际是减去一个正数,导致权重衰减。
在实验过程中参数W、b的更新会乘以学习速率η,以方便调节学习速率避免过大或偏小。引入动量因子ρ,更新权向量W和阈值b,具体公式表示为:
式中,η为学习速率;为更新后的第l层第j个神经元与第l+1层第i个神经元之间的权向量;为更新前第l层第j个神经元与第l+1层第i个神经元之间的权向量;为第l层第j个神经元与第l+1层第i个神经元之间的权向量。
学习率指参数每次更新走多远,若果设置过大,则容易越过最优解或者在最优解附近徘徊,设置过小又会导致收敛时间过长。因此设计模型时动态改变学习率是有必要的。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是:所述正则项系数λ=0.005。
在我们实验过程中,取λ=0.005达到了理想的实验效果。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是:所述ρ设置为0.9。
这样设置的目的是在下降初期,使用前一次的大比重下降方向加速,在越过函数局部最大值时,连续两次更新方向基本相反,此时ρ可以使得更新幅度减小,越过谷面。随着梯度不断下降,优化过程极容易陷入局部最小值,此时梯度为0,此时ρ帮助跳出函数面最低点。如表1,多次实验确定了7层神经网络的结构,根据Relu函数特性确定了各层节点个数。神经网络模型的结构用下表来描述。
表1 神经网络结构示意
其它步骤及参数与具体实施方式一至六之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例一种并行程序的集合通信函数建模方法具体是按照以下步骤制备的:
将实验数据分为训练集和测试集,其中70%作为训练集,30%作为测试集。多次混合交叉实验,每次实验把输入数据打乱,重新选取训练集和测试集。上述神经网络结构对通信数据的拟合效果如图6、图7、图8和图9所示;采用图6到图9的4个例子验证人工神经网络对不同集合通讯的拟合效果;
拟合结果采用相关系数量化,相关系数是反映变量之间密切程度的统计指标。其中皮尔卡逊相关系数r描述的是两个变量间线性相关的强弱程度,r的范围为[-1,1],当r>0时,两个变量是正相关的。r的绝对值越大,相关性越强。
表2 相关系数
相关系数能反映数据之间相关关系,用均方根误差(RMSE)量化测量的精密度。
表3 RMSE
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!