一种基于Storm流式计算框架多并发写文件的方法及系统与流程
本发明涉及数据处理领域,尤其涉及一种基于Storm流式计算框架多并发写文件的方法及系统。
背景技术:
Storm是一个免费、开源的分布式实时流计算框架,在Storm中,一个实时计算应用程序的逻辑被封装在一个称为Topology的对象中,也称为计算拓扑,在逻辑上,一个Topology是由消息获取任务线程和消息处理任务线程通过流分组连接成有向无环图的图状结构,消息获取任务线程在Topology中充当消息发送者的角色,而消息处理任务线程充当消息处理的角色,消息获取任务线程从Topology外部获取消息并将消息发送给消息处理任务线程。一些业务场景中,将Storm中的消息写入文件的逻辑主要是在消息处理任务线程组件中实现的,为了保证Storm集群处理消息的速度和吞吐量,需要调整该消息处理任务线程组件的并行度来改变消息写入文件的速度,如此,将造成文件的数量太多和文件大小不一,不利于文件的管理,如果在该消息处理任务线程组件中,实现多并发写同一个文件,一般需要使用同步锁机制来保证文件中消息的正确性和完整性,但同步锁会严重影响Storm集群的性能,降低写文件效率。
技术实现要素:
本发明要解决的技术问题之一,在于提供一种基于Storm流式计算框架多并发写文件的方法,提高写文件的速度,提高Storm集群处理消息的速度。
本发明要解决的技术问题之一是这样实现的:一种基于Storm流式计算框架多并发写文件的方法,包括如下步骤:
步骤1、利用消息获取任务线程采集原始消息,并将所述原始消息以数组形式发送给消息处理任务线程中任一一个线程;
步骤2、通过消息处理任务线程对获取到的消息进行处理,得到处理后的消息,并将处理后的消息写入同一队列中;
步骤3、通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,通过所述队列处理线程获取队列中的消息按批次发送给一异步线程池;
步骤4、通过异步线程池根据所述队列处理线程传来的数据使用异步方式写文件,所述异步线程池包括复数个写文件线程,且每一写文件线程对应写一个文件块。
进一步的,在所述消息处理任务线程初始化的时候,以单例模式一起启动队列处理线程,保证一个工作进程中对应一个队列。
进一步的,所述步骤3进一步包括:
步骤31、通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,所述批次大小为消息条数;
步骤32、通过所述队列处理线程实时监听队列,当监听到队列中有消息时,根据结束位置和文件大小判断是否需要创建新的文件路径,若结束位置大于或等于文件大小,则新建一个文件路径,并将起始位置和结束位置置为0,进入步骤33,否则,直接进入步骤33;
步骤33、创建一个空的集合类,所述集合类的默认大小设为批次大小,用于存储每一批次的消息;
步骤34、通过所述队列处理线程循环地从队列中获取消息存放在集合类里,同时根据添加的消息修改结束位置,直至集合类的消息数大于批次大小或者结束位置不小于文件大小或者队列为空,结束循环,进入步骤35;
步骤35、判断所述集合类是否为空,若是,则返回步骤32,否则,通过所述队列处理线程将文件路径、集合类、起始位置作为参数传递给异步线程池,修改起始位置为结束位置。
进一步的,所述步骤4具体为:通过异步线程池中空闲的写文件线程获取所述队列处理线程传递的集合类和文件路径,并根据起始位置将集合类中的消息写入到所给文件对应的文件块位置,所述文件块大小为集合类中所有消息的大小,所述集合类用于存放每一批次消息。
本发明要解决的技术问题之二,在于提供一种基于Storm流式计算框架多并发写文件的系统,提高写文件的速度,提高Storm集群处理消息的速度。
本发明要解决的技术问题之二是这样实现的:一种基于Storm流式计算框架多并发写文件的系统,包括一消息采集模块、一队列存储模块、一批次处理模块和一异步写文件模块:
所述消息采集模块,用于利用消息获取任务线程采集原始消息,并将所述原始消息以数组形式发送给消息处理任务线程中任一一个线程;
所述队列存储模块,用于通过消息处理任务线程对获取到的消息进行处理,得到处理后的消息,并将处理后的消息写入同一队列中;
所述批次处理模块,用于通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,通过所述队列处理线程获取队列中的消息按批次发送给一异步线程池;
所述异步写文件模块,用于通过异步线程池根据所述队列处理线程传来的数据使用异步方式写文件,所述异步线程池包括复数个写文件线程,且每一写文件线程对应写一个文件块。
进一步的,在所述消息处理任务线程初始化的时候,以单例模式一起启动队列处理线程,保证一个工作进程中对应一个队列。
进一步的,所述批次处理模块进一步包括:
一初始化参数模块,用于通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,所述批次大小为消息条数;
一监听模块,用于通过所述队列处理线程实时监听队列,当监听到队列中有消息时,根据结束位置和文件大小判断是否需要创建新的文件路径,若结束位置大于或等于文件大小,则新建一个文件路径,并将起始位置和结束位置置为0,执行集合类创建模块,否则,直接执行集合类创建模块;
一集合类创建模块,用于创建一个空的集合类,所述集合类的默认大小设为批次大小,用于存储每一批次的消息;
一消息存储模块,用于通过所述队列处理线程循环地从队列中获取消息存放在集合类里,同时根据添加的消息修改结束位置,直至集合类的消息数大于批次大小或者结束位置不小于文件大小或者队列为空,结束循环,执行发送模块;以及
一发送模块,用于判断所述集合类是否为空,若是,则返回执行监听模块,否则,通过所述队列处理线程将文件路径、集合类、起始位置作为参数传递给异步线程池,修改起始位置为结束位置。
进一步的,所述异步写文件模块具体为:通过异步线程池中空闲的写文件线程获取所述队列处理线程传递的集合类和文件路径,并根据起始位置将集合类中的消息写入到所给文件对应的文件块位置,所述文件块大小为集合类中所有消息的大小,所述集合类用于存放每一批次消息。
本发明具有如下优点:保证生成大小固定的文件,确保文件内容有序,使得文件命名规则有序;不影响Storm原有的性能,提高Storm集群处理消息的速度,提高写文件的速度,同时减少了消息处理任务线程组件生产文件的个数,使生成的文件便于管理和控制。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明一种基于Storm流式计算框架多并发写文件的方法执行流程图。
图2为本发明一种基于Storm流式计算框架多并发写文件的系统逻辑示意图。
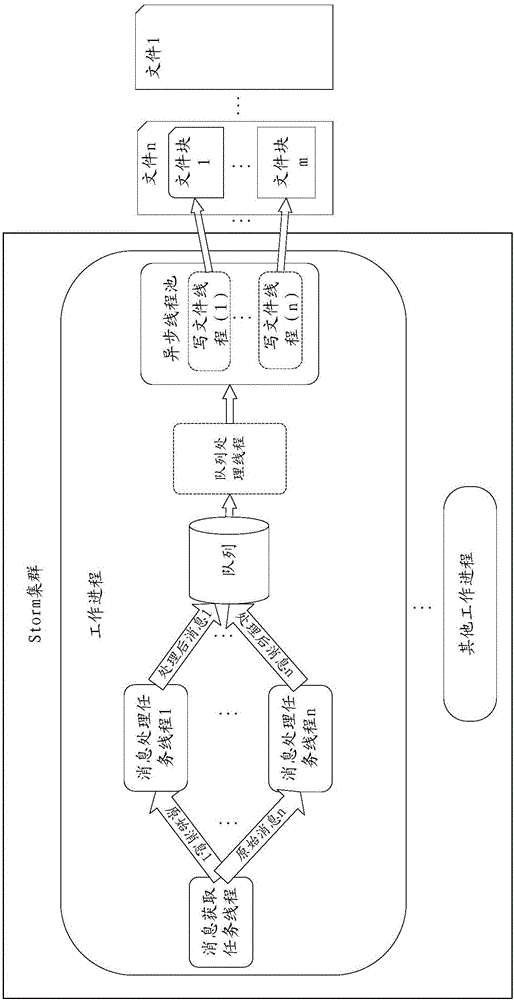
图3为本发明一种基于Storm流式计算框架多并发写文件原理示意图。
具体实施方式
如图1和图3所示,一种基于Storm流式计算框架多并发写文件的方法,包括如下步骤:
步骤1、利用消息获取任务线程采集原始消息,并将所述原始消息以数组形式发送给消息处理任务线程中任一一个线程;
步骤2、通过消息处理任务线程对获取到的消息进行处理,得到处理后的消息,并将处理后的消息写入同一队列中,且在所述消息处理任务线程初始化的时候,以单例模式一起启动队列处理线程,保证一个工作进程中对应一个队列;
步骤3、通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,通过所述队列处理线程获取队列中的消息按批次发送给一异步线程池;所述步骤3进一步包括步骤31至步骤35:
步骤31、通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,所述批次大小为消息条数;
步骤32、通过所述队列处理线程实时监听队列,当监听到队列中有消息时,根据结束位置和文件大小判断是否需要创建新的文件路径,若结束位置大于或等于文件大小,则新建一个文件路径,并将起始位置和结束位置置为0,进入步骤33,否则,直接进入步骤33;
步骤33、创建一个空的集合类,所述集合类的默认大小设为批次大小,用于存储每一批次的消息;
步骤34、通过所述队列处理线程循环地从队列中获取消息存放在集合类里,同时根据添加的消息修改结束位置,直至集合类的消息数大于批次大小或者结束位置不小于文件大小或者队列为空,结束循环,进入步骤35;
步骤35、判断所述集合类是否为空,若是,则返回步骤32,否则,通过所述队列处理线程将文件路径、集合类、起始位置作为参数传递给异步线程池,修改起始位置为结束位置;
步骤4、通过异步线程池根据所述队列处理线程传来的数据使用异步方式写文件,所述异步线程池包括复数个写文件线程,且每一写文件线程对应写一个文件块,所述步骤4具体为:通过异步线程池中空闲的写文件线程获取所述队列处理线程传递的集合类和文件路径,并根据起始位置将集合类中的消息写入到所给文件对应的文件块位置,所述文件块大小为集合类中所有消息的大小,所述集合类用于存放每一批次消息。
如图2和图3所示,一种基于Storm流式计算框架多并发写文件的系统,包括一消息采集模块、一队列存储模块、一批次处理模块和一异步写文件模块:
所述消息采集模块,用于利用消息获取任务线程采集原始消息,并将所述原始消息以数组形式发送给消息处理任务线程中任一一个线程;
所述队列存储模块,用于通过消息处理任务线程对获取到的消息进行处理,得到处理后的消息,并将处理后的消息写入同一队列中,在所述消息处理任务线程初始化的时候,以单例模式一起启动队列处理线程,保证一个工作进程中对应一个队列;
所述批次处理模块,用于通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,通过所述队列处理线程获取队列中的消息按批次发送给一异步线程池所述批次处理模块进一步包括一初始化参数模块、一监听模块、一集合类创建模块、一消息存储模块和一发送模块:
所述初始化参数模块,用于通过一队列处理线程初始化文件大小、默认批次和文件路径,并划分文件块,记录文件写入的起始位置和结束位置,所述批次大小为消息条数;
所述监听模块,用于通过所述队列处理线程实时监听队列,当监听到队列中有消息时,根据结束位置和文件大小判断是否需要创建新的文件路径,若结束位置大于或等于文件大小,则新建一个文件路径,并将起始位置和结束位置置为0,执行集合类创建模块,否则,直接执行集合类创建模块;
所述集合类创建模块,用于创建一个空的集合类,所述集合类的默认大小设为批次大小,用于存储每一批次的消息;
所述消息存储模块,用于通过所述队列处理线程循环地从队列中获取消息存放在集合类里,同时根据添加的消息修改结束位置,直至集合类的消息数大于批次大小或者结束位置不小于文件大小或者队列为空,结束循环,执行发送模块;
所述发送模块,用于判断所述集合类是否为空,若是,则返回执行监听模块,否则,通过所述队列处理线程将文件路径、集合类、起始位置作为参数传递给异步线程池,修改起始位置为结束位置;
所述异步写文件模块,用于通过异步线程池根据所述队列处理线程传来的数据使用异步方式写文件,所述异步线程池包括复数个写文件线程,且每一写文件线程对应写一个文件块,所述异步写文件模块具体为:通过异步线程池中空闲的写文件线程获取所述队列处理线程传递的集合类和文件路径,并根据起始位置将集合类中的消息写入到所给文件对应的文件块位置,所述文件块大小为集合类中所有消息的大小,所述集合类用于存放每一批次消息。
下面结合一具体实施例对本发明做进一步说明:
本发明以Storm的工作进程为粒度,让每个工作进程中所有消息处理任务线程将消息写入队列中,并在工作进程中新启动一个写文件的线程,将队列中的消息按批次通过JAVA的并发框架分块异步写入文件,从而在保证Storm集群性能的同时,控制文件生成的数量和大小,大大提高原有写文件的速度。
在本发明的Storm集群中的一工作进程中,包括一消息获取任务线程、复数个消息处理任务线程、一队列、一队列处理线程以及一异步线程池,所述异步线程池中包括复数个异步处理消息的写文件线程,写文件的过程如下:
利用所述消息获取任务线程将采集到的消息(即原始消息)以数组的形式发送给下游的任一一个消息处理任务线程;
通过所述消息处理任务线程对获取到的消息进行处理,得到处理后的消息,并将处理后的消息写入所述队列中,且在所述消息处理任务线程初始化的时候,以单例模式一起启动队列处理线程,从而保证一个工作进程中对应一个队列;
通过一队列处理线程初始化文件大小(例如,初始化文件大小为128M)、默认批次和文件路径(即某一文件地址),并划分文件块,即把一文件划分成固定大小的文件块,记录文件写入的起始位置和结束位置,将起始位置和结束位置初始化为0,所述批次大小为消息条数(例如1000条消息);
通过所述队列处理线程实时监听队列,当监听到队列中有消息时,根据结束位置和文件大小判断是否需要创建新的文件路径,若结束位置大于或等于文件大小,则新建一个文件路径,并将起始位置和结束位置置为0;
创建一个空的集合类,所述集合类的默认大小设为批次大小,用于存储每一批次的消息;
通过所述队列处理线程循环地从队列中获取消息存放在集合类里,同时根据添加的消息修改结束位置,即每存入一个消息就将结束位置增加该消息的长度(例如结束位置为endPos,消息为element,element为byty[]类型,endPos=endPos+element.length),直至集合类的消息数大于批次大小或者结束位置不小于文件大小或者队列为空,结束该循环,进入下一步;
判断所述集合类是否为空,若是,则返回继续监听队列,否则,通过所述队列处理线程将文件路径、集合类、起始位置作为参数传递给异步线程池,修改起始位置为结束位置;
通过JAVA的并发框架的异步线程池中空闲的写文件线程获取所述队列处理线程传递的集合类和文件路径,并根据起始位置将集合类中的消息写入到对应的文件块位置,所述文件块大小为集合类中所有消息的大小,使用这种异步方式写文件,可以避免同步锁引起的阻塞,加快队列中消息的消费,提高些文件的速度,一个写文件线程对应写一个文件块,如果该写文件线程写完对应的文件块,可以将重新领取到的集合类中的消息写入其他文件块中,从而可以保证同一时刻有多个写文件线程并发写同一个文件,大大提高文件处理速度。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!