一种基于内容及用户行为的文本类推荐方法和装置与流程
本发明涉及数据挖掘技术领域,特别涉及一种基于内容及用户行为的文本类推荐方法和装置。
背景技术:
互联网的出现和普及给用户带来了大量的信息,满足了用户在信息时代对信息的需求,但随着网络的迅速发展而带来的网上信息量的大幅增长,使得用户在面对大量信息时无法从中获得对自己真正有用的那部分信息,对信息的使用效率反而降低了,这就是所谓的信息超载问题。
目前,针对信息超载问题的解决办法之一是以搜索引擎为代表信息检索系统,它们在帮助用户获取网络信息方面发挥着极其重要的作用。但目前的搜索引擎往往仅能根据用户输入的字符进行匹配搜索,在使用同一个关键字搜索信息时,得到的结果是相同的,无法根据多样化的搜索需求得到不同结果。另一方面来看,信息及其传播是多样化的,而用户对信息的需求是多元化和个性化的,那么通过以搜索引擎为代表的信息检索系统获得的结果不能满足用户的个性化需求,仍然无法很好地解决信息超载问题。
技术实现要素:
本发明提供一种基于内容及用户行为的文本类推荐方法和装置,以解决上述技术问题。
本发明提供的一种基于内容及用户行为的文本类推荐方法,包括步骤:
步骤A,获取待分析的文档集合,对所述文档集合中的文档进行中文分 词得到多个词项;
步骤B,对所述文档集合中的词项进行信息增益计算,按照信息增益量的大小排序筛选多个词项作为基准向量;
步骤C,根据所述基准向量,将所述文档集合中的文本转换为多维的空间向量模型;
步骤D,对所述空间向量模型进行TF-IDF计算,得到文本向量矩阵;
步骤E,计算不同的文本向量矩阵之间的相似度,形成文档关系矩阵;
步骤F,分析用户行为数据,结合所述文档关系矩阵,形成推荐列表推荐给用户。
其中,步骤A之前还包括步骤:
生成词典并将所述词典持久化到词典库中。
其中,步骤生成词典包括步骤:
获取多种记载有词汇信息的原始词典,利用TreeSet对所述原始词典所记载的词汇进行自动排序、加载、过滤及汇总,根据词汇的属性生成List,再通过双数组索引树生成词典,持久化到词典库中。
其中,步骤A中对对所述文档集合中的文档进行中文分词包括步骤:
从所述词典库中采集加载好的词典到内存中,基于DATrie进行多模式匹配,生成竞选路径,同时对文档中的词汇进行分割处理,过滤掉特殊字符,计算得到最佳路径进行匹配,生成分词结果。
其中,步骤A之后,步骤B之前还包括步骤:
提取名词词项,过滤掉停用词。
其中,步骤B中对所述文档集合中的词项进行信息增益计算包括步骤:
将每篇文本作为一个类别,将文本中的词项作为特征,按照如下公式计算信息增益量:
其中,N表示所述文本集中的总文本数;P(Ci),表示类别Ci出现的概率; P(t),表示特征(T)出现的概率;表示特征(T)不出现的概率;P(Ci|t)表示文本包含特征(T)且属于类别Ci的概率;表示文本包含特征(T)且属于类别Ci的概率。
其中,步骤D中对所述空间向量模型进行TF-IDF计算包括步骤:
按照如下公式计算TF-IDF:
TF=log(1+ft,d);
TF-IDF=TF*IDF;
其中,TF为词频,IDF为文档逆频率。
其中,所述步骤计算不同的文本向量矩阵之间的相似度包括步骤:
通过计算两个不同的文本向量矩阵的夹角余弦值来得到两个不同的文本向量矩阵的相似度,余弦相似度计算公式如下:
其中,wi,k表示词项的TF-IDF结果。
其中,步骤A之后所述步骤B之前还包括步骤:
将所述文档集合中的文本向量化,采用Hash数据库结构进行存储。
本发明还提供一种基于内容及用户行为的文本类推荐的装置,包括:
分词模块,用于获取待分析的文档集合,对所述文档集合中的文档进行中文分词得到多个词项;
IG计算模块,用于对所述文档集合中的词项进行信息增益计算,按照信息增益量的大小排序筛选多个词项作为基准向量;
降维模块,用于根据所述基准向量,将所述文档集合中的文本转换为多维的空间向量模型;
TF-IDF计算模块,用于对所述空间向量模型进行TF-IDF计算,得到文本向量矩阵;
相似度计算模块,用于计算不同的文本向量矩阵之间的相似度,形成文档关系矩阵;
推荐模块,用于分析用户行为数据,结合所述文档关系矩阵,形成推荐列表推荐给用户。
本发明实施例提供了一种基于内容及用户行为的文本类推荐方法和装置,通过词典生成、文本分词、特征选择、TF-IDF计算、相似度计算、用户行为分析等步骤,挖掘出文本与文本之间的相似度,并根据用户历史数据分析用户的兴趣,进行建模,从而主动给用户推荐可满足他们兴趣和需求的信息,实现基于用户行为的个性化数据推荐,降低了推荐数据的盲目性和无效性,提高了数据推荐的准确度和效率。
附图说明
图1为本发明基于内容及用户行为的文本类推荐方法一个实施例的流程示意图;
图2位本发明实施例二提供的方法的流程示意图;
图3本发明实施例二中词典生成的流程示意图;
图4本发明实施例二中分词的流程示意图;
图5本发明实施例二中相似度计算相关流程的示意图;
图6本发明实施例三提供的装置的结构框架示意图。
具体实施方式
本发明实施例提供了一种基于内容及用户行为的文本类推荐方法和装置。
实施例一
参见图1所示,本发明实施例一提供的方法包括步骤:
步骤S110,获取待分析的文档集合,对文档集合中的文档进行中文分词得到多个词项。
步骤S111,对文档集合中的词项进行信息增益计算,按照信息增益量的 大小排序筛选多个词项作为基准向量。
步骤S112,根据所述基准向量,将所述文档集合中的文本转换为多维的空间向量模型。
步骤S113,对所述空间向量模型进行TF-IDF计算,得到文本向量矩阵。
步骤S114,计算不同的文本向量矩阵之间的相似度,形成文档关系矩阵。
步骤S115,分析用户行为数据,结合所述文档关系矩阵,形成推荐列表推荐给用户。
可选地,进行中文分词之前需要预先构建生成词典,并将所述词典持久化到词典库中。
词典生成主要通过各类词典(中、外)及用户词典,利用TreeSet自动排序,进行加载、过滤及汇总,持久化到词典库中,根据词的属性生成List,继而通过Double-Array Trie(双数组索引树,简称DAT)生成最终的词典Dict DATrie。Double-Array Trie是TRIE树的一种变形,它是在保证TRIE树检索速度的前提下,提高空间利用率而提出的一种数据结构。它本质是一个确定的有限状态自动机(DFA),每个节点代表自动机的一个状态,根据变量的不同,进行状态转移,当到达结束状态或者无法转移的时候,完成查询。
生成词典的目的在于收集大量的词汇组成词库,词库越丰富代表着分词的结果会越准确。
文本分词,是通过一定的算法将文本进行分词转化,并统计文本相关信息,如:文档频率、词频、词总数等。将文本向量化,存储到内存数据库,已备后续步骤使用。
文本分词需从词库中采集加载好的词典到内存中,基于之前预先生成的词典DATrie进行多模式匹配,生成竞选路径,同时对词进行分割处理,过滤掉特殊字符,加上词频权重等,计算路径代价,从而得到最佳路径进行匹配,生成分词结果。其中特殊字符为本领域公知技术用语,包括标点符号、空格等非文字的符号。
分词之后,需要进行名词提取及停用词过滤对分词结果进一步过滤,匹 配名词及停用词词库,过滤掉与文本特征不相关的词汇。可选地,预先收集停用词库及词性,通常认为名词词性对于区分文本的异同有着最大程度的重要性。因此,需要通过名词词性及停用词(“的”、“得”、“地”等)过滤对其进行筛选,以保证文本相似度计算的差异性和准确性。
准备文档集,记载词典库,并进行中文分词,过滤停用词,筛选出名词词性的特征,生成名词集合之后,就需要统计每个词项(Term)的出现频率和词项文档频率以及文档词数等,并将文本向量化,采用Hash Key数据结构,存入内存数据库。
信息增益表示特征在文本中出现或不出现为判定文本所属类别所提供的信息量的大小。通过信息增益计算(IG计算),往往能够将高维度的空间转换成低维的空间,它根据训练数据,计算出各个特征项的信息增益,删除信息增益很小的项,其余的按照信息增益从大到小排序,从而达到降维的目的。具体地,对整个文本系统的所有词汇通过IG计算,按照对整个系统贡献信息量的大小进行排序,筛选出前N个词汇作为基准向量,采用LIST数据结构,持久化到内存数据库中。
通过计算信息增益可以得到那些在正例样本中出现频率高而在正例样本中出现频率低的特征。信息增益涉及较多的数学理论和复杂的熵理论公式,本发明实施例将其定义为某特征项为整个分类所能提供的信息量,不考虑任何特征的熵于考虑该特征后的熵的差值。它根据训练数据,计算出各个特征项的信息增益,删除信息增益很小的项,其余的按照信息增益从大到小排序。本发明实施例提供的信息增益计算公式如下:
符号说明:
N,表示总文本数,即总类别数;P(Ci),表示类别Ci出现的概率,即文 本Di出现的概率,等于P(t),表示特征(T)出现的概率,采用包含特征(T)的文本数量除以总文本数量N,即:其中DFT表示特征(T)的文档频率;表示特征(T)不出现的概率,等于1-P(t);P(Ci|t),表示文本包含特征(T)且属于类别Ci的概率;表示文本包含特征(T)且属于类别Ci的概率。
信息增益计算之后,对文本的分词结果进行向量空间模型转换,根据IG的计算结果,对文本进行词过滤,将所有文本都表示成n维的特征向量。即文本d可以表示为n维的空间向量W1,W2,…,Wn,其中Wi是第i个特征项在文本d中的权重值,如下:
d1→W11,W12,…,W1n
d2→W21,W22,…,W2n
…
dn→Wn1,Wn2,…,Wnn
接下来,需要对文本向量进行TF-IDF计算,得到词项对该文本的重要程度,形成新的文本矩阵,存储到内存数据库中。TF-IDF计算,实际上是TF*IDF,TF词频(Term Frequency),IDF(Inverse Document Frequency)。TF表示词项在文档d中出现的频率,IDF是文档逆频率,即在词频的基础上,要对每个词分配一个"重要性"权重。例如最常见的词(“在”等)给予最小的权重,较常见的词(“中国”等)给予较小的权重,较少见的词(“贝叶斯”、等)给予较大的权重。它的大小与一个词的常见程度成反比。TF-IDF计算公式如下:
TF计算公式:log(1+ft,d)
IDF计算公式:
N表示总文本数,ft,d表示特征t在文本d中出现的频率,nt表示特征T在文本d中的个数。
之后,针对TF-IDF结果,通过余弦相似度公式计算文本之间的相似度,形成文档关系矩阵,越趋近1表明两个向量越相似,相反,则两个向量越不 相似。
余弦相似度计算,通过计算两个向量的夹角余弦值来评估他们的相似度。通过上述的空间向量,将目标向量与候选向量进行相似度计算,结果范围在[0,1]之间,越趋近1表明两个向量越相似,相反,则两个向量越不相似。余弦相似度计算公式如下:
其中:wi,k表示词的TF-IDF结果。
其中,本领域技术人员可根据本发明技术方案确定其余参数定义,本发明实施例不一一列举。
根据文本与文本之间余弦相似度计算的结果,得到文档关系矩阵,通过分析用户行为数据,挖掘出用户感兴趣的标签,结合文档关系矩阵,采用一定的权重比例对推荐列表进行评分、过滤及排序,形成最终的推荐列表,推荐给用户。
本发明实施例一,基于用户行为分析,围绕用户历史数据建立分析模型,通过有效算法对其进行深入挖掘,挖掘出用户需求及喜好,提供个性化的推荐,提升了数据推荐的有效性和针对性,改善了用户体验。
实施例二
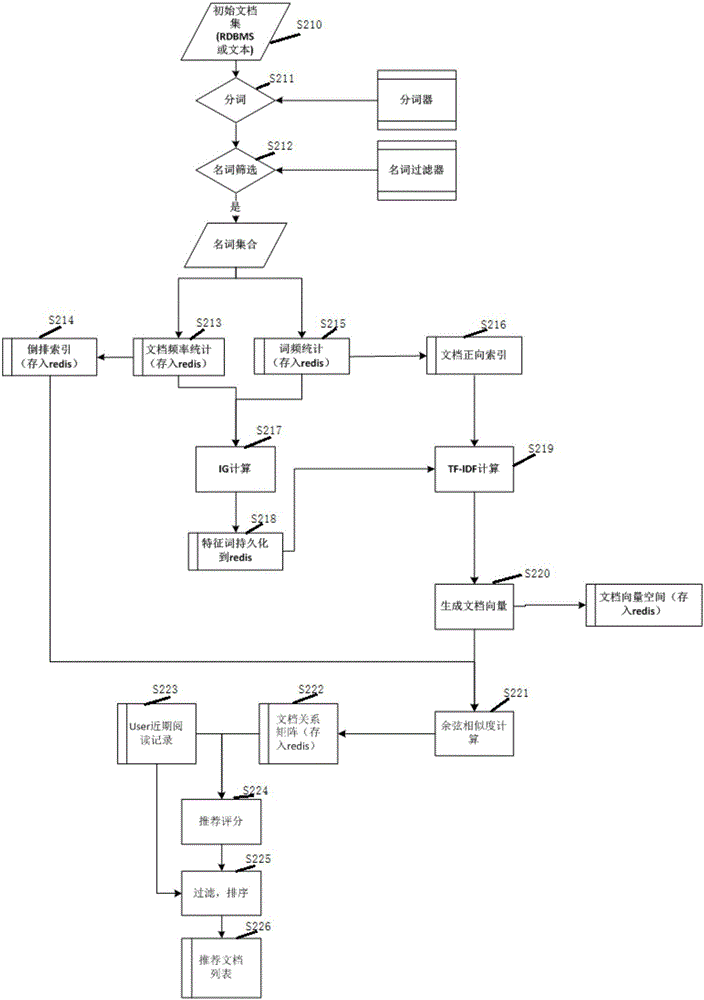
本发明实施例二提供的基于内容及用户行为的文本类推荐方法的流程参见图2所示,具体包括:
步骤S210,获取初始文档集,为RDBMS或者文本。
步骤S211,采用分词器对初始文档集进行中文分词。
步骤S212,采用名词过滤器进行名词筛选得到名词集合。
步骤S213,进行文档频率统计并存入redis,进入步骤S214和步骤S217。
步骤S214,进行倒排索引并将索引结果存入redis,并进入步骤S221。
步骤S215,进行词频统计并存入redis,之后进入步骤S216和步骤S217。
步骤S216,进行文档正向索引,之后进入步骤S219。
步骤S217,进行IG计算。
步骤S218,将IG计算得到的特征词持久化到redis,之后进入步骤S219。
步骤S219,进行TF-IDF计算。
步骤S220,生成文档向量,转换成文档向量空间并存入redis。
步骤S221,进行余弦相似度计算。
步骤S222,根据余弦相似度计算结果建立文档关系矩阵并存入redis。
步骤S223,获取用户近期阅读记录。
步骤S224,结合文档关系矩阵和用户近期阅读记录,进行推荐评分。
步骤S225,根据评分结果和用户近期阅读记录进行过滤和排序。
步骤S226,得到推荐文档列表推荐给用户。
在本发明实施例二中,词典生成流程参见图3所示,分词器进行分词流程参见图4所示,文本相似度计算相关流程参见图5所示。
实施例三
本发明实施例还提供一种基于内容及用户行为的文本类推荐的装置,参见图6所示,包括:
分词模块,用于获取待分析的文档集合,对所述文档集合中的文档进行中文分词得到多个词项;
IG计算模块,用于对所述文档集合中的词项进行信息增益计算,按照信息增益量的大小排序筛选多个词项作为基准向量;
降维模块,用于根据所述基准向量,将所述文档集合中的文本转换为多维的空间向量模型;
TF-IDF计算模块,用于对所述空间向量模型进行TF-IDF计算,得到文本向量矩阵;
相似度计算模块,用于计算不同的文本向量矩阵之间的相似度,形成文档关系矩阵;
推荐模块,用于分析用户行为数据,结合所述文档关系矩阵,形成推荐列表推荐给用户。
本发明实施例提供了一个可以个性化推荐的方法和装置,实现了根据用户的信息需求、兴趣等,将用户感兴趣的信息、产品等推荐给用户的针对性信息推荐。和传统的搜索引擎相比,该推荐系统通过研究用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点及文本与文本之间的相似度,从而引导用户发现自己的信息需求,为用户提供更为有效的数据推荐服务。
需要说明的是,本发明实施例中的装置或者系统实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。从硬件层面而言,如图6所示,为本发明实施例的一种硬件结构框架示意图,除了CPU、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的设备通常还可以包括其他硬件,如负责处理报文的转发芯片等等。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在设备的CPU将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!