一种通用隐写分析的深度学习堆栈式自动编码方法与流程
本发明涉及一种通用隐写分析的深度学习堆栈式自动编码方法。
背景技术:
基于神经网络的实现原理,2006年,Hinton对原型自动编码器结构进行改进,进而产生了深度学习自动编码器,如说明书附图中的图1。它由编码器、解码器和隐含层组成,它先用无监督逐层贪婪训练算法完成对隐含层的预训练,然后用BP(基追踪)算法对整个神经网络进行系统性参数优化调整,显著降低了神经网络的性能指数,有效改善了BP算法易陷入局部最小的不良状况。2006年,Benjio提出稀疏自动编码器的概念,进一步深化了深度学习自动编码器的研究。2008年,Vincent提出降噪自动编码器,在输入数据中添加限制向量,防止出现过拟合现象,并取得了良好的效果。2009年,Benjio总结了已有的深度结构,阐述了利用堆栈自动编码器构建深度学习神经网络的一般方法。2011年,Salah对升维和降维的过程加以限制,提出收缩自动编码器。2011年,Jonathan提出卷积自动编码器,用于构建卷积神经网络,2012年,Guyon对深度学习自动编码器与无监督特征学习之间的联系进行了深入的探讨,详细介绍了如何利用自动编码器构建不同类型深度结构。Hinton,Bengio和Vincent等人对比了原型自动编码器、稀疏自动编码器、降噪自动编码器、收缩自动编码器、卷积自动编码器和RBM等结构的性能,为以后的实践和科研提供了参考。2013年Amaral等研究了用不同代价函数训练的深度学习自动编码器的性能,为代价函数优化策略的发展指明了方向。
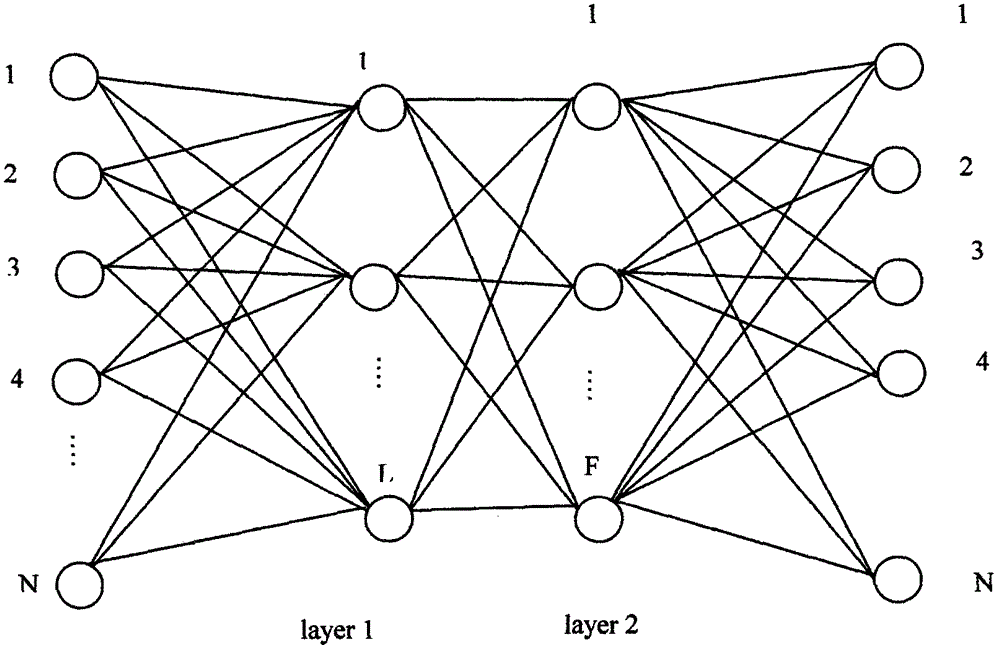
最近,基于Y.Chen等的技术原理,J.Zabalza等面向高光谱图像处理提出一个堆栈式自动编码器S-SAEs。它能够在网络的深度层把特征数据只用几个分量来统计,其基本的2层结构如说明书附图中的图2所示。
通用隐写分析是在未知原始载体对象和隐写术的基础上对检测图像是否含密进行判断的一种分析方法。通用隐写分析不再依据少量敏感统计特性判断载体是否含密,而是从大量原始载体样本和含密载体样本中提取多维特征向量来区分原始载体和以不同隐写方法得到的含密载体。
由于通用隐写分析的重点在于多维特征提取,而深度学习SAEs技术在隐含层能够更深刻地理解图像信号的分布特性及其潜在的结构化特征,进而可以为分析技术提供更加准确的分类判断。
但由于深度学习的复杂性和计算量,目前把深度学习的SAEs方法用于隐写分析的技术还没有。基于说明书附图中的图2的深度学习S-SAEs原理,本专利提出一种用于通用隐写分析的深度学习USoSAE技术。
技术实现要素:
本发明针对现有技术的不足,提供一种通用隐写分析的深度学习堆栈式自动编码方法,该方法主要包括以下步骤:
第一步,图像分块处理;输入待检测的图像样本通过酉变化(如小波变换(Discrete Wavelet Transform,DWT)、多小波变换(Multi-wavelet transform,MWT)或离散余弦变换(Discrete Cosine Transform,DCT))等对图像进行分解,运用图像信号的联合概率密度函数拉普拉斯(Laplacian)变换对信号方差进行处理,并运用马儿科夫(Markov)准则获得概率密度函数的统计关系:
其中,代表了图像信号的临界方差分布,而条件概率分布表示了系统获得局部系数的一种概率统计行为,对应临界分布条件,全局数据概率统计特性为:
运用公式(4)对公式(5)进行统计条件分割,并按照不同大小属性的间隔,得到相关性统计模型;
第二步,USoSAE特征数据输入,通过编码函数f将i个不同节点数据分别按照相关性统计模型的分割结果输入到各自的输入层,并通过梯度下降算法求解误差代价函数L(x1,y′1)=argminw,p,q[error(x1,y′1)]训练出第1级隐含层结构的网络参数θ1={w1,p1,q1},并将训练好的参数作为该节点第1级隐含层的输出;
第三步,USoSAE特征数据的映射,通过编码h=f(x):=sf(wx+p)得到特征表达h,再用梯度法求解误差代价函数(y′1,y1)=argminw,p,q[error(y′1,y1)],训练该节点第2级隐含层网络的参数θ2={w2,p2,q2};
为了简化计算,令hj(x)表示输入特征为x的数据在隐含层上第j个神经元的激活度,则:表示隐含层上第j个神经元在训练集上的平均激活度。为了保证隐含层上的神经元满足特征摘要的稀疏性限制,要求其中ρ为稀疏性参数,通常取一个很小的数(如ρ=0.03)。如果训练时和ρ相隔太大,就采用基于KL-divergence方法进行惩罚,其惩罚函数形式为:
这样在第i(i=1,2,…,k)个节点上的两级隐含层上总的训练代价函数为:
公式(7)中,β为控制稀疏性惩罚项的权重系数,m为该节点的训练神经元个数。
这样在每个节点中,每个神经元的输入与前一级的局部训练过程相连,因此,USoSAE技术可以有效提取该局部的特征,并在该局部特征被提取后,它与其他特征间的位置关系也随之确定下来。
第四,USoSAE特征数据输出,通过在每个节点上按照第二步和第三步的两级训练方式,得到隐写图像的特征数据集输出作为多分类器的输入,利用原始数据标签来训练出分类器的网络参数作为最后隐写分析的判断依据;
第五,重复第一步、第二步和第三步的网络参数作为USoSAE技术检测的深度网络系统的参数初始化值,然后用随机梯度下降算法迭代求出上面代价函数最小值附近处的参数值,并作为整个USoSAE网络训练最后的优化参数值。
为了进一步提高隐写分析的准确率和运行效率,本发明进行特征选择与融合的通用隐写分析方法的优点主要体现在以下几个方面:
1)、根据隐写检测图像的概率密度函数统计,把USoSAE输入层的数据按照信号方差关系进行条件分割,组成不同级、不同节点的分段SAEs训练模型,降低了深度学习输入层的数据维数。
而常用的深度学习SAEs是把整个图像信号作为训练输入数据,数据量较大,迭代耗时,难以满足神经网络的表示效率。
2)、USoSAE网络中的每一个特征提取层(第1层)都紧跟着稀疏性与二次特征训练的计算层(第2层),这种隐含层特有的两次特征训练结构使网络对高维输入的不同属性数据有较好的调节能力,提高了通用隐写分析的识别精度。
而常用的深度学习堆栈式自动编码器是三层神经网络结构:一个输入层,一个隐含层和一个输出层。
3)、基于KL-divergence方法,USoSAE通过在隐含层的代价函数中加入稀疏性惩罚项及其权重系数,降低了原始信号的特征维数和训练数据的计算量。
附图说明
图1为基于深度学习自动编码器的实现方案示意图;
图2为基于深度学习S-SAEs的实现方案(2层)示意图;
图3为基于方差分布的图像分割的相关性统计模型示意图;
图4为本发明USOSAE实现方案示意图。
具体实施方式
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
参照图1~4,本发明实施例一种通用隐写分析的深度学习堆栈式自动编码方法,该方法主要包括以下步骤:
第一步,图像分块处理;输入待检测的图像样本通过酉变化(如小波变换(Discrete Wavelet Transform,DWT)、多小波变换(Multi-wavelet transform,MWT)或离散余弦变换(Discrete Cosine Transform,DCT))等对图像进行分解,运用图像信号的联合概率密度函数拉普拉斯(Laplacian)变换对信号方差进行处理,并运用马儿科夫(Markov)准则获得概率密度函数的统计关系:
其中,代表了图像信号的临界方差分布,而条件概率分布表示了系统获得局部系数的一种概率统计行为,对应临界分布条件,全局数据概率统计特性为:
运用公式(4)对公式(5)进行统计条件分割,并按照不同大小属性的间隔,得到相关性统计模型,如说明书附图3;
第二步,USoSAE特征数据输入,通过编码函数f将i个不同节点数据分别按照相关性统计模型的分割结果输入到各自的输入层,并通过梯度下降算法求解误差代价函数L(x1,y′1)=argminw,p,q[error(x1,y′1)]训练出第1级隐含层结构的网络参数θ1={w1,p1,q1},并将训练好的参数作为该节点第1级隐含层的输出;
第三步,USoSAE特征数据的映射,通过编码h=f(x):=sf(wx+p)得到特征表达h,再用梯度法求解误差代价函数(y′1,y1)=argminw,p,q[error(y′1,y1)],训练该节点第2级隐含层网络的参数θ2={w2,p2,q2};
为了简化计算,令hj(x)表示输入特征为x的数据在隐含层上第j个神经元的激活度,则:表示隐含层上第j个神经元在训练集上的平均激活度。为了保证隐含层上的神经元满足特征摘要的稀疏性限制,要求其中ρ为稀疏性参数,通常取一个很小的数(如ρ=0.03)。如果训练时和ρ相隔太大,就采用基于KL-divergence方法进行惩罚,其惩罚函数形式为:
这样在第i(i=1,2,…,k)个节点上的两级隐含层上总的训练代价函数为:
公式(7)中,β为控制稀疏性惩罚项的权重系数,m为该节点的训练神经元个数。
这样在每个节点中,每个神经元的输入与前一级的局部训练过程相连,因此,USoSAE技术可以有效提取该局部的特征,并在该局部特征被提取后,它与其他特征间的位置关系也随之确定下来。
第四,USoSAE特征数据输出,通过在每个节点上按照第二步和第三步的两级训练方式,得到隐写图像的特征数据集输出作为多分类器的输入,利用原始数据标签来训练出分类器的网络参数作为最后隐写分析的判断依据;
第五,重复第一步、第二步和第三步的网络参数作为USoSAE技术检测的深度网络系统的参数初始化值,然后用随机梯度下降算法迭代求出上面代价函数最小值附近处的参数值,并作为整个USoSAE网络训练最后的优化参数值。
为了进一步提高隐写分析的准确率和运行效率,本发明进行特征选择与融合的通用隐写分析方法的优点主要体现在以下几个方面:
1)、根据隐写检测图像的概率密度函数统计,把USoSAE输入层的数据按照信号方差关系进行条件分割,组成不同级、不同节点的分段SAEs训练模型,降低了深度学习输入层的数据维数。
而常用的深度学习SAEs是把整个图像信号作为训练输入数据,数据量较大,迭代耗时,难以满足神经网络的表示效率。
2)、USoSAE网络中的每一个特征提取层(第1层)都紧跟着稀疏性与二次特征训练的计算层(第2层),这种隐含层特有的两次特征训练结构使网络对高维输入的不同属性数据有较好的调节能力,提高了通用隐写分析的识别精度。
而常用的深度学习堆栈式自动编码器是三层神经网络结构:一个输入层,一个隐含层和一个输出层。
3)、基于KL-divergence方法,USoSAE通过在隐含层的代价函数中加入稀疏性惩罚项及其权重系数,降低了原始信号的特征维数和训练数据的计算量。
本发明实施例经过实验、模拟,具体实现过程如下:
1)实验条件和参数
本专利实验选取的图像源为UCID图像库和testing数据集,在特征数据训练和分类过程中,本专利使用径向基函数(radial basis function,简称RBF)支持向量分类(C-SVC)的LibSVM2.86。
实验分别对常用隐写算法F5,JPHide和JSteg进行隐写分析。选择testing数据集载体图像及嵌入率分别为Large(简写为L),Medium(简写为M),Small(简写为S)和Tiny(简写为T)的F5,JPHide和JSteg的隐写图像各1000张,共计12000张。L,M,S,T分别表示了秘密信息占载体图像数据量的40%以上,15%-40%,5%-15%以及5%以下。实验时,分别用4000张原始载体图像(不含秘密信息)和对应的4000张隐写图像(含密信息)进行训练,用2000张载体图像和2000张对应的隐写图像进行测试。
同时,实验对基本YASS隐写(也进行了检测分析。其中,载体图像选择testing数据集图像5000张,并进行质量因子QFa的JPEG压缩处理。候选数据嵌入到Zigzag扫描排序的前19个低频DCT系数,按照YASS算法进行最大嵌入容量隐写。其参数设置为:主块大小分别为10,12,14;图像质量因子QFa和嵌入质量因子QFh选择为50/50和75/50两种,量化索引步长为1.5,生成5000张图像,用其中1500张载体图像及其对应的1500张隐写图像进行训练,用1000张载体图像及其对应的1000张隐写图像进行测试。
实验时,USoSAE的系统设置参数如下表0。表0为USoSAE的网络参数设置,表0中,总的特征数为20,C-1(k=5)表示输入图像数据在第1级按照属性分成5个子块输入的情况,C-2(k=4)表示隐含层对4个子块数据训练的配置,C-3(k=2)表示隐含层对2个子块数据训练的配置。其中,Nk表示数据源的分割大小范围,Lk=m表示训练节点神经元的大小,Fk表示不同节点不同级训练的特征大小配置。
表1为检测F5,JPHide和JSteg隐写结果,表2为检测YASS隐写结果。表1-2分别列出了不同隐写算法下,本专利USoSAE方法与常用的LSB(Least Significant Bit)空域检测方法、DCT和DWT域检测方法以及文献[20](黄炜,赵险峰,等.基于主成分分析进行特征融合的JPEG隐写分析[J],软件学报,2012,23(7):1869-1879.)的主成成分分析(Principal Component Analysis,PCA)特征融合方法的检测比较结果。表中,TPR(True Positive Rate)表示真阳性率,TNR(True negative Rate)表示真阴性率,A(accuracy)表示检测精度。
2)实验结果分析
实验计算环境在Intel Xeon E7420 2.13GHz和8GB内存硬件环境下运行,分别运行LSB空域检测、DCT和DWT域检测、文献[20]PCA特征融合检测、文献[1](J.Zabalza,J Ren,Jiangbin Zheng,Huimin Zhao,Chunmei Qing,et al,“Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging,”Neurocomputing,10.1016/j.neucom.2015.11.044,185:1-10,April 2016.)的S-SAE方法检测,并与本专利USoSAE检测技术进行了对比。同时,对于特定的隐写算法,实验配置的隐写分析和训练器都相同,只有特征优选方法不同。由表1可见,本专利USoSAE方法优于其他隐写分析方法,并且特征选择稳定,检测识别精度远高于其他隐写分析方法。
由表2可见,典型的DCT和DWT变换域隐写分析方法不能有效地检测YASS隐写秘密信息的随机性嵌入位置,检测精度远低于USoSAE技术,约为14%-45.8%。而在空域,虽然检测精度高于USoSAE技术2.13%,但LSB空域检测方法一直存在鲁棒性问题,应用效率很低。以下为表0~2的具体情况:
表0 USoSAE的网络参数设置
表1 检测F5,JPHide和JSteg隐写结果
表2 检测YASS隐写结果
以上已将本发明做一详细说明,但显而易见,本领域的技术人员可以进行各种改变和改进,而不背离所附权利要求书所限定的本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!