一种基于用户评论和历史评分的网购产品评估方法与流程
本发明属于自然语言处理等领域,尤其涉及一种基于用户评论和历史评分的网购产品评估方法。
背景技术:
随着Web技术的广泛应用和发展,互联网进入人们社会生活的方方面面。网络已然成为人们实际生活中不可或缺的一部分。用户在网络上可以开展各式各样的活动,其中购物也不仅仅局限于现实生活中,足不出户的网上购物成为许多用户便捷省事的选择。
网购在带来便捷性和商品多样性的同时,也增加了虚假宣传的可能性。因为网购用户无法直接查看产品,用户通常情况是根据其他用户的评论和评分来判断产品的可靠性,大部分的用户会根据评分的高低来决定是否购买某一产品;如果评分低的话可能放弃购买,如果评分高的情况下,则极有可能购买。然而每个用户评分都有一定的倾向性,有的用户倾向于打高分,有的用户倾向于打低分,甚至还有一些用户则是商家雇来刷好评的,现在的很多店家都会根据消费者的心理,会打出比如给优评返现金或者给优评返还优惠券等方式,来获取高评分来吸引顾客。因此产品的评分往往不是那么准确可靠。与此同时,现有的产品评分系统仅考虑用户对该产品的评分,没有考虑用户的评论和评分习性,未必能准确反应产品的真实评分。因此如何构建一个可靠的、不带有个人情感色彩,能够真实的反应产品的估分并且不完全基于用户的评分的产品评估方法一直是本领域待解决的技术难题。
技术实现要素:
本发明针对现有技术的不足公开了一种基于用户评论和历史评分的网购产品评估方法,通过该评估方法可以反应产品的真实估分,且该方法计算简单,通用性和扩展性强,可以有效地对网购产品进行评估。
本发明公开了一种基于用户评论和历史评分的网购产品评估方法,具体步骤如下:
(1)获取网络中同一产品下的用户评论,对于每个用户评论,将其分割为句子集合;
(2)基于句子中的情感词,完成对每一个句子的情感估分;
(3)结合句子的情感估分以及句子在用户评论中的位置,加权平均计算用户评论的情感估分;
(4)提取用户评论的文档特征,基于历史平均值设置用户评论标签,采用bootstrap采样生成多个训练集来训练多个随机森林分类器,加权平均计算分类器估分;
(5)对上述步骤(3)以及步骤(4)的估分加权平均计算,获取每个用户评论的综合估分,再采用平均法得到一个产品的综合估分。
进一步,所述的步骤(1)中分割为句子集合的具体步骤为:对获取的每个用户评论进行处理,将每个用户评论以“。”、“;”、“?”、“!”将其分割为句子集合,即:R={S1,S2,…},其中R代表一个用户评论,S代表一个句子。
进一步,所述的步骤(2)包括如下步骤:
(2.1)以“,”将句子分割成短句,句子分割后的序列为S=<sengrop1,...,sengropj>,其中sengropj表示句子S中的第j个短句;
(2.2)短句经过分词处理,短句分词后的序列为sengrop=<w1,w2,...,wn>,其中wn即代表一个词,n为个数;
(2.3)对照情感词库提取情感词、否定词和程度词,根据所含的情感词、否定词和程度词来计算短句的情感估分,公式为:
scoreG(sengropj)=情感词权重×否定词权重×程度词权重;
式中,情感词权重的评判原则:对应情感词库将情感词分正面以及负面两个极性,
正面:情感词权重为1;
负面;情感词权重为-1;
否定词权重的评判原则:if position(否定词)>position(程度词):
否定词权重为-1;
else:
否定词权重为+0.5;
程度词权重的评判原则:程度词对应情感词库中的程度级别词语,分6个等级;
1)句子中包括“非常,极”:程度词权重为1.2;
2)包括“很,很是,太”:程度词权重为1;
3)包括“较,较为,还”:程度词权重为0.8;
4)包括“稍,稍微,些微”:程度词权重为0.6;
5)包括“不怎么,半点,不大”:程度词权重为0.4;
6)包括“过,过度,偏”;程度词权重为0.2;
若无否定词、程度词,否定词、程度词权重默认设为1;若无情感词,则情感词权重为0;
(2.4)句子的情感估分scoreS(s)可由短句的情感估分得到,公式为:
(2.5)以阈值t为标准值,将句子的情感估分离散化为正面、负面以及中性三个极性,其中t∈[0.1,0.4]:
正面:scoreS(s)≥t,此时的估分为+1;
负面:scoreS(s)≤-t,此时的估分为-1;
中性:scoreS(s)∈(-t,t),此时估分为0;
通过对句子估分离散化,可以防止因一些句子情感估分过高对评论情感估分造成影响。
进一步,所述的步骤(3)包括如下分步骤:
(3.1)根据句子在用户评论中的位置加权计算,基于句子在评论中的位置计算评论的情感估分,用户评论通常首句和尾句直接点明主题,一般赋予更高的权重,其中计算公式为:
SS=(scoreG(首句)+scoreG(尾句)+socreG(其他句子的平均值))/3
式中,socreG(其他句子的平均值)为其他句子情感估分的平均值,若无其他句子,则为首句和尾句情感估分的平均值;
(3.2)对情感估分标准化处理,统一到(0,1)之间,分值越高说明对产品评价越高,其公式为:
式中,max为所有用户评论中SS的最大值,min为所有用户评论中SS的最小值。
进一步,所述的步骤(4)包括如下步骤:
(4.1)首先提取用户评论的文档特征,针对每一个用户评论Ri,统计如下特征:
1)正向词个数及比例;
2)负向词个数及比例;
3)否定词个数及比例;
4)程度词个数及比例;
5)其他类别词个数及比例;
6)根据是否包含否定词、程度词、情感词划分三个离散特征{η1,η2,η3},η1,η2,η3=1则为包含对应的词;
(4.2)对用户评论中的每个句子,基于上述步骤(4.1)中正向词个数及比例,负向词个数及比例,否定词个数及比例,程度词个数及比例,其他类别词个数及比例这10个特征,分别求其中最大值、最小值和平均值;共得到30个特征,与上面评论特征组合在一起,构成用户评论的文档特征向量,共43个特征;
(4.3)在对所有评论抽取了文档特征之后,基于历史平均值获取对应评论的标签;如果是老用户,获取用户的历史评分,求其平均值作历史平均值,如果是新用户,则以该产品的平均评分作为其历史平均值,将用户评分与历史平均值相减,大于0则标签打为1,否则标签打为0;
(4.4)然后对数据集进行bootstrap采样,生成N个训练集,然后在每个训练集上,训练随机森林分类器;
(4.5)将上述步骤(4.4)训练好的随机森林分类器对所有的用户评论进行分类,计算每个随机森林分类器对用户评论的分类器估分,公式如下:
scoreC=Nmost/Nall
式中,Nmost是分类结果标签为1的决策树个数,Nall是所有决策树的总个数;
(4.6)之后对所有随机森林分类器进行平均,获得用户评论的分类器估分,公式如下:
scoreCC=∑scoreC/N
式中,N为相应训练集个数。
进一步,所述的步骤(5)包括如下步骤:
(5.1)首先采用加权平均法计算用户评论的综合估分,结合用户评论的情感估分以及分类器估分两个方面的估分计算用户评论的综合估分,公式如下:
score=θscoreSS+(1-θ)scoreCC
式中,θ是权重;
(5.2)然后对目标产品所有评论的综合估分进行平均,获得产品估分,公式如下:
scoreP=Σscore/n
式中,n为用户评论个数。
本发明具有如下有益效果:
(1)综合考虑了用户评论的词性和文档特征,并有效去除用户的评分习性带来的影响,规避了传统的评分的不真实性以及倾向性;
(2)充分考虑不同用户评论的情感倾向,以及用户的评分习性,从而提高产品评价的客观性和准确性;
(3)计算成本简单,具有扩展性和适应性,适用于网上产品的客观评估,帮助用户做出更好的选择。
附图说明
图1是本发明基于用户评论和历史评分的网购产品估分方法的总体框架流程图;
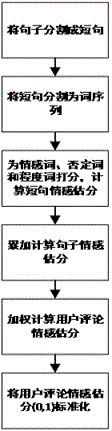
图2是本发明基于情感词对用户评论完成情感估分的流程图;
图3是本发明训练多个随机森林模型并计算分类器估分的流程图;
图4是本发明加权平均计算产品估分的流程图。
具体实施方式
下面结合附图以及具体的实施例,对发明的方案做进一步的阐述。
如图1所示,是本发明的产品估分的总体框架流程图,具体的步骤如下:
(1)获取网络中同一产品下的用户评论,对于每个用户评论,将其分割为句子集合;
例如对以下一件衣服的评论:“发货速度很快,服务态度超好。收到衣服老板还主动询问,衣服质量没得说。很开心得一次网购,下次还会来。”
这段评论可以分成三个句子:
S1“发货速度很快,服务态度超好。”
S2“收到衣服老板还主动询问,衣服质量没得说。”
S3“很开心得一次网购,下次还会来。”
(2)如图2所示,是基于句子中的情感词,完成对每一个句子的情感估分,其中的情感词库选用中国知网的HowNet词库;
其中对情感词、否定词和程度词打分的具体方法如下:
对情感词进行打分,情感词分两个极性;
1)正面:对应情感词库的“正面情感”或“正面评价”词语,例如:“不可或缺,部优,才高八斗,爱,赞赏,快乐”等;打分为1;
2)负面:对应情感词库的“负面情感”或“负面评价”词语,例如:“哀伤,半信半疑,鄙视,丑,苦,华而不实”等;打分为-1;
对否定词进行打分:
当一个句子中同时出现否定词和程度词时,由于否定词和程度词相对位置的不同,会引起情感的不同,比如:
“我很不高兴”经过分词之后:我很不高兴
“我不很高兴”经过分词之后:我不很高兴
第一句话表达的是一种很强烈的负面情感,而第二句话表达的则是一种较弱的正面情感。因此,如果否定词在程度词之前,起到的是减弱的作用;如果否定词在程度词之后,则起到的是逆向情感的作用;
对否定词进行打分:
if position(否定词)>position(程度词):
否定词权重为-1;
else:
否定词权重为+0.5;
对程度词进行打分,程度词对应情感词库中的“程度级别”词语,分6个等级:
1)6:句中包括“非常,极”;打分为1.2;
2)5:包括“很,很是,太”;打分为1;
3)4:包括“较,较为,还”;打分为0.8;
4)3:包括“稍,稍微,些微”;打分为0.6;
5)2:包括“不怎么,半点,不大”;打分为0.4;
6)1:包括“过,过度,偏”;打分为0.2;
若无否定词、程度词,否定词、程度词权重默认设为1;若无情感词,则情感词权重为0;
然后,对句子的情感估分可由短句的情感估分得到:
以步骤(1)中的句子S1为例,以“,”分割成短句序列为:
“发货速度很快”+“服务态度超好”
序列中情感词有“快,好”,程度词有“很,超”;这个句子的情感估分为1*1+1.2*1=2.2。
接着,将句子的情感估分离散化为三个极性,以阈值t为标准值,其中t∈[0.1,0.4],建议取值0.3:
正面:scoreS(s)≥t,此时估分为+1;
负面:scoreS(s)≤-t,此时估分为-1;
中性:scoreS(s)∈(-t,t),此时估分为0。
以步骤(1)中的评论为例,句子S1情感估分离散为1,句子S2情感估分离散为1,句子S3情感估分离散为1。
(3)结合句子的情感估分以及句子在用户评论中的位置,加权平均计算用户评论的情感估分;
(3.1)根据情感词在句子中的位置加权计算,公式为:
SS=(scoreG(首句)+scoreG(尾句)+socreG(其他句子的平均值))/3
式中,socreG(其他句子的平均值)为其他句子情感估分的平均值,若无其他句子,则为首句和尾句情感估分的平均值。
以步骤(1)中的评论为例,SS=(1+1+1)/3=1,情感估分为1;
(3.2)对情感估分标准化处理,统一到(0,1)之间,情感估分越高说明对产品评价越高,其计算公式为:
式中,max为所有用户评论中SS的最大值,min为所有用户评论中SS的最小值。
(4)提取用户评论的文档特征,基于历史平均值设置用户评论标签,如图3所示,采用bootstrap采样生成多个训练集来训练多个随机森林分类器,加权平均计算分类器估分;
(4.1)提取用户评论的文档特征,针对每一个用户评论Ri,统计如下特征:
1)正向词个数及比例;
2)负向词个数及比例;
3)否定词个数及比例;
4)程度词个数及比例;
5)其他类别词个数及比例;
7)根据是否包含否定词、程度词、情感词划分三个离散特征{η1,η2,η3},η1,η2,η3=1则为包含对应的词;
(4.2)对用户评论中的每个句子,基于上述步骤(4.1)中正向词个数及比例,负向词个数及比例,否定词个数及比例,程度词个数及比例,其他类别词个数及比例这10个特征,分别求其中最大值、最小值和平均值;共得到30个特征,与上面评论特征组合在一起,构成用户评论的文档特征向量,共43个特征;
(4.3)在对所有评论抽取了文档特征之后,基于历史平均值获取对应评论的标签;如果是老用户,获取用户的历史评分,求其平均值作历史平均值,如果是新用户,则以该产品的平均评分作为其历史平均值,将用户评分与历史平均值相减,大于0则标签打为1,否则标签打为0;
(4.4)然后对数据集进行bootstrap采样,生成N个训练集,然后在每个训练集上,训练随机森林分类器;
(4.5)将上述步骤(4.4)训练好的随机森林分类器对所有的用户评论进行分类,计算每个随机森林分类器对用户评论的分类器估分,公式如下:
scoreC=Nmost/Nall
式中,Nmost是分类结果标签为1的决策树个数,Nall是所有决策树的总个数,通常设置Nall=10;
(4.6)之后对所有随机森林分类器进行平均,获得用户评论的分类器估分,公式如下:
scoreCC=∑scoreC/N
式中,N为相应训练集个数,通常设置N=5。
(5)如图4所示,对上述步骤(3)以及步骤(4)的估分加权平均计算,获取每个用户评论的综合估分,再采用平均法得到一个产品的综合估分;
(5.1)首先采用加权平均法计算用户评论的综合估分,结合用户评论的情感估分以及分类器估分两个方面的估分计算用户评论的综合估分,公式如下:
score=θscoreSS+(1-θ)scoreCC
式中,θ是权重,设置θ=0.4;
(5.2)然后对目标产品所有评论的综合估分进行平均,获得产品估分,公式如下:
scoreP=∑score/n
式中,n为用户评论个数。
- 还没有人留言评论。精彩留言会获得点赞!