一种基于半监督的迁移学习分类方法与流程
本发明涉及机器学习
技术领域:
,特别是涉及一种基于半监督的迁移学习分类方法。
背景技术:
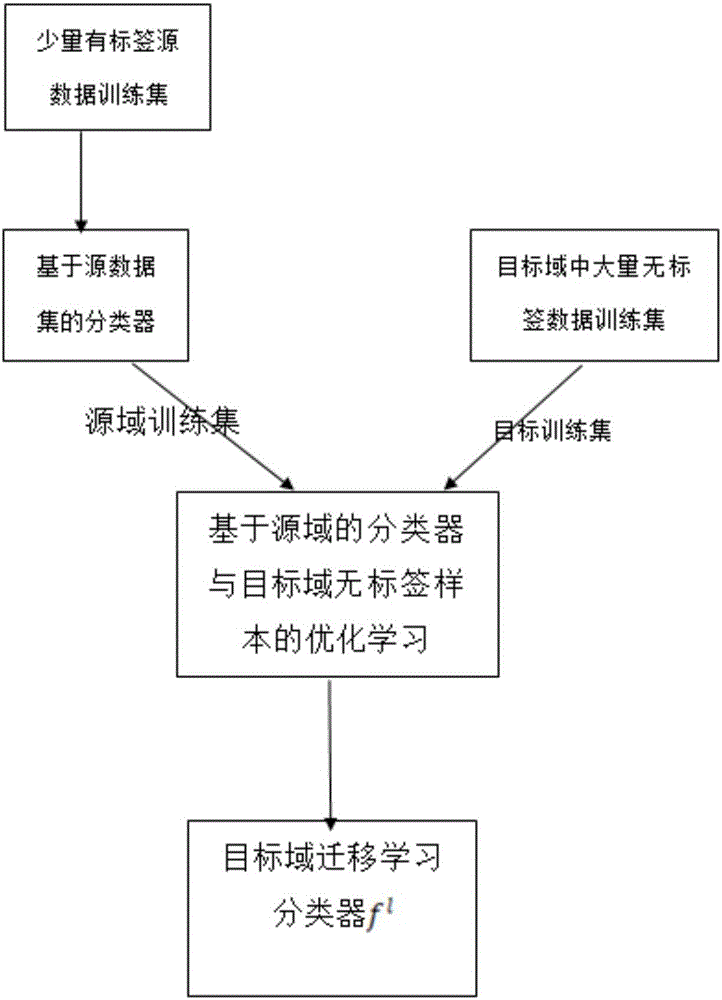
:目前,迁移学习是近几年兴起的一种学习模式,广泛应用于机器学习和数据挖掘中,其通过利用相似领域中大量数据来帮助新领域目标任务的学习。迁移学习不仅不对训练数据与测试数据作同分布的要求,还不要求目标域中有大量的标注数据。迁移学习可以利用原有学习到的模型或过期的标注数据帮助新数据领域更好的学习。迁移学习的目标任务就是利用源域中的知识迁移到目标域中,进而帮助目标域的学习。在机器学习领域中,传统的学习方法有两种:监督学习和无监督学习。半监督学习是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。多任务学习也是机器学习的一种的算法,它跟单任务学习相比较来看,其主要看重任务与任务之间的联系,通过联合学习,同时对多个任务学习不同的回归函数,既考虑到了任务之间的差别,又考虑到任务之间的联系,这也是多任务学习最重要的思想之一。现在,在无监督学习中源域和目标域都是采用大量的无标签的数据集,这样的话就会忽略了数据集中存在的有标签的数据,这就会造成资源的浪费并且不能获取到较高的学习模型,分类精确度较低。况且无监督需要对其结果进行大量的分析然后处理,才能得到可靠的分类结果,这就会造成需要大量的人力物力。并且无监督还存在分类出的集群与地类间,或对应、或不对应,加上普遍存在的“同物异谱”及“异物同谱”现象,使集群组与类别的匹配难度大的现象。技术实现要素:本发明的目的是提供一种基于半监督的迁移学习分类方法,以实现节省资源,提高分类精确度。为解决上述技术问题,本发明提供一种基于半监督的迁移学习分类方法,包括:对源数据集中的有标签的数据进行预处理,得到源数据集的特征分类器;利用多任务学习算法对目标数据集的无标签的数据和所述源数据集的特征分类器进行迁移迭代训练,得到目标分类器;利用目标分类器完成对特征的分类。优选的,所述多任务学习算法适用于监督学习,所述多任务学习算法为基于多任务学习的特征选择算法。优选的,所述对源数据集中的有标签的数据进行预处理,得到源数据集的特征分类器,包括:通过对源数据集中的有标签的数据不断地迭代找到最适合要求的参数,得到源数据集的特征分类器fs。优选的,所述利用多任务学习算法对目标数据集的无标签的数据和所述源数据集的特征分类器进行迁移迭代训练,得到目标分类器,包括:建立多任务学习算法;对所述多任务学习算法的参数进行优化;获取目标分类器。优选的,所述多任务学习算法的目标方程的表达式如下:其中,其中,表示源数据集的特征分类器,ls表示迟钝退化函数,w=w0+wr表示分类器的参数,表示目标数据集的目标分类器,γ、β、c和θ均代表正则化参数,ss代表源数据集在(0,1)上的可行集合,n表示目标数据集的数据样本个数。优选的,所述对所述多任务学习算法的参数进行优化,包括:引入消除变量,对多任务学习算法的目标方程进行更新;引入对偶变量,完成对多任务学习算法的目标方程的拉格朗日变换;通过拉格朗日梯度来得到最优参数。优选的,更新后的目标方程的表达式如下:min12||w0+wr||2+θ2Σi=1nssΣj=1n(fs(xjs)+fl(xil))2+cΣi=1n(ξi+ξi′);]]>其中,ξi代表有标签数据的消除变量,ξ′i代表无标签数据的消除变量。本发明所提供的一种基于半监督的迁移学习分类方法,对源数据集中的有标签的数据进行预处理,得到源数据集的特征分类器;利用多任务学习算法对目标数据集的无标签的数据和所述源数据集的特征分类器进行迁移迭代训练,得到目标分类器;利用目标分类器完成对特征的分类。可见,采用多任务学习算法即基于多任务学习的特征选择算法,由于在复杂的空间中存在着复杂并且海量的数据,采用这种算法能够处理域中各个任务之间的关联性,这是其他算法所不能做到的,该方法将由源数据中的有标签的数据获取到的特征分类器向目标数据中无标签的数据迁移,不断的迭代获取到目标数据集的分类器,从而根据这个分类器就可以在复杂的空间特征中分类出所需要的特征,如此考虑无标签的数据和有标签的数据,两者共同结合,能够节省人力、物力等资源,避免资源的浪费,并且充分利用有标签的数据的先验知识,通过大量未标注数据和少量标签的数据的共同学习,以提高分类精度。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。图1为本发明所提供的一种基于半监督的迁移学习分类方法的流程图;图2为迁移学习自训练分类流程示意图。具体实施方式本发明的核心是提供一种基于半监督的迁移学习分类方法,以实现节省资源,提高分类精确度。为了使本
技术领域:
的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。请参考图1,图1为本发明所提供的一种基于半监督的迁移学习分类方法的流程图,该方法包括:S11:对源数据集中的有标签的数据进行预处理,得到源数据集的特征分类器;S12:利用多任务学习算法对目标数据集的无标签的数据和所述源数据集的特征分类器进行迁移迭代训练,得到目标分类器;S13:利用目标分类器完成对特征的分类。可见,采用多任务学习算法即基于多任务学习的特征选择算法,由于在复杂的空间中存在着复杂并且海量的数据,采用这种算法能够处理域中各个任务之间的关联性,这是其他算法所不能做到的,该方法将由源数据中的有标签的数据获取到的特征分类器向目标数据中无标签的数据迁移,不断的迭代获取到目标数据集的分类器,从而根据这个分类器就可以在复杂的空间特征中分类出所需要的特征,如此考虑无标签的数据和有标签的数据,两者共同结合,能够节省人力、物力等资源,避免资源的浪费,并且充分利用有标签的数据的先验知识,通过大量未标注数据和少量标签的数据的共同学习,以提高分类精度。基于上述方法,具体的,所述多任务学习算法适用于监督学习,所述多任务学习算法为基于多任务学习的特征选择算法,具体为半监督迁移多任务算法。(Semi-supervised-basedtransferMulti-task,半监督迁移多任务)算法是利用相关辅助域的数据集进行迁移来帮助目标域任务的学习,并且利用了半监督迭代的思想来训练分类模型。基于半监督下的多任务迁移学习算法解决复杂特征空间的分类的问题。其中,步骤S11的过程具体为:通过对源数据集中的有标签的数据不断地迭代找到最适合要求的参数,得到源数据集的特征分类器fs。对源数据集中的有标签的数据进行预处理,即通过不断地迭代找到最适合要求的参数,从而我们就得到源数据集中的特征分类器fs。用Ds来表示辅助数据集即源数据集,其里面封装的是少量的有标签的数据。目标数据集采用Dl来表示,对于目标数据集,用来表示大量的无标签的数据,其中包含li个样本{xi,i=1,2,3,.....,n},n表示目标数据集的数据样本个数。步骤S12中,采用了适用于监督学习的多任务学习算法,通过在多任务学习算法中对目标数据集的无标签的数据和源数据集的分类器进行大量的迁移迭代训练,训练出最佳的目标分类器,从而实现对特征的分类。在此步骤中需要进行多任务学习算法的表示、算法参数的优化、评估标准的提出即目标分类器的获取。其中,步骤S12的过程具体包括:S21:建立多任务学习算法;S22:对所述多任务学习算法的参数进行优化;S23:获取目标分类器。具体的,所述多任务学习算法的目标方程的表达式如下:其中,其中,表示源数据集的特征分类器,ls表示迟钝退化函数,w=w0+wr表示分类器的参数,表示目标数据集的目标分类器,γ、β、c和θ均代表正则化参数,ss代表源数据集在(0,1)上的可行集合,n表示目标数据集的数据样本个数。表达式中是源数据集的分类器,本方法最后需要得到的就是目标数据集的分类器进一步的,步骤S22的过程具体包括:S31:引入消除变量,对多任务学习算法的目标方程进行更新;其中,引入消除变量ξ。在参数优化方面,首先引入消除变量ξ来替换掉前面所说的退化函数ls,因为退化函数可能会出现不稳定的现象,所以将退化函数用消除变量ζ来替换掉,更新后的目标方程的表达式如下:min12||w0+wr||2+θ2Σi=1nssΣj=1n(fs(xjs)+fl(xil))2+cΣi=1n(ξi+ξi′);]]>其中,ζi代表有标签数据的消除变量,ζ′i代表无标签数据的消除变量。S32:引入对偶变量,完成对多任务学习算法的目标方程的拉格朗日变换;其中,引入对偶变量实现对公式的拉格朗日变换,方便后面的梯度求最优解;具体的拉格朗日变换过程的公式如下:其中,ai代表有标签数据集的对偶变量,a′i代表无标签数据集的对偶变量,b表示拉普拉斯变换的参数,ω′表示无标签数据集的分类器的参数,表示无标签数据集的特征权重,∈指代常量值,α表示偶变量,ω表示分类器的参数,ξ代表消除变量,fl表示目标数据集的目标分类器,Lp表示拉普拉斯函数。S33:通过拉格朗日梯度来得到最优参数。其中,通过拉格朗日梯度来得到参数最优解的问题。首先,对在梯度求解,ω,b,ξ进行最优化过程中,在这过程中,获得了关于fs和fl的关系,fs和fl的关系的表达公式如下:Σi=1n(ai+ai′)fi(xil)=θΣi=1nssΣj=1n(fs(xjs)+fl(xil))]]>接着对对偶因子ai和a′i同样进行拉普拉斯变换,最后最优解问题的表达式如下:mins,fi,α,α′-12(α-α′)K(α-α′)-ϵ1nl′(α+α′)+mins,fiθ2tns′sB′B;]]>s.t.1nl′α=1nl′α′;]]>其中,K表示每个数据集的核心矩阵,表示在源数据集中的有标签数据排列的向量值,B表示分类器的偏差,指的是在1到n样本中选择到的最合适的目标分类器。其中代表的是源域分类器fs等级排列的矢量值,作用是将每个数据的fs进行排列,直至,选出最适合的fs。最后得到的目标域分类器的表达方程如下:其中,是源数据集分类器的权重,指的是源域即有标签数据集中分类器权重的向量值,βs表示有标签数据集中的正则化参数。从最后的可以看出,完成了将源域中的有标签的数据集分类器向目标域中无标签的数据集迁移,不断的迭代获取到目标域中的分类器,从而我们根据这个分类器就可以在复杂的空间特征中分类出我们自己想要的特征。整个过程可参考图2,图2为迁移学习自训练分类流程示意图。源域即源数据集,目标域即目标数据集。本发明是基于半监督的迁移学习算法来对复杂空间进行分类,迁移学习的算法有很多,但是这里采用基于多任务学习的特征选择算法,这是因为在复杂的空间中存在着复杂并且海量的数据,采用这种算法,可以处理域中各个任务之间的关联性,这是其他算法所不能做到的。本发明采用多任务学习算法在半监督的体系下对复杂的特征空间进行迁移学习,从而对目标域中的特征进行分类。跟本发明相关的方案,虽然其也是利用多任务算法进行迁移学习,但是大多是是采用在无监督的体系下进行的,通过在源领域中采用大量的无标签数据进行迭代获取分类器,然后用在目标域中的无标签数据集,从而进行学习,获得学习器。本发明中用多任务学习算法对目标数据集的无标签的数据和所述源数据集的特征分类器进行迁移迭代训练,得到目标分类器,可以看到,本发明是在半监督学习的体系下进行的迁移学习,进行了半监督和多任务学习算法优化的过程,通过在辅助数据域即源数据域中的有标签的数据集获取到分类器fs,然后将fs迁移到目标域中的无标签的数据集中,通过不断的迭代优化,最后得到我们所需要得目标域的分类器fl,这些都是在多任务学习算法中完成的,所以,本发明通过半监督迁移学习这个过程,包括里面的多任务算法的优化过程和半监督迁移学习迭代过程,获得目标分类器,完成特征分类。由于通过使用少量的有标签数据和大量的无标签数据相结合,远优于只使用少量的有标签的数据或者只使用大量的无标签的数据。并且半监督学习还有如下优点:半监督方法中考虑无标签的数据和有标签的数据,让其共同学习,能够节省人力、物力等资源,避免资源的浪费;通过大量未标注数据和少量标签的数据的共同学习,可以用来降低获取训练数据分类器的困难度;可充分利用有标签数据的先验知识,预先确定分类的类别来可控制训练样本的选择,并可通过反复检验训练样本,以提高分类精度。多任务学习是相对于单任务学习模式而言的,其优势就在于而多任务学习则看重任务之间的联系,通过联合学习,对多个任务学习,既考虑到了任务之间的差别,又考虑到任务之间的联系,这也是多任务学习最重要的思想之一,既能发掘这些子任务之间的关系,同时又能区分这些任务之间的差别。在半监督迁移学习中,对于特征的选取,还是有很多算法的。像半监督模式下的Self-Trainingsvm算法,自学习算法,多视角学习算法等等,这些算法都可以利用少量的带标签数据和大量的无标签数据完成相应的迁移学习,但是对于复杂的特征空间,多任务学习算法能够较好的发掘这些子任务之间的关系,同时又能区分这些任务之间的差别,这是其他的算法无法实现的。以上对本发明所提供的一种基于半监督的迁移学习分类方法进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1