Git中央仓库管理系统及控制方法与流程
本发明涉及计算机技术领域,特别涉及一种分布式多中心Git中央仓库管理系统及控制方法。
背景技术:
随着分布式源码管理工具Git的流行,出现了GitHub、GitLab、OSC、Coding、GitCoffee等Git的中央仓库管理软件。中央仓库管理由于要存储大量的代码仓,所以要解决存储容量可扩展的问题,以及多个研发中心跨地域访问的问题。
现有的中央仓库管理系统,以Gitlab为代表,大部分都使用了分布式文件系统(DFS)作为仓库容量扩展的手段。分布式文件系统可以动态扩展容量,然而,由于Git仓库由大量小文件组成,而分布式文件系统都不适合大量的小文件存储的场景,所以存储效率低,IO读写性能差。因此,分布式文件系统的应用给中央仓库管理系统的性能造成了巨大的限制(参见图1)。
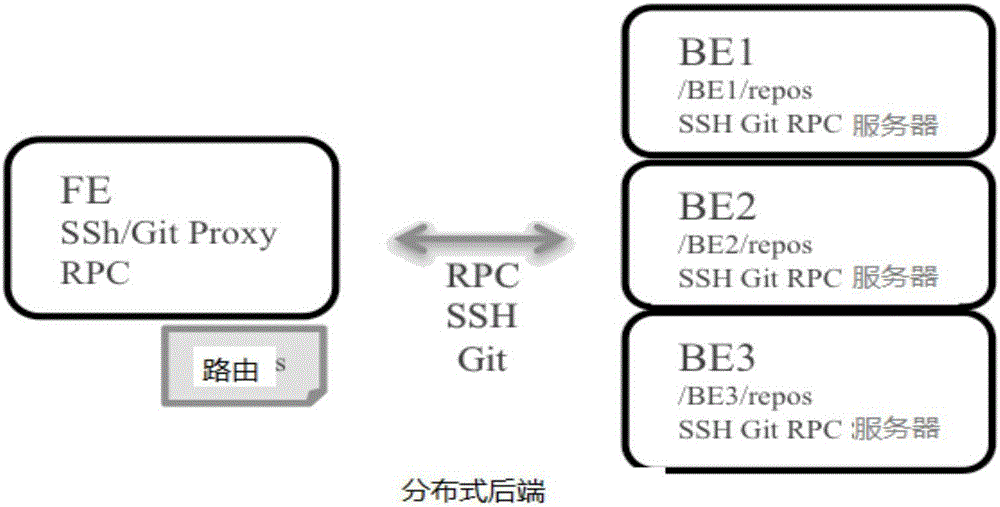
另外,现有的中央仓库管理系中,以GitHub为代表,使用了前后台远程调用的方式来扩展存储容量。这种方式解决了容量动态扩展,但是GitHub使用了后端RT-PRC来实现前后端的远程调用(参见图2)。
后端RT-RPC使用Erlang,通过自定义的序列化方式,可以实现多种面向对象语言的对象序列化,能够实现Ruby的远程调用。然而,这需要程序员自己定义好服务接口和Ruby对象映射,这增加了分布式后端实现和维护的复杂程度。
另外,不论是Gitlab,还是Github,都没有解决多个研发中心跨地域访问的问题。而且,在一个公司有多个研发中心的情况下,如果中央仓库位于其中一个研发中心,则其它研发中心访问由于要经过广域网,会造成网络延迟较大,网络流量剧增。
技术实现要素:
针对以上问题,本发明的目的在于提供一种读写分离的、多个研发中心可异地访问的分布式多中心Git中央仓库管理系统。
为实现以上目的,本发明提供以下技术方案:
一种Git中央仓库管理系统,其包括:多个后端,其包括本地后端和其他远程后端,所述多个后端用于存储仓库;前端,其用于通过远程调用来访问后端上的仓库;以及同步模块,其用于使所述多个后端上存储的仓库同步。
本发明的有益效果在于:
本发明使用dRuby实现了Git仓库的Ruby远程访问,解决了Git仓库的容量的动态扩展问题以及多个研发中心跨地域访问的问题,同时大大提升了读写速度,降低了基于Ruby程序开发分布Git仓库的复杂度,并且提升了系统性能;本发明还实现了多中心Git仓库的同步,达到读写分离,提升了多个研发中心访问中心仓库的网络速度。
附图说明
图1为现有的采用DFS方式来实现容量扩展的示意图。
图2为现有的采用分布式调用来实现容量扩展的示意图。
图3为本发明的分布式多中心Git中央仓库管理系统的示意图。
图4为本发明的基于dRuby的Git远程调用的流程示意图。
图5是描述用于控制Git中央仓库的控制方法的图。
具体实施方式
下面,参照附图对本发明的具体实施例做进一步说明,请注意,以下实施例对本发明仅仅是例示性的,并且决不旨在限制本发明的范围。
如图1所示,为现有的采用分布式文件系统(DFS)方式来实现容量扩展的示意图。其中,共享资源驻留在多台服务器上的各个共享文件夹中,同时DFS方式不适合大量的小文件存储的场景。
如图2所示,为现有的采用分布式调用来实现容量扩展的示意图。其中,GitHub使用了前后台远程调用的方式来扩展存储容量,其使用了后端RT-PRC来实现前后台远程调用,这需要程序员自己定义好服务接口和Ruby对象映射,增加了分布式后端实现和维护的复杂程度。
对于Ruby语言,自从1.9.3版本之后,其内部实现了dRuby模块,实现分布式远程调用,dRuby使用自己定义的协议,不需要任何外部协议就能实现编码,使得远程调用程序更容易编写和维护。同时dRuby的proxy机制最大限度地使用了缓存,提高了系统性能。
因此,本发明直接采用dRuby来实现远程调用,使得系统功能和性能都有很大提高。
下面参考图3描述根据本发明一个实施例的分布式多中心Git中央仓库管理系统10。如图3示出了本发明的分布式多中心Git中央仓库管理系统10的示意图。其中,本发明的分布式多中心Git中央仓库管理系统10包括多个后端101,其用作数据存储仓库,例如存储代码。所述多个后端101分布在多个中心。图3的实施例中具有两个中心,分别为主中心100和分中心110。本领域技术人员容易理解,本实施例的分布式多中心Git中央仓库管理系统10可以具有多于两个的中心。并且主中心和分中心也并非是限制性的,多个中心的地位可以是平等的。以下以主中心100和分中心110为例进行说明。
图3中示出主中心100和分中心110通过广域网进行通讯。但本领域技术人员容易理解,本发明不限于此。主中心100和分中心110例如可通过有线或无线个人域网(PAN)、局域网(LAN)、城域网(MAN)、等等进行通讯。
根据一个优选实施例,主中心100和分中心110包括相同数量的后端101,例如均包括后端BE1、BE2和BE3。主中心的后端分别相对应。例如分中心110的后端BE1、BE2和BE3分别是主中心的后端BE1、BE2、BE3的镜像。
图3的实施例中,主中心100还包括前端(FE)102,分中心110也 包括前端112。前端102和112分别可供主中心100和分中心110的用户就近访问。由于主中心的后端和分中心的后端分别存储有数据或者数据的镜像,因此用户可以就近访问当地的前端,减少网络延迟和网络流量,大大提高用户读取仓库的速度。
前端102、112还可以对用户访问进行权限检查,例如确认用户是否具有对该中心进行读和/或写操作的权限,并且根据权限检查的结果进行下一步操作,例如拒绝用户访问,或按照用户的请求对后端进行读写操作。
图3实施例中的分布式多中心Git中央仓库管理系统10中,主中心100还可包括路由模块103,分中心110也可包括路由模块113。路由模块103和113有相应的前端102、112调用,用于根据路由规则定位存储有用户所需代码的后端。本领域技术人员容易理解,对于主中心100和分中心110,路由模块都不是必须的。例如前端102和112可分别具有查询功能,根据用户输入而查询到相应的后端。但当存储量大、后端数目多的时候,具有路由模块是优选的,因为设置优化的路由规则,可以减少查询、定位所需的时间成本,提高用户体验质量。
图3实施例中的分布式多中心Git中央仓库管理系统10中,主中心100还包括同步模块104,分中心110也包括同步模块114。
本领域技术人员理解,本实施例的分布式多中心Git中央仓库管理系统10也可包括一个统一的同步模块,而非在各个中心中包括单独的同步模块。以下以各个中心分别包括各自的同步模块为例进行说明。
同步模块104和114用于同步主中心100和分中心110的后端的存储数据和作业。其中,主中心100的同步模块104通过状态同步服务生成同步作业;分中心110的同步模块114通过状态同步服务来同步主中心生成的同步作业,并且更新同步状态。例如当主中心100的后端BE1接受了写入操作时,同步模块104和114可以进行数据同步,更新分中心110的后端BE1的数据。同样,当分中心110的后端BE2接受了写入操作时,同步模块104和114可以进行数据同步,更新主中心110的后 端BE2的数据。同步模块104和114之间可以使用标准的Git协议。二者之间的同步可以是实时的,例如当主中心100和分中心110中的一个的后端数据被更新时,自动触发同步。二者之间的同步也可以是非实时的,例如定时更新。也可以根据具体需求而设定一定的同步规则。
在各个中心,前端可以对用户访问进行权限检查,当确认用户具有对应的读写权限时,调用路由模块。路由模块根据路由规则,发现仓库所在的后端,然后使用RPC远程调用该后端,这样用户可以访问位于该后端的仓库内容。
另外,根据本发明的一个优选实施例,分中心110的前端112可以访问主中心100的后端。反之,主中心100的前端102也可以访问分中心110的后端。这样例如在主中心100和分中心110之间尚未进行同步时,也能够保证用户可以访问最新的数据。例如主中心100和分中心110均设有同步状态标记,例如可以为“已同步”或者“未同步”。例如在主中心100的后端已经进行更新的情况下,通过前端产生同步操作,发送给状态同步模块,状态同步模块通过状态同步服务生成同步作业,并向所有分中心指出应该同步该同步作业;同时将所有分中心的同步状态设置为未同步。
以下分别描述主中心和分中心的读/写操作。
当用户在主中心执行写操作时,首先,用户发出Git写操作命令,该命令被发送到本地前端。其次,前端调用路由模块,路由模块根据路由规则,查找仓库在本地所处的后端;然后前端使用RPC远程调用该后端,将内容写入后端。然后,前端产生同步操作,发送给状态同步模块,状态同步模块通过状态同步服务生成同步作业,并向所有分中心指出应该同步该同步作业;同时将所有分中心的同步状态设置为未同步。最后,各个分中心状态同步模块通过Git协议,同步主中心的Git仓。各个分中心完成同步之后,把自身的同步状态设置为已同步。在所述远程调用中,除了dRuby之外,还可以使用xmlrpc、thrift等远程调用协议。
然后,当用户在分中心执行读操作时,首先,用户发出Git写读作命 令,该命令被发送到本地前端。然后,前端查看本中心的同步状态,查看同步状态是已同步还是未同步。如果状态是已同步,则前端调用路由模块,路由模块根据路由规则,查找仓库在本地所处的后端;然后前端使用RPC远程调用访问后端上的仓库内容,返回给客户。如果状态是未同步,则前端调用路由模块,路由模块根据路由规则,查找仓库在主中心所处的后端;然后前端使用RPC远程调用访问后端上的仓库内容,返回给客户。在所述远程调用中,除了dRuby之外,还可以使用xmlrpc、thrift等远程调用协议。
这样,当分中心的用户读仓库时,分中心前端先检查同步状态。如果同步状态为已同步,则访问本地后端。如果同步状态为未同步,则访问主中心后端。由此,实现在本地完成读操作,大大缓解网络延迟。
当用户在分中心执行写操作时,与在主中心执行写操作类似地,首先,用户发出Git写操作命令,该命令被发送到本地前端。其次,前端调用路由模块,路由模块根据路由规则,查找仓库所在的后端,然后前端使用RPC远程调用该后端,将内容写入后端。然后,前端产生同步操作,发送给状态同步模块,状态同步模块通过状态同步服务生成同步作业,并向主中心指出应该同步该同步作业。最后,主中心状态同步模块通过Git协议,同步分中心的Git仓。在所述远程调用中,除了dRuby之外,还可以使用xmlrpc、thrift等远程调用协议。
当用户在主中心执行读操作时,首先,用户发出Git写读作命令,该命令被发送到本地前端。其次,前端调用路由模块,路由模块根据路由规则,查找仓库在主中心所处的后端。然后,前端使用RPC远程调用访问后端上的仓库内容,返回给客户。在所述远程调用中,除了dRuby之外,还可以使用xmlrpc、thrift等远程调用协议。
其中,当用户在分中心执行写操作时,可以将写操作一起写入多个分中心的后端,这样,可以在多个分中心执行读写操作,实现多中心的读写分离。例如,用户在一个分中心执行写操作时,可以将其一起写入多个分中心,然后,用户可以在该多个分中心中的任何一者中执行读写 操作,由此达到读写分离。
由以上内容可知,在任何时候,当用户提交代码时(即执行写操作时),都会被写入到主中心。位于各个后端的所有仓库的内容,在其对应的中心,都有一份完整备份。
下面,以基于dRuby来实现Git仓库的Web访问的前后台分离为例,对本发明的远程调用的过程进行说明。
如图4所示,为本发明的基于dRuby的Git远程调用的流程示意图。其中,在一个中心,前端对用户访问进行权限检查,确认用户被授权之后,调用路由模块,根据路由规则,发现仓库所在的后端,然后使用RPC远程调用访问位于后端上的仓库内容。Web逻辑使用Ruby语言开发,针对Git仓库,封装了相应的RubyGitObject来访问Git仓库数据。
为了实现远程访问其他终端上的Git仓库,首先,Git仓库所在主机(后端)启动作为DrbServer,Web逻辑所在主机(前端)作为DrbClient,DrbServer首先提供一组接口,允许DrbClient根据仓库的名称,访问对应仓库的内容。DrbServer根据RubyGitObject的特征,返回两种类型的Object。一种为Re前端rence型的object,此种类型的object返回到client后,作为一个代理,代理到server侧的DrbObject,以后每次方法调用,都是一次远程访问。另一种为Value型的object,此种类型的object返回RubyGitObjects,其中包含所需的Git仓库数据。
根据RubyGitObjects的特点,实现为Re前端rence型的有:repository、blame、MergeRepo、OnlineEdit。实现为Value型的有blob、commit、tree、diff、tag。DrbInterface Object作为一个Re前端rence型的object被作为Server的Front Object,使用Ruby的method_missing机制,在client与server之间提供其他所有GitObject映射。
另外,为了实现多中心读写分离,本发明采用了状态同步模块,状态同步模块通过使用状态同步服务,实现状态和作业的同步,并由此实现读写分离。
下面,具体介绍本发明的多个中心之间实现作业和状态同步的详细 过程。
首先,介绍路由数据结构。其中,各中心使用共享Redis来存储所有的仓库、后端的仓库路由以及同步状态信息。
仓库路由保存仓库所在的location和backendCluster。在redis中,存在名为repoMap的哈希表来保存所有的仓库路由。该哈希表的Key为repo的path(username/repo),值为其存储的后端组(locationName_backendClusterName,e.g.BJ_backendCluster1)。
状态数据保存仓库所在的后端的同步状态信息。各个仓库所在的后端的状态,用名为repoPath_syncStatus的哈希表来保存。该哈希表的key为IP,值为“state&time”。其中,State当前取值为0时,表示未同步;取值为1时表示已同步。
当系统初始化时,路由信息为空,在项目创建时,生成路由信息。项目的状态信息在项目创建时生成,并且项目的状态信息只会根据写状态而改变,但不会消失。
后端组集合记录每个后端组中的后端:使用集合来保存,集合的名称为locationName_backendClusterName_hosts,值为后端的IP。
后端组的Maser成员为一个有效时间为5秒(可配置)的字符串,key格式为,locationName_backendClusterName_master,值是master的IP。
后端组成员的存活状态由一个有过期时间(可配置)整数值表示,key为IP_alive,值为1。如果存在则表示活,不存在表示不活。
后端组资源分别为:
location_backendCluser1_storageFree:integer
location_backendCluser1_cpuIdle:integer
location_backendCluser1_memFree:integer。
后端成员资源分别为:
ip1_cpuIdle:integer;
ip1_memFree:integer;
ip1_storageFree:integer。
后端成员同步队列为ip1_queue:tasks。
下面,描述生成/import/Fork新的仓库的过程,其包括以下步骤:
a)根据主中心中各backendCluster的资源使用情况,选择一个backendCluster保存此项目。
b)前端通过gitlab_git_client到主后端上生成项目。
c)生成仓库路由。
d)backendCluster中对应的主后端和从后端。对于主后端(即主中心后端),生成仓库状态数据为已同步+当时时间。对于从后端(即分中心后端),生成仓库状态数据为未同步+当时时间。
e)项目生成成功后,前端在所有的从后端(不管存活状态)中添加同步任务,要求从后端从主后端同步项目。
f)从后端中的同步进程读取从后端中的同步任务,完成同步,完成后更新仓库状态数据为已同步+当时时间。
下面,描述页面修改仓库的过程,其包括:前端(gitlab_git_client)查找路由信息,查找仓库所在的backendCluster。获取本backendCluster的master。前端通过gitlab_git_client到master写入操作。写入完成后,master上的hooks函数,负责在所有的从后端中添加同步任务,要求从后端从主后端同步项目,同时把所有的从节点的同步状态设为未同步+时间戳。从后端中的同步进程读取从后端中的同步任务,完成同步,完成后更新仓库状态数据为已同步+当时时间。
页面读取仓库时,前端(gitlab_git_client)查找路由信息,查找仓库所在的backendCluster。根据backendCluster的各后端的状态,选择一个读取后端。前端通过gitlab_git_client到选出的后端上读操作。
后端同步时,各个后端上都运行多个同步进程(可配置),同步进程监听location_backendCluser1_ip1_queue:tasks上的任务,根据任务完成仓库的同步。每个任务都包括:同步要同步的仓库,生成同步任务的时间。如果此仓同步状态已经为已同步,则不做同步操作,任务完成。执行同步操作成功,如果生成同步任务的时间大于等于仓库状态数据中为 同步的时间,则标注状态为已同步+当前时间,同步完成。执行同步操作失败,则把此任务重新插入任务队列。
另外,各个后端上都运行有资源检查守护进程,此进程间隔(可以默认为1天)上报本后端storeage free、cpu idle、mem free,并且定期(可以默认为5秒)更新本后端的alive状态,同时抢注自己为maser。
每次上报完本后端的资源使用情况后,更新本后端所在后端组的资源使用情况:更新本后端组的storage Free,为本组中最小后端的storageFree。更新所有活的后端的CPU Idle的平均值。更新所有活的后端的MeM Free的平均值。
各个后端中的后端Daemon定期更新本后端的存活状态,并且竞争成为Master。原则上Master保持稳定,竞争成功的后端会长期保持为Master,直到该后端发生故障(硬件故障、网络故障等等)或者运维人员的主动切换、关机时才会发生Master的切换。切换的原理是当前一个Master的Key在Redis中过期后,第一个通过Redis的SETNX操作设置自己为Master的后端会操作成功,其余的后端会因为键值已存在而抢注失败。
在Master切换成功后,新Master应将自己所有仓的同步状态设置为已同步(仅仅设置Redis中的同步状态,不做真正的GIT同步)。为了保证可靠性,在设置同步状态期间,新Master应将自己节点的在线状态暂时设置“下线”,并且拒绝这段时间的所有写操作(SSH直接断开连接,Web显示维护中)。当完成所有仓的同步状态设置完成后,将Master节点的在线状态设置为“上线”。
下面参考图5描述根据本发明另一个实施例的用于控制Git中央仓库的控制方法500。该控制方法涉及到如何在包括多个仓库中心的分布式Git中央仓库之间同步数据(例如计算机软件代码)的方法。
如图5所示,在步骤501,首先接收来自用户的对所述多个仓库中心中的一个仓库中心执行更新的指令。该更新指令例如计算机软件代码的修改、删除、添加、合并等等。
在接收到该用户指令后,可选地,可以进行用户身份或者权限校验。如果校验通过,则继续进行以下步骤。
接下来,在步骤502,按照该用户指令,更新所述一个仓库中心。例如修改、删除、添加、合并计算机软件代码。
接下来,在步骤503,根据步骤502,对所述多个仓库中心中的其他仓库中心执行同步操作,使得所述其他仓库中心与该仓库中心同步,保持各个仓库中心之间数据的一致性。
根据该实施例的一个变形,对所述多个仓库中心中的其他仓库中心执行同步操作之前,将所述其他仓库中心的同步状态标记设置为“未同步”,并且在对所述多个仓库中心中的其他仓库中心执行同步操作之后,将所述其他仓库中心的同步状态标记设置为“已同步”。
根据该实施例的一个变形,使用标准Git协议来执行所述同步操作。
根据该实施例的一个变形,还包括:当接收到用户对所述多个仓库中心中的一个仓库中心执行读取指令时,若所述一个仓库中心的同步状态标记为“未同步”,则读取其他的同步状态标记为“已同步”的仓库中心的数据。
使用本发明,如果用户有多个研发中心,则可以轻松的实现仓库在各个研发中心的备份。同时保证位于同一个研发中心的用户在读仓库的时候,使用在本研发中心网络中的仓库备份。这大大提高了用户读仓库的速度,减少了网络延迟和网络流量。另外,基于dRuby的Git远程调用,使得远程调用性能和可维护性大大的提高,使系统更加稳定。
虽然参照示例性实施例对本发明进行了描述,但是应当理解,本发明不限于所公开的示例性实施例。应当对所附权利要求的范围给予最宽的解释,以使其涵盖所有这些变型例以及等同的结构和功能。
- 还没有人留言评论。精彩留言会获得点赞!