一种基于本体知识库的半自动日志分析方法及系统与流程
本发明涉及日志分析技术领域,尤其涉及一种基于本体知识库的半自动日志分析方法及系统。
背景技术:
本体(Ontology)的概念诞生于古希腊哲学领域,对于本体,国内认知度较高的一种翻译是本体论,从上个世纪90年代至今,本体论已经发展成为人工智能领域最具吸引力的课题之一,本体论吸引了国内外诸多学者的关注目光,并被广泛地应用到包括物理领域、生物领域、化学领域、医学领域以及语言学领域在内的众多学科领域中。
然而,对于将本体论应用到日志分析的报道几乎没有,目前通常需要耗费巨大的人力资源去分析日志,完成debug工作。
因此,现有技术还有待于改进和发展。
技术实现要素:
鉴于上述现有技术的不足,本发明的目的在于提供一种基于本体知识库的半自动日志分析方法及系统,旨在解决现有的日志分析方法,人力资源消耗大、效率低的问题。
本发明的技术方案如下:
一种基于本体知识库的半自动日志分析方法,其中,包括步骤:
A、当程序运行出现异常事件时,获取异常日志和用于对比的正常日志;
B、访问本体知识库,判断所述异常事件是否存在于所述本体知识库中,当是时,则将标志位clusterMark设置为false,同时在本体知识库中取出所述异常事件对应的特征值集合,进入步骤C;当否时,则将标志位clusterMark设置为true,通过聚类分析从本体知识库中找出与所述异常事件距离最近的簇,并取出所述簇的特征值集合,进入步骤C;
C、对特征值集合中的特征值进行优先级排序,按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当是时,则记录所述异常日志中的异常特征值,同时设置标志位unReaValMark为true,进入步骤D;
D、判断标志位clusterMark是否为false,当是时,则根据本体知识库的描述,输出结果分析报告,进入步骤G;当否时,则进入步骤E;
E、更新概念格和本体知识库;
F、判断标志位unReaValMark是否为true,并根据判定结果做出相应的处理,进入步骤G;
G、将各操作信息数据更新到关联数据库中,结束流程。
较佳地,所述的基于本体知识库的半自动日志分析方法,其中,所述步骤C具体包括:
C1、采用公式计算特征值的优先级,并将所述特征值按优先级高低排序,Pe值越小,表示优先级越高,其中,e为特征值,ωe为调控系数,ke为核心系数,所述ke通过公式计算所得,其中所述fe为特征值e的出现频次,所述ne为特征值e对应的充分必要事件的个数;
C2、按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当检查到异常日志中存在一个异常特征值时,则结束检查。
较佳地,所述的基于本体知识库的半自动日志分析方法,其中,所述步骤D具体包括:
D1、当判定标志位clusterMark为false时,则根据本体知识库的描述,输出结果分析报告,同时根据异常特征值,查找所述本体知识库中与异常特征值有关联的事件,输出现象预测报告,进入步骤G;
D2、当判定标志位clusterMark为true时,则进入步骤E。
较佳地,所述的基于本体知识库的半自动日志分析方法,其中,所述步骤F具体包括:
F1、当判定标志位unReaValMark为true时,表明异常特征值存在于更新后的本体库中,则根据更新后的本体知识库的描述,输出结果分析报告,进入步骤G;
F2、当判定标志位unReaValMark为false时,表明异常特征值不存在与更新后的本体库中,直接进入步骤G。
较佳地,所述的基于本体知识库的半自动日志分析方法,其中,所述操作信息数据具体包括:
结果分析报告、现象预测报告、新增异常特征值、新增异常事件、新增概念格节点以及新增日志。
一种基于本体知识库的半自动日志分析系统,其中,包括:
获取模块,用于当程序运行出现异常事件时,获取异常日志和用于对比的正常日志;
特征值提取模块,用于访问本体知识库,判断所述异常事件是否存在于所述本体知识库中,当是时,则将标志位clusterMark设置为false,同时在本体知识库中取出所述异常事件对应的特征值集合,进入检查模块;当否时,则将标志位clusterMark设置为true,通过聚类分析从本体知识库中找出与所述异常事件距离最近的簇,并取出所述簇的特征值集合,进入检查模块;
检查模块,用于对特征值集合中的特征值进行优先级排序,按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当是时,则记录所述异常日志中的异常特征值,同时设置标志位unReaValMark为true,进入第一判断模块;
第一判断模块,用于判断标志位clusterMark是否为false,当是时,则根据本体知识库的描述,输出结果分析报告,进入第二更新模块;当否时,则进入第一更新模块;
第一更新模块,用于更新概念格和本体知识库;
第二判断模块,用于判断标志位unReaValMark是否为true,并根据判定结果做出相应的处理,进入第二更新模块;
第二更新模块,用于将各操作信息数据更新到关联数据库中,结束流程。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述检查模块具体包括:
排序单元,采用公式计算特征值的优先级,并将所述特征值按优先级高低排序,Pe值越小,表示优先级越高,其中,e为特征值,ωe为调控系数,ke为核心系数,所述ke通过公式计算所得,其中所述fe为特征值e的出现频次,所述ne为特征值e对应的充分必要事件的个数;
检查单元,用于按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当检查到异常日志中存在一个异常特征值时,则结束检查。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述第一判断模块具体包括:
第一输出单元,用于当判定标志位clusterMark为false时,则根据本体知识库的描述,输出结果分析报告,同时根据异常特征值,查找所述本体知识库中与异常特征值有关联的事件,输出现象预测报告,进入第二更新模块;
第一跟进单元,用于当判定标志位clusterMark为true时,则进入第一更新模块。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述第二判断模块具体包括:
第二输出单元,用于当判定标志位unReaValMark为true时,表明异常特征值存在于更新后的本体库中,则根据更新后的本体知识库的描述,输出结果分析报告,进入第二更新模块;
第二跟进单元,用于当判定标志位unReaValMark为false时,表明异常特征值不存在与更新后的本体库中,直接进入第二更新模块。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述操作信息数据具体包括:
结果分析报告、现象预测报告、新增异常特征值、新增异常事件、新增概念格节点以及新增日志。
有益效果:本发明提供了一种基于本体知识库的半自动日志分析方法及系统,具体地,基于本体知识库理论,通过将本体知识库应用到智能日志分析领域,初步解放人力,减少了人力资源消耗,同时显著提高了debug工作效率。
附图说明
图1为本发明的一种基于本体知识库的半自动日志分析方法较佳实施例的流程图。
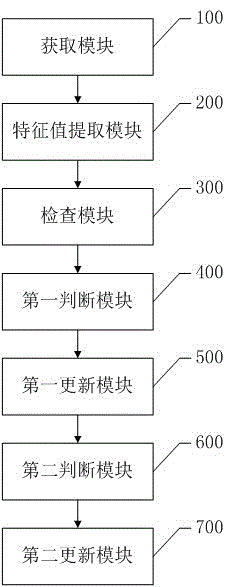
图2为本发明的一种基于本体知识库的半自动日志分析系统较佳实施例的结构框图。
具体实施方式
本发明提供一种基于本体知识库的半自动日志分析方法及系统,为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参阅图1,图1为本发明一种基于本体知识库的半自动日志分析方法较佳实施例的流程图,如图1所示,其包括步骤:
S100、当程序运行出现异常事件时,获取异常日志和用于对比的正常日志;
具体来说,所述正常日志和异常日志需要具有一定的可对比性。
S110、访问本体知识库,判断所述异常事件是否存在于所述本体知识库中,当是时,则将标志位clusterMark设置为false,同时在本体知识库中取出所述异常事件对应的特征值集合,进入步骤S120;当否时,则将标志位clusterMark设置为true,通过聚类分析从本体知识库中找出与所述异常事件距离最近的簇,并取出所述簇的特征值集合,进入步骤S120;
具体来说,当判定所述异常事件存在于所述本体知识库中时,则直接在本体知识库中取出异常事件对应的特征值集合,进入步骤S120;当判定所述异常事件不存在于所述本体知识库中时,则需要通过聚类分析从本体知识库中找出与所述异常事件距离最近的簇,具体地,本发明可采用常用的K-means算法将所述异常事件和本体知识库中的所有事件进行聚类分析,迭代完成的聚类分析结果会生成多个聚类簇,,找出所述异常事件所述的聚类簇,然后找出所述聚类簇的特征值集合,进入步骤S120。
S120、对特征值集合中的特征值进行优先级排序,按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当是时,则记录所述异常日志中的异常特征值,同时设置标志位unReaValMark为true,进入步骤S130;若检查结束时,还未发现异常,则通过领域专家干预得到新的特征值,并设置标志位unReaValMark为false,进入步骤S140;
进一步,所述步骤S120具体包括:
S121、采用公式计算特征值的优先级,并将所述特征值按优先级高低排序,Pe值越小,表示优先级越高,其中,e为特征值,ωe为调控系数,ke为核心系数,所述ke通过公式计算所得,其中所述fe为特征值e的出现频次,即特征值e在历次分析的日志中出现的频次统计;所述ne为特征值e对应的充分必要事件的个数;
具体地,在细化的方案中,如果一个特征值发现异常,此时如果该特征值不是该事件的充要条件,并不会终止特征值遍历,反之,则立即终止遍历。因此,特征值e对应的充分必要事件的个数越多,则优先检查特征值e可以越多的节省计算资源。
S122、按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当检查到异常日志中存在一个异常特征值时,则结束检查。
具体来说,在上述步骤中,只要找到异常特征值,就跳出循环,不在查找优先级排在异常特征值后面的特征值集合,这样做的优势在于,可以有效的节约计算资源。
S130、判断标志位clusterMark是否为false,当是时,则根据本体知识库的描述,输出结果分析报告,进入步骤S160;当否时,则进入步骤S140;
进一步,所述步骤S130具体包括:
S131、当判定标志位clusterMark为false时,则根据本体知识库的描述,输出结果分析报告,同时根据异常特征值,查找所述本体知识库中与异常特征值有关联的事件,输出现象预测报告,进入步骤S160;
具体地,所述结果分析报告是指debug结果,即给出所述异常事件对应的根本原因的详细描述;所述现象预测报告的功能是:参照多次迭代出的概念格,给出已出现的异常特征值还会影响到的现象集,所述现象集根据层级可以分为:必定发生的现象、可能发生的现象,这项功能充分利用了本体知识库的特性。
进一步,所述现象预测报告还具有更多的现实意义,比如测试资源的节约,同源现象的debug资源节约以及紧急bug的风险计算等。
S132、当判定标志位clusterMark为true时,则进入S140、
S140、更新概念格和本体知识库;
具体地,在本发明中,所述概念格,它是一种根据形式背景中对象和属性之间的二元偏序关系建立的层次结构,是形式概念分析理论中的核心数据结构。所述概念格中的节点体现了概念内涵和外延的统一,非常适合规则的发现和推理,目前这种数据结构被广泛应用于不同的领域中,在本发明中,所述概念格作为核心数据结构应用与本体知识库的创建中。
进一步,所述形式背景是由事件集合G和属性集合M以及表示G和M之间的关系I组成,在本发明中所述事件集合G中的事件即对应异常事件,所述属性集合M中的属性即对应异常特征值。
具体来说,对所述概念格进行更新,即通过添加新的异常事件或新的异常特征值对概念格进行更新;进一步,基于概念格对所述本体知识库进行更新这一部分内容已经有成熟的理论基础,不再赘述。
S150、判断标志位unReaValMark是否为true,并根据判定结果做出相应的处理,进入步骤S160;
进一步,所述步骤S150具体包括:
S151、当判定标志位unReaValMark为true时,表明异常特征值存在于更新后的本体库中,则根据更新后的本体知识库的描述,输出结果分析报告,进入步骤S160;
具体地,当判定标志位unReaValMark为true时,表明异常特征值存在于更新后的本体库中,也就是说所述步骤S140中,概念格和本体知识库的更新是由新的异常事件的添加引起的。
S152、当判定标志位unReaValMark为false时,表明异常特征值不存在与更新后的本体库中,直接进入步骤S160。
具体地,当判定标志位unReaValMark为false时,表明异常特征值不存在与更新后的本体库中,也就是说所述步骤S140中,概念格和本体知识库的更新是由新的异常特征值的添加引起的。
S160、将各操作信息数据更新到关联数据库中,结束流程。
具体来说,所述操作信息数据具体包括:结果分析报告、现象预测报告、新增异常特征值、新增异常事件、新增概念格节点以及新增日志。可以将所述关联数据库理解为一个存储着大量的、不完全的、有噪声的数据的容器,它存在的目的是为下一步的指示提取、数据挖掘以及语义分析等提供数据基础。
基于上述方法,本发明还提供一种基于本体知识库的半自动日志分析的系统较佳实施例,如图2所示,其包括:
获取模块100,用于当程序运行出现异常事件时,获取异常日志和用于对比的正常日志;
特征值提取模块200,用于访问本体知识库,判断所述异常事件是否存在于所述本体知识库中,当是时,则将标志位clusterMark设置为false,同时在本体知识库中取出所述异常事件对应的特征值集合,进入检查模块;当否时,则将标志位clusterMark设置为true,通过聚类分析从本体知识库中找出与所述异常事件距离最近的簇,并取出所述簇的特征值集合,进入检查模块;
检查模块300,用于对特征值集合中的特征值进行优先级排序,按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当是时,则记录所述异常日志中的异常特征值,同时设置标志位unReaValMark为true,进入第一判断模块;当检查结束时,还未发现异常,则通过领域专家干预得到新的特征值,并设置标志位unReaValMark为false,进入第一更新模块;
第一判断模块400,用于判断标志位clusterMark是否为false,当是时,则根据本体知识库的描述,输出结果分析报告,进入第二更新模块;当否时,则进入第一更新模块;
第一更新模块500,用于更新概念格和本体知识库;
第二判断模块600,用于判断标志位unReaValMark是否为true,并根据判定结果做出相应的处理,进入第二更新模块;
第二更新模块700,用于将各操作信息数据更新到关联数据库中,结束流程。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述检查模块300具体包括:
排序单元,采用公式计算特征值的优先级,并将所述特征值按优先级高低排序,Pe值越小,表示优先级越高,其中,e为特征值,ωe为调控系数,ke为核心系数,所述ke通过公式计算所得,其中所述fe为特征值e的出现频次,所述ne为特征值e对应的充分必要事件的个数;
检查单元,用于按优先级先后顺序依次检查所述异常日志中与所述特征值对应的值是否异常,当检查到异常日志中存在一个异常特征值时,则结束检查。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述第一判断模块400具体包括:
第一输出单元,用于当判定标志位clusterMark为false时,则根据本体知识库的描述,输出结果分析报告,同时根据异常特征值,查找所述本体知识库中与异常特征值有关联的事件,输出现象预测报告,进入第二更新模块;
第一跟进单元,用于当判定标志位clusterMark为true时,则进入第一更新模块。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述第二判断模块600具体包括:
第二输出单元,用于当判定标志位unReaValMark为true时,表明异常特征值存在于更新后的本体库中,则根据更新后的本体知识库的描述,输出结果分析报告,进入第二更新模块;
第二跟进单元,用于当判定标志位unReaValMark为false时,表明异常特征值不存在与更新后的本体库中,直接进入第二更新模块。
较佳地,所述的基于本体知识库的半自动日志分析系统,其中,所述操作信息数据具体包括:
结果分析报告、现象预测报告、新增异常特征值、新增异常事件、新增概念格节点以及新增日志。
关于上述模块单元的技术细节在前面的方法中已有详述,故不再赘述。
综上所述,本发明提供了一种基于本体知识库的半自动日志分析方法及系统,具体地,基于本体知识库理论,通过将本体知识库应用到智能日志分析领域,初步解放人力,减少了人力资源消耗,同时显著提高了debug工作效率。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!