一种文本话题和情感的联合检测方法及装置与流程
本发明属于机器学习技术领域,尤其涉及一种文本话题和情感的联合检测方法及装置。
背景技术:
联合话题情感混合模型的主要目标是通过对大量的文本集合进行分析、处理,归纳总结并推理出文本所隐含的语义结构和情感倾向,以鉴别其所讨论的话题和情感倾向。近年来,随着移动互联网的迅猛普及和发展,微博、博客、论坛、微信等大量新兴社会媒体不断涌现,使得用户在个人电脑和移动终端表达意见、分享评论变得越来越便捷,因此越来越多的不同年龄段的用户都积极的参与到产品、服务、新闻等的实体评论中。面对海量的数据,如何有效地对其内容进行组织、整理、挖掘和分析,以准确识别出其中包含的观点信息和情感倾向,对于各个行业的企业及时了解用户诉求,掌握市场态势有着重要的现实意义,同时也是自然语言处理领域研究的热点问题。
由于概率话题模型(例如,潜在狄利克雷分布LDA)以词作为基本属性,将文本表示为词的集合,是一种有效捕捉文档隐含话题的无监督学习方法,因此,大部分联合话题情感分析方法是在概率话题模型的基础上进行扩展。然而,现有提出的联合话题情感分析方法,大多只是从数据本身的属性出发,以词为基本特征,基于词共现统计进行话题概率计算,每个词都被看作是一个单一的实体,各词语、语句之间语义层面的联系考虑较少,难以满足实际应用的需要。一般说来,共现次数越多的词,越有可能被分配在同一话题下。但当语料数较少或文本篇幅较短时,文本特征稀疏并且维度较高,这种单纯依靠词频统计进行话题和情感分配的方法往往会因为语义信息不足而造成情感分布和话题分布的结果不够理想。另一方面,这些方法大多都引入了情感种子词,完全依赖这些特有领域的情感知识先验信息来识别语料中的正向和负向词,然而同一个词在不同的语句中可能有着不同的情感倾向。并且当种子词典的词比较少,且比较单一时,这些情感先验的影响就会受到限制,从而降低了获取的话题下情感分布的准确度。
技术实现要素:
本发明的目的在于提供一种文本话题和情感的联合检测方法及装置,旨在解决现有技术的文本情感和话题联合检测准确率不高的问题。
一方面,本发明提供了一种文本话题和情感的联合检测方法,所述方法包括下述步骤:
使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向;
将预先获取的外部语料的词向量设置为所述目标文本的词向量的初始值;
使用预设的话题情感混合模型对输入的目标文本进行训练,以得到所述目标文本中各个情感话题对与词之间的初始分配;
根据所述目标文本中每个词的初始情感倾向、所述词向量的初始值以及所述各个情感话题对与词之间的初始分配,对所述目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到所述目标文本所涉及的话题和情感。
另一方面,本发明提供了一种文本话题和情感的联合检测装置,其特征在于,所述装置包括:
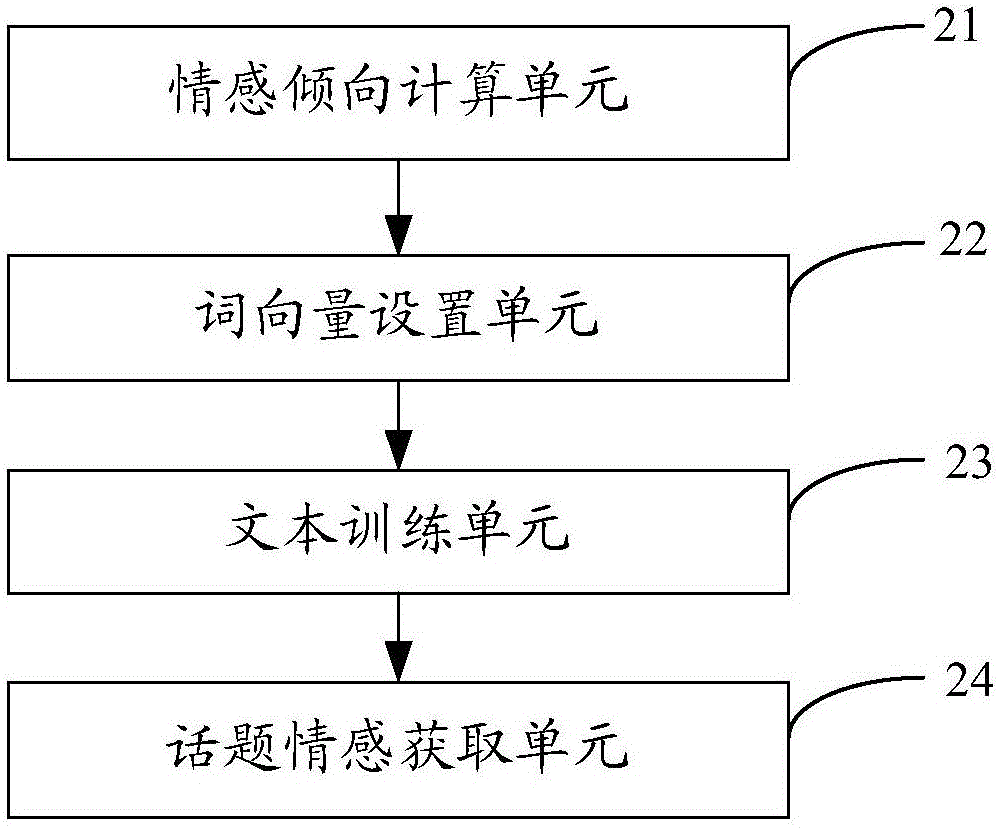
情感倾向计算单元,用于使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向;
词向量设置单元,用于将预先获取的外部语料的词向量设置为所述目标文本的词向量的初始值;
文本训练单元,用于使用预设的话题情感混合模型对输入的目标文本进行训练,以得到所述目标文本中各个情感话题对与词之间的初始分配;
话题情感获取单元,用于根据所述目标文本中每个词的初始情感倾向、所述词向量的初始值以及所述各个情感话题对与词之间的初始分配,对所述目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到所述目标文本所涉及的话题和情感。
本发明使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向,将预先获取的外部语料的词向量设置为目标文本的词向量的初始值,使用预设的话题情感混合模型对输入的目标文本进行训练,以得到目标文本中各个情感话题对与词之间的初始分配,最终根据目标文本中每个词的初始情感倾向、词向量的初始值以及各个情感话题对与词之间的初始分配,对目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到所述目标文本的话题和情感,从而提高了获得的目标文本的话题和情感的准确度。
附图说明
图1是本发明实施例一提供的文本话题和情感的联合检测方法的实现流程图;
图2是本发明实施例二提供的文本话题和情感的联合检测装置的结构示意图;以及
图3是本发明实施例三提供的文本话题和情感的联合检测装置的优选结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的文本话题和情感的联合检测方法的实现流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤S101中,使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向。
在本发明实施例中,接收到用户发送的文本话题和情感获取请求后,使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向。目标文本可以是公用的传统话题检测数据样本,也可以为来自网络的微博、博客、论坛、商品在线评论数据等数据文档。当然,在获取后这些文档后,应对这些文档进行预处理,例如,分词、去停用词、高低频词以及非法字符等,以得到本发明实施例中的目标文本。优选地,使用HowNet词典计算输入的目标文本中每个词的初始情感倾向,以提高目标文本中每个词的初始情感倾向的准确度,加快目标文本的话题和情感获取速度。
在步骤S102中,将预先获取的外部语料的词向量设置为目标文本的词向量的初始值。
在本发明实施例中,外部扩展语料可作为目标文本对应的原始数据的语义补充,使用预设词向量训练程序对获取的外部扩展语料进行预训练,以得到外部扩展语料中各个词语的词向量,进而利用得到的词向量对目标文本的词向量进行初始化。
具体地,外部语料应尽可能地包含目标文本中的所有词语,这样,可保证目标文本中的每个词都能从外部语料获取一个初始的词向量作为该词语义和词义的补充,用于进一步学习词向量和话题向量。优选地,外部扩展语料为维基百科或百度百科,从而得到提高词向量训练的效率。优选地,预设的词向量训练程序为word2vec或者GloVe工具,从而简化词向量的训练过程,提高训练速度,保证了训练结果的稳定性。
在步骤S103中,使用预设的话题情感混合模型对输入的目标文本进行训练,以得到目标文本中各个情感话题对与词之间的初始分配。
在本发明实施例中,预设的话题情感混合模型用于获取目标文本中各个情感话题对与词之间的初始分配。优选地,预设的话题情感混合模型为文本弱监督联合情感-话题检测模型(Weakly Supervised Joint Sentiment-Topic Detection from text,缩写为JST)模型,从而提高各个情感话题对与词之间的初始分配的准确率。
在步骤S104中,根据目标文本中每个词的初始情感倾向、词向量的初始值以及各个情感话题对与词之间的初始分配,对目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到目标文本所涉及的话题和情感。
在本发明实施例中,目标文本可以看成是由多篇文档组成,多篇文档可以涉及相同或不同的情感和话题。具体在获取目标文本所涉及的话题和情感时,可根据目标文本中每个词的初始情感倾向、词向量的初始值以及所述各个情感话题对与词之间的初始分配,对目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤。
在本发明实施例中,预设的话题和情感检测步骤包括:
(1)利用对目标文本的话题向量进行学习,其中,为L2正则化项,μ为正则化因子,vk为话题k对应的话题向量,为话题k下词wi出现的次数,代表词wi对应的词向量表示。这样,可以使得话题向量的学习速度更快、学习准确率更高。
(2)使用计算每篇文档情感和话题向量对应下的词向量概率分布,vk代表话题向量,W为语料库中词典内包含的词的集合,w′i为词典中的词。
(3)根据公式
更新训练目标词对应的情感倾向和话题,其中,表示文本情感下话题的分布,表示文本下情感的分布,表示情感下话题词的分布。α、β、γ表示Dirichlet先验超参数,λ表示服从伯努利分布的参数,ν表示话题向量,ω表示词向量,V、T、L分别表示词典大小、话题个数、情感标签的个数。表示除文档d中的第i个词外,情感l中被分配到话题k的词的个数,表示文档d中的第i个词被分配到情感l的次数,但不包含当前分配,表示除文档d中的第i个词外,情感l下分配到的词的总数,表示当前词i被分配到情感l中话题k的词的次数,但不包含当前分配,表示除当前词i外,情感l下分配到话题k的词的总数。这样,可将词共现的词频统计狄利克雷多项式概率分布元和话题-词向量元MulT(wi|νkωT)结合,充分利用词频统计和词向量的优点,拓展词的语义信息,最终使情感-话题与词语的匹配更精准。
本发明使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向,将预先获取的外部语料的词向量设置为目标文本的词向量的初始值,使用预设的话题情感混合模型对输入的目标文本进行训练,以得到目标文本中各个情感话题对与词之间的初始分配,最终根据目标文本中每个词的初始情感倾向、词向量的初始值以及各个情感话题对与词之间的初始分配,对目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到所述目标文本的话题和情感,从而提高了获得的目标文本的话题和情感的准确度。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如ROM/RAM、磁盘、光盘等。
实施例二:
图2示出了本发明实施例二提供的文本话题和情感的联合检测装置的结构,为了便于说明,仅示出了与本发明实施例相关的部分,其中包括:
情感倾向计算单元21,用于使用预设的情感词典计算输入的目标文本中每个词的初始情感倾向;
词向量设置单元22,用于将预先获取的外部语料的词向量设置为所述目标文本的词向量的初始值;
文本训练单元23,用于使用预设的话题情感混合模型对输入的目标文本进行训练,以得到所述目标文本中各个情感话题对与词之间的初始分配;以及
话题情感获取单元24,用于根据目标文本中每个词的初始情感倾向、词向量的初始值以及各个情感话题对与词之间的初始分配,对目标文本中包括的每篇文档进行扫描,对扫描到的每个训练目标词执行预设的话题和情感检测步骤,以得到目标文本所涉及的话题和情感。
优选地,如图3所示,在本发明实施例中,话题情感获取单元24包括:
词向量学习单元241,用于利用对目标文本的话题向量进行学习,其中,为L2正则化项,μ为正则化因子,vk为话题k对应的话题向量,为话题k下词wi出现的次数,代表词wi对应的词向量表示;
分布计算单元242,用于使用计算每篇文档情感和话题向量对应下的词向量概率分布,vk代表话题向量,代表词wi对应的词向量表示,W为语料库中词典内包含的词的集合,w′i为词典中的词;以及
情感话题更新单元243,用于根据更新训练目标词对应的情感倾向和话题,其中,表示文本情感下话题的分布,表示文本下情感的分布,表示情感下话题词的分布,α、β、γ表示Dirichlet先验超参数,λ表示服从伯努利分布的参数,ν表示话题向量,ω表示词向量,V、T、L分别表示词典大小、话题个数、情感标签的个数,表示除文档d中的第i个词外,情感l中被分配到话题k的词的个数,表示文档d中的第i个词被分配到情感l的次数,但不包含当前分配,表示除文档d中的第i个词外,情感l下分配到的词的总数,表示当前词i被分配到情感l中话题k的词的次数,但不包含当前分配,表示除当前词i外,情感l下分配到话题k的词的总数。
进一步优选地,文本话题和情感的联合检测装置还包括:
语料获取单元30,用于获取外部扩展语料,以作为目标文本对应的原始数据的语义补充;以及
语料训练单元31,用于使用预设词向量训练程序对获取的外部扩展语料进行预训练,以得到外部扩展语料中各个词语的词向量。
优选地,外部扩展语料为维基百科或百度百科,预设词向量训练程序为word2vec或者GloVe工具。优选地,预设的情感词典为HowNet词典,预设的话题情感混合模型为JST模型。
在本发明实施例中,文本话题和情感的联合检测装置的各单元可由相应的硬件或软件单元实现,各单元可以为独立的软、硬件单元,也可以集成为一个软、硬件单元,在此不用以限制本发明。各单元的具体实施方式可参考实施例一的描述,在此不再赘述。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!