多传感器系统数据融合精度的提高方法与流程
本发明涉及目标跟踪技术领域中的多传感器系统数据融合技术,是通过在经典数据融合方法中加入参数模糊整定的自适应加权因子,以实现提高跟踪精度的设计方法。
背景技术:
目标定位与跟踪是依据最佳估计原理,采用数字滤波的计算方法,对传感器接收到的量测进行处理,估计目标运动要素的数据处理过程。量测是指被噪声污染的有关目标状态的传感器观测信息,包括如斜距离、方位角、俯仰角、以及时差等其他信息。目标运动要素一般指目标状态、航向等参数。目标状态主要是指目标的运动分量(如位置、速度、加速度等)。通常,把目标定位与跟踪简称为目标跟踪。
数据融合是针对使用多个或多类传感器的系统而开展的一种信息处理新方法。在多传感器系统中,各种传感器提供的信息具有不同的特征,数据融合通过对各种传感器及其观测信息的合理支配与使用,把在空间和时间上互补与冗余的信息依据某种优化准则组合起来,以获得更多有效的信息。空间目标测量手段逐渐多样化,融合处理技术是降低测量信息不确定性影响,获得稳健、高精度目标跟踪结果的重要方法。
卡尔曼滤波是由R.E.Kalman最早提出的,它是一种线性最小方差估计,采用状态空间方法,在时域内设计滤波器,算法采用递推形式,是实现多传感器位置融合的主要技术手段之一。卡尔曼滤波应用于目标跟踪技术时,用系统状态方程来描述目标的运动特性,其中的状态向量通常由目标的位置、速度和加速度参量构成。用n表示观测系统第n个采样周期,把过程噪声v1(n-1)及观测噪声v2(n)假定为零均值白噪声,则卡尔曼滤波算法可利用观测量集合{z(1),z(2),…,z(n)}对系统状态变量x(n)进行最优估计得出状态估计变量。
定义估计误差自相关矩阵P(n)为:
在每一步卡尔曼递推滤波计算中,遵照最小均方误差准则,通过新息过程及卡尔曼增益的修正解算,得出和估计误差自相关矩阵P(n),并参与下一步递推计算。
参阅图7。在工程运用中将常见的分布式融合结构中,局部滤波为分布传感器的卡尔曼滤波过程,融合单元输出的全局估计是局部估计的线性组合,这里融合单元的作用是实现局部估计的优化组合。假设有L个局部状态估计和相应的局部估计误差自相关矩阵P(1)(n),P(2)(n),…,P(L)(n),且各局部估计互不相关,则全局最优估计及全局估计误差自相关矩阵为:
式中:i为1-L号传感器分系统中的第i个传感器。
由上式可知,若第i个传感器估计精度差,则它对全局估计的贡献就比较小。在分布式数据融合结构中,每个传感器都可独立地处理其自身信息,再进行融合,可以一定程度上克服数据融合数据互联复杂、计算和通信资源要求高等不足,但同时又很难避免一些有效信息的损失。
基于分布式融合系统的思想,融合单元输出的最终状态估计量为各传感器局部状态估计量的线性优化组合。在全局最优估计解算时,引入各局部估计误差自相关矩阵P(i)(n)调节相应局部估计量的权重,若n时刻某传感器的估计精度差,则它对全局估计的贡献就比较小。但实验证明,单凭P(i)(n)的调节力度是比较有限的,若遇到某传感器的误差特别大时,其估计结果仍参与加权求和计算,导致其它较优局部估计信息损失,全局估计精度将不可避免地被大幅拉低。
技术实现要素:
本发明的目的是针对现有技术存在的不足之处,提供一种带较高调节灵敏度加权因子,能有效控制局部不良信息对全局估计影响,优化数据融合全局估计结果,多传感器系统数据融合精度的提高方法。
本发明的上述目的可以通过以下措施来达到,一种多传感器系统数据融合精度的提高方法,其特征在于包括如下步骤:基于多传感器系统分布式数据融合原理框架,在估计精度相对较差或时有较大干扰的传感器系统局部估计分量中,设置一个加权因子λ,并根据λ解算参数α、β设置相匹配的参数模糊整定器;各传感器独立采集量测点迹经局部卡尔曼滤波后,将得出的局部状态估计1-L输入数据融合预处理模块,数据融合预处理模块根据卡尔曼滤波估计误差自相关矩阵的定义,提取各局部估计误差自相关矩阵的第1行第1列分量,在线解算用于量化描述各局部估计误差大小关系的误差比系数r和误差比系数变化率rc;误差比例系数r和误差比系数变化率rc经模糊化接口转换为误差比变量R、误差比变化率变量RC,并输入参数模糊整定器;参数模糊整定器根据λ解算参数α、β工作原理设计的模糊规 则库模糊推理,在线整定α、β取值,针对各种可能出现的R、RC取值给出的对应倍数变量A、指数变量B模糊查询表,供在线查询的A、B取值,将α、β的具体值经过清晰化接口输出至加权因子解算模块;加权因子解算模块调用上述r、α和β的实时运算结果在线解算λ,自适应调节λ的取值;最后,数据融合解算模块引入加权因子λ,通过改进后的数据融合方法实时解算,得出最终全局状态估计。
本发明相比于现有技术具有如下有益效果。
能有效控制多传感器系统局部不良信息对全局估计影响。本发明在估计精度相对较差或时有较大干扰的传感器局部估计分量中设置一个加权因子λ,改进后的引入了λ的数据融合全局状态估计解算方法中,当带λ的传感器分系统误差持续较高或遇到干扰陡增时,其局部估计误差自相关矩阵将被实时自适应缩放,以控制其对全局状态估计的不良影响。
能实现加权因子λ的高灵敏度调节效果,优化数据融合全局估计结果。本发明根据λ的原理特性进一步设计了相匹配的参数模糊整定器,通过在线模糊整定λ的解算参数α、β,结合误差比系数r从倍数和指数关系上在线自适应修订λ的取值大小,从而实现λ根据所在分系统误差具体情况高灵敏度调节缩放相应局部估计误差自相关矩阵,优化数据融合全局估计结果。
改进的数据融合方法易于工程实现。本发明参数模糊整定器在线整定λ解算参数α、β的流程中,模糊推理过程可离线运算。发明人已针对各种可能出现的误差比变量R、误差比变化率变量RC取值,给出对应的倍数变量A、指数变量B模糊查询表,可供直接在线查询A、B取值,再经清晰化接口输出α、β的具体值。计算量小,易于工程实现。
本发明引入加权因子λ改进了数据融合全局估计解算公式;当带加权因子的传感器m分系统误差持续较高或遇到干扰陡增时,本发明解算方法能通过λ的实时值λ(m)(n)自适应缩放该分系统第n个采样周期的局部估计误差自相关矩阵。
附图说明
以下结合附图和实施例进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
图1是本发明改进的数据融合系统原理图。
图2是图1中参数模糊整定器的结构图。
图3是图2参数模糊整定器的原理框图。
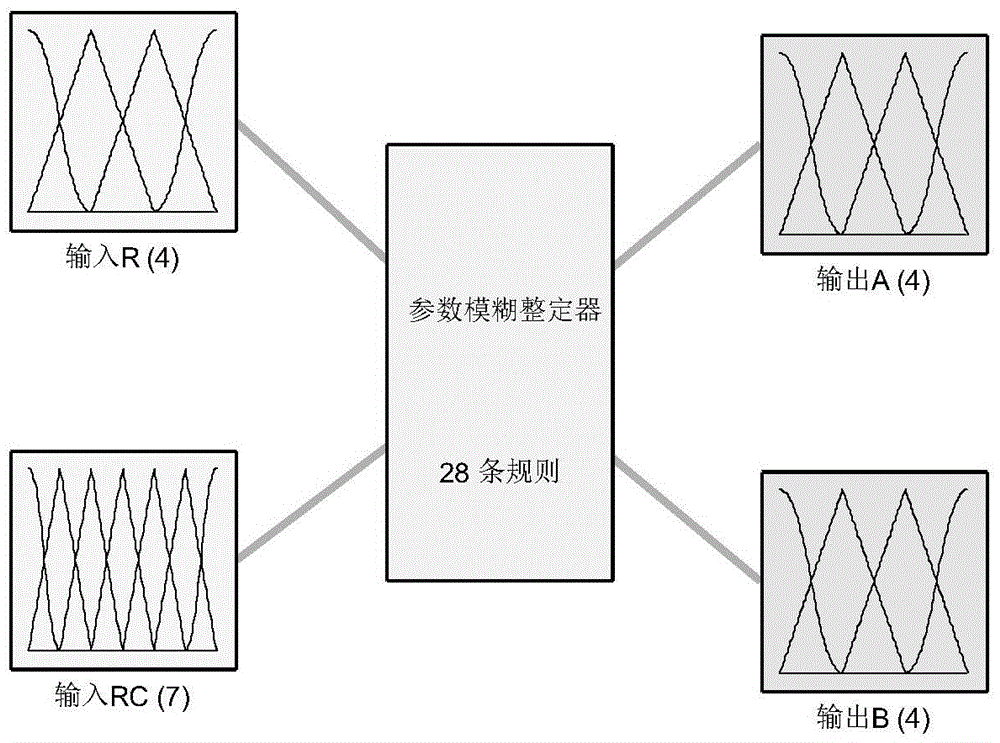
图4是图3中四个语言变量R、RC、A、B的隶属函数分布。
图5是传统数据融合方法状态估计均方根误差统计示意图。
图6是本发明数据融合方法状态估计均方根误差统计示意图。
图7是本发明基于多传感器系统分布式数据融合系统原理图。
具体实施方式
参阅图1。在以下描述的实施例中,多传感器系统由L个传感器分系统独立测量滤波的L组局部状态估计,然后通过数据融合解算得出全局状态估计。根据本发明,基于多传感器系统分布式数据融合原理框架,在估计精度相对较差或时有较大干扰的传感器局部估计分量中,设置一个加权因子λ,并根据λ的原理特性设计相匹配的参数模糊整定器对其取值在线自适应修订;各传感器独立采集量测点迹并进行局部卡尔曼滤波,将得出的局部状态估计1-L输入数据融合预处理模块,在线解算分系统加权因子λ,然后进行带自适应加权因子的数据融合解算,得出最终全局状态估计;数据融合预处理模块,根据卡尔曼滤波估计误差自相关矩阵的定义,提取各局部估计误差自相关矩阵的第1行第1列分量,在线解算用于量化描述各局部估计误差大小关系的误差比系数r和误差比系数变化率rc;参数模糊整定器在线整定α、β取值,误差比例系数r和误差比系数变化率rc经过模糊化接口转换为语言变量R、RC,输入模糊整定器,通过专门针对λ解算参数α、β工作原理设计的模糊规则库模糊推理,输出语言变量A、B,再经过清晰化接口出参数α、β的具体值,为利于工程实现,本发明模糊推理过程可离线运算,已针对各种可能出现的R、RC取值给出了模糊查询表,实现α、β对应参数模糊整定器输出量语言变量A、B的在线查询;加权因子解算模块调用r、α和β的实时运算结果在线解算λ,以实现λ取值的自适应调节;数据融合解算模块通过改进后的引入了加权因子λ的数据融合解算方法实时解算全局状态估计。当带λ的传感器系统误差持续较高或遇到干扰陡增时,进行带自适应加权因子的数据融合解算,自适应缩放该传感器系统局部估计误差自相关矩阵,优化全局状态估计精度。其中,加权因子λ的取值应遵循如下规律:
(1)当r=1,λ=1即不起加权作用;
(2)当r<1,表明带加权因子的分系统观测精度相对较好,此时保持或减小λ的数值以保持或扩大此局部估计量在全局数据融合中的权重优势。
(3)当r>1,表明带加权因子的分系统观测精度相对较差,r越大,相对精度越差;rc越大,相对精度变差得越快。此时可根据r、rc的大小,整定α、β的取值,从倍数和指数关系上自适应调节λ的数值大小,从而及时控制误差较大局部估计量对全局状态估计量的不良影响。
假设传感器m分系统设置有加权因子,则本多传感器系统数据融合精度的提高方法第n个采样周期具体实施步骤如下:
步骤1:传感器1-L独立采集量测点迹并进行局部卡尔曼滤波,得出传感器第n个采样周期的L组局部状态估计和局部估计误差自相关矩阵P(1)(n),P(2)(n),…,P(L)(n),输入数据融合预处理模块。Zn表示传感器截至第n个采样周期观测量集合{z(1),z(2),…,z(n)},表示第n个采样周卡尔曼滤波算法利用观测量集合Zn对系统状态变量x(n)进行最优估计得出的状态估计,1-L表示L个传感器分系统的序号。步骤1直接引用卡尔曼滤波经典算法,这里不再对计算步骤展开赘述。
步骤2:数据融合预处理模块在线解算传感器m第n个采样周期误差比系数r和误差比系数变化率rc的实时值r(m)(n)、rc(m)(n),输入参数模糊整定器模块。根据卡尔曼滤波估计误差自相关矩阵的定义,第n个采样周期各局部估计误差自相关矩阵P(i)(n)的第1行第1列分量[P(i)(n)]1,1体现了该时刻估计量的位置误差特性且该分量恒为正,其值越大则分系统位置误差越大。基于此原理,本发明设计构建了用于量化描述各局部估计误差大小关系的误差比系数r和误差比系数变化率rc的实时解算公式。则数据融合预处理模块的工作步骤如下:
步骤2.1:数据融合预处理模块提取各局部估计误差自相关矩阵P(i)(n)的第1行第1列分量[P(i)(n)]1,1,在线实时计算传感器m分系统误差比系数r(m)(n)。
式中,n表示第n个传感器采样周期,i表示1-L号传感器分系统中的第i个传感器,m表示1-L号传感器分系统中带加权因子的第m号传感器。
步骤2.2:数据融合预处理模块在线实时计算传感器m分系统误差比系数变化率rc(m)(n)。
rc(m)(n)=r(m)(n)-r(m)(n-1)m∈[1,L]
式中,n表示第n个传感器采样周期,m表示1-L号传感器分系统中带加权因子的第m号传感器。
步骤2.3:数据融合预处理模块做r(m)(n)∈[rl,rh],rc(m)(n)∈[rcl,rch]限幅处理,其中限幅范围由设计者根据系统特性事先设定。
当r(m)(n)>rh时,r(m)(n)=rh;当r(m)(n)<rl时,r(m)(n)=rl;当rc(m)(n)>rch时,rc(m)(n)=rch;当rc(m)(n)<rcl时,rc(m)(n)=rcl。
步骤3:参数模糊整定器在线整定参数α、β,解算其实时整定值α(m)(n)、β(m)(n),输入加权因子解算模块。
参阅图2、图3。本发明针对模糊整定器的每个输入、输出空间,分别定义对应r、rc、 α、β定义误差比变量R、误差比变化率变量RC、倍数变量A和指数变量B的四个语言变量。
误差比例系数r和误差比系数变化率rc经过模糊化接口转换为误差比变量R、误差比变化率变量RC,输入模糊整定器,通过模糊规则库模糊推理,输出倍数变量A、指数变量B,再经过清晰化接口出参数α、β的具体值。考虑带有加权因子的传感器分系统对目标状态估计的实时要求,应选用分辨率较高、灵敏度较好的形状较尖的隶属函数,隶属函数相邻两曲线交点对应的隶属度值较小时,控制灵敏度较高,但鲁棒性不好;反之则鲁棒性较好,灵敏度欠佳。且隶属函数的分布必须覆盖语言变量的整个论域,若出现“空档”将导致参数整定失败。
综上所述,发明人对参数模糊整定器中四个语言变量R、RC、A、B,设计图4所示覆盖整个语言变量论域的分布隶属函数。在隶属函数分布设计中,将R划分为四档,RC划分为七档,A划分为四档,B划分为七档。隶属函数分布设计如下:将R在论域上划分为{Z,S,M,B}四档,设定其语言值隶属函数[0,1]段为Z形函数,[2,3]段为S形函数,中间为三角型函数,取各语言值对应三角隶属函数的中心值分别为{1,2},宽度均为1;将RC在论域上划分为{NB,NM,NS,Z,PS,PM,PB}七档,设定其语言值隶属函数[-3,-2]段为Z形函数,[2,3]段为S形函数,中间为三角型函数,取各语言值对应三角隶属函数的中心值分别为{-2,-1,0,1,2},宽度均为1;将A在论域上划分为{S,MS,MB,B}四档,设定其语言值隶属函数[1,3]段为Z形函数,[5,7]段为S形函数,中间为三角型函数,取各语言值对应三角隶属函数的中心值分别为{3,5},宽度均为2;将B在论域上划分为{S,MS,MB,B}四档,设定其语言值隶属函数[1,2]段为Z形函数,[3,4]段为S形函数,中间为三角型函数,取各语言值对应三角隶属函数的中心值分别为{2,3},宽度均为1。
基于上述分布隶属函数设定,本发明对模糊整定器的两个输出量参数α对应的倍数变量A和参数β对应的指数变量B各自的模糊规则做出了28条规则设定。A的模糊推理规则具体如下:
ARE1:IF R is Z AND RC is NB THEN A is S;
ARE2:IF R is Z AND RC is NM THEN A is S;
ARE3:IF R is Z AND RC is NS THEN A is S;
ARE4:IF R is Z AND RC is Z THEN A is S;
ARE5:IF R is Z AND RC is PS THEN A is S;
ARE6:IF R is Z AND RC is PM THEN A is S;
ARE7:IF Ris Z AND RC is PB THEN A is S;
ARE8:IF Ris S AND RC is NB THEN A is S;
ARE9:IF Ris S AND RC is NM THEN A is S;
ARE10:IF R is S AND RC is NS THEN A is S;
ARE11:IF R is S AND RC is Z THEN A is S;
ARE12:IF R is S AND RC is PS THEN A is S;
ARE13:IF R is S AND RC is PM THEN A is MS;
ARE14:IF R is S AND RC is PB THEN A is MS;
…
ARE28:IF R is B AND RC is PB THEN A is B;
其中,R为误差比变量,Z、S、M、B为其语言值;RC为误差比变化率变量,NB、NM、NS、Z、PS、PM、PB为其语言值;A为倍数变量,S、MS、MB、B为其语言值。
这些规则用矩阵表形式可描述如下:
表1A调整规则表
同理,指数变量B的模糊推理规则用矩阵表形式可描述如下:
表2B调整规则表
以参数α对应的倍数变量A的推算过程为例,A调整规则库28条规则中第i条规则的推理结果可表述为:
AREi:IF R is Ri AND RC is RCi THEN A is Ai。
其中,Ri、RCi、Ai是第i条规则中与R、RC、A对应的语言值,这个推理结果蕴含的模糊关系为:
AREi=(Ri×RCi)×Ai
整定规则库中的28条规则之间可看作是“或”,也就是“求并”的关系,则整个规则库蕴涵的模糊关系矩阵RA为:
将R,RC与RA“合成运算”以实现模糊推理,得出模糊输出量A*:
A*=(R×RC)οRA
本发明选用重心法则为去模糊化的推算方法,即对模糊输出量中各元素Ai及其对应的隶属度求加权平均值,并四舍五入取整,得出倍数变量A的输出量。
式中,<>代表四舍五入取整运算。指数变量B的模糊推理方法同倍数变量A。
为利于工程实现,模糊推理过程可离线运算,针对各种可能出现的R、RC取值给出了模糊查询表,实现α、β对应参数模糊整定器输出量倍数变量A、指数变量B的在线查询。本发明设定R的论域为{0,1,2,3},RC的论域为{-3,-2,-1,0,1,2,3},A的论域为{1,3,5,7},B的论域为{1,2,3,4},则按照上述规则库及模糊推理算法计算得出的模糊查询表如下所示:
表3A模糊查询表
表4B模糊查询表
该表可被存储在计算机内存中直接在线查询,则参数模糊整定器的工作步骤如下:
步骤3.1:参数模糊整定器将数据融合预处理模块解算求得的传感器m第n个采样周期误差比系数r(m)(n)和误差比系数变化率rc(m)(n),量化为模糊整定器的输入语言变量。取适当的量化因子kr、krc,则传感器m第n个采样周期误差比变量R的实时值R(m)(n)、误差比变 化率变量RC的实时值RC(m)(n)为:
R(m)(n)=<kr·r(m)(n)>
RC(m)(n)=<krc·rc(m)(n)>
式中,n表示第n个传感器采样周期,m表示1-L号传感器分系统中带加权因子的第m号传感器。
步骤3.2:参数模糊整定器根据误差比变量R和误差比变化率变量RC的实时值R(m)(n)、RC(m)(n),在线查模糊查询表表3、表4,得出传感器m第n个采样周期倍数变量A和指数变量B的实时值A(m)(n)、B(m)(n)。
以R=2,RC=1的情况为例,A的取值参考表3可知:
ARE19:IF R is 2 AND RC is 1 THEN A is 5。
B的取值参考表4可知:
BRE19:IF R is 2 ANDRC is 1 THEN Bis 2。
于是得出A=5,B=2。
步骤3.3:参数模糊整定器通过比例因子kα、kβ将语言变量A(m)(n)、B(m)(n)清晰化为传感器m第n个采样周期参数α、β的实时整定值α(m)(n)、β(m)(n)。
α(m)(n)=kα·A(m)(n)
β(m)(n)=kβ·B(m)(n)
式中,n表示第n个传感器采样周期,m表示1-L号传感器分系统中带加权因子的第m号传感器。
步骤4:加权因子解算模块调用数据融合预处理模块解算的误差比系数r(m)(n)和参数模糊整定器整定结果α(m)(n)、β(m)(n),在线实时解算传感器m第n个采样周期加权因子λ的实时值λ(m)(n),实现λ取值的自适应调节。
式中,n表示第n个传感器采样周期,m表示1-L号传感器分系统中带加权因子的第m号传感器。
步骤5:数据融合解算模块调用加权因子解算模块解算结果λ(m)(n)在线数据融合,得出多传感器系统第n个采样周期基于组传感器测量集合的全局状态估计
i=1,2…L,i≠m,m∈[1,L]
式中,n表示第n个传感器采样周期,i表示1-L号传感器分系统中的第i个传感器,m 表示1-L号传感器分系统中带加权因子的第m号传感器。
单个采样周期数据融合解算全局状态估计量完成,等待下个采样周期重复步骤1-5。
参阅图5、图6。仿真试验中模拟产生传感器1和传感器2两组观测噪声特性不同的观测量,连续400次采样。其中传感器2分系统观测噪声较不稳定时有陡增情况,其局部估计分量上引入自适应加权因子。在相同边界条件下,经典数据融合方法和本发明改进的数据融合方法分别做200次蒙特卡洛实验。全局位置估计仿真结果统计数据可知,当带加权因子的传感器分系统误差持续较高或遇到干扰陡增时,本发明数据融合方法通过实时灵敏调节加权因子的取值,自适应缩放该分系统局部估计误差自相关矩阵,有效控制了局部不良信息对全局估计的负面影响,实现了全局状态估计精度的优化。
- 还没有人留言评论。精彩留言会获得点赞!