一种版式文档段落识别方法与流程
本发明属于版式识别技术领域,具体地说,本发明涉及一种将版式文档转化为流式文档的技术。
背景技术:
传统的出版书籍、各种报刊、杂志等阅读媒介都主要由版式文档组成。版式文档的特点是版面固定、不跑版,即所见即所得。在使用过程中,版式文档呈现效果不因软硬件环境、操作者的变化而变化,在版式、版面、字体、字号等方面与纸质文档保持完全一致。
另一方面,当前移动互联网处于高速发展时期,手机已经极大的普及了。人们正越来越多的从纸质阅读转移到手机电子阅读。而传统的阅读媒介都主要由版式文档组成,已经不能满足不同尺寸的移动设备对流式阅读体验的需求。所以版式文档转化为流式文档,能够将传统的版式阅读体验转移到最新的移动阅读体验上来。
要将版式文档转化为流式文档,首先需要将版式文档的段落识别出来,即识别出那些字句构成自然段、自然段之间如何排序等。然而,版式文档的版面设计各不相同,这给计算机的自动识别造成了诸多困难。例如:版式文档的版面中时常插入大小不一的图片,这对文字的连贯性会造成干扰,且版面中的文字有时横排有时竖排,并且,由于版面设计的原因,有的上、下文之间时常跳过一大块区域。上述这些版式文档的特性都给计算机自动识别版面中的段落造成了困难。
因此,当前迫切需求一种识别版式文档段落的解决方案。
技术实现要素:
本发明的目的是提供一种识别版式文档段落的解决方案。
本发明提供了一种版式文档段落识别方法,包括下列步骤:
1)对版式文档的页面进行文字行识别;
2)用扫描线扫描所述页面,根据扫描线是否与文字行相交识别出页面中的各个空白分隔区,并用所述空白分隔区将所述页面切割成多个文字块;
3)分别将各个文字块切分成段。
其中,所述步骤2)中,所述用扫描线扫描所述页面包括用竖直扫描线横向扫描所述页面以及用水平扫描线纵向扫描所述页面,所述空白分隔区包括竖直空白分隔区和水平空白分隔区。
其中,所述步骤2)中,用所述空白分隔区将所述页面切割成多个文字块的方法如下:利用各个所述空白分隔区多次切割所述页面,其中优先使用分隔距离宽的所述空白分隔区进行切割。
其中,所述步骤2)包括下列子步骤:
21)用竖直扫描线对当前页面进行横向扫描,获得横向扫描过程中连续出现有效扫描线的区域,并将这些区域认定为竖直空白分隔区,所述有效扫描线是与任何文字行都不相交的扫描线;找出具有最大横向长度MaxHLine的最大竖直空白分隔区;
22)用水平扫描线对所述当前页面进行纵向扫描,获得纵向扫描过程中连续出现有效扫描线的区域,并将这些区域认定为水平空白分隔区;找出具有最大纵向长度MaxVLine的最大竖直空白分隔区;
23)比较竖直空白分隔区的最大横向长度MaxHLine和水平空白分隔区的最大纵向长度MaxVLine的大小:
如果MaxHLine>MaxVLine且MaxHLine>0,则用对应于最大横向长度MaxHLine的竖直空白分隔区对当前页面做纵向切割,得到两个子页面;
如果MaxHLine<MaxVLine且MaxVLine>0,则用对应于最大纵向长度MaxVLine的水平空白分隔区对当前页面做横向切割,得到两个子页面;
如果MaxHLine=0且MaxVLine=0,则表明当前页面不能再做切割,此时对当前页面的处理结束;
步骤24)对步骤23)切割得到的子页面进行排序,然后依次将各子页面作为新的当前页面,返回步骤21)进行处理;这样不断重复递归,直到所有的子页面都不能再切割为止,此时就直接得到了排序后的文字块。
其中,所述步骤24)中,在每次切割时,根据切割得到的两个子页面的左右位置或上下位置对这两个子页面进行排序。
其中,所述步骤24)中,根据每次切割时得到的两个子页面的排序,得到整个所述页面的所有文字块的排序。
其中,所述步骤1)包括:提取版式文档页面中的所有文字及该文字的位置信息,根据各个文字的位置信息,基于行识别算法将各个文字合并,得到相应的文字行。
其中,所述步骤1)中,行识别算法包括下列子步骤:
步骤11)对于当前待识别页面的对象集合,根据其中各个文字的位置,计算文字之间的距离,找出距离最接近的两个文字;其中,对象集合中的对象包括文字和文字行;
步骤12)将所找出的两个文字合并成为文字行LA,将已合并的文字从当前待识别页面的对象集合中删去,并在该对象集合中加入文字行LA,然后根据两个文字的位置关系,得到该文字行LA的方向信息,并进一步生成该文字行LA的基础对象数据,所述基础对象数据包括文字行的字号和轮廓;
步骤13)在当前待识别页面的对象集合中遍历所有文字,找到与文字行LA位置最接近的一个文字WB;
步骤14)根据字号、文字方向和轮廓,判别文字行LA与文字WB合并是否合理,如果不合理,返回步骤11);否则,将文字行LA与文字WB合并成新行LC,然后继续执行步骤15);
步骤15)用新行LC作为新的当前文字行LA,返回步骤13)开始下一轮的处理;
上述步骤11)~15)不断循环,直至待识别页面的对象集合中的所有文字均合并成文字行。
其中,所述步骤14)包括下列子步骤:
步骤141)比较文字行LA中的文字和查找到的文字WB的字号,如果字号差别超过预设的阈值,返回步骤11);否则,继续执行步骤142);
步骤142)将文字行LA和查找到的文字WB合并成为新行LC,比较新行LC和原文字行LA是否具有相同的方向,如果新行LC中具有方向不同的文字,或者新行LC的方向和原文字行LA的方向不相同,释放新行LC,同时返回步骤11);否则,继续执行步骤143);
步骤143)基于轮廓判断新行LC是否和别的对象发生交叠,如果发生交叠,则新行LC的合并无效,释放新行LC,同时返回步骤11);如果不发生交叠,则进入步骤15)。
其中,所述步骤3)包括:对于每个文字块,根据行间距、行的起始或结束处是否存在文字缩进来识别各个段落;将各个有序文字块内部的段落按照顺序合并在一起,生成一个有序的段落序列;将每组相邻的有序文字块之间的相邻的两个段落进行检测,在这两个段落具有相同的字体且这两个段落均不是完整的段落时,将这两个相邻的段落合并。
与现有技术相比,本发明具有下列技术效果:
1、本发明能够准确地识别出版式文档中的自然段。
2、本发明能够给出自然段之间的排序。
附图说明
图1示出了本发明一个实施例的段落识别方法的总体流程;
图2示出了本发明一个实施例中识别文本行的流程;
图3示出了本发明一个实施例中一页pdf文档示例的文本行识别结果示意图;
图4示出了本发明一个实施例的块识别过程中竖直扫描线横向扫描的示意图;
图5示出了本发明一个实施例的块识别过程中水平扫描线纵向扫描的示意图;
图6示出了本发明一个实施例中块识别结果的示意图;
图7示出了本发明一个实施例中基于所识别的块的段识别流程图。
具体实施方式
根据本发明的一个实施例,提供了一种用于将版式文档转化为流式排版的段落识别方法,图1示出了该段落识别方法的总体流程,参考图1,该段落识别方法包括下列步骤:
步骤1:读取文档元数据,进行行识别。文档元数据包括组成版式文档的文字和图片等基本元素。版式文档处理的基础就是对基础的元数据的处理,从版式文档识别出单个文字和单个图片的方法是已有技术,此处不再赘述。
版式文档和流式文档一个主要的区别是没有所谓的顺序信息,也就是所有的文字信息只包括纯粹的位置信息(这个位置信息可以是文字所对应的坐标位置),文字在版式文档中的顺序只能作为参考,而不能作为严密的顺序信息使用。所以,现有的版式文档识别方案通常只能获取无顺序的零散文字,要进行段落识别,首选需要将文档元数据(尤其是文字)进行排序。本实施例中,基于根据每个文字的位置,通过行识别的方式将零散的文字组织起来并在行范围内实现了文字的排序。
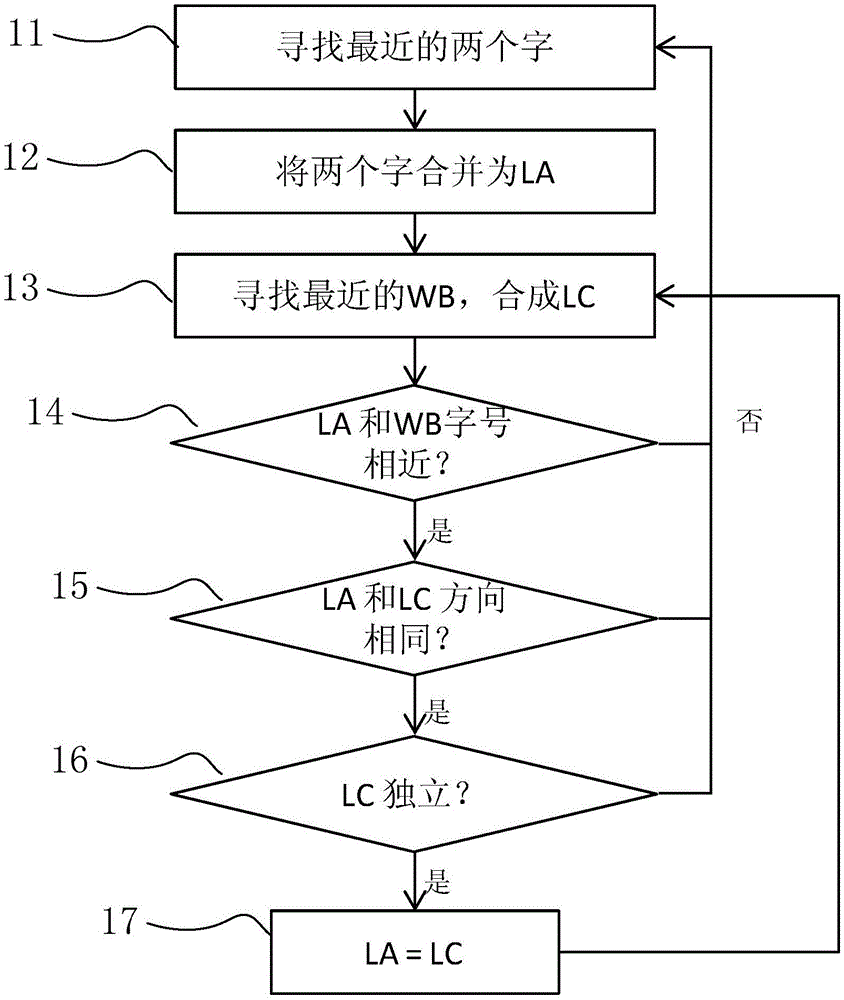
图2示出了本发明一个实施例中的行识别流程,包括下列步骤:
步骤11:对于当前待识别页面的对象集合,根据其中各个文字的位置,计算文字之间的距离,找出距离最接近的两个文字。本文中,对象包括文字和文字行。
步骤12:将所找出的两个文字合并成为文字行LA,然后根据两个文字的位置关系,得到该文字行LA的方向信息,例如是横向文字行还是纵向文字行。同时还可以进一步生成该文字行LA的字号(表示文字大小)、轮廓等基础对象数据。本实施例中,文字行的轮廓是涵盖该文字行所有文字的最小矩形框。
本步骤中,还将已合并的文字从当前待识别页面的对象集合中删去,并在该对象集合中加入文字行LA。在一个实施例中,当前待识别页面的对象集合可以用对象间距离矩阵的方式存储和表征,其中,对象间距离矩阵的每一行分别代表一个对象,每一列也分别代表一个对象,对象间距离矩阵的元素为对象与对象之间的距离,即该元素为相应行所代表对象与相应列所代表对象之间的距离。
步骤13:在当前待识别页面的对象集合中遍历所有文字,找到与文字行LA最接近的一个文字WB,将该文字WB作为后续处理的输入对象。
步骤14:比较文字行LA中的文字与和查找到的文字WB的字号,如果字号差别超过预设的阈值(例如25%),则返回步骤11;否则继续执行步骤15。
本步骤中,如果字号差别超过预设的阈值,则说明文字WB不适合并入文字行LA中,返回步骤11,以便在当前的待识别页面的对象集合中,重新寻找最接近的两个文字合并成新的文字行。需注意,此时的待识别页面的对象集合中已删去了已经被合并的文字,新的文字行将由剩余的文字合并而成。
步骤15:将文字行LA和查找到的文字WB合并成为新行LC,比较新行LC和原文字行LA是否具有相同的方向,如果新行LC中具有方向不同的文字,或者新行LC的方向和原文字行LA的方向不相同,释放新行LC,同时返回步骤11;否则,继续执行步骤16。本步骤中,如果新行LC中具有方向不同的文字,或者新行LC的方向和原文字行LA的方向不相同,则说明新行LC和原文字行LA具有不同的属性,所以新行LC的合并是无效的,因此释放新行LC,同时返回步骤11,以便在当前的待识别页面的对象集合中,重新寻找最接近的两个文字合并成新的文字行;
步骤16:判断新行LC是否和别的对象发生交叠(交叠也可以称为相交,它是指新行LC的轮廓与其他对象的轮廓存在部分面积或全部面积的重叠),如果发生交叠,则认为新行LC不是完全独立的,新行LC的合并无效,释放新行LC,同时返回步骤11,以便在当前的待识别页面的对象集合中,重新寻找最接近的两个文字合并成新的文字行;如果不发生交叠,则认为新行LC独立,进入步骤17。
步骤17:新行LC此时已通过各种检验,可认定新行LC的合并是合理的合并,令LA=LC(即将新行LC作为新的当前文字行LA),返回步骤13,开始下一轮的处理。本步骤中,当前待识别页面的对象集合中的文字行LA也一并被新行LC的内容替换。但需注意的是,在其他实施例中,也可以不在本步骤中对待识别页面的对象集合中的LA进行更新,而是等到当前文字行完全识别完毕,即在步骤14、15或16的判别后需要返回步骤11的情形下,用新行LC的内容替换待识别页面的对象集合中的文字行LA的原内容。
可以看出,每一轮处理时,如果返回11,就可以完成一个完整行的生成,当整个集合中所有的文字都合并成文字行以后,循环结束,得到的结果就是行识别的最后结果。当完成行识别以后,效果如图3所示,页面会变成由行和图片组成。
需说明的是,上述行识别的方式并不是唯一的,在其他实施例中,也可以使用其他的行识别算法,只要能够将从版式文档页面中提取的零散文字及其位置信息识别成文字行即可。
步骤2:对当前页面进行块识别。当完成行识别以后,进一步将页面的结构划分为多个文字块,并识别页面中各个文字块的顺序。
在完成行识别后,对当前页面进行块识别的方法具体包括下列子步骤:
步骤21:用竖直扫描线对页面进行横向扫描,在扫描过程中,如果竖直扫描线不与页面中的任何文字行相交,则判定此时竖直扫描线所处的行是竖直有效行。图4示出了竖直扫描线横向扫描的示意图,其中箭头表示扫描方向,虚线表示竖直扫描线。
步骤22:获得横向扫描过程中连续出现竖直有效行的区域,这些区域是竖直空白区,在页面中这种竖直空白区通常会被作为文字块之间的分隔区,所以也可称为竖直空白分隔区。在图4中,区域a示出了一个竖直空白分隔区。本步骤中,统计本次扫描过程中每个竖直分隔区的横向长度,求出其中最大横向长度MaxHLine,它表示的是左右相邻的块与块之间的分隔距离。
步骤23:用水平扫描线对页面进行纵向扫描,在扫描过程中,如果水平扫描线不与页面中的任何文字行相交,则判定此时水平扫描线所处的行是水平有效行。图5示出了水平扫描线纵向扫描的示意图,其中箭头表示扫描方向,虚线表示水平扫描线。
步骤24:获得各个纵向扫描过程中连续出现水平有效行的区域,这些区域是水平空白区,在页面中这种水平空白区通常会被作为文字块之间的分隔区,所以也可称为水平空白分隔区。在图5中,区域b示出了一个水平空白分隔区。本步骤中,统计本次扫描过程中每个水平分隔区的纵向长度,求出其中最大纵向长度MaxVLine,它表示的是上下相邻的块与块之间的分隔距离。
在本实施例中,扫描线是长度能够贯穿整个页面的线条。扫描过程中,扫描线可以逐个像素地移动。但这个移动方式不是唯一的,例如,在其他实施例中,也可以设定其它的移动步长,该移动步长使得不同空白分隔区的不同分隔距离能够被区分出来。
步骤25:比较竖直空白区的最大横向长度MaxHLine和水平空白区的最大纵向长度MaxVLine的大小:
如果MaxHLine>MaxVLine且MaxHLine>0,则用对应于最大横向长度MaxHLine的竖直有效行(或者竖直空白区)对当前页面做纵向切割,得到两个子页面;
如果MaxHLine<MaxVLine且MaxVLine>0,则用对应于最大纵向长度MaxVLine的水平有效行(或者水平空白区)对当前页面做横向切割,得到两个子页面;
如果MaxHLine=0且MaxVLine=0,则表明当前页面不能再做切割,此时对当前页面的处理结束。
步骤26:对步骤25切割得到的子页面进行排序,然后依次将各子页面作为新的当前页面,返回步骤21进行处理。这样不断重复递归,直到所有的子页面都不能再切割为止。此时,整个页面的文字块识别完毕,图6示出了本发明一个实施例中块识别结果的示意图。
另外,本步骤中,各个子页面的排序规则为上面的子页面的排序优先于下面的子页面,左面的子页面的排序优先于右面的子页面。
执行上述步骤26后,最后所得的每个子页面代表一个文字块或者图片等其它基本元素。根据基本元素信息,可以很方便地提取出其中的文字块。并且,由于各个子页面已经排序,因此可直接得到排序后的文字块。
步骤3:基于步骤2所得到的排序文字块进行段识别。段主要是将文字块识别成一个又一个的段落,如图6所示。每一个文字块都是段识别的输入项,输出项则为块内切割出的一个又一个段落。
图7示出了一个实施例中的段识别的方法的流程,包括下列子步骤:
步骤31:首先新建一个段落PB,段落PB是行的容器,即段落PB由行组成,初始时,段落PB为空。
步骤32:从当前文字块中取出一个行LA。
步骤33:判断PB是否为空,如果是,执行步骤34,如果否,执行步骤35。
步骤34:直接将LA加入到PB,然后跳转到步骤37。
步骤35:根据LA距离PB的最短距离是否大于PB中的行间距,确定是否将行LA加入段落PB。PB中的行之间会有一个间距,即行间距,如果LA距离PB的最短距离大于PB的行间距,说明LA不适合加入PB,此时认为当前段落PB的识别已结束,返回步骤31,以便识别下一个段落;否则,继续执行步骤36。
步骤36:段落PB中所有的行所组成的段落会有一个位置关系,如果新加入的行的左侧(或者上侧)相对于段落最后一行的左侧(或者上侧)缩进至少2em(1em=一个文字宽度),则说明LA相对PB是新段落的开始,LA不加入PB,且认为当前段落PB的识别已结束,返回转步骤31,以便识别下一个段落;否则,继续执行步骤37。
步骤37:将LA加入PB,返回步骤32,以便重新取一行进行处理。
当所有的行都处理完毕以后,生成的段落就是最后所需要的段落,这些段落的顺序就是它们在文字块中的顺序。
步骤4:连续段落处理,通过步骤2以后,可以识别并生成一个有序的文字块序列,通过步骤3,可以将每一个文字块拆分成段落,并且段落之间也是有序的,所以连续段落处理就是处理块与块之间的段落关系,其过程如下:
步骤41:首先将有序块内部的段落按照顺序合并在一起,生成一个有序的段落序列,这样整个页面的段落都是有序的了。
步骤42:在有序的段落序列中,将相邻的有序文字块之间的相邻有序段落拿出来进行检测,如果两个段落可以合并,则进行合并。判断合并的条件为:当两个段落具有相同的字体,且两个段落均不是完整的段落时,将这两个相邻段落合并。将相邻有序文字块对应的连续段落合并以后,整个有序段落序列就是最后的结果。
在一个优选实施例中,步骤42包括下列子步骤:
步骤421:对于相邻的文字块,取前一文字块的最后一个段落A和后一文字块的第一个段落B。
步骤422:比较段落A和段落B的字体,判断两个段落字体是否相同,如果否,则段落A和段落B肯定不是连续段落,段落A和段落B不做合并处理,如果是,则继续执行步骤423。
步骤423:判断段落A是否为head段落,head段落的定义是当前段落是一个完整段落的上部分,但不是一个完整的段落。如果段落A不是head段落,则不对段落A和段落B进行合并,如果段落A是head段落,则继续执行步骤424。在具体实现上,可以判断段落A的最后一行的右侧相对于该段落其他行的右侧是否存在文字缩进,如果存在,则认为段落A不是head段落,如果不存在,则认为段落A是head段落。
步骤424:判断段落B是否为tail段落,tail段落的定义为当前段落是一个完整段落的下半部分,但不是一个完整的段落。如果段落B不是tail段落,则不对段落A和段落B进行合并,如果段落B是tail段落,则继续执行步骤425。在具体实现上,可以判断段落B的第一行的左侧相对于该段落其他行的左侧是否存在文字缩进,如果存在,则认为段落B不是tail段落,如果不存在,则认为段落B是tail段落。
步骤425:将段落A和段落B标记为连续的段落,使得在将有序文本单元导成流式文件的时候,段落A和段落B自动合并成为一个段落。
最后应说明的是,以上实施例仅用以描述本发明的技术方案而不是对本技术方法进行限制,本发明在应用上可以延伸为其它的修改、变化、应用和实施例,并且因此认为所有这样的修改、变化、应用、实施例都在本发明的精神和教导范围内。
- 还没有人留言评论。精彩留言会获得点赞!