基于事件直接先于关系的云间科学工作流挖掘方法与流程
本发明属于数据挖掘领域,具体涉及一种基于事件直接先于关系的云间科学工作流挖掘方法。
背景技术:
近些年,科学工作流管理的概念被应用到许多企业信息系统中。类似于Staffware,IBM MQSeries,COSA等的工作流管理系统提供了通用模型和制定结构化业务流的能力。通过图形化的方式对业务事件先后执行顺序的描述,刻画出更为直观、可理解的业务生命周期模型,也就是所谓的科学工作流模型,对企业事务进行更为高效、合理的管理运营。现如今,科学工作流的概念被运用到各个领域,不仅是企业的业务流程框架,更包括诸如高能物理学、生物信息学、大气科学等的学术研究,这些研究过程包含了海量的数据分析和处理步骤,科学家需要通过高层次的工具,将问题抽象化,搭建设计合理、高效的业务流程,以解决复杂、繁琐的高层次问题。而科学工作流提供了这样的环境,通过数据管理、分析、仿真和可视化的相互结合,以协助科学发现的过程。
日志,作为计算机网络安全的重要组成部分,记录着计算机每次运行事件的日期、时间、使用者、动作等相关操作。事件日志作为信息宝库,蕴藏着无穷的价值。通过对事件日志的分析研究,而获得整个项目或平台的结构化业务流,也就是科学工作流,将大大的方便科学家对现有工作平台,业务事件工作顺序的把控。通过计算机记录的事件日志而挖掘生成的科学工作流更具有真实性,更贴近、符合实际业务事件执行的先后次序。其价值之高在于一方面方便业务架构师在原有业务模型的基础上,对业务流程进行重构、优化,另一方面也有助于通过可视化图形对实际业务流中存的问题、缺陷进行进一步的优化和完善,以提高整个业务流的运行效率与质量。
随着科技的发展,各个学术领域中所研究的问题规模日益增大。大型科学工作流通常需要在复杂的分布式计算机系统上执行,例如超级计算机、分布式集群系统以及网络系统等。然而,构造这样的系统往往需要付出异常昂贵的代价,申请访问这些系统也需要复杂耗时的过程。
技术实现要素:
本发明的目的在于提供一种基于事件直接先于关系的云间科学工作流挖掘方法,该方法能够解决在分布式云平台环境下的科学工作流挖掘问题,具有高效性、完备性和灵活性的特点。
实现本发明目的的技术方案为:一种基于事件直接先于关系的云间科学工作流挖掘方法,通过事件日志信息,挖掘跨云平台下的科学工作流,以XES格式描述的事件日志为输入,以SVG为格式的云间科学工作流为输出结果,该方法具体包括以下步骤:
步骤1,输入以XES格式描述的事件日志,解析事件日志获得事件,生成对应的事件序列集合,根据事件序列集合获得事件直接先于关系,完成云内科学工作流的挖掘;
步骤2,各个云平台分别挖掘完成各自云平台内的科学工作流后,两两云平台之间同时进行消息传递,完成初步跨云间的科学工作流的挖掘;
步骤3,通过步骤2的跨云间科学工作流的挖掘,对整个云平台联盟下的总体科学工作流进行归约、合并和简化处理,得到跨云间的科学工作流。
本发明与现有技术相比,其显著优点:(1)在各个云计算平台下进行子科学工作流的挖掘时,在同等大小的本地日志规模下,本发明的挖掘效果较传统科学工作流挖掘方法具有明显优势,其挖出的工作流图更具有完备性、准确性、可靠性,更接近实际的科学工作流过程;(2)本发明在科学工作流的挖掘时间上也具有一定优势,采用云计算,通过多个云平台同时挖掘的技术,较以往单平台下的挖掘,大大节约了时间成本,减轻了单平台数据挖掘的负担,减少了单平台下挖掘可能产生的内存溢出、系统崩溃等一系列问题。
附图说明
图1是本发明基于事件直接先于关系的云间科学工作流挖掘方法流程图。
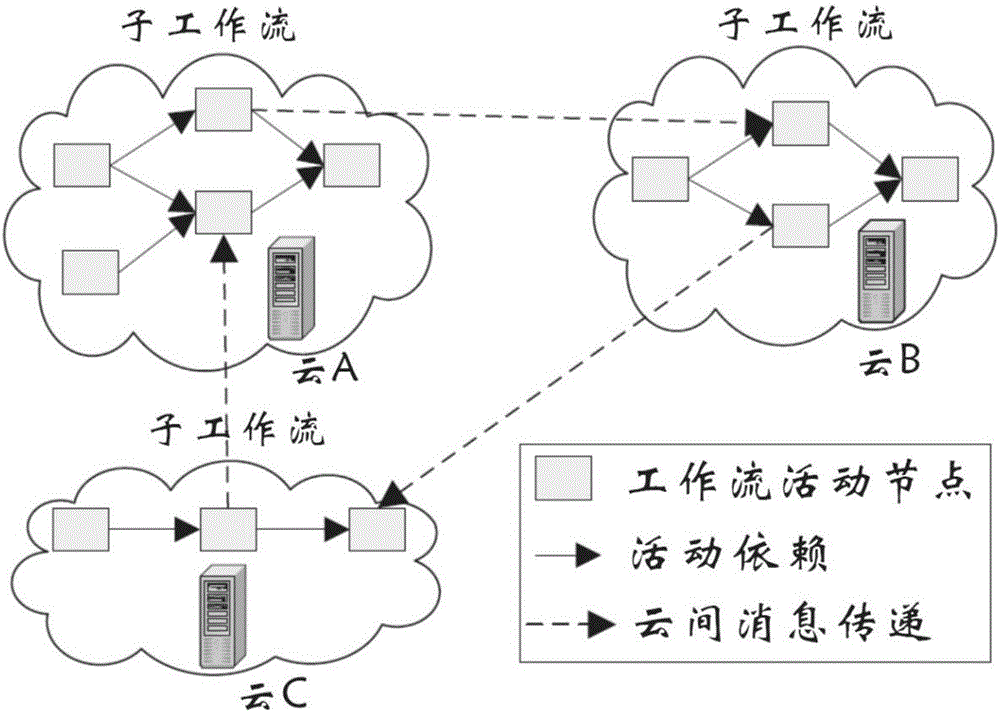
图2是跨云间科学工作流的挖掘过程图。
图3是日志挖掘完成后生成的单一平台下的完整的子科学工作流图。
图4(a)是各云平台均完成各云平台下的子科学工作流的挖掘的图。
图4(b)是各云平台相互发送消息的科学工作流图。
图4(c)是基于事件直接先于关系的挖掘完成的云间科学工作流图。
图5(a)是未进行传递归约操作的科学工作流图。
图5(b)是进行传递归约操作后的科学工作流图。
具体实施方式
结合图1,本发明的一种基于事件直接先于关系的云间科学工作流挖掘方法,通过事件日志信息,挖掘跨云平台下的科学工作流,以XES格式描述的事件日志为输入,以SVG为格式的云间科学工作流为输出结果,该方法具体包括以下步骤:
步骤1,输入以XES格式描述的事件日志,解析事件日志获得事件,生成对应的事件序列集合,根据事件序列集合获得事件直接先于关系,完成云内科学工作流的挖掘;具体为:
步骤1-1,完成事件日志的解析,将格式为XES的日志文件转化为对应的事件序列集合,所述事件序列集合是指日志中事件可能发生的先后顺序的排序组合;
步骤1-2,遍历事件序列集合,根据事件序列集合获得事件直接先于关系;具体包括:
步骤1-2-1,任意一条事件序列{a1a2a3a4……aN-1aN}包含N个事件,a1……aN代表事件,这N个事件按照事件先后发生顺序,获得N-1组的事件直接先于关系:a1→L a2、a2→L a3、a3→L a4……aN-1→L aN;a1→L a2表示事件a1发生顺序直接先于事件a2;
步骤1-2-2,遍历事件序列集合,获得所有可能的事件直接先于关系,删除所有重复的事件直接先于关系;
步骤1-2-3,在步骤1-2-2中所得到的所有的直接先于关系的集合中删除存在并发关系的直接先于关系,并按照最终剩余的事件直接先于关系,连结事件生成云内科学工作流。
步骤2,各个云平台分别挖掘完成各自云平台内的科学工作流后,两两云平台之间同时进行消息传递,完成初步跨云间的科学工作流的挖掘;
步骤3,通过步骤2的跨云间科学工作流的挖掘,对整个云平台联盟下的总体科学工作流进行归约、合并和简化处理,得到跨云间的科学工作流。
进一步的,步骤2中各云平台相互发送消息,各个不同云平台下的事件相互响应,完成所有云间科学工作流的消息传递,通过这些响应,将各个子云平台连结成为一个完整的云平台联盟,完成初步云间科学工作流的挖掘。
进一步的,步骤3中对整个云平台联盟下的总体科学工作流进行归约、合并和简化处理的具体过程为:
对初步跨云间科学工作流进行合并,当两个事件之间存在多条相同的路径时,删除重复的路径,仅保留一条路径;
对合并后的初步跨云间科学工作流进行传递归约,即在保证一副图中可达关系不变情况下删除冗余的路径,得到跨云间的科学工作流。
下面结合具体实施例对本发明作进一步说明。
实施例
本发明基于事件直接先于关系的云间科学工作流挖掘方法,是一个基于云计算平台下的,通过事件日志进行跨云间的科学工作流的挖掘的方法,具体挖掘过程如图2所示。
首先,根据各云平台下本地事件日志文件进行云内挖掘,获得本地子科学工作流,接着,各云平台下的子科学工作流两两之间进行消息传递,连结各个云平台下的子科学工作流,最后云平台联盟进一步整合、优化生成总的科学工作流,这个过程称之为跨云间科学工作流的挖掘。
本发明基于事件直接先于关系的云间科学工作流挖掘方法,是一个依赖于事件日志中事件发生的先后次序的、跨平台的科学工作流的挖掘方法。首先,各云平台独自完成各平台下的子科学工作流的挖掘,这个过程也称之为云内挖掘。云内挖掘具体包括解析本地日志文件、根据日志中所有事件发生的先后次序所组成的序列分析获取事件直接先于关系,根据事件直接先于关系构建完整的子科学工作流图,这个序列在下文中称之为Trace,Trace条数不唯一;接着,各平台完成本地科学工作流挖掘后,也就是完成云内挖掘后,进行跨云间的挖掘,各个云平台之间相互发送消息日志,根据消息日志,连结各个云平台的子科学工作流图,进一步挖掘出跨云间各个事件的响应先后次序;最后,对于整个云平台联盟下的总体科学工作流进行整理、合并、简化,挖掘完成总体的科学工作流。
该方法包括:
步骤1,云内挖掘:完成本地日志的解析、根据事件日志中事件发生的先后次序序列获得事件直接先于关系、挖掘获取完整的本地子科学工作流图,具体步骤如下:
步骤1.1,完成本地日志的解析
输入以.XES为输入的本地日志文件,该XES文件存储了事件日志的信息,包括每个事件发生的时间、状态等等。读取事件日志,按照日志中Trace条目,依次读取各个事件,按序读取的事件组成一条Trace,而一个事件日志中,包含着多条Trace,每一条Trace代表着多个事件可能发生的先后顺序。任意一条Trace记录的事件排序为{a1a2a3a4……aN-1aN},其中a1……aN代表N个不同的事件,根据该条Trace的事件排序,获得N-1个事件直接先于关系:a1→L a2、a2→L a3、a3→L a4……aN-1→L aN,代表在该条Trace中,事件a1直接发生在事件a2之前、事件a2直接发生于事件a3之前,以此类推,aN-1直接发生在事件aN之前。
步骤1.2,遍历Trace集合,每一条Trace都获得N-1组事件直接先于关系,删除这些事件先于关系中重复的组合,留下单一、不重复的事件先于关系组合。
步骤1.3,挖掘出本地、完备、全面的子科学工作流。根据步骤1.2中剩余的事件先于关系组合中,可能存在ap→L aq和aq→L ap这样的事件直接先于关系组合,ap≠aq,这代表这事件ap可能发生在事件aq之前,也可能发生在事件aq之后,这也意味着事件ap和事件aq存在并发关系;删除步骤1.2中存在的具有并发关系的事件直接先于关系组合,并根据剩余的事件直接先于关系组合,生成云内的科学工作流。
结合实例,具体的操作步骤为:假设读取某一事件日志,该日志包含四条Trace:GABCDEF、AGBCDEF、ABGCDEF、ABCGDEF。根据日志中的每一条Trace获得各事件的直接先于关系:如根据第一条Trace:GABCDEF,可以获得6组直接先于关系有G到A(简化为G→L A)、A→LB、B→L C、C→L D、D→L E、E→L F,分析全部四条Trace,并去掉冗余的直接先于关系,得到12组的事件直接先于关系:G→L A、A→L B、B→L C、C→L D、D→L E、E→L F、A→L G、G→L B、B→L G、G→L C、C→L G、G→L D。值得注意的是,这12组的事件直接先于关系中,包含了类似G→L A和A→L G这样的直接先于关系,这两组先于关系代表了事件G可以发生在事件A之前,而事件A又可以发生在事件G之前,这种情况表明了事件A和事件G存在并发关系,所以不符合事件直接先于关系的定义,所以在这12组的事件直接先于关系中删除并发的关系A→L G和G→L A、B→L G和G→L B以及C→L G和G→L C。所以最终获得了6组事件直接先于关系:A→L B、B→L C、C→L D、D→L E、E→L F、G→L D。根据6组事件直接先于关系挖掘生成图3,即单一平台下的完整的子科学工作流。
步骤2,各平台均完成本地子科学工作流的挖掘后,各平台之间相互发送消息,根据消息日志,连结各个云平台的子科学工作流图,完成云平台联盟下总体科学工作流的初步挖掘。
如图4(a)所示,根据各个云平台下的本地日志,云A挖掘出了子科学工作流A,云B挖掘出了子科学工作流B,云C挖掘出了子科学工作流C。各个云平台之间两两存在消息日志,可以是云A发送消息日志到云B,也可以是云B发送消息日志到云A,如云A至云B的消息日志包括A→L H,云B到云A的消息日志包括I→L D、I→L E,具体表现如图4(b)所示,图中虚线表示各个云平台之间消息日志的传递。
步骤3,对于步骤2挖掘出的初步的云间科学工作流,根据本方法需要进一步对整个云平台联盟下的总体科学工作流进行整理、合并、简化。步骤2中初步建立的云间科学工作流图,是冗余的科学工作流,是存在传递闭包的科学工作流,在本方法中需要对该科学工作流进行传递归约操作,删除这些冗余的边。所谓传递归约操作就是通过最少的边,保证一幅图中可达关系不变,而删除的这些冗余的边,不影响云间科学工作流中所有事件的可达关系,最终达到简化云间科学工作流的目的,完成挖掘,获得完整、精简、优化的云间科学工作流。
各云平台两两进行消息传递后,生成的图4(b)中存在类似于I→L D、I→L E、D→LE这样结构的图,将图放大至图5(a),在科学工作流中,这种存在冗余关系的边的科学工作流,即I到E的可达关系中,存在两种可达方式,一种方法为I通过D再到E,另一种方式为I直接到E,在本方法中,这种科学工作流需要进行传递归约的操作,已达到简化工作流的目的,所以对图5(a)进过传递归约后,获得了图5(b)。而总的科学工作流需要完成该科学工作流中所有的需要进行传递归约的操作,使整个科学工作流精简而又不失其完整性和完备性。最终基于直接先于关系的云间科学工作流图得挖掘如图4(c)所示,是一个完整的、跨云间的、符合事件现实依赖关系的科学工作流图。
- 还没有人留言评论。精彩留言会获得点赞!