一种MPP型异构高速MCU系统的制作方法
本发明主要涉及到片上MPP型MCU体系结构设计领域,特指一种MPP型异构高速MCU系统。
背景技术:
随着高速图像处理技术的应用领域日益扩大,对图像的性能要求也越来越高。单纯依靠减小工艺制造尺寸来提高处理器性能变得越来越乏力,因此单核处理器系统已经难以满足未来图像处理的实时性要求。而此时,随着集成电路产业以及工艺水平的快速发展,单颗芯片可以集成的处理器数目越来越多,多核系统应运而生,多核技术的迅猛发展为高速图像的并行处理提供了一种新的研究方向和解决方法。片上多核系统芯片充分利用了多处理器核的并行执行能力,是解决大规模运算和高实时性复杂应用的一种可行方案,广泛的应用在多媒体、数字信号处理以及网络通信等领域。
研究人员已经将一些应用程序加速了超过100倍,但这只是在增强的算法得到了大量优化和调整后,从而使应用程序超过99.9%的执行时间都花费在并行执行部分上。一般来说,应用程序直接并行化可能会导致存储器(DRAM)带宽达到饱和,使得加速只能达到10倍。解决途径在于如何突破存储器带宽的限制,这需要进行某种转换以便用专门的GPU芯片上存储器显著减少访问DRAM的次数。然而,如果要想突破这些限制,不但需要对代码进行进一步的优化,以限制片上存储器的容量。更需要GPU片上存储器结构打破传统的观念,对大量的数据进行并行读写,以满足大量矩阵运算的需要。
特别是,CPU的芯片面积由缓存决定,而GPU的芯片面积则由数据通路和固定功能逻辑决定。GPU存储器接口更重视带宽而不是延时(大规模并行执行会隐藏延时)。事实上,GPU带宽已经超出CPU带宽许多倍,在最近的设计中已经超过190GB/s,但仍显不足。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种结构简洁、存储带宽高、能极大地提高传输效率的MPP型异构高速MCU。所述MPP (Massively Parallel Processing),意为大规模并行处理系统,这样的系统是由许多松耦合处理单元组成,每个单元内的CPU都有自己私有的资源,如总线、内存、DMA等,在每个单元内都有各自的操作系统和管理数据库的实例复本。所述MCU(SingleChipMicrocomputer)的各个节点都是异构的,能将专业的问题交给专门的节点进行高速处理。
为解决上述技术问题,本发明采用以下技术方案:
一种MPP型异构高速MCU系统,其特征在于:包括:node1、node2、node3、node4共4个异构的处理器节点,所述node1为I/O节点,node2为超标量计算节点,node3为超越函数节点,node4为超级计算节点;网络托扑采用四面体结构,节点位于四面体的顶点,所述节点间采用四面体结构互连,网络中任意一节点到其它节点的步长都是1;节点之间采用AXI总线互连;存储器设置为分布共享的方式访问。
作为本发明的进一步改进:所述节点1包括:指令cache存储体11、加载启动ROM12、数据存储体13、存储总线14、指令寄存器IR15、程序地址计数器PC16、MCU控制器17、JTAG控制逻辑18、时钟控制逻辑19、通用寄存器R0-R7110、32位桶式移位器功能部件111、32位地址运算功能部件ARAU112、地址寄存器AR7-AR0 113、辅助寄存器114、DMA控制器115、外部总线Pbus116、定时器Time117、AXI总线接口控制器118、RapidIO高速串口控制器119、同步栅栏120、32位ALU算数逻辑运算功能部件121;
所述指令cache存储体11,存放node1所要执行的指令;其地址来自存储总线14,单向;其数据来自/去到存储数据总线14,双向;
所述加载启动ROM12,存放node1的初始化程序;12的地址来自存储总线14,单向;其数据来自/去到存储数据总线14,双向;
所述数据存储体13,可存放node1、node2、node3或node4的数据,其地址来自存储总线14,单向;其数据来自/去到存储总线14,双向;
所述指令寄存器IR15,32位,接收来自存储总线14的指令,作为待执行指令的暂存器;
所述程序地址计数器PC16,32位,其值送往存储总线14,作为下一条指令的地址;
所述32位桶式移位器功能部件111,完成对数据的左移和右移;接收来自通用寄存器110 R7-R0 上的数据,移位结果送往通用寄存器110R0-R7;
所述32位ALU算数逻辑运算功能部件111,完成对数据的算数逻辑运算;接收来自通用寄存器110R7-R0上的数据,计算结果送往通用寄存器110R0-R7;
所述32位地址运算功能部件ARAU112,完成地址运算;两路操作数可分别来自地址寄存器AR7-AR0 113和存储总线14,结果送往地址寄存器113 AR7-AR0;
所述辅助寄存器114为12个,提供诸如寻址、堆栈管理、中断及块重复等的系统功能需求;其数据来自存储总线14,输出值送往32位ALU算数逻辑运算功能部件111;
所述存储总线控制信号和数据14,完成对存储总线的传输和控制。信号分别是:
总线类:
数据总线D31-D0 (I/O/Z) 数据总线;
地址总线A31-A0 (O/Z) 地址总线;
总线控制:
Strb# (O/Z) 访问片外的选通信号;
Rady# (I) 访问外设时外设准备好信号,MCU可以结束本次访问;
Hold# (I) 保持信号,迫使MCU置A23-A0,D31-D0,STRB#,R/W#为高阻,使外设取得总线控制权;
Rd/Wt# (O/Z) 高电平表示读,低电平表示写;
MCU控制器17,是实现控制信号的逻辑,信号分别是:
Reset# (I) 复位信号;
Int3-0# (I) 外部中断;
Iack# (O/Z) 由IACK指令产生一个负脉冲;
JTAG控制逻辑18,实现边界扫描、内部扫描的控制,信号是:
Jcon5-0 (I) JTAG控制信号;
时钟控制逻辑19,实现MCU的时钟控制,信号分别是:
EXTCLK (I) 外部时钟;
所述DMA控制器115,以直接存储器访问的方式完成存储器与外部总线Pbus116的数据交换;DMA控制器115的地址总线和数据总线14相连,与116相连,地址、数据宽度为32位;
所述定时器Time117,实现看门狗、定时控制;
所述AXI总线接口控制器118,32位,一端连接node1的外部总线Pbus 116,另一端连接node2、node3、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
所述RapidIO高速串口控制器119,一端连接node1的外部总线Pbus116,32位,另一端连接外部其它设备,4条高速全双工通道,每个通道的波特率可为1.25Gbps、2.5Gbps、3.125Gbps、6.25Gbps;
所述外部总线Pbus116,实现外部设备115、117、118、119与存储器总线14之间的数据交换;
所述同步栅栏120,实现各节点进程之间的同步。
作为本发明的进一步改进:所述节点2包括:指令cache存储体21、加载启动ROM22、存储数据总线23、指令寄存器IR24、程序地址计数器PC25、DMA控制器26、浮点乘加矩阵27、AXI总线接口控制器28、外部总线Pbus29;
所述指令cache存储体21,存放node2所要执行的指令;其地址来自存储总线23,单向;其数据来自/去到存储数据总线23,双向;
所述加载启动ROM22,存放node2的初始化程序;其地址来自存储总线23,单向;其数据来自/去到存储数据总线23,双向;
所述指令寄存器IR24,32位,接收来自存储总线23的指令,作为待执行指令的暂存器;
所述程序地址计数器PC25,32位,其值送往存储总线23,作为下一条指令的地址;
所述DMA控制器26,以直接存储器访问的方式完成存储器与外部总线Pbus29的数据交换;DMA控制器26的地址总线和数据总线23相连,与29相连,地址、数据宽度为32位;
所述AXI总线接口控制器28,32位,一端连接node2的外部总线Pbus 29,另一端连接node1、node3、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
所述外部总线Pbus29,实现外部设备26、28与存储器总线23之间的数据交换;
所述浮点乘加矩阵27,可在1拍内一次并行获得8X8的矩阵结果,每一个矩阵运算单元又可并发流水执行矩阵乘加运算,可1拍获得矩阵的1个元素结果,字长位32位。
作为本发明的进一步改进:所述节点3包括:指令cache存储体31、加载启动ROM32、数据存储体33、存储总线34、指令寄存器IR35、程序地址计数器PC36、通用寄存器38R7-R0、32位桶式移位器功能部件39、32位地址运算功能部件ARAU310、地址寄存器AR7-AR0 311、辅助寄存器312、DMA控制器313、外部总线Pbus314、定时器Time315、AXI总线接口控制器316、32位ALU算数逻辑运算功能部件317;
所述指令cache存储体31,存放node3所要执行的指令;其地址来自存储总线34,单向;其数据来自/去到存储数据总线34,双向;
所述加载启动ROM32,存放node3的初始化程序;其地址来自存储总线34,单向;其数据来自/去到存储数据总线34,双向;
所述数据存储体33,可存放node1、node2、node3或node4的数据,其地址来自存储总线34,单向;其数据来自/去到存储总线34,双向;
所述指令寄存器IR35,32位,接收来自存储总线34的指令,作为待执行指令的暂存器;
所述程序地址计数器PC36,32位,其值送往存储总线34,作为下一条指令的地址;
所述32位桶式移位器功能部件39,完成对数据的左移和右移;接收来自通用寄存器R7-R038上的数据,移位结果送往通用寄存器R7-R038;
所述32位ALU算数逻辑运算功能部件317,完成对数据的算数逻辑运算;接收来自通用寄存器R7-R038上的数据,计算结果送往通用寄存器R7-R038;
所述32位地址运算功能部件ARAU310,完成地址运算。两路操作数可分别来自地址寄存器AR7-AR0 311和存储总线34,结果送往地址寄存器AR7-AR0 311;
所述辅助寄存器312为12个,提供诸如寻址、堆栈管理、中断及块重复等的系统功能需求; 数据来自存储总线34,输出值送往39;
所述存储总线控制信号和数据34,完成对存储总线的传输和控制;
所述DMA控制器313,以直接存储器访问的方式完成存储器与外部总线Pbus314的数据交换;DMA控制器313的地址总线和数据总线与34相连,与314相连,地址、数据宽度为32位;
所述定时器Time315,实现看门狗、定时控制功能;
所述AXI总线接口控制器316,32位,一端连接node3的外部总线Pbus 314,另一端连接node1、node2、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
所述外部总线Pbus314,实现外部设备313、315、316与存储器总线34之间的数据交换。
作为本发明的进一步改进:所述节点4包括:指令Cache和启动ROM41、存储总线MB42、指令控制部件43、DMA控制器44、外部总线AXI45、超算矩阵46;
所述指令Cache和启动ROM41, 指令cache存储体,存放节点4所要执行的指令。其地址来自存储总线MB42,单向,数据来自存储总线MB42,单向。加载启动ROM,存放协处理器的初始化程序。其地址来自存储总线MB42,单向,数据来自存储总线MB42,单向;
存储总线MB42,是节点4中其它部件与存储器交换信息的桥梁;
指令控制部件43,负责指令的流出和执行;
DMA控制器44,以直接存储器访问的方式完成超算矩阵46中存储器之间的数据交换,或与外部总线AXI45进行数据交换;
AXI总线控制器45,32位,完成节点4与节点1、节点2和节点3之间的数据交换;
超算矩阵46,完成矩阵定点数的超高速计算。
作为本发明的进一步改进:所述超算矩阵46,包括:
4套乘加矩阵阵列,4条阵列可在一拍内一次并行获得4个8X8的整数矩阵结果,每一个整数矩阵运算单元又可并发流水执行矩阵乘加运算,可一拍获得1个8X8的矩阵结果,字长为32位。
与现有技术相比,本发明的优点在于:本发明的超速矩阵运算协处理器架构,结构简洁,一个算数矩阵的运算效率是传统算数矩阵运算的n2倍。解决了片内SerDes技术的数据传输问题,极大地节省了工程布线时的走线空间,为图像的高速处理提供了一个高速硬件平台。
附图说明
图1是本发明的顶层拓扑结构示意图;
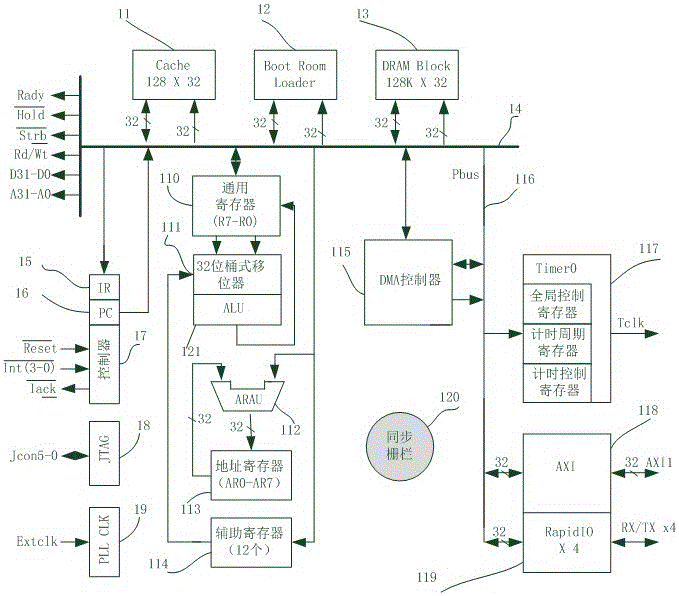
图2是本发明节点1I/O节点的逻辑结构原理示意图;
图3是本发明节点2高速浮点运算节点的逻辑结构原理示意图;
图4是本发明节点3标量超越函数运算节点的逻辑结构原理示意图;
图5是本发明节点4超级整数矩阵运算节点的逻辑结构原理示意图。
具体实施方式
以下将结合说明书附图和具体实施例对本发明做进一步详细说明;
如图1所示,本发明的一种MPP型异构高速MCU系统顶层拓扑结构示意图,包括:4个异构的处理器节点,网络托补采用四面体结构,节点位于四面体的顶点,节点之间采用AXI总线互连,位宽为32位,网络中任一节点到其它节点的步长都是1。其中:node1为I/O节点,node2为高速浮点运算节点,node3为标量超越函数运算节点,node4为超级整数矩阵运算节点。
如图2所示,本发明的节点1,I/O节点的逻辑结构原理示意图;
指令cache存储体11,128×32位,采用LRU淘汰规则,存放node1所要执行的指令。11的地址来自存储总线14,单向;11的数据来自/去到存储数据总线14,双向;
加载启动ROM12,存放node1的初始化程序。12的地址来自存储总线14,单向;12的数据来自/去到存储数据总线14,双向;
数据存储体13,128K×32位,可存放node1、node2、node3或node4的数据,13的地址来自存储总线14,单向;13的数据来自/去到存储总线14,双向;
指令寄存器IR15,32位,接收来自存储总线14的指令,作为待执行指令的暂存器;
程序地址计数器PC16,32位,其值送往存储总线14,作为下一条执行指令的地址;
32位桶式移位器功能部件111,完成对数据的左移和右移。接收来自通用寄存器R7-R0110上的数据,移位结果送往通用寄存器R0-R7110;
32位ALU算数逻辑运算功能部件121,完成对数据的算数逻辑运算。接收来自通用寄存器110 R7-R0上的数据,计算结果送往通用寄存器R7-R0110;
32位地址运算功能部件ARAU112,完成地址运算。两路操作数可分别来自地址寄存器AR7-AR0 113或存储总线14,结果送往地址寄存器113 AR7-AR0;
辅助寄存器114为12个,32位,提供诸如寻址、堆栈管理、中断及块重复等的系统功能需求。 数据来自存储总线14,输出值送往111;
存储总线控制信号和数据14,完成对存储总线的传输和控制。信号分别是:
总线类:
数据总线D31-D0 (I/O/Z) 数据总线;
地址总线A31-A0 (O/Z) 地址总线;
总线控制:
Strb# (O/Z) 访问片外的选通信号;
Rady# (I) 访问外设时外设准备好信号,MCU可以结束本次访问;
Hold# (I) 保持信号,迫使MCU置A23-A0,D31-D0,STRB#,R/W#为高阻,使外设取得总线控制权;
Rd/Wt# (O/Z) 高电平表示读,低电平表示写;
MCU控制器17,是实现控制信号的逻辑,信号分别是:
Reset# (I) 复位信号;
Int3-0# (I) 外部中断;
Iack# (O/Z) 由IACK指令产生一个负脉冲;
JTAG控制逻辑18,实现边界扫描、内部扫描的控制,信号是:
Jcon5-0 (I) JTAG控制信号;
时钟控制逻辑19,实现MCU的时钟控制,信号分别是:
EXTCLK (I) 外部时钟;
DMA控制器115,以直接存储器访问的方式完成存储器与外部总线Pbus116的数据交换。DMA控制器115的地址总线和数据总线14相连,与116相连,地址、数据宽度为32位;
定时器Time117,实现看门狗、定时控制功能;
AXI总线接口控制器118,32位,一端连接node1的外部总线Pbus 116,另一端连接node2、node3、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
RapidIO高速串口控制器119,一端连接node1的外部总线Pbus116,32位,另一端连接外部其它设备,4条高速全双工通道,每个通道的波特率可为1.25Gbps、2.5Gbps、3.125Gbps、6.25Gbps;
外部总线Pbus116,实现外部设备115、117、118、119与存储器总线14之间的数据交换;
同步栅栏120,实现各节点进程之间的同步。
如图3所示,本发明的节点2,高速浮点运算节点的逻辑结构原理示意图;
指令cache存储体21,128×32位,采用LRU淘汰规则,存放node2所要执行的指令。其地址来自存储总线23,单向;其数据来自/去到存储数据总线23,双向;
加载启动ROM22,存放node2的初始化程序。22的地址来自存储总线23,单向;22的数据来自/去到存储数据总线23,双向;
指令寄存器IR24,32位,接收来自存储总线23的指令,作为待执行指令的暂存器;
程序地址计数器PC25,32位,其值送往存储总线23,作为下一条指令的地址;
DMA控制器26,以直接存储器访问的方式完成存储器与外部总线Pbus29的数据交换。DMA控制器26的地址总线和数据总线23相连,与29相连,地址、数据宽度为32位;
AXI总线接口控制器28,32位,一端连接node2的外部总线Pbus 29,另一端连接node1、node3、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
外部总线Pbus29,实现外部设备26、28与存储器总线23之间的数据交换;
浮点乘加矩阵27,可在1拍内一次并行获得8×8×32位的矩阵结果,每一个矩阵运算单元又可并发流水执行矩阵乘加运算,可1拍获得矩阵的1个元素结果,字长位32位。
如图4所示,本发明的节点3,标量超越函数运算节点的逻辑结构原理示意图;
指令cache存储体31,128×32位,采用LRU淘汰规则,存放node3所要执行的指令。31的地址来自存储总线34,单向;31的数据来自/去到存储数据总线34,双向;
加载启动ROM32,存放node3的初始化程序。32的地址来自存储总线34,单向;32的数据来自/去到存储数据总线34,双向;
数据存储体33,128K×32位,可存放node1、node2、node3或node4的数据,33的地址来自存储总线34,单向;33的数据来自/去到存储总线34,双向;
指令寄存器IR35,32位,接收来自存储总线34的指令,作为待执行指令的暂存器;
程序地址计数器PC36,32位,其值送往存储总线34,作为下一条指令的地址;
32位桶式移位器功能部件39,完成对数据的左移和右移。接收来自通用寄存器38R7-R0上的数据,移位结果送往通用寄存器38R7-R0;
32位ALU算数逻辑运算功能部件39,完成对数据的算数逻辑运算。接收来自通用寄存器R7-R038上的数据,计算结果送往通用寄存器38R7-R0;
32位地址运算功能部件ARAU310,完成地址运算。两路操作数可分别来自地址寄存器AR7-AR0 311和存储总线34,结果送往地址寄存器AR7-AR0 311;
辅助寄存器12个312,提供诸如寻址、堆栈管理、中断及块重复等的系统功能需求。 数据来自存储总线34,输出值送往39;
存储总线控制信号和数据34,完成对存储总线的传输和控制;
DMA控制器313,以直接存储器访问的方式完成存储器与外部总线Pbus314的数据交换。DMA控制器313的地址总线和数据总线与34相连,与314相连,地址、数据宽度为32位;
定时器Time315,实现看门狗、定时控制功能;
AXI总线接口控制器316,32位,一端连接node3的外部总线Pbus 314,另一端连接node1、node2、node4对应的AXI总线接口,完成MCU内各节点之间的数据交换;
外部总线Pbus314,实现外部设备313、315、316与存储器总线34之间的数据交换。
如图5所示,本发明的节点4,超级整数矩阵运算节点的逻辑结构原理示意图;
指令Cache和启动ROM41,128×32位,采用LRU淘汰规则,指令cache存储体,存放节点4所要执行的指令。其地址来自存储总线MB42,单向,数据来自存储总线MB42,单向。加载启动ROM,存放协处理器的初始化程序。其地址来自存储总线MB42,单向,数据来自存储总线MB42,单向;
存储总线MB42,是节点4中其它部件与存储器交换信息的桥梁;
指令控制部件43,负责指令的流出和执行;
DMA控制器44,以直接存储器访问的方式完成超算矩阵46中存储器之间的数据交换,或与外部总线AXI45进行数据交换;
AXI总线控制器45,32位,完成节点4与节点1、节点2和节点3之间的数据交换;
超算矩阵46,完成矩阵定点数的超高速计算;
4套整数乘加矩阵阵列,4条阵列可在一拍内一次并行获得4个8×8×32位的整数矩阵结果,每一个整数矩阵运算单元又可并发流水执行矩阵乘加运算,可一拍获得1个8×8×32的矩阵结果,字长为32位。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!