一种嵌入式设备的FLASH资源回收的方法与流程
本发明涉及一种嵌入式设备的FLASH资源回收的方法,属于嵌入式设备技术领域。
背景技术:
嵌入式设备对其本身的可靠性要求极高,当一些不可预测的因素或者是没有发现的潜在危险导致FLASH垃圾资源回收不及时,会造成文件操作耗时过长等异常情况,甚至会造成一些操作无法正常运行,最终导致嵌入式设备产生不可预知的危险。在这种情况下,将很难保证设备运行的可靠性和安全性,甚至会对整个系统造成严重的后果。
因此,及时对FLASH资源进行回收,尽量避免由于设备有效资源不足而造成的设备不能正常运行的异常状况,成为嵌入式设备应用中的重要问题。
技术实现要素:
本发明的目的是提出一种嵌入式设备的FLASH资源回收的方法,用于解决由于设备后台资源回收不及时而导致设备不能正常运行的技术问题。
为解决上述技术问题,本发明提出了一种嵌入式设备的FLASH资源回收的方法,包括:
步骤1,实时检测CPU负载率和Flash空间利用率;
步骤2,根据所述CPU负载率和Flash空间利用率确定后台资源回收的清理周期;所述CPU负载率越低所对应的清理周期越小,所述CPU负载率越高所对应的清理周期越大;所述Flash空间利用率越高对应的清理周期越小,Flash空间利用率越低对应的清理周期越大;
步骤3,根据所述确定的清理周期进行垃圾回收。
进一步地,步骤2中根据所述CPU负载率判定对应的所述清理周期范围,根据所述Flash空间利用率确定在所述判定的对应的清理周期范围内特定的清理周期。
进一步地,所述清理周期的大小还与设备特性有关,所述设备特性包括CPU速率、CPU平均负载、FLASH空间大小和FLASH空间利用率。
进一步地,步骤2中所述CPU负载率越低对应的所述清理周期范围的平均值越低,所述CPU负载率越高对应的所述清理周期范围的平均值越高。
进一步地,在步骤2中当所述Flash空间利用率高于设定阀值时,设备进行报警。
本发明的有益效果是:
根据CPU的负载和FLASH剩余有效资源的情况,自动地调整FLASH垃圾资源回收的快慢,确保设备尽量在有效资源充足的状态下高效运行。在嵌入式设备运行过程中,根据CPU负载情况和有效资源空间剩余情况实时地对垃圾资源回收的清理周期做出调整,在不影响其他任务运行的情况下尽量保证有效资源空间充足,避免由于资源不足而引发的异常情况。
一旦出现有效资源严重不足的异常状况,也能够及时报警,保证了设备运行的安全性和可靠性。
附图说明
图1是清理周期及清理周期范围的示意图;
图2是嵌入式设备的FLASH资源回收方法的流程图;
图3是CPU负载检测任务示意图;
图4是在不同CPU负载下清理周期范围的示意图。
具体实施方式
下面结合附图对本发明进行详细的介绍。
本发明提供的一种嵌入式设备的FLASH资源回收的方法,通过实时检测到的CPU负载率和Flash空间利用率来确定后台资源回收的清理周期,即设备每次清理内存的时间间隔,并根据该特定的清理周期定时清理内存。
在具体介绍该方法之前,首先对清理周期范围进行详细介绍。
如图1所示,嵌入式设备后台资源回收的清理周期按照大小顺序依次排列,具体每个清理周期的大小由设备特性如CPU速率、CPU平均负载、FLASH空间大小和FLASH空间利用率来决定。其中,清理周期的确定没有具体理论上的公式,基于大量具体工程应用而得出的经验公式表示为:
其中T表示清理周期,coefficient是一个与具体工程应用有关的经验系数,free_block表示有效资源剩余量,complexity表示不同业务的系统复杂度,erase_speed表示块擦除速度,gc_ability表示系统本身的垃圾回收能力,fcpu表示CPU主频率,need_space表示flash剩余空间大小。
清理周期范围表示对于按照大小顺序进行排列的多个清理周期值,取其中一段范围内的多个临近的清理周期值所组成的一个集合。
定义清理周期范围的平均值表示为该清理周期范围内的所有清理周期值的平均值。在嵌入式设备运行过程中,清理周期范围的平均值根据实时检测到的CPU负载率的变化情况进行变化,CPU负载率越低所对应的清理周期范围的平均值越低,CPU负载率越高所对应的清理周期范围的平均值越高。
定义清理周期范围的大小表示为该清理周期范围内的所有清理周期值的数目。在嵌入式设备运行过程中,清理周期范围的大小根据CPU负载率变化范围的大小来决定。例如:嵌入式设备使用过程中CPU负载变化范围大,空闲的时候负载率为10%,繁忙的时候负载率高达99%,此时对应的清理周期范围比较大,即该清理周期范围内包含更多的清理周期值;嵌入式设备使用过程中CPU负载变化范围小,空闲的时候负载率为60%,繁忙的时候负载率为70%,此时对应的清理周期范围比较小,即该清理周期范围内包含较少的清理周期值。
在图1的实施例中,清理周期范围的大小为11,即该清理周期范围内包含11种清理周期,该清理周期范围的上限值是2000,下限值是500。在嵌入式设备使用过程中,若CPU负载率变化的范围基本恒定,那么在该恒定的变化范围内,若CPU负载率由小变大,则对应的清理周期范围会向右移动;若CPU负载率由大变小,则对应的清理周期范围会向左移动。
在嵌入式设备使用过程中,若CPU负载率变化的范围发生改变,那么对应的清理周期范围的大小也要相应做出调整。此时若CPU负载率的变化范围变大,则清理周期范围的大小也会相应变大,可能为12、13或14等值;若CPU负载率的变化范围变小,则清理周期范围的大小也会相应变小,可能为10、9或8等值。
一种嵌入式设备的FLASH资源回收的方法,参照图2,具体包括:
步骤1,实时检测CPU负载率和Flash空间利用率;
步骤2,根据所述CPU负载率和Flash空间利用率确定后台资源回收的清理周期;所述CPU负载率越低所对应的清理周期越小,所述CPU负载率越高所对应的清理周期越大;所述Flash空间利用率越高对应的清理周期越小,Flash空间利用率越低对应的清理周期越大;
步骤3,根据所述确定的清理周期进行垃圾回收。
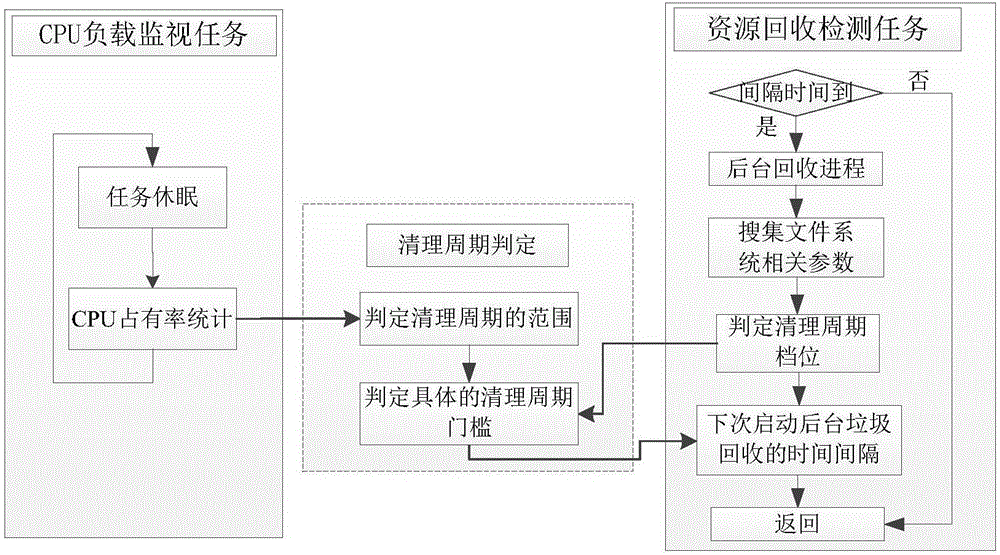
对于步骤1,嵌入式设备在运行过程中,CPU的负载率是不断变化的,需要实时检测CPU的负载情况,其中具体实现CPU负载检测任务的方法如图3所示:
在检测任务的初始化阶段,先记录一段固定延时的时间间隔,由于此时其他任务都没有开始运行,所以该固定延时的时间间隔是一个比较精确的标准参照时间间隔。
在检测任务运行期间,记录一段固定延时的标准参照时间间隔,该标准参照时间间隔与检测任务初始化阶段所记录的时间间隔一样。在设备运行期间,由于检测任务的优先级最低,所以只要有其他任务运行,就会打断该检测任务去执行其他任务,直到其他任务都执行完毕并处于挂起状态,该检测任务才会被继续执行。所以CPU任务越多,执行越频繁,记录固定延时的时间间隔所需的实际时间间隔就越长。将设备运行期间获取的实际时间间隔与标准参照时间间隔进行比较就能够得到CPU的占有率,进而计算出CPU的负载大小,并根据CPU的负载情况,调整程序代码段自检的门槛值。CPU负载的每次检测任务完成后,检测任务进入休眠,并为下次检测任务做好准备。
对于步骤2,若CPU负载率变化范围不变,则对应的清理周期范围的大小不变,那么在该固定的清理周期范围内,若CPU负载率比较低,对应的清理周期范围的平均值也相应较低,即该清理周期范围内的清理周期的取值相对较小,以减小后台资源回收检测任务的时间,提高垃圾回收速度;若CPU负载率比较高,对应的清理周期范围的平均值也相应较高,即该清理周期范围内的清理周期的取值相对较大,以增大后台资源回收检测任务的时间,降低垃圾回收速度,减轻CPU负载。
对于一个确定的清理周期范围,具体选择该对应清理周期范围内的哪个清理周期值则是由实时检测到的Flash空间利用率来决定,其中Flash空间利用率的获取可根据现有技术中Flash空间利用率的检测方法实现。
在Flash空间利用率比较高的情况下,清理周期选择在对应清理周期范围内的较小的清理周期值,在Flash空间利用率比较低的情况下,清理周期选择在对应清理周期范围内的较大的清理周期值。
对于步骤3,设备需要实现资源回收的检测任务,在检测任务初始化时,需要定义垃圾回收清理周期的默认值,比如:回收清理周期设定为400ms,那么每隔400ms就会进行一次后台的垃圾回收。在检测任务运行期间,当垃圾清理时间到来时,后台回收进程开始,通过搜索文件系统的相关参数,实现资源回收。资源回收任务完成后,根据实时检测CPU负载率和Flash空间利用率确定的具体的清理周期值,调整下次后台垃圾回收的时间间隔。
在CPU负载率的变化范围不会发生改变的情况下,对应清理周期范围的大小不变,下面具体以图4为例,详细地说明随着CPU负载率的变化,清理周期具体的确定方法:
CPU低负载状态:当CPU占有率小于30%时候,此时CPU负载比较低,清理周期范围的平均值较小,可以看到此时的清理周期范围是100ms到900ms,共包括11个清理周期,具体选择哪个清理周期值就需要由剩余的有效资源决定,即需要根据有效资源剩余的程度在该清理周期范围内选择相应的清理周期。有效资源剩余量比较多的时候,说明资源足够,垃圾回收的需求不迫切,可以选择900ms的清理周期;有效资源剩余量比较少的时候,垃圾回收的需求就比较迫切,可以选择100ms的清理周期,加快垃圾回收。
CPU中负载状态:当CPU占有率在60%左右的时候,此时CPU负载较大,清理周期范围的平均值变大,可以看到此时的清理周期范围是300ms到1600ms,共包括11个清理周期,具体选择哪个清理周期值就需要由剩余的有效资源决定。有效资源剩余量比较多的时候,说明资源足够,垃圾回收的需求不迫切,可以选择1600ms的清理周期;有效资源剩余量比较少的时候,垃圾回收的需求就比较迫切,可以选择300ms的清理周期,加快垃圾回收。
CPU高负载状态:当CPU占有率大于90%时候,此时CPU负载很大,清理周期范围的平均值相对较大,可以看到此时的清理周期范围是600ms到2200ms,共包括11个清理周期,具体选择哪个清理周期值就需要由剩余的有效资源决定。有效资源剩余量比较多的时候,说明资源足够,垃圾回收的需求不迫切,可以选择2200ms的清理周期;有效资源剩余量比较少的时候,垃圾回收的需求就比较迫切,可以选择600ms的清理周期,加快垃圾回收。
当然,图4中的清理周期以及清理周期范围仅为一种具体的实施例,实际应用中需要根据嵌入式设备和业务的需求来进行更精确的设定。
另外,在嵌入式设备运行过程中,后台资源回收特定的清理周期也可以根据CPU占有率和Flash空间利用率情况进行直接计算或者查表来获取。
- 还没有人留言评论。精彩留言会获得点赞!