基于GPS平台的k‑bisimulation计算算法的制作方法
本发明属于图数据平台处理技术领域,特别涉及一种基于GPS平台的k-bisimulation计算算法。
背景技术:
在基于图的众多研究中,互模划分在许多应用领域中都起着至关重要的作用。直观上,图的互模划分是指将图中的点按照预先定义的“特征”进行划分的操作,“特征”相同的点被划分到同一集合中。“特征”可以根据需要而灵活定义;互模划分有着广泛的应用。在数据压缩领域,同一集合中的点使用相同的编号;通过适当的定义,互模划分可以被用来为XML以及RDF数据库建立结构化索引;此外,在数据的查询优化以及分析中互模划分也有明确的应用。随着图数据规模的增长,例如:点数目、边数目的增长,许多图数据,例如社交网络图等,已经包含数以亿计的点和边。传统的运行在单机上的互模划分算法面临着越来越大的挑战,分布式算法以及并行算法则成为提高图计算可扩展性的重要途径。
针对图的互模划分问题,两种基于MapReduce计算模型的分布式算法近来被提出来,这两种算法均计算图的局部互模划分,又称k-互模划分。k-互模划分预先定义点的特征,包含点的内容以及与点距离为k以内的邻居的信息。这两种算法均使用MapReduce计算模型的开源实现平台:Hadoop,Hadoop是一种通用的分布式数据处理平台,执行计算时将计算的中间结果直接存储在本地磁盘或者存储在HDFS文件系统上。图的局部互模计算算 法需要使用多轮迭代操作,采用Hadoop平台处理则需要精细设计多轮MapReduce操作,每轮操作中的Map操作会将中间结果存储在本地磁盘上,Reduce操作会将中间计算结果存储在HDFS上,磁盘或者HDFS上的读写操作会带来性能瓶颈。此外,每次MapReduce迭代操作均会将整个图中所有点边的状态通过网络传输,重新为点边分配计算节点,这不可避免的带来沉重的网络通信负担。尽管基于MapReduce模型可以解决互模划分的可扩展性问题,但采用Hadoop平台计算点的k-互模划分特征,会带来沉重的全局网络通讯代价,进而影响算法本身的效率。这成为两种基于Hadoop算法可能遇到的瓶颈之一。
技术实现要素:
发明目的:本发明提供基于GPS平台的k-bisimulation计算算法,以解决现有技术中的问题。
技术方案:为实现上述目的,本发明采用的技术方案为:
基于GPS平台的k-bisimulation计算算法,其算法步骤包括图的预划分处理和k-互模特征的分布式计算;所述图的预划分处理用于减少分配到不同工作节点上面的图之间的边数,还保证各个工作节点处理的点规模相当;所述k-互模特征的分布式计算包括:点特征编号更新、计算节点特征的编号和计算图中每个点的k-互模划分特征;图的预划分处理和k-互模特征的分布式计算都基于节点编程的GPS分布式图数据处理平台,用于规定空间局域性。
进一步,所述输入到GPS分布式图数据处理平台的图数据格式为:<vertex-id><opt-vertex-value><outgoing-edge-id-1><opt-outgoing-edge-id-1-v alue><outgoing-edge-id-2><opt-outgoing-edge-id-2-value>…<outgoing-edge-i d-w><opt-outgoing-edge-id-w-value>;每一行数据代表了图中一个点的信息,其中vertex-id表示点编号,opt-vertex-value表示点的内容,outgoing-edge-id-1表示该点的第一条出边指向的点的编号,opt-outgoing-edge-id-1-value表示该点第一条出边的边值,边的编号w=1,2,3…;GPS分布式图数据处理平台的输入按照点的标号从0开始输入,如果某个点没有边,则独自占一行输入。
进一步,所述图的预划分处理的操作步骤包括:
步骤(A),将原始图数据转换成GPS分布式图数据处理平台要求的输入格式;
步骤(B),将GPS分布式图数据处理平台中,图信息的发送方向逆转,将信息反向传递;
步骤(C),使用METIS程序对图做预划分处理,将划分后的多个子图输入到GPS中;
步骤(D),使用METIS程序将图划分后获得的子图数目是实验中使用的工作节点数目的5倍,所述每个工作节点处理五个子图。
进一步,所述图的预划分处理的操作只需执行一次。
进一步,所述k-互模特征的分布式计算的操作步骤包括:
步骤(E),根据点的内容计算点的k-互模划分特征编号,初始特征编号k=0;
步骤(F),向所有外出边相邻点发送点的初始特征编号λE0(u,u′)以及边的编号pId0(u′);
步骤(G),从相邻点中获取自身的特征信息;
步骤(H),计算点的初始特征编号λE0(u,u′)以及边的编号pId0(u′),处理获取到的特征信息集合,获取下一步的特征编号λE1(u,u′)以及边的编号pId1(u′);
步骤(I),向所有外出边相邻点发送点的特征编号λE1(u,u′)以及边的编号pId1(u′),从相邻点中获取自身的特征信息,计算下一步的点的特征编号以及边的编号;
步骤(J),重复步骤(I),当计算完k-互模划分后,输出经过k互模划分的图,运行状态设置为休眠态,程序结束。
进一步,所述算法通过网络传输的数据主要有特殊标志、出发点编号、有向边的编号、终止点编号以及出发点所在的划分集合编号;假定这五个元素的长度都是a个字节、图中点的个数为N、边的个数为M;边的起点和终点位于不同工作节点数目为M',总的网络数据传输规模为3×a×M'。
有益效果:与现有技术相比,本发明具有以下优点:
1、本发明提出了基于GPS分布式图处理平台的局部互模划分算法,利用分布式图处理平台的框架和编程思想大幅度提升算法运行效率,可达到网络数据传输量仅为采用MapReduce计算模型算法的1/2~1/12;并且,对于计算包含数亿边、点的大图的局部互模划分,本发明算法所需的计算时间仅为采用MapReduce计算模型算法的1/7~1/16;
2、采用“预划分处理”的做法,本发明进一步提升算法效率。在具体执行前,对图数据进行预划分,使得对于分配到不同工作节点上处理的点之间边数尽可能的减少,进一步降低了网络数据传输量;
3、为了平衡不同工作节点之间的负载,本发明算法在做预处理的时候,预先划分的子图数目是工作节点数目的5倍,然后给每个工作节点分配5个子图,以此达到不同工作节点之间的负载均衡的目的。
附图说明
图1是本发明实施例的算法样例图;
图2是本发明实施例中输入到GPS平台的数据。
具体实施方式
基于GPS平台的k-bisimulation计算算法,其算法步骤包括图的预划分处理和k-互模特征的分布式计算;所述图的预划分处理用于减少分配到不同工作节点上面的图之间的边数,还保证各个工作节点处理的点规模相当;所述k-互模特征的分布式计算包括:点特征编号更新、计算节点特征的编号和计算图中每个点的k-互模划分特征;图的预划分处理和k-互模特征的分布式计算都基于节点编程的GPS分布式图数据处理平台,用于规定空间局域性。
前述输入到GPS分布式图数据处理平台的图数据格式为:<vertex-id><opt-vertex-value><outgoing-edge-id-1><opt-outgoing-edge-id-1-v alue><outgoing-edge-id-2><opt-outgoing-edge-id-2-value>…<outgoing-edge-i d-w><opt-outgoing-edge-id-w-value>;每一行数据代表了图中一个点的信 息,其中vertex-id表示点编号,opt-vertex-value表示点的内容,outgoing-edge-id-1表示该点的第一条出边指向的点的编号,opt-outgoing-edge-id-1-value表示该点第一条出边的边值,边的编号w=1,2,3…;GPS分布式图数据处理平台的输入按照点的标号从0开始输入,如果某个点没有边,则独自占一行输入。
前述图的预划分处理的操作步骤包括:
步骤(A),将原始图数据转换成GPS分布式图数据处理平台要求的输入格式;
步骤(B),将GPS分布式图数据处理平台中,图信息的发送方向逆转,将信息反向传递;
步骤(C),使用METIS程序对图做预划分处理,将划分后的多个子图输入到GPS中;
步骤(D),使用METIS程序将图划分后获得的子图数目是实验中使用的工作节点数目的5倍,所述每个工作节点处理五个子图。
前述图的预划分处理的操作只需执行一次。
前述k-互模特征的分布式计算的操作步骤包括:
步骤(E),根据点的内容计算点的k-互模划分特征编号,初始特征编号k=0;
步骤(F),向所有外出边相邻点发送点的初始特征编号λE0(u,u′)以及边的编号pId0(u′);
步骤(G),从相邻点中获取自身的特征信息;
步骤(H),计算点的初始特征编号λE0(u,u′)以及边的编号pId0(u′),处理获取到的特征信息集合,获取下一步的特征编号λE1(u,u′)以及边的编号pId1(u′);
步骤(I),向所有外出边相邻点发送点的特征编号λE1(u,u′)以及边的编号pId1(u′),从相邻点中获取自身的特征信息,计算下一步的点的特征编号以及边的编号;
步骤(J),重复步骤(I),当计算完k-互模划分后,输出经过k互模划分的图,运行状态设置为休眠态,程序结束。
前述算法通过网络传输的数据主要有特殊标志、出发点编号、有向边的编号、终止点编号以及出发点所在的划分集合编号;假定这五个元素的长度都是a个字节、图中点的个数为N、边的个数为M;边的起点和终点位于不同工作节点数目为M',总的网络数据传输规模为3×a×M'。
下面结合实施例对本发明作更进一步的说明。
为了并行进行高效图的k-互模划分计算,本发明算法的设计基于以下几点考虑:
第一,进行图的预划分操作,较大幅度的减少了位于不同工作节点上的点之间的边数,而只有边的起点终点处于不同工作节点上时的数据传输才需要通过网络进行,这样的处理意味着较大幅度的减少了通过网络传输的数据量;
第二,“自动”实现点特征编号的更新,而不用为此增加额外操作;Luo为了实现节点特征编号的更新,增加了一次MapReduce操作。为 了实现节点特征编号的更新,不惜额外将图中每条边通过MapReduce处理,增加了网络数据传输负担。而由于本发明算法采用分布式图数据处理平台及相应的算法框架,所以无需为此增加额外操作。
第三,采用哈希函数来计算节点特征的编号,这相比较于Luo节省了很多运算;
第四,考虑到为了计算图中每个点的k-互模划分特征,算法只需要利用到点的邻居(与点距离不超过k)信息,而采用基于节点编程的GPS分布式图数据处理平台,可以充分利用到这种空间局域性;
整个算法分为两个部分:
第一部分实现图的划分,在尽可能减少分配到不同工作节点上面子图之间的边数的同时保证各个工作节点处理的点规模相当;
第二部分实现各个点的k-互模特征的分布式计算;
首先定义输入到GPS分布式图数据处理平台的图数据格式:
<vertex-id><opt-vertex-value><outgoing-edge-id-1><opt-outgoing-edge-id-1-v alue><outgoing-edge-id-2><opt-outgoing-edge-id-2-value>...
每一行数据代表了图中一个点的信息,其中vertex-id表示点编号,opt-vertex-value表示点的内容,outgoing-edge-id-1表示该点的第一条出边指向的点的编号,opt-outgoing-edge-id-1-value表示该点第一条出边的边值(在接下来的实验中,边值为该边的编号)。
GPS是要求输入按照点的标号从0开始输入,如果某个点没有边,那么也应独自占一行输入。
下述算法给出了本算法的部分(伪)代码实现。
上述算法中,Pre_Process(G)代表了算法的第一部分,进行图的预处理。在整个算法的执行过程中,图的预处理只需要执行一次。图的预处理需要完成以下四部分的工作:
1)将原始图数据转换成GPS要求的输入格式,这部分工作在第5节有详细的介绍;
2)实现图中有向边方向的倒转,因为计算点的特征需要从其外向相邻点中获取信息,而GPS中信息的发送是沿着有向边指向的方向,由有向边的起点向终点传递;
3)使用METIS程序对图做预划分处理,同时,为了将划分后的多个子图输入到GPS中,需要对图数据进行转换;
4)平衡各个工作节点的工作量;经过METIS程序划分后,每个工作节点处理一个子图在部分实验中会导致比较严重的负载不均衡问题,即某个工作节点的运行时间相比较于其他工作节点要长许多。为了均衡各个工作节点上的负载,实验在做预划分的时候使用METIS程序将图划分后获得的子图数目,是实验中使用的工作节点数目的5倍,即每个工作节点处理五个子图。算法运行样例中预处理划分的子图数目等于工作节点数目;
函数compute()代表了算法的第二部分代码。在第superstepNum轮迭代中,每个点均会执行一次compute函数,执行完毕后superstepNum自动加一。详细解释如下:
1)3-4行代码根据点的内容计算点的初始特征编号,即0-互模划分特征编号(k=0);
2)5-8行代码向所有外出边相邻点发送点的初始特征编号以及边的编号,即发送(λE(u,u'),pId0(u'));
3)10-12行代码从相邻点中获取自身的特征信息;
4)13-14行代码计算点的特征编号,采用哈希函数来处理获取到的特征信息集合,进而获取特征编号;需要注意的是哈希值应当与特征信息集中中元素的顺序无关。
5)15-18行代码向所有外出边相邻点发送点的特征编号以及边的编号,即发送(λE(u,u'),pId0(u'));
6)当计算完k-互模划分后,在第19行代码中点将自己的运行状态设置为休眠态。程序中所有点在下一轮迭代开始前进入休眠态,程序结束;
图1是算法样例图。图1是原始样例图的翻转图,即将原始样例图中的每条有向边边的指向颠倒。
点的初始内容(图中的A,B)可以根据需要选择是否输入到GPS中;出于完整性的考虑。伪代码中以及本节的算法运行样例中均默认点的初始内容是存在的。点的初始内容经过哈希函数的计算即可获得点的初始特征编号,即0-互模划分特征编号。
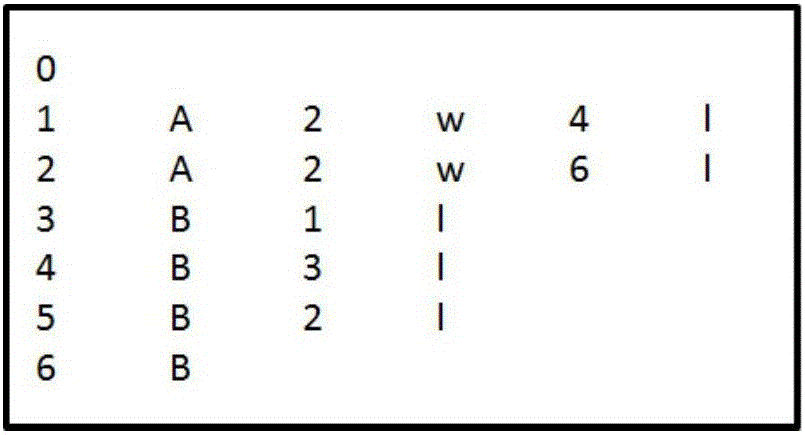
图2是输入到GPS平台的数据,根据GPS平台的默认处理(假设有两个工作节点),点0、2、4、6会被放在第一个工作节点中进行处理,点1、3、5会放在第二个工作节点中处理。有4条边的起点和终点处于不同的工作节点中。
经过图的预划分处理,图从边(1,w,2)处分为两块子图。第一个工作节点处理点1、3、4而第二个工作节点处理点2、5、6、0,此时只有1条边的起点和终点处于不同的工作节点中。为了将经过预划分的子图输入到GPS分布式图数据处理平台中,需要按照划分结果处理图2的算法运行样例输入,以便在GPS中实际的将点1、3、4放置于同一个工作节点中,将点0、2、5、6放置于另一个工作节点中。处理的方法是将图2中的编号0、1、2、3、4、5、6分别映射成0、1、2、3、5、4、6,再按照第一列排序。这样做的依据是GPS平台内部默认的分配算法是将编号为node_id的点分配到编号为vertex_id=node_id%vertex_num的工作节点上,其中vertex_num为工作节点的数目。
第0轮迭代,图中各点根据点的内容计算初始特征编号,并沿着有向边向相邻点发送信息{边值,初始特征编号};
从第1轮到第k轮迭代,首先从相邻点获取其特征以及对应边的边值,加上点的内容,即sigi(u)=(pId0(u),L),然后利用哈希函数计算点的当前特征编号,并更新;
当k-互模划分计算完成后,所有的点进入休眠态,程序结束。
下面给出算法性质的分析,在分析之前有两点需要说明。第一,由于三种算法的本质是一样的,故而认为对于同一个计算任务三种算法所需要的迭代次数也是相同的,同时算法均需要有个终止条件判断部分,这部分需要的通讯量非常少,故而本节的讨论没有考虑这部分;第二,对于Hadoop平台而言,无论mapper和reducer是否运行于同一台机器,两者之间的数据传输均使用网络,即可以认为mapper和reducer之间所有的数据均通过网络传输。
通过网络传输的数据主要有特殊标志、出发点编号、有向边的编号、终止点编号以及出发点所在的划分集合编号。假定这五个元素的长度都是a个字节、图中点的个数为N、边的个数为M。
对于Luo的算法,第一次MapReduce操作通过网络传输的数据有两部分,(点编号,特别标注,点的初始集合编号,点在上一轮迭代后所在的集合编号)以及(发出点编号,有向边的编号,终止点编号,终止点在上一轮迭代后所在的集合编号)。合并起来,第一轮通过网络传输的数据规模为4×a×N+4×a×M;第二次通过网络传输的数据为(点编号,特殊标志,点的初始集合编号,点的特征),其中点的特征包括了点上一轮迭代后所在的集合编号、从它出发的边编号以及指向的点的上一轮迭代后所在集合编号。合并起来,第二次MapReduce操作通过网络传输的数据规模为4×a×N+2×a×M;第三次MapReduce操作通过网络传输的数据为(点编号,特殊标志,点所在的初始集合编号,点的本轮迭代后所在集合编号),故而为4×a×N。综合整个过程,每一轮迭代需要通过网络传输的数据总量为6×a×M+8×a×N。
对于的算法,其需要通过网络传输的数据也有两部分:(起始点编号,数字0,起始点编号,边编号,终止点编号,终止点所在的集合编号)和(终止点编号,数字1,起始点编号,边编号,终止点编号,终止点所在的集合编号),为了方便起见可以认为数字0和数字1的大小也是a个字节。可以计算出来,通过网络传输的数据规模为6×a×M+6×a×M=12×a×M。
对于本发明提出的算法,仅当边的起点和终点位于不同工作节点的时候,它们之间的数据传输才需要通过网络,假设这样的边的数目为M'。需要通过网络传输的数据为(边编号,点在上一轮迭代后所在集合编号,终止点编号)则总的网络数据传输规模为3×a×M'。
Luo的算法的网络通讯量为6×a×M+8×a×N,图中边的数目一般比点的数目要多许多,如Twitter的数据中边的数目几乎为点的数目的30倍。故而可以认为Luo算法的网络通讯量为6×a×M。的算法的网络数据 通讯量为12×a×M。
根据实验结果,M'在多数情况下相当于M的1/3,有些情况下甚至仅为M的1/50。这里取故所以本发明提出的算法网络数据通讯量近似为a×M。算法的网络数据通讯量下降为Luo的算法的1/6,的算法的1/12。最坏情况下M'=M,算法的网络数据通讯量下降为Luo的算法的1/2,的算法的1/4。
根据上述分析,本发明提出的算法的网络数据通讯量下降为Luo的算法的1/2~1/6,的算法的1/4~1/12。
k-互模是指预先定义点的特征只包含距离它k以内(包含k)的邻居信息以及点自身的信息(k≥0)。
N表示有限的点集,表示边集合,λN表示从点集N到点编号集合ΓN的映射,λE表示从边集E到边编号集合ΓE的映射。k-互模严格的数学定义如下:
k是一个非负整数,G=<N,E,λN,λE>是一个图,那么点u,v∈N被称为k-互模(表示为u≈k v),当且仅当下述条件成立:
λN(u)=λN(v);
当k>0时,则使得u'≈k-1v',λE(u,u')=λE(v,v');
当k>0时,则使得v'≈k-1u',λE(v,v')=λE(u,u');
本发明提出的的算法不是为了判断两个图是否是k-互模,为的是将图 中的点划分为不同的集合,同一集合内的点之间k-互模。
k是一个非负整数,G=<N,E,λN,λE>是一个图,k-互模划分标识是k+1个函数映射的集合P={pId0,…,pIdk};对于0≤i≤k,pIdi是从点集N到点编号集合的一个映射,并且对于pIdi(u)=pIdi(v)当且仅当u≈iv。
为了将每个点划分到对应的集合中,基于每个点所在的位置为每个点建立“特征”,特征的严格定义如下:
k是一个非负整数,G=<N,E,λN,λE>是一个图,P={pId0,…,pIdk}是图G的k-互模划分标识,那么u∈N的k-互模划分特征sigk(u)=(pId0(u),L)。L为点的位置信息,
本发明提出的算法基于GPS分布式图数据处理平台,类似的平台还有Google公司的Pregel图数据处理平台等,都可以将本发明用于这一类图数据处理平台。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!