一种互联网用户行为采集及分析检测的大数据方法与流程
本发明属于计算机、互联网、信息技术领域,涉及信息的搜集与分析技术,尤其是一种互联网用户行为采集及分析检测的大数据方法。
背景技术:
随着科技与互联网的进步,电子商务成为互联网行业的重要的一环,数据已经成为改变一家企业所必不可少的利器。尤其是随着大数据时代的到来,一些曾经非常棘手的问题都能够迎刃而解。用户的消费习惯、兴趣爱好、关系网络以及整个互联网的趋势、潮流都将成为互联网从业者关注的热点,而这一切的获取和分析都离不开大数据。一方面,社会化媒体基础上的大数据挖掘和分析将会衍生很多应用;另一方面,基于数据分析的营销咨询服务也正在兴起。
数据背后潜藏着巨大的商业机会。以前只有Google、微软这样的公司能做大数据的深挖,现在已经有越来越多的创业公司进入,不同公司在不同维度的数据分析和服务正创造出新的商业模式。
微博发言使得人们的行为和情绪的细节化测量成为可能。挖掘用户的行为习惯和喜好,凌乱纷繁的数据背后找到更符合用户兴趣和习惯的产品和服务,并对产品和服务进行针对性地调整和优化,这就是大数据的价值。大数据也日益显现出对各个行业的推进力。
大数据的核心即是通过收集、整理生活中方方面面的数据,并对其进行分析挖掘,进而从中获得有价值信息,最终衍化出一种新的商业模式。这里面,核心的技术就是数据挖掘和统计分析。
目前现有企业虽然可以通过ERP系统及时的监控跟踪分析自己的产品,但是对于竞争对手的情况,市场的动向以及消费者口碑等信息难以从量的角度把握。
经对现有技术的文献检索发现,有关用户多维度分析与监测方法主要有以下几种:
1.LDA(Latent Dirichlet Allocation)算法。这是一个概率模型,用于从文本中挖掘出用户所谈论的主题,本发明将其应用在中文系统,并实现了分布式环境下的海量数据的快速挖掘(来源:Blei,D.M.,Ng,A.Y.,Jordan,M.I.:Latent Dirichlet Allocation.Journal of Machine Learning Research 3(2003)993-1022)
2. Bayes算法(朴素贝叶斯算法)来进行年龄预测。这是一个非常常用的文本分类算法,也适合在分布式环境里对海量数据进行分类,效果不错。(参考文献:1.Zhang,Harry.″The Optimal ity of Naive Bayes″.FLAIRS2004conference.
方法1是一个集合概率模型,主要用于处理离散的数据集合,目前主要用在数据挖掘(dm)中的text mining和自然语言处理中,主要是用来降低维度的。效果不错但是会有数据缺失的问题。
方法2是ML中的一个非常基础和简单的算法,常常用它来做分类,适用于text classification。现在的研究中已经很少有人用它来实验了(除非是做base line),但确实是个很好的入门的算法,不过对于年龄等数据推算补足还是太过于粗略。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种互联网用户行为采集及分析检测的大数据方法。
为达到上述目的,本发明的解决方案是:
一一种互联网用户行为采集及分析检测的大数据方法,包括:
(1)搜集数据进行预处理;
(2)对预处理之后的数据进行分析、挖掘;
(3)对数据分析、挖掘数据的结果进行展现、可视化,对数据结果集加以利用。
进一步,步骤(1)中所述数据的搜集,主要采用ETL进行预处理;
优选的,搜集主要的互联网用户数据,主要是微博、qq、微信数据,包括用户的个人基本信息和网络发言数据;以及主要的互联网商业数据,包括电商,行业论坛,门户网站的相关频道,主要是商品,商品销量,以及用户评价等;
优选的,通过自建计算集群来进行上述搜集,从互联网上抓取网页→建立索引数据库→在索引数据库中搜索排序;
优选的,根据公开的信息去预测、补全未公开的信息,如年龄预测,性别预测等。
根据公开的信息去预测、补全年龄的年龄演算推测法:
把年龄分为N個年齡群組A{a1,a2,a3,a4..an}表示A用户的好友集合
(1)然后把关系网数据降维,减少数据量;
(2)age=MAX(count(an)).age;A的年龄=好友中年龄出现最多的
(3)预测正确年龄段人数N;
(4)实际有年龄段的人数M;
(5)准确率=预测正确年龄段人数/实际有年龄段的人数=N/M。
步骤(2)中以数据的分析,挖掘为主;
优选的,数据分析:企业用户可以按时间纬度自己的产品以及指定竞争对手在各个网络渠道的销售情况,以及这些产品的评论口碑,给企业用户多维查询;
优选的,数据挖掘主要包括:
(1)基于CRM库的定向营销:预先建立微博、qq、微信等实体用户数据库,并且为这些用户的贴上喜好标签,企业方可以对这些用户发送广告信息;
(2)交叉销售;
优选的,购买了某品牌产品的用户,也同时购买了其他产品;建议增加绑定,提高销量;
(3)促销活动预测和结果分析;
优选的,对促销前,对目标客户群锁定,计算促销方案,促销之后,评价;
优选的,促销前,一般促销方案分为:满减,满赠,积分等;
比如,满300元送精美餐具一套,预估日均业绩100万,送多少比合适;
预测的参加率为30%,(100万*30%)/300元=1000笔(合适)
优选的,促销后,评测促销结果:
a.促销活动的效益增加率;
b.基于微博,评论数据,了解有多少人还记得这次促销活动,看法和态度如何,对品牌的忠诚度的上升或下跌;
(4)时间序列预测;基于全网的用户发言倾向,产品数据,对企业方的产品销量,市场饱和度,市场走势发展做出预测;
优选的,比如检测到某个时间段,笔记本电脑热卖;而且季节也临近夏季,那么笔记本用户对电脑散热的需求也随之而来。
步骤(3)中第三阶段以数据的展现、可视化、数据结果集的操作利用为主;
优选的,除了常规的表示数据走势的曲线图,数据份额的饼状图以外,该系统可以为企业方提供向特定用户群发联络信的功能。
针对互联网上海量用户的发言,采用的技术是中文的文本挖掘;中文的文本分析首先用到的是中文分词;
优选的,本发明采用的是IKAnalyzer中文分词系统,这是一个开源的分词系统,在这个工具的基础上,创建了多达250个分类词库;
优选的,在经过“分词”这一基本的文字处理后,为了从海量的用户发言中挖掘出用户的兴趣爱好,从而给每个用户打上标签,采用的是LDA算法;用于从文本中挖掘出用户所谈论的主题,本发明将其应用在中文系统,并实现了分布式环境下的海量数据的快速挖掘;
优选的,采用 Bayes算法,即朴素贝叶斯算法来进行年龄预测。
在互联网的海量数据中,用户间的关系组成了一张庞大的关系网,从中找出最核心的用户,即整个关系网中最有影响力的用户;
优选的,采用PageRank算法,将其应用在人与人之间的网络关系上,用来判断一个人的影响力,通过分布式环境,能够计算几亿人之间的关系,得到几亿人的影响力。
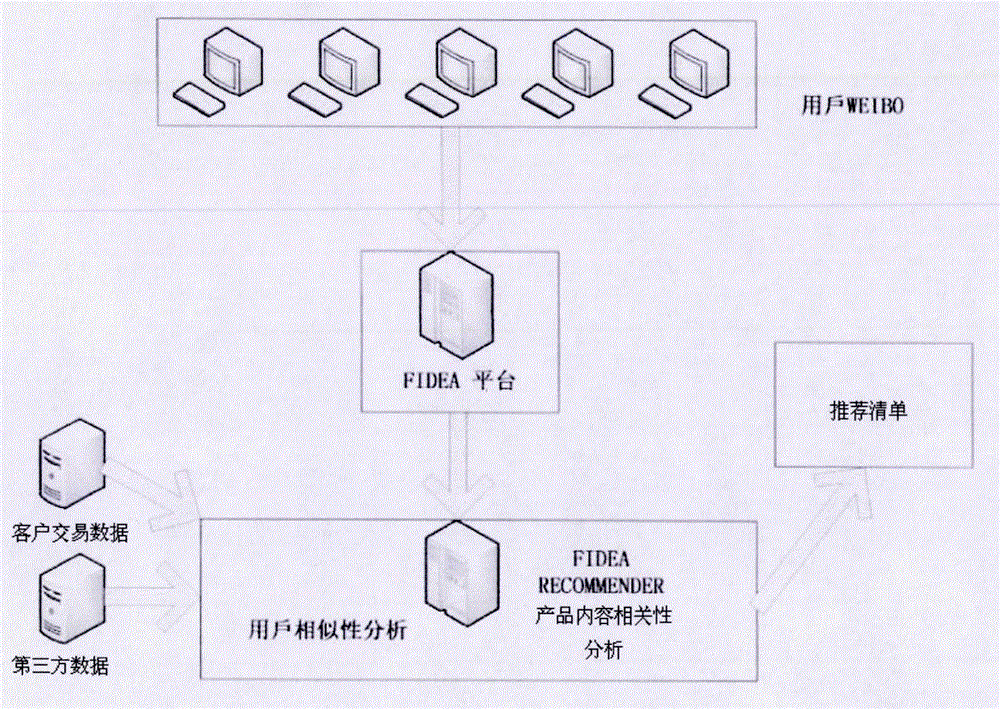
通过微博平台实现:1)海量信息的获取;2)海量信息的分析与挖掘;
优选的,部署一个爬虫集群,抓取到新浪微博上的用户基本信息,用户发言信息,甚至评论,转发等信息;
抓取到的信息,保存在HADOOP的HIVE数据库,通过分布式系统的强大数据处理能力,本发明对这些信息进行统计分析与挖掘,从中整理出企业感兴趣的,针对企业官方微博的粉丝的分析结果,供企业决策参考;
优选的,针对3个层面进行分析:
1)粉丝比对分析:主要是针对粉丝共有信息的一些比对分析,如“基本信息”(年龄,性别等),“属性”,“发贴习惯”,“粉丝重合”情况等;
2)微博比对分析:针对蓝V之间所发微博的差异度分析;
3)个性比对分析:不同蓝V的粉丝群特有属性的统计分析,如:“常用发帖平台”,“粉丝兴趣爱好”,“粉丝关注的关键字”,“粉丝电商偏好”等等;
优选的,给企业官V总结5个指数:
粉丝质量指数,影响力指数,勤奋指数,网络购买指数,被攻击指数,将其综合定义成为一个飞迪尔指数;
通过飞迪尔指数以及5个细化指数,可以了解到企业官V在微博运营方面哪里做得领先于竞争对手,哪里还有待加强。
所述的方法,其特征在于:操作步骤:
6)通过爬虫软件抓取互联网上开发平台的公开信息;
7)抓取到的数据汇总到数据库中;
8)对抓取来的数据进行整理、建模;
9)将统计分析的数据生成到MYSQL数据库;
10)更新数据,开放给用户使用;
操作步骤:
步骤1)中通过微博搜集数据;海量的数据采用一个爬虫集群来进行搜集;
步骤2)中,数据量巨大,需要一个HADOOP分布式环境,将数据保存在HIVE数据库中;
步骤3)中,包括:
1)最基础的是分词,这是必须的第一步;
2)然后将分词结果应用在不同的模型中,如LDA模型, Bayes模型,对用户进行打标签,以及分类;
3)根据网络关系,迭代计算一定规模人群的影响力;
4)根据分词结果,基于TF-IDF算法,统计不同用户群的关键字排名;
步骤4)中将统计分析的数据生成到MYSQL数据库,确保MYSQL数据库可以支持多达几十个条件的组合查询,例如用户规模在2000万,查询效率在5秒左右;
步骤5)中,进一步根据人口和地理信息进行分类统计;
优选的,后续的问题:
数据范围(边缘)的精细化
例如:发现实际有个1980年出生人,好友,同学,同事有79年比较多,预测的话就算到70后了;
可以用聚类先分出实际范围,做最大化距离划分,以此提高精度。
使用本发明可以实现更为精准、有效的信息搜集及分析,从量的角度把更好地把握市场的动向以及消费者口碑等信息。
附图说明
图1为本发明一种实施例的第一阶段流程图。
图2为本发明一种实施例的第二阶段架构图。
图3为本发明一种实施例的粉丝种类比例图。
图4为本发明一种实施例的粉丝年龄比例图。
具体实施方式
以下结合附图所示实施例对本发明作进一步的说明。
本发明属于互联网大数据领域,涉及非公开数据演算推测法,尤其是推测粉丝用户,以便更好的进行演算推测以补全预处理。
第一阶段以数据的抓取,ETL(Extraction-Transformation-Loading的缩写,中文名称为数据提取、转换和加载)预处理为主。
通过自建计算集群收集了主要的互联网用户数据,主要是微博,qq,微信数据,包括用户的个人基本信息和网络发言数据;以及主要的互联网商业数据,包括电商,行业论坛,门户网站的相关频道,主要是商品,商品销量,以及用户评价等。
某些用户未必原意公开自己的年龄数据。本发明需要对其进行演算推测,补全。
在互联网的海量数据中,普遍存在的一个问题就是数据缺失,不可能所有的数据都抓得到,有的人愿意公开,有的人不愿意公开,这就要求根据公开的信息去预测未公开的信息,如年龄预测,性别预测等等。在本发明所涉及到的数据领域,性别数据相对比较全,不需要做预测,但年龄信息则有很大的缺口。
某些用户未必愿意公开自己的年龄数据。本发明需要对其进行演算推测以补全。
一种非公开数据年龄演算推测法:
1数据背景
对现有蓝V的粉丝用户的年龄进行预测
基于2013年3月份的数据【粉丝表一千万(11595605),关系网数据46亿(4690796073)】
2主要思路
假设互粉好友(互相关注)的人中,数量最多的是同年龄段人(同事,同学,朋友)。
先求出互粉好友中的年龄最多的分布,作为预测年龄分布。
最后验证,和自己的年龄进行比对,算出准确率。
3基于原始得出一些数据分布图,判断可行性
请参阅图3-4:
a好友分布
约7440万人中(74400425的互粉用户)
好友数1~3的比例占35%
6人以上的占50%
b好友中没有年龄的比率
约1/4(24%)的用户中的好友全都没有年龄信息,剩下3/4或多或少有好友年龄
4计算具体方法
●首先,把年龄分为(70前,70后,80后,90后)四种
●然后吧关系网数据降维,减少数据量
●关系网数据46亿(4690796073)->只有粉丝的关系网13亿(1346976033)->双边(好友)关系一亿(103103273)
验证算下来:
准确率=预测正确年龄段人数/实际有年龄段的人数=1891469/2415840=0.78
第二阶段以数据的分析,挖掘为主。
数据分析:企业用户可以按时间纬度(日/月/年)自己的产品以及指定竞争对手(需要购买)在各个网络渠道的销售情况,以及这些产品的评论口碑,给企业用户多维查询。
数据挖掘:主要可以
1,基于CRM库的定向营销:本发明有微博,qq,微信等实体用户,并且已经为这些用户的贴上喜好标签。企业方可以对这些用户发送广告信息。
2,交叉销售(关联)
购买了某海尔空调的用户,也同时购买了其他产品(微波炉,热水器,洗衣机)。除了洗衣机是海尔的以外,其他都是别的商家。建议增加绑定,提高销量。
3,促销活动预测和结果分析
对促销前,对目标客户群锁定,计算促销方案,促销之后,评价(比如,那个电商促销效果好?)。
促销前,一般促销方案分为:满减,满赠,积分等。
比如,满300元送精美餐具一套,预估日均业绩100万,送多少比合适?
预测的参加率为30%,(100万*30%)/300元=1000笔(合适)
促销后,评测促销结果
a.促销活动的效益增加率
b.基于微博,评论数据,了解有多少人还记得这次促销活动,看法和态度如何,对品牌的忠诚度的上升或下跌。
4,时间序列预测。基于全网的用户发言倾向,产品数据,对企业方的产品销量,市场饱和度,市场走势发展做出预测。比如检测到某个时间段,笔记本电脑热卖;而且季节也临近夏季,那么笔记本用户对电脑散热的需求也随之而来。
第三阶段 以数据的展现,可视化,数据结果集的操作利用为主。
除了常规的表示数据走势的曲线图,数据份额的饼状图以外。
该系统可以为企业方提供向特定用户群发联络信的功能(邮件,微博id)。
本发明针对的是互联网上海量用户的发言,因此主要采用的技术是中文的文本挖掘。中文的文本分析首先用到的是中文分词,这是有别于英文的中文特有的自然语言处理技术。
本发明采用的是IKAnalyzer中文分词系统,这是一个开源的分词系统,已经非常成熟。在这个工具的基础上,创建了多达250个分类词库
在经过“分词”这一基本的文字处理后,本发明希望从海量的用户发言中挖掘出用户的兴趣爱好,从而给每个用户打上标签,这方面本发明采用的是LDA(Latent Dirichlet Allocation)算法。这是一个概率模型,用于从文本中挖掘出用户所谈论的主题,本发明将其应用在中文系统,并实现了分布式环境下的海量数据的快速挖掘。
(来源:Blei,D.M.,Ng,A.Y.,Jordan,M.I.:Latent Dirichlet Allocation.Journal of Machine Learning Research 3(2003)993-1022)
在互联网的海量数据中,普遍存在的一个问题就是数据缺失,不可能所有的数据都抓得到,有的人愿意公开,有的人不愿意公开,这就要求本发明根据公开的信息去预测未公开的信息,如年龄预测,性别预测等等。在本发明所涉及到的数据领域,性别数据相对比较全,不需要做预测,但年龄信息则有很大的缺口。因此本发明采用 Bayes算法(朴素贝叶斯算法)来进行年龄预测。这是一个非常常用的文本分类算法,也适合在分布式环境里对海量数据进行分类,效果不错。
(参考文献:1.Zhang,Harry.″The Optimality of Naive Bayes″.FLAIRS2004conference.
2.Caruana,R.;Niculescu-Mizil,A.(2006).″An empirical comparison of supervised learning algorithms″.Proceedings of the 23rd international conference on Machine learning.CiteSeerX:10.1.1.122.5901.)
在互联网的海量数据中,除了用户的发言数据外,用户与用户的关系数据也是非常有价值的。用户间的关系组成了一张庞大的关系网,而本发明要做的,是从中找出最核心的用户,即整个关系网中最有影响力的用户。针对这个问题,本发明采用了PageRank算法。这是Google排名运算法则(排名公式)的一部分,是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。本发明将其应用在人与人之间的网络关系上,用来判断一个人的影响力,这是一个创举。通过分布式环境,本发明能够计算几亿人之间的关系,得到几亿人的影响力。
(来源:1.″Google Press Center:Fun Facts″.www.google.com.Archived from the original on 2009-04-24.
2.Brin,S.;Page,L.(1998).″The anatomy of a large-scale hypertextual Web search engi ne″.Computer Networks and ISDN Systems 30:107-117.)
微博作为Web 2.0时代的新生网络应用形式,在最近几年中取得了迅猛的发展,其中犹以新浪微博最具有代表性。2012年,新浪微博的用户数已经超过了5亿。这么多的用户,每天都产生海量的信息,这些信息给本发明什么样的启示,给企业策略带来什么样的引导,这都是需要进行深入分析的。要完成这一任务,需要做两件事情:1)海量信息的获取;2)海量信息的分析与挖掘
新浪微博虽然是个开放平台,并且有开发的API可供使用,但是在使用上存在着较多的限制,使用API能抓取的信息量,基本只适合用于研究。本发明针对这一问题,部署了一个爬虫集群,可以以非常高的效率,抓取到新浪微博上的用户基本信息,用户发言信息,甚至评论,转发,等等。
抓取到的信息,保存在HADOOP的HIVE数据库,通过分布式系统的强大数据处理能力,本发明对这些信息进行统计分析与挖掘,从中整理出企业感兴趣的,针对企业官方微博(蓝V)的粉丝的分析结果,供企业决策参考。
本发明针对3个层面进行分析:
(1)粉丝比对分析:主要是针对粉丝共有信息的一些比对分析,如“基本信息”(年龄,性别等),“属性”,“发贴习惯”,“粉丝重合”情况,等等
(2)微博比对分析:针对蓝V之间所发微博的差异度分析
(3)个性比对分析:不同蓝V的粉丝群特有属性的统计分析,如:“常用发帖平台”,“粉丝兴趣爱好”,“粉丝关注的关键字”,“粉丝电商偏好”等等。
在以上分析的基础上,本发明给企业官V总结了5个指数:
粉丝质量指数,影响力指数,勤奋指数,网络购买指数,被攻击指数并将其综合定义成为一个飞迪尔(FIDEA)指数。
通过飞迪尔(FIDEA)指数以及5个细化指数,就可以了解到企业官V在微博运营方面哪里做得领先于竞争对手,哪里还有待加强。
操作步骤:
(1)通过爬虫软件抓取互联网上开发平台的公开信息,如微博数据等;海量的数据需要一个爬虫集群
(2)抓取到的数据汇总到数据库中,由于数据量巨大,本发明需要一个HADOOP分布式环境,将数据保存在HIVE数据库中
(3)对抓取来的数据进行整理,建模
a)最基础的是分词,这是必须的第一步
b)然后将分词结果应用在不同的模型中,如LDA模型, Bayes模型,对用户进行打标签,以及分类
c)根据网络关系,迭代计算1亿6千万人的影响力
d)根据分词结果,基于TF-IDF算法,统计不同用户群的关键字排名
(4)将统计分析的数据生成到MYSQL数据库,确保MYSQL数据库可以支持多达几十个条件的组合查询,用户规模在2000万,查询效率在5秒左右。
(5)更新数据,开放给用户使用
e)根据人口和地理信息进行分类统计
(6)后续的问题
数据范围(边缘)的精细化
i是中心点的标号,j是比较点的标号。dij就是i到j的距离。k是从1到n
eg:我发现实际有个1980年出生人,好友,同学,同事有79年比较多,预测的话就算到70后了
可以用聚类先分出实际范围,做最大化距离划分,以此提高精度。
上述的对实施例的描述是为便于该技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对这些实施例作出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于这里的实施例,本领域技术人员根据本发明的揭示,不脱离本发明的范畴所做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!