一种面向大数据的跨语言检索方法与流程
本发明属于跨语言检索技术领域,尤其涉及一种面向大数据的跨语言检索方法。
背景技术:
随着信息化技术的不断发展和世界各国文化交流的加深,互联网已经逐步成为一个全球性的多语言信息共享仓库。如何从海量的信息库中快速准确的获取用户满意的跨语言信息,是多语言信息时代一个亟待解决的问题。
跨语言信息检索即是一个获取多语言信息的重要手段,跨语言信息检索(cross-languageinformationretrieval,clir)是指以某语言为载体构建的查询,检索其他一种或多种语言表示的信息的信息检索技术或方法。clir作为信息检索(informationretrieval,ir)领域的一个分支,在语言层面上有其自身的复杂度,除了要处理ir所面临的问题,clir还要处理查询和文档集语种不一致的问题。在clir中,用户输入的查询语言称为源语言(sourcelanguage),系统返回的文档所使用的语言称为目标语言(targetlanguage),clir的主要问题就是要在源语言和目标语言之间做一个映射。很自然的想法是对查询或文档做翻译,然后把clir的问题统一到单语ir的问题上。维基百科(wikipedia)作为当下最权威的多语言网络百科全书之一,包含460万篇文章,涵盖了社会、艺术、历史、科学技术等诸多领域的数字信息,是一个潜力巨大的信息仓库。由于维基百科的多语言特性,可以把它当作一本多语网络词典运用于clir技术研究中。跨语言信息检索面临的主要问题是查询所使用的语言和文档使用的语言不一致,导致无法采用传统的信息检索技术,但又希望用户在不改变查询输入的情况下,依然可以检索到和查询相关的其他语言的文档结果。
综上所述,现有跨语言信息检索方法面临存在查询所使用的语言和文档使用的语言不一致的问题。
技术实现要素:
本发明的目的在于提供一种面向大数据的跨语言检索方法,旨在解决跨语言信息检索面临存在查询所使用的语言和文档使用的语言不一致的问题。
本发明是这样实现的,一种跨语言检索模型,所述跨语言检索模型以源语言查询向量为输入,输出和查询向量语义相近的目标语言文档的相似度;查询翻译过程中,采用典型关联分析的结果,利用下式计算查询和目标文档的相似度,其中,f(x)是单语词向量模型函数:
进一步,所述构建方法包括:
根据维基百科中英文可比语料库,分别构建中文和英文词条的字典树;英文字典树采用trie树数据结构,词条是转换成小写后的英文词;对于中文字典树采用改进的trie树结构,由trie树和哈希函数组成;
对于查询词,根据语种在不同的字典树中查找,如果能找到,返回对应的词条编号;
根据词条编号和中英文词条的跨语言链接关系,返回该编号对应的目标语言词条;
如果字典树没有找到对应的词条,则根据语种的不同,利用前面训练单语词向量模型将查询表示成查询向量
输出目标语言查询词或查询词向量。
进一步,所述面向大数据的跨语言检索方法采用中英维基百科词条及词条间的跨语言关系,构建双语词向量模型,再利用这个双语词向量模型对查询做翻译,最后根据候选译文构建新的查询执行检索。
进一步,从维基百科网站上收集同时具有中英文版本的词条,抽取词条的标题、正文和跨语言链接,并对文本内容做预处理,包括去停用词、分词、词根化;最后生成xml文件;将维基百科的词条标题称为主题,正文中出现的非主题词称为普通词;
语料库的构建采取如下流程:
用网页url作为词条的统一标识,抽取词条的标题、正文和跨语言链接;
解析网页正文,对非主题词做停用词、分词处理,主题词保留原格式及重定向链接;
建立跨语言链接表,标示表示同一主题的中英文词条url。
进一步,所述双语词向量模型的构建方法包括:
根据语料库,分别训练中英文主题词的词向量模型,拟采取dbn算法;
训练普通词的词向量模型,拟采取共现主题词向量叠加模型;
拟采用线性回归模型训练双语词向量模型间的语言连接。
本发明的另一目的在于提供一种利用跨语言检索模型的双语互相翻译目标方法,包括:
x是源语言文档向量,对x的每一维,x是由每个维度的线性组合而成,表示为下式:
x=α1x1+α2x2+…+αnxn
y是目标语言文档向量,同样将y表示为下的形式:
y=β1y1+β2y2+…+βmym
利用皮尔森相关系数,度量x和y的关系;最大化ρx,y就是要求解最优参数a=(α1,α2,...,αn)和b=(β1,β2,...,βm),使得x和y有最大可能的关联度;
模型的优化目标变为下式,其中∑ij是x和y的协方差矩阵:
maximizeαt∑12β
约束:αt∑11α=1,βt∑22β=1
通过拉格朗日的对偶性,将公式maximizeαt∑12β的有约束问题,转换为无约束问题,问题maximizeαt∑12β转化为最大化λ;
根据求解的最大的λ,求出当λ取最大时的α和β,α和β称之为典型变量,λ是变量a和b之间的相关系数.
本发明提供的面向大数据的跨语言检索方法,从查询自动翻译的角度出发,利用不同语种之间文档的语义相似性特点,找到两种语言的共享语义空间,在此共享空间上对查询做语义转述,从而实现查询的自动翻译功能。维基百科词条独具语言多样性的特点,因此本发明以维基百科的中英文词条为数据基础,构建语义相似的中英文可比语料。基于中英可比语料,利用深度学习方法,训练双语词向量模型对查询进行语义翻译。同时由于维基百科词条本身的规范性,可以直接用于基于词典的查询翻译。本发明结合以上两种查询翻译策略,实现了一个中英跨语言检索模型。
附图说明
图1是本发明实施例提供的面向大数据的跨语言检索方法流程图。
图2是本发明实施例提供的系统整体框架设计图。
图3是本发明实施例提供的系统实现流程图。
图4是本发明实施例提供的rbm结构图。
图5是本发明实施例提供的dbn结构图。
图6是本发明实施例提供的自动编码器结构图。
图7是本发明实施例提供的dbn网络层次结构图。
图8是本发明实施例提供的查询翻译模块流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
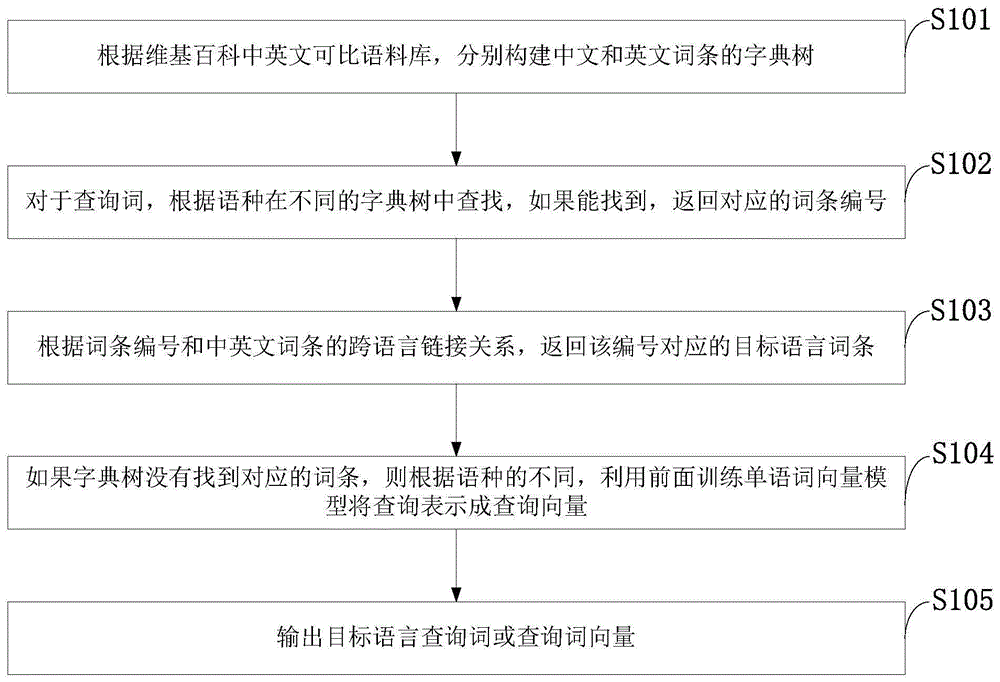
如图1所示,本发明实施例的面向大数据的跨语言检索方法包括以下步骤:
s101:根据维基百科中英文可比语料库,分别构建中文和英文词条的字典树;
s102:对于查询词,根据语种在不同的字典树中查找,如果能找到,返回对应的词条编号;
s103:根据词条编号和中英文词条的跨语言链接关系,返回该编号对应的目标语言词条;
s104:如果字典树没有找到对应的词条,则根据语种的不同,利用前面训练单语词向量模型将查询表示成查询向量;
s105:输出目标语言查询词或查询词向量。
下面结合具体实施例对本发明的应用原理作进一步的描述。
本发明实施例拟采用中英维基百科词条及词条间的跨语言关系,构建双语词向量模型,再利用这个双语词向量模型对查询做翻译,最后根据候选译文构建新的查询执行检索。系统的整体框架设计如图2。
根据上面的分析,本发明实施例的跨语言检索系统技术研究主要包括中英可比语料、双语词向量模型、基于双语词向量的查询翻译三个子模块。具体拟定的实现细节流程图如图3所示。
1、中英可比语料的构建:
从维基百科网站上收集同时具有中英文版本的词条,抽取词条的标题、正文和跨语言链接,并对文本内容做预处理,包括去停用词、分词、词根化等。最后生成xml文件。为了便于描述,本发明将维基百科的词条标题称为主题,正文中出现的非主题词称为普通词。语料库的构建采取如下流程:
用网页url作为词条的统一标识,抽取词条的标题、正文和跨语言链接;
解析网页正文,对非主题词做停用词、分词处理,主题词保留原格式及重定向链接;
建立跨语言链接表,标示表示同一主题的中英文词条url。
2、双语词向量模型的构建方法
借鉴jungikim等人基于dbn单语词向量模型的训练方法,本发明拟采取同样的深度学习方法根据词条的正文描述训练词向量。不同的是,本发明在对主题词做完词向量模型训练后,反过来对正文的普通词根据主题模型提取特征。双语词向量模型的构建拟采取如下流程:
根据语料库,分别训练中英文主题词的词向量模型,拟采取dbn算法;
训练普通词的词向量模型,拟采取共现主题词向量叠加模型;
拟采用线性回归模型训练双语词向量模型间的语言连接;
单语词向量模型其实是一个文档模型,其目标是构建一个文档的词向量。本发明采用dbn网络训练文档向量,dbn由栈式rbm构建而成,每一个rbm以贪婪式算法单独训练,最后再整体微调模型参数。rbm可以看作是一个由可见节点和隐藏节点组成的带权值的二分图,可见节点和隐藏节点之间有带权值的边连接,可见节点或隐藏节点内部无连接,边权值即是模型参数,训练过程中,根据输入数据,不断迭代更新参数。rbm的结构图如图4所示。
rbm可由能量模型(energy-basedmodel)描述,能量模型由能量函数定义,形式如公式(5-1),其中z=∑u,ge-e(u,g)是规范化因子。e(v,h)定义为能量函数,形式如公式(5-2)所示,其中wij是模型参数,ci和bj分别是可见节点vi和隐藏节点hj的偏置项,α是惩罚因子常量。由rbm的模型结构可知,在给定可见节点的条件下,隐藏节点的条件概率p(hj=1|v)可由公式(5-3)求得,同理,p(vi=1|h)可由公式(5-4)求得,其中σ=1/(1+e-x),是sigmoid函数。
e(v,h)=-∑i,jvihjwij-∑icivi-α∑jbjhj(5-2)
p(hj=1|v)=σ(bj+∑iviwij)(5-3)
p(vi=1|h)=σ(ci+∑jhjwij)(5-4)
一个由输入层和l个隐藏层组成的dbn,可以描述为由l个rbm组成的rbm栈,形式化表示如公式(5-5)所示,其中x=h0表示输入,p(hk|hk+1)是rbm中在给定可见节点的情况下,求隐藏节点的条件概率,参见公式(5-3)。dbn的结构图如图所示,每两层看作一个rbm,每个rbm单独训练,第k-1个rbm的输出是第k个rbm的输入。本发明在实现时把整个dbn看作一个大的自动编码器,采用后向算法微调参数。
dbn的训练过程分为两步,第一步预训练(pre-training),训练每个rbm,hinton在他的文章中提出相对散度(contrastivedivergence,cd)算法,是一种近对数似然算法,可以快速的求解rbm,第二步微调(fine-tune),利用自动编码器调节模型参数。
下面详细介绍本发明实施例中这两个训练过程和核心算法。
算法1
1)预训练
对比散度是一种无监督逐层训练算法,通过逐层训练降低学习复杂度。首先把输入数据x和第一个隐藏层当作一个rbm,训练这个rbm的参数w1。然后固定这一层的参数,把h1看作可见层,h2看作隐藏层,训练第二个rbm的参数w2。后面按照这个过程,逐层迭代。rbm的训练算法如所示。
dbn在训练过程中,需要使用吉布斯抽样(gibbssample)方法,首先将可见节点映射到隐藏节点,由隐藏节点重建可见节点,再由可见节点重建隐藏节点,反复执行以上步骤,就是吉布斯抽样的过程。dbn运用cd算法逐层训练,得到每一层参数,用于初始化dbn,整个dbn的训练过程可以分解为多个rbm的训练,具体的训练算法如
算法2所示。
算法2
算法2是完整的dbn预训练过程,在得到预训练模型之后,需要根据具体任务目标,微调模型参数。由于本发明最终的dbn模型为文档向量模型,需要对文档建模,希望能对文档向量作特征抽取,因此,本发明在参数微调部分采用了自动编码器。
2)微调
本发明实施例所采用的自动编码器是栈式自动编码器,它是由多层稀疏自动编码器组成的一个网络结构,网络前一层的输出作为后一层的输入,逐层训练,这和本发明前部分dbn的训练过程非常相似。自动编码器是一种无监督学习算法,利用反向传播算法,其目标是使模型的输入尽可能的等于模型的输出,从而达到对输入重新编码的目的。在调整模型的输入节点个数和输出节点个数之后,自动编码器能够学习到对输入数据的压缩表示,也可以理解为降维,这是一种对输入数据更精确的表示方法。自动编码器的网络结构如图6所示。
从图可以看出,自动编码器的目标就是要学习公式(5.6),其中f(x)可以看作一个非线性函数,可以利用交叉熵作为目标函数进行学习。
fw,b(x)≈x(5.6)
本发明实施例主要把dbn的微调过程看作栈式自动编码的后向传播过程,因此重点主要在介绍栈式自动编码器的后向传播算法。自动编码后向算法的核心是计算每一层的损失梯度,并且不断向前传递损失梯度值,从而更新模型参数。算法流程参见算法3。
算法3
本发明实施例在实现时,采用的网络层次结构如图7所示,下面五层是dbn网络,上面四层和dbn网络共同构成一个自动编码器,用于调节模型参数。图7中深色那层是模型的输出层,通过这个网络结构,生成一个维度为200的文档向量,这就是单语词向量模型的目的。
以上是本发明实施例单语词向量模型的训练算法原理和流程。
双语词向量模型是在单语词向量的基础之上,通过分析双语词向量之间的关系,得到从源语言到目标语言的映射关系。由于通过单语词向量模型可以得到文档向量,如果能在文档向量之间找到双语的映射关系,就实现了双语互相翻译的目标。
本发明实施例在跨语言检索模型的问题上,以典型关联分析为主,训练了双语词向量的映射模型,并在此基础上,实现了从源语言到目标语言的翻译过程。下面将详细介绍典型关联分析算法原理和跨语言检索模型算法。
3)典型关联分析算法原理
为了分析n维特征向量x和输出结果y之间的关系,其中x,y∈rn,可以采用多元回归分析,在输入和输出之间拟合一个函数。但是,多元回归分析的局限在于它只能分析y中的每个特征和x的所有特征的关系,而无法分析y的特征之间的关系。在本发明中,假设x是源语言文档向量,对x的每一维,可以认为x是由每个维度的线性组合而成,表示为公式(5.7);y是目标语言文档向量,同样可以将y表示为公式(5.8)的形式。利用皮尔森相关系数,度量x和y的关系,如公式(4.1)所示。最大化ρx,y就是要求解最优参数a=(α1,α2,...,αn)和b=(β1,β2,...,βm),使得x和y有最大可能的关联度。
x=α1x1+α2x2+…+αnxn(5.7)
y=β1y1+β2y2+…+βmym(5.8)
由公式(4.5),模型的优化目标变为公式(5.9),其中∑ij是x和y的协方差矩阵。
maximizeαt∑12β(5.9)
约束:αt∑11α=1,βt∑22β=1
通过拉格朗日的对偶性,将公式(5.9)的有约束问题,转换为无约束问题,得到公式(5.10)。分别对α和β求一阶导,并令导数等于0,得到公式(5.11)和公式(5.12)。由公式(5.11)和公式(5.12)求解,得到公式(5.13)。这样,问题(5.9)转化为最大化λ。
λ=θ=αt∑12β(5.13)
b-1aw=λw(5.16)
对公式(5.11)和(5.12)进一步化简,得到公式(5.14)和公式(5.15),其中
最后,根据求解的最大的λ,求出当λ取最大时的α和β,α和β称之为典型变量,λ是变量a和b之间的相关系数,即是本发明中所提到的共享语义空间。
4)跨语言检索模型
跨语言检索模型以源语言查询向量为输入,输出和查询向量语义相近的目标语言文档的相似度。查询翻译过程中,采用典型关联分析的结果,利用公式(5.17)计算查询和目标文档的相似度,其中,f(x)是单语词向量模型函数。
跨语言检索模型的算法描述如算法4所示。
算法4
基于双语词向量模型的翻译模型的构建方法
主要包含以下几个流程:
根据维基百科中英文可比语料库,分别构建中文和英文词条的字典树。英文字典树采用trie树数据结构,词条是转换成小写后的英文词;
对于查询词,根据语种在不同的字典树中查找,如果能找到,返回对应的词条编号;
根据词条编号和中英文词条的跨语言链接关系,返回该编号对应的目标语言词条;
如果字典树没有找到对应的词条,则根据语种的不同,利用前面训练单语词向量模型将查询表示成查询向量
输出目标语言查询词或查询词向量。
查询翻译模块的流程图如图8所示。
本发明提供的面向大数据的跨语言检索方法,从查询自动翻译的角度出发,利用不同语种之间文档的语义相似性特点,找到两种语言的共享语义空间,在此共享空间上对查询做语义转述,从而实现查询的自动翻译功能。维基百科词条独具语言多样性的特点,因此本发明以维基百科的中英文词条为数据基础,构建语义相似的中英文可比语料。基于中英可比语料,利用深度学习方法,训练双语词向量模型对查询进行语义翻译。同时由于维基百科词条本身的规范性,可以直接用于基于词典的查询翻译。本发明结合以上两种查询翻译策略,实现了一个中英跨语言检索模型。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!