一种基于专利群的信息处理装置及方法与流程
本发明涉及一种基于专利群的信息处理装置及方法,尤其涉及一种对技术信息,例如专利信息进行处理,从而对技术信息进行评分,并筛选出重要度高的信息的方法和装置。
背景技术:
:技术信息,尤其是专利信息对于企业或科研院所的发展是不可或缺的重要资源。例如在企业或科研院所进行研发或投资前,可以全面了解特定
技术领域:
的现有技术水平,确定正确的研究方向,避免重复开发,节省时间和科研经费。但是由于全世界的申请人每年在各
技术领域:
向不同国家申请了大量不同质量和价值的专利,这些专利中的一些专利对该领域技术做出了巨大的贡献,而另一些专利仅对公知技术进行了微小改进。因此,企业通常需要分析这些庞大的专利信息,以获得有价值的内容。此外,在企业内部进行技术信息,尤其是专利信息的管理时,通常是将所有的专利集中在一起进行管理,但随着时间的推移和技术的发展,有些申请变为无价值的专利,因此,为了确保维持有价值的专利,同时摒弃无价值的专利,企业通常需要对专利价值进行评估。传统上是以人工方式进行上述专利价值评估的,因此需要消耗大量的人力及时间成本。由此可知,需要构建一种信息处理装置及方法,以自动对相关领域的专利进行评分,从而筛选出有价值的专利信息,并对无价值的专利信息加以摒弃。在专利文献1(公开号:US2011/0289096A1)中,公开了一种对专利和其他无形资产进行评价的方法和系统,比较第一组已知的具有较高价值的专利(例如诉讼成功的专利)与第二组已知的具有较低价值的专利(例如诉讼不成功或不具有诉讼历史的专利),来获得第一组和第二组专利的多个特征值,其中,第一组专利的上述特征值要大大高于第二组专利的上述特征值,上述特征值可以是专利的维护周期、被引证次数等。使用上述分析出的多个特征值,来建立数学模型或数学算法,以评价未知的一个或一组专利,从而获知待评专利是否具有较高价值。但是,由于专利的保护范围更多地体现为权利要求的保护范围,因此,权利要求对于表征专利的法律价值和技术价值具有重要意义,但在上述专利文献1中,用来评价专利价值的仅仅是如专利的维护周期,被引证次数等特征值,虽然这些特征值可以在一定程度上表征某些专利的法律价值和技术价值,但其只是一些辅助数据,不能通过语义信息,尤其是权利要求的语义信息来对专利的价值进行评价。此外,由于即便是同一辅助数据,其在不同领域的具体指标值也会存在较大差异,例如典型地在电子计算机领域和医药领域,专利维护周期、被引证次数等辅助指标的值之间即存在明显不同,因此,用相同标准在不同领域中评判专利价值也是不科学的。在专利文献2(CN1573738A)中,公开了一种自动分析专利文件中专利范围的方法,其用以分析一专利文件中有关申请专利范围的权利范围,包括下列步骤:输入上述专利文件,上述专利文件包含至少一申请专利范围;以及撷取上述至少一申请专利范围中,逗点/分号与逗点/分号间的文字,逗点/分号与句号间的文字以及逗点/分号与连接词间的文字,形成多个字组;参考一关键词库,比对上述字组以得到至少一组成组件;根据上述至少一组成组件,以评估上述至少一申请专利范围的权利范围。虽然在上述专利文献2中是以语义信息为基础来分析权利要求的范围的,但是对于一个项目或系统而言,企业或科研院所会形成一组专利,该一组专利也可以称作为专利群或专利包,由于专利包中不仅包含了核心专利,还包含了围绕上述核心专利的多个外围专利,是核心构思与具体实现方法的有机结合,所以专利包的专利相对于同等水平的单个专利而言,应具有更高的价值,同时,企业在判断是否要摒弃某个专利时,还需考虑该专利在专利包中的作用,因此,需要结合专利在专利包中的作用来分析该单个专利的价值。技术实现要素:本发明要解决的技术问题是提供一种基于专利群的信息处理装置及方法,尤其是提供一种专利信息处理装置和方法,能够通过语义信息,结合专利群分析结果,对专利进行信息处理,从而对专利信息进行评分,并筛选出重要度高的信息。为解决上述技术问题,本发明的基于专利群的信息处理装置,包括:接收单元,接收用户输入的信息;比较文件生成单元,根据用户输入的信息,生成检索式来检索与该用户输入的信息对应的领域范围,并存储检索获得的文件;分析单元,语义分析检索获得的每个文件,得到每个文件的关键词列表;参考关键词列表存储单元,存储参考关键词列表,其中该参考关键词列表对应于上述领域范围;以及评价单元,对比较文件生成单元检索获得的文件进行文件群分析,得到文件群聚类结果,之后,根据文件群聚类结果、分析单元获得的每个文件的关键词列表与参考关键词列表,得到评分值。本发明的基于专利群的信息处理方法,包括如下步骤:接收步骤,接收用户输入的信息;比较文件生成步骤,根据用户输入的信息,生成检索式来检索与该用户输入的信息对应的领域范围,并存储检索获得的文件;分析步骤,语义分析检索获得的每个文件,得到每个文件的关键词列表;参考关键词列表存储步骤,存储参考关键词列表,其中该参考关键词列表对应于上述领域范围;以及评价步骤,对比较文件生成步骤检索获得的文件进行文件群分析,得到文件群聚类结果,之后,根据文件群聚类结果、分析单元获得的每个文件的关键词列表与参考关键词列表,得到评分值。依照本发明,由于其根据用户输入的信息,生成检索式来检索与该用户输入的信息对应的领域范围,由此可知本发明是在与用户输入的信息对应的领域中来进行评价的,上述方式保证了评价基准的相对统一。通常当文件中除该基础术语之外,未包含进一步限定某些术语的细化特征关键词,则说明该文件涉及的范围较大,而若文件中包含了很多更为细化的特征关键词,则说明文件涉及的范围较小,因此,根据这种特征关键词之间的比较,可以确定哪些权利要求具有更宽的保护范围,而哪些权利要求的保护范围更窄。同时,专利群与单一专利相比,可以更全方位地保护核心思想,从权利的对比关系来看,相比于单一专利,由于专利群不仅从核心思想,而且从该核心思想的实现方法等方面来保护一个主题,因此,专利群的权利范围也更为稳定,所以,本发明中,通过对属于特定类型人员的文件群进行分析,其中,该文件群可以是专利群,同时将文件的关键词列表与参考关键词列表相比较,从而可以基于文件群、表征权利要求的特征关键词的数量多少来对不同的文件赋予不同的评分值。可选的,上述文件群分析和关键词比较之间的关系可以是先进行关键词比较,再用文件群聚类结果去调整其关键词比较结果,从而输出评分值;或者将文件群聚类结果和关键词比较同时输入到某一模块,例如是比较模块,从而输出最终的评分值;或者先进行文件群的分析,建立文件群之间的网络关系,并获得该文件群中的最基础的文件,之后将该最基础的文件与参考关键词列表相比较,获得该最基础的文件的评分值,之后根据文件群中的专利与最基础文件的关系,来获得文件群中的不同文件的评分值。可选的,本发明进一步具有排序装置,将评价单元输出的评分结果进行排序,并当用户输入特定专利号时,高亮显示该特定专利的评分值,并且,本发明还可进一步具有报告生成单元,根据排序装置的排序结果来生成报告,由此,可以更直观地看到评分结果,获知文件价值的高低,并得到更易于进行人机交互的报告。可选的,对于专利文件来说,由于权利要求中包含了法律信息,直接表征该文件的保护范围,而如果分析整个说明书信息,可能会带来更多的噪声,因此,在语义分析检索获得的每个文件时,可以仅对每个文件的权利要求进行分析,从而获得每个文件的关键词列表;可选的,还可仅对每个文件的独立权利要求进行分析,从而获得其关键词列表。可选的,该参考关键词列表是通过整合分析单元所获得的每个文件的关键词列表,并进行同义词合并后自动形成的关键词列表。即,上述参考关键词列表可以通过自动分析来获得。由此,不需要事先通过人工方式建立每个
技术领域:
的参考关键词,而可通过大数据的方式语义分析某一
技术领域:
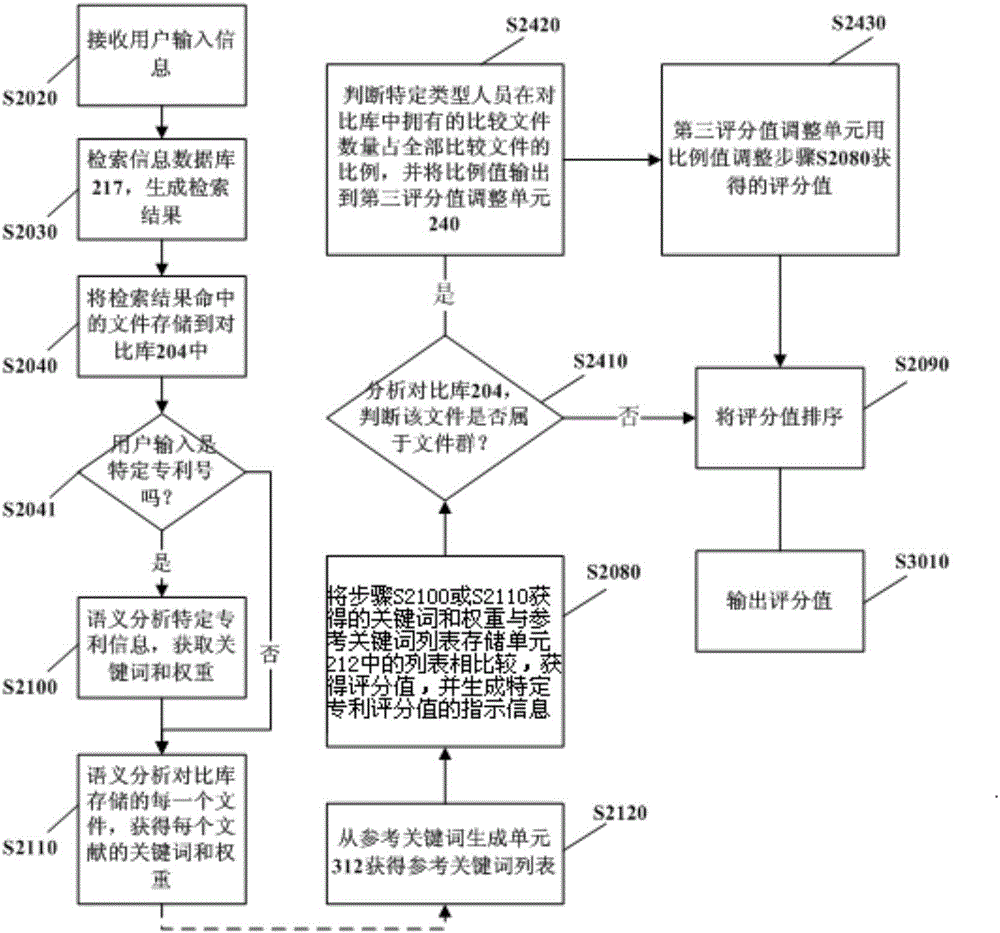
的全部技术文献,来获得参考关键词列表,不仅可节约人力,而且通过大数据分析可以更客观地获得该领域的关键词表征。可选的,由于对于同样的技术文件而言,发表时间越早,意味着该技术文件更有价值,因此,该信息处理装置还可包括日期分析单元,获得比较文件生成单元检索获得的每个文件的日期;评分值调整单元,根据日期分析单元分析得到的日期,来调整比较单元输出的评分值。可选的,可以根据上述信息处理装置输出的值来进行后续处理,比如可通过参考上述值来进行专利投资等专利运营,或者在企业内部可以根据上述值来评价可以停止哪些专利的维持费用,由此,可以节约大量人力成本。附图说明下面结合附图对本发明的具体实施方式作进一步详细的说明,其中:图1示意性示出了依照本发明的信息处理系统的第一实施例;图2示意性示出了依照本发明的信息处理系统所实施的处理流程的一实施例;图3示意性示出了依照本发明的数据生成单元的一实施例;图4示意性示出了本发明的数据生成单元所实施的处理流程的一实施例;图5示意性示出了依照本发明的数据生成单元的另一实施例;图6示意性示出了本发明的数据生成单元所实施的处理流程的另一实施例;图7示意性示出了依照本发明的分析单元的一实施例;图8示意性示出了本发明的分析单元所实施的处理流程的一例;图9示意性示出了依照本发明的比较单元的一实施例;图10示意性示出了本发明的比较单元所实施的处理流程的一例;图11示意性示出了依照本发明的比较单元的另一实施例;图12示意性示出了依照本发明的信息处理系统的第二实施例;图13示意性示出了依照本发明的信息处理系统的第三实施例;图14示意性示出了文件群的拓扑网络图;图15示意性示出了依照本发明的信息处理系统的第四实施例;图16示意性示出了依照本发明的信息处理系统的第五实施例;图17示意性示出了依照本发明的信息处理系统的第六实施例;图18示意性示出了依照本发明的信息处理系统的第七实施例。具体实施方式结合附图来说明本发明的实施例。需要说明的是,每个附图中的实线表示信号的经过线路,而虚线表示该模块或步骤在整个装置或流程中是可省略的,而点划线表示上述多个模块可进行组合或不进行组合,而独立成为模块。第一实施例图1示出了本发明的信息处理系统的一个实施例。图2示出了依照本发明的信息处理系统所实施的处理流程的一实施例。下面,结合图1和图2来进行相应说明。如图1所示,该信息处理系统包括输入装置101、信息处理装置201和显示装置301。在步骤S2020中,上述输入装置101接收用户输入的信息,该输入信息例如是某个特定专利号或用户关注的相应技术的简单描述。上述信息处理装置包括接收单元202,用于接收用户输入的信息;在步骤S2030中,比较文件生成单元230中的数据生成单元203根据用户输入的信息,生成相应的检索式,并用所生成的检索式在信息数据库217中进行检索而得到包含一组技术文件信息的检索结果,该组技术文件信息的
技术领域:
与某个特定专利号或用户关注的相应技术的
技术领域:
相同,其中,该信息数据库217中预先存储了一批技术文件信息,该技术文件信息包括但不限于各国专利公报、专利公告、实用新型公报、特定标准、核心期刊文件等。之后,在步骤S2040中,数据生成单元203将上述检索结果存储到比较文件生成单元230的对比库204中。当用户向输入装置101输入的是某个特定专利号时(步骤S2041中“是”),该系统还包括第一分析单元210,对所输入的特定专利进行语义分析,并进行词频分析、相关度分析、冗余信息去除等或上述方式的组合,从而获得与该特定专利号对应的关键词及该关键词的权重。接着,在步骤S2110中,将对比库204中存储的所有比较文件中的每一个依次输入到第二分析单元211,之后对对比库204中存储的每一个文件进行语义分析,并进行词频分析、相关度分析、冗余信息去除等或上述方式的组合,从而获得与该文件对应的关键词及其权重,并依次将每个文件所对应的关键词及其权重输入到比较单元208。在步骤S2120中,从参考关键词列表存储单元212获得参考关键词列表,其中,上述参考关键词列表存储单元212用于生成参考关键词列表,该参考关键词列表可以是预先存储在该信息处理装置201中的,这些预先存储的参考关键词是由相应领域的专家根据经验给出的,并在列表中按领域范围进行分类,也可以通过分析对比库204中的技术文件信息来自动获得。即,当通过自动分析获得时,该参考关键词列表存储单元212可包括第三分析单元214和存储器215,其中第三分析单元214通过整合第二分析单元211中获得的关键词及其权重,并通过对其进行同义词整理和归纳,来形成参考关键词列表,该列表包括了相应的参考关键词及其对应权重。或者第三分析单元214也可直接读取对比库204中存储的比较文件,并通过与第一分析单元210或第二分析单元211同样的方式进行分析,之后再对所获得关键词进行同义词归纳和整理,来形成参考关键词列表。第三分析单元214将所获得的上述参考关键词列表及其权重存储到存储器215中。当然,在通过自动分析获得参考关键词列表时,也可省略该存储器215,而使该参考关键词列表存储单元212仅包括第三分析单元214。在步骤S2080中,当用户向输入装置101输入的是某个特定专利号时,比较单元208将由第一分析单元210得到的关键词及其权重与参考关键词列表存储单元212中的参考关键词及其权重进行对比,而获得用户所输入的上述特定专利的评分值,同时生成指示信息,该指示信息用于标志该评分值是上述用户输入的特定专利的评分值。同时,将第二分析单元211所获得的每个文件的关键词及其权重与参考关键词列表存储单元212中的参考关键词及其权重进行对比,而分别得到上述对比库204中存储的每个文件的评分值。该信息处理装置201还包括文件群分析单元241,在步骤S2410中分析对比库204中存储的比较文件的特定类型人员信息(例如申请人信息、发明人信息或作者信息),并判断该文件是否属于文件群,当分析结果是:与该比较单元208输出的评价值对应的文件不属于文件群时,即步骤S2410中的判断为否时,不对评分值进行调整,而直接在步骤S3010中输出评分值,并当用户向输入装置101输入的是特定专利号时,高亮显示其评分值。上述中,该文件群可以是专利群。当步骤S2410的判断结果为是,即,在判断为与该比较单元208输出的评价值对应的文件属于文件群时,在步骤S2420中,判断特定类型人员在对比库中拥有的比较文件数量占所有比较文件的比例,并将该比例值输出到第三评分值调整单元240。在步骤S2430中,该第三评分值调整单元240根据文件群分析单元输出的比例值,对步骤S2080中由比较单元208输出的评分值进行调整。该特定类型人员可以是特定的申请人、发明人或特定的作者等。其中,在由文件群分析单元241进行特定类型人员分析时,尤其是特定申请人的分析时,可以根据预先收集的申请人列表来进行相应的分析,例如“知识产权出版社有限责任公司”、“北京中献电子技术开发中心”和“北京中知智慧科技有限公司”等在该申请人列表中被认为同属于一个公司,此时文件群分析单元241将其归为属于一个申请人来进行相应的比较文件的比例值分析。可选的,该信息处理装置201还具有映射单元242,建立了文件群分析单元241输出的特定类型人员的比较文件的比例值与调整值c之间的映射关系,第三评分值调整单元240用调整值c对比较单元输出的比较值进行调整。在步骤S3010中,以列表方式将评分结果显示在显示装置301上。当然,也可仅显示部分评分值,比如前300个比较文件和特定专利号的评分值。当用户向输入装置101输入的是某个特定专利号时,以高亮方式显示该特定专利号的评分结果。该信息处理装置201还可进一步包括排序单元209,即,在S2080和S3010之间插入步骤S2090,接收比较单元208输出的每个评分值,并在进行同族专利或相同专利去重后,将上述比较单元208生成的每个文件的评分值以及用户输入的特定专利对应的评分值进行排序,得到排序结果。可以采用归一化的值来得到排序结果,例如,可以根据文件的相应排序来获得每个文件的序号,之后,再根据每个文件在全部文件中的序号占比来获得相应的归一化排序结果,比如,当某一文件的排序号是21时,而共有553个比较文件时,该归一化值可以是21/553,并将该值作为排序结果。此时,显示装置301接收排序单元209输出的排序结果,当用户向输入装置101输入的是某个特定专利号时,还接收步骤S2080中生成的指示信息,并显示上述排序结果,同时,当用户向输入装置101输入的是某个特定专利号时,以高亮方式显示该特定专利号的评分值。上述中,可以将比较单元208、第三评分值调整单元240、映射单元242和文件群分析单元241组合为一个模块,即组合为评价单元250。其中,上述第一分析单元210、第二分析单元211和第三分析单元214中的任两个或全部三个可以仅由一个分析单元216实现。此外,因专利的权利要求书代表了该专利的法律信息,且独立权利要求包含了大部分重要的法律信息,因此,在第一分析单元210、第二分析单元211和第三分析单元214对专利进行语义分析时,可以仅对其权利要求进行分析,或仅对独立权利要求进行分析。图3是本发明的数据生成单元的一个实施例,对应于用户向输入装置101输入一特定技术文件,如特定专利号的情形。图4是本发明的数据生成单元的处理流程图。下面结合图3和图4来进行说明。该数据生成单元203包括
技术领域:
语义分析单元2031、分类号获取单元2032、特定特征提取单元2033和检索式生成单元2034。其中,在用户向输入装置101输入特定专利号时,该数据生成单元203在图4的步骤S20301中从信息数据库217中检索该特定专利号而获得上述特定专利的信息。之后,该
技术领域:
语义分析单元2031在图4的步骤S20302中从所获得的上述特定专利的信息中提取该专利的发明名称、说明书的
技术领域:
、权利要求的前序部分进行语义分析,而获得与该特定专利有关的
技术领域:
关键词。通过语义分析方法来获得关键词的方法是现有技术中常用的技术,方法有例如US2010/0185689A1和CN104239300A所公开的通过语义分析来提取关键词的方法等。在提取出相应的关键词后,
技术领域:
语义分析单元2031在图4的步骤S20303中访问同义词库2036,获取所提取的关键词的同义词。其中,同义词是预先存储在同义词库2036中的。分类号获取单元2032在图4的步骤S20304中提取用户输入的特定专利的分类号,并获得上述特定专利分类号的交叉分类号。其中该交叉分类号的获取方法包括预先建立所有分类号的交叉分类号映射,在提取出特定专利的分类号后,通过映射方式获得其所有交叉分类号;或者通过统计分析获得该特定专利的分类号的方法等。在步骤S20313中,将表示是否进行了特定特征提取的标志i设为0。之后,检索式生成单元2034在图4的步骤S20305中获得
技术领域:
语义分析模块所提取的关键词及其同义词和分类号获取单元2032获取的分类号,来构建检索式。在步骤S20306中通过检索单元2035用由检索式生成单元2034所生成的检索式在信息数据库库217中进一步检索而获得检索结果,当步骤S2037中的检索结果超过第一阈值且i<5时(对应于步骤S20307中的“是”),该第一阈值的取值范围是例如5000,说明检索结果存在较大噪声,此时数据生成单元203启动图4的步骤S20314,使标志i=i+1,并在S20315中判断i是否为1。在i为1的情况下,表示需进行特定特征提取,而在步骤S20308中,使特定特征提取单元2033工作,该特定特征提取单元2033从权利要求的特征部分、说明书全文中寻找出现“技术问题”、“发明目的”等体现该所要解决的技术问题的句子或段落,从上述句子或段落中通过与上述类似的语义分析方法来获得上述句子或段落的关键词。当特定特征提取单元2033提取的关键词有多个时,对上述关键词进行优先级排序,例如可根据权利要求的序号、与“发明目的”、“技术问题”的词距远近程度、词频的概率、与发明名称之间的相关程度等来建立该优先级顺序,并将上述关键词命名为优先级1关键词、优先级2关键词….优先级N关键词。在图4的步骤S20309中,将特定特征提取单元2033提取的关键词,即优先级1关键词、优先级2关键词….优先级N关键词与排除词库2037相比较,而将表示该领域通用含义的词语排除,该排除词例如是“处理器”、“数据”、“信息”、“信号”、“单元”、“模块”等代表了本领域通用结构的词语。例如在此例中,优先级1关键词是通用词,因此,在步骤S20310中将其抛弃。在步骤S20311中,以优先级为顺序对保留关键词进行排序,例如在此例中,保留的关键词是优先级2关键词….优先级N关键词。之后,从优先级最高的关键词开始,即在本例中,从优先级2关键词开始,查询同义词库2036,获得该优先级2关键词的同义词,在步骤S20305中,以步骤S20303获得的
技术领域:
的关键词及其同义词、步骤S20304中获得的特定专利的分类号及其交叉分类号以及步骤S20312中获得的优先级2关键词及其同义词库为基础,构建检索式,并继续在S20307中判断检索结果是否大于第一阈值且i是否小于5,在检索结果大于第一阈值且i小于5的情况下,继续进行S20314,使i=i+1,由于此时i=2,因此,直接进入到S20312中,获取优先级次之的优先级3关键词及其同义词,并与步骤S20303获得的关键词及其同义词、步骤S20304获得的分类号及其交叉分类号以及优先级2关键词一起,在步骤S20305中构建检索式,直至S20307的判定结果为否。当S20307的判定结果为否时,结束流程。将此时数据生成单元203所获得的数据存储到对比库204中。图5是本发明的数据生成单元的另一实施例。图6是本发明的数据生成单元所实施的处理流程的另一例。其对应于用户输入相关技术的简单描述的情形。如图5所示,数据生成单元203包括
技术领域:
分析单元2031’,分类号获取单元2032’、特定特征分析单元2033’、检索式生成单元2034’和检索单元2035’。如图6所示,该
技术领域:
分析单元2031’在步骤S20301’中获取用户输入的有关
技术领域:
的相关描述,该描述可以是用户输入的有关
技术领域:
的关键词或者相应句子表述。在用户输入是句子表述时,可通过语义分析将该句子拆分成表征
技术领域:
的关键词。之后,在步骤S20302’中,访问同义词库2036,来获取与用户输入的
技术领域:
有关的关键词对应的同义词。在步骤S20303’中,通过在信息数据库217中检索该
技术领域:
的关键词及其同义词,来统计与该
技术领域:
对应的分类号。由于关键词检索会引入大量噪声,通常认为排序在后的分类号与申请人输入的
技术领域:
无关,因此,可以只选取统计分析得到的前10或前20分类号作为需要检索的分类号。该图6的后续步骤与图4的相应流程步骤相同,因此,在此省略说明。图7是本发明的分析单元的一实施例。图8是本发明的分析单元的处理流程图。下面结合图7和图8来进行说明。如图7所示,第一分析单元210包括专利信息获取单元2101、前序关键词获取单元2102、独权关键词获取单元2103、从权关键词获取单元2104和综合单元2105。专利信息获取单元2101在步骤S21001中获取与专利号对应的专利信息,在步骤S21002中,前序关键词获取单元2102提取出独立权利要求,并通过语义分析来分析其前序部分,获得关键词表,并通过访问同义词库2036,合并所获得的关键词同义词而得到关键词表1,获得该关键词表1中的每个关键词对应的词频,并对其赋予第一加权值W1。在步骤S21003中,独权关键词获取单元2103提取独立权利要求的特征部分,并通过语义分析和访问同义词库2036而获得关键词表2及关键词表2的关键词的对应词频,同时根据上述关键词表2中的关键词与前序部分的相关关系对其赋予不同的相关度,并对上述关键词表2中的关键词赋予第二加权值W2。在步骤S21004中,从权关键词获取单元2104提取从属权利要求的特征,并通过语义分析和访问同义词库2036获得关键词表3及关键词表3的关键词的对应词频,同时根据上述关键词表3中的关键词与前序部分的相关关系对其赋予不同的相关度,并对上述关键词表3中的关键词赋予第三加权值W3。在步骤S21005中,综合单元2105获取步骤S21002、S21003、S21004的关键词、词频、相关值,加权值,并进一步进行同义关键词合并,而得到关键词列表,该列表中存储了相关关键词及其对应权重。图1中的第二分析单元211的结构和处理流程与上述第一分析单元210相似,在此省略相应说明。图1中的第三分析单元214接收第二分析单元211分析得出的对比库204中存储的每个文件的关键词及其权重,并访问同义词库2036来进行同义词整理和归纳,而形成参考关键词列表,该列表包括了相应的参考关键词及其对应权重。图9是本发明的比较单元208的一个实施例。图10是本发明的比较单元208所实施的实施流程的一个实施例。如图9和图10所示,本发明的比较单元208包括参考关键词权重排序单元2081、关键词顺序分析单元2082和求和单元2083。首先,在步骤S20801中,对所输入的参考关键词列表及其权重,按权重对参考关键词进行排序,并赋予每个关键词相应的序号。在步骤S20802中,获得待评专利的关键词及其权重。该待评专利可以是用户向图1的输入装置101输入的特定专利或者图1的对比库204中的每一个文件。接着,在步骤S20803中,由关键词顺序分析单元2082获得待评专利中的每个关键词在参考关键词表中的序号,之后由求和单元2083在步骤S20804中对待评专利的每个关键词的序号求和,而获得最终的评分值。图11是本发明的比较单元的另一实施例。对于其与图9的相同模块与结构,引用与图9相同的图标记而省略说明。在这里,仅说明其与图9的不同点。图11的比较单元208还包括关键词相似度分析单元2085’,用于输入参考关键词及其权重值和待评专利关键词及其权重,分析其相似度后,输出到求和单元2083’。该相似度分析方法包括但不限于求取参考关键词及其权重值和待评专利关键词及其权重之间的向量夹角,从而获得其相似度。由此,通过相似度来调整求和单元2083’输出的求和值,从而得到评分值。第二实施例图12示出了本发明的信息处理系统的另一实施例。对于与图1具有相同功能的模块或单元,在图12中引用同一附图标记而省略说明。在这里,仅说明其与图1的不同点。图1中,在比较单元208输出评分值之后,根据文件群分析单元241分析得到的特定类型人员在全部比较文件中的比例值,来调整比较单元208输出的比较值。但在图12中,文件群分析单元241将其分析结果直接输出到比较单元208’。比较单元208’在获得评分值时,参考文件群分析单元241获得的特定类型人员在比较文件中所占的比例值,比较第一分析单元210得到的与该特定专利号对应的关键词及该关键词的权重或第二分析单元211得到的对比库204中存储的每个比较文件的关键词及该关键词的权重,以及参考关键词列表存储单元212中存储的参考关键词列表及其权重,来获得评分值。可以在比较单元208’中预先存储上述比例值、特定文件或比较文件的关键词及其权重与参考关键词及其权重之间的预定算法,该算法例如是变量为关键词相似度与比例值之间的非线性函数,因此,在获得第一分析单元210得到的与该特定专利号对应的关键词及该关键词的权重或第二分析单元211得到的对比库204中存储的每个比较文件的关键词及该关键词的权重,以及文件群分析单元241获得的特定类型人员在比较文件中所占的比例值之后,根据上述非线性函数,来得到相应的评分值。之后,将上述评分值由显示装置301输出,或经排序单元209排序后,由显示装置301输出。当然,当用户向输入装置101输入的是特定专利号时,还高亮显示该特定专利对应的评分值。上述中可以将比较单元208’和文件群分析单元241合并为一个评价单元250’。第三实施例图13示出了本发明的信息处理系统的第三实施例。对于与图1具有相同功能的模块或单元,在图13中引用同一附图标记而省略说明。在这里,仅说明其与图1的不同点。图13中,该文件群分析单元241’包括比较文件抽取单元2410,先对对比库204中的比较文件按特定类型人员(例如申请人)进行聚类,接着抽取出对比库中属于特定类型人员的全部文件,该特定类型人员的聚类方法可以是如第一实施例中所述的例如将“知识产权出版社有限责任公司”、“北京中献电子技术开发中心”和“北京中知智慧科技有限公司”等认定为同属于一个申请人,而在文件抽取时由比较文件抽取单元2410抽出申请人为上述几个公司的全部比较文件。之后,网络构建单元2411访问第二分析单元211,获得与由比较文件抽取单元2410抽出的每个比较文件对应的关键词及其权重,并根据所获得的对应关键词和权重,同时参考同义词库2036,来构建上述比较文件抽取单元2410抽取出的多个比较文件之间的拓扑关系。例如,对于比较文件1,其抽取出的关键词及其权重如下:序号关键词权重1摄像0.832异常0.623旋转0.53对于比较文件2,其抽取的关键词及其权重如下:序号关键词权重1相机0.762高温0.63异常0.544转动0.32对于比较文件3,其抽取的关键词及其权重如下:序号关键词权重1拍摄0.872异常0.533高温探测器0.44比较0.315旋转0.236正常场景0.12由于比较文件1中的摄像、比较文件2中的相机和比较文件3中的拍摄属于同义词,所以通过参考同义词库2036,将其认为是同一词语。同时,也将“旋转”和“转动”也认定为是同一词语。因此,可以认为比较文件1的关键词是“摄像”、“异常”和“旋转”,比较文件2的关键词是“摄像”、“高温”、“异常”和“旋转”,比较文件3的关键词是“摄像”、“异常”、“高温探测器”、“比较”、“旋转”和“正常场景”,而“高温探测器”可以进一步分解为“高温”和“探测器”,因此可知比较文件1是在比较文件1-3中的母节点,比较文件2是三个中的第二级节点,比较文件3是第三级节点,三个比较文件之间的拓扑关系即如图14(1)所示。将比较文件抽取单元2410中抽取的多个文件形成拓扑网络,如图14(2)所示。之后,根据上述拓扑网络之间的节点数量和上述的关键词之间的权重相似度来获得抽取出的每个文件在文件群中的位置指标值Ln(n为自然数),并得出多个位置指标值(即网络特征值)L1……Ln中的最大值。在此假设比较文件k对应的位置指标值Lk为L1……Ln中的最大值。该树形网络构建单元2411向比较单元208”输出位置指标值(即网络特征值)L1……Ln及其最大值Lk,同时还向比较单元208”输出所抽出的比较文件的数量n。之后,比较文件208”在输出评价值时,先判断该相应的文件是否属于一个文件群,在其不属于某个文件群时,比较单元208将由第一分析单元210或第二分析单元211得到的关键词及其权重与参考关键词列表存储单元212中的参考关键词及其权重进行对比,而获得用户所输入的上述特定专利或对比库中的相应专利的评分值。但是,当其属于文件群时,比较单元208”将具有最大的位置指标值Lk的比较文件k的关键词及其权重与参考关键词列表存储单元212中的参考关键词及其权重进行对比,得到该比较文件k的评价值。之后,根据该比较文件k的评价值,基于L1……Ln与Lk之间的关系以及n的数值,得到该文件群中的所有比较文件1~比较文件n的评分值。上述中树形网络构建单元2411是以属于特定类型人员的比较文件的关键词及其权重为基础,来构建相应的文件之间的拓扑网络,但是也可以以属于特定申请人的比较文件的引证关系为基础,来构建上述拓扑关系网络,其中该引证关系包括文件之间的引证和被引证关系。第四实施例图15示出了本发明的信息处理系统的第四实施例。由于其与图1、图12和图13类似,因此,将图1、图12和图13中的文件群分析单元与比较单元之间的组合用评价单元250来表示,并在图15中仅示出其与图1、图12或图13相比有变化的模块或单元。图15中,该信息处理装置201还包括报告生成单元218,接收排序单元209输出的排序结果,当用户向输入装置101输入的是某个特定专利号时,还接收指示该特定专利的评分值的指示信息,并根据上述排序结果和指示信息,生成相应的图表与对应的说明,从而生成报告,并将对应的报告输出到显示装置301。上述报告包括重要度最高的多项技术或专利以及当用户向输入装置101输入的是某个特定专利号时,该特定技术或专利的排名情况、重要度最高的专利的申请人分布、特定申请人的专利重要度时间分布、领域分布等。由此,用户可以通过图文等直观的方式获知评价结果,以便进行后续操作。这里排序单元209所接收的评分值可以是根据第一、第二或第三实施例所获得的评分值。第五实施例图16示出了本发明的信息处理系统的又一实施例。由于其与图1、图12和图13类似,因此,将图1、图12和图13中的文件群分析单元与比较单元之间的组合用评价单元250来表示。图16中,与图1中相同,该数据生成单元203将检索结果存储到对比库204’中。由于当向输入装置101输入的是某个特定专利号时,数据生成单元203是以该输入的特定专利号为基础来生成检索式的,因此,此时所输入的特定专利号也包含在对比库204’的比较文件中。因此,此时可以省略设置第一分析单元210。此时,对比库204’可获得接收单元202接收的特定专利号,并用一指示信息来标示该特定专利号。第二分析单元211接收对比库204’中的一组技术文件信息以及表示用户输入的特定专利号的指示信息,来进行分析,并输出每个技术文件信息的关键词分析结果和表示用户输入的特定专利的指示信息。之后,可按照第一、第二或第三实施例的方式由文件群分析单元进行文件群分析,而输出最终的比较值。当然,上述图16的信息处理装置201也可如图15所示,具有报告生成单元218,生成相应的图表与对应的说明,从而生成报告,并将对应的报告输出到显示装置301。第六实施例图17表示本发明的信息处理装置的第六实施例。对于与图1具有相同功能的模块或单元,在图17中引用同一附图标记而省略说明。在这里,仅说明其与图1的不同点。该图17的信息处理装置201还包括日期分析单元230和第一评分值调整单元231。该日期分析单元230分析待评专利的日期,例如申请日。该待评专利是用户向图1的输入装置101输入的特定专利或者图1的对比库204中的每一个文件,其是评价单元250输出的专利的评分值所对应的文件。第一评分值调整单元231根据日期分析单元230输出的日期,对评价单元250输出的评分值进行调整。其中,日期分析单元230分析该对比库204中的每一个比较文件,求出这些文件的日期平均值,之后将日期分析单元230获得的某个比较文件的日期与上述日期平均值相比,根据其距日期平均值的距离,获得调整值b,并用调整值b与比较单元208输出的评分值加权,来进行调整。其中,当某个比较文件的日期早于平均值时,该调整值b>1,且比较文件的日期越早,调整值b越大;该某个比较文件专利的日期晚于平均值时,该调整值b<1,且比较文件的日期越晚,调整值b越小。显示装置301显示该第一评分值调整单元231输出的结果。当然,还可在第一评分值调整单元231后具有排序单元,对调整后的评分值进行排序。同时,该信息处理装置201还可具有报告生成单元,根据调整后的评分值生成报告,并将报告结果显示在显示装置301上。第七实施例本发明的信息处理系统可以由图18所示的计算机系统501来实现。如图18所示,本发明的计算机系统501包括输入装置5013、存储器5011和处理器5012,其中用户向该输入装置5013输入信息,在该存储器5011中存储了计算机指令信息和参考关键词列表,该计算机指令信息是可执行例如图2、4、6、8或10等流程或第二、第三实施例的对应流程的指令信息;该处理器5012从存储器5011中读取该计算机指令信息,来加以处理,使得该处理器可接收用户输入的信息;根据用户输入的信息,生成检索式来检索与该用户输入的信息对应的领域范围,并存储检索获得的文件;语义分析检索获得的每个文件,得到每个文件的关键词列表;获得检索所获得的文件的特定类型人员的聚类信息;根据所获得的每个文件的关键词列表、存储器中存储的参考关键词列表以及特定人员聚类信息,来得到评分值,并在计算机系统501的显示器上显示最终的评分结果。在用户输入的信息中包含了特定专利号时,以高亮方式显示该特定专利的评分值。本发明的信息处理装置及方法可以在如下几个方面实施:例如,对于企业而言,可以将由本发明的信息处理装置输出的评分值输入到企业的知识产权管理系统中,该知识产权管理系统中具有年费管理装置,该年费管理装置可根据本发明的信息处理装置输出的评分值,同时根据信息处理装置中的评价单元分析得到的文件群聚类结果,来决定继续支付年费或放弃。当企业决定放弃属于文件群的专利时,可以由第一、二或三实施例的文件群分析单元输出全部文件群列表或基于第三实施例构建的文件群拓扑网络,由此,可以慎重决定是否放弃支付年费。例如,也可将本发明的信息处理装置输出的评分值输出到企业运营管理系统中,在投资价值不明的情况下,该企业管理系统具有判断装置,根据上述评分值来分析本企业的核心技术,并针对上述核心技术进行外围布局,以形成专利包,从而更好地保护自身专利。例如,也可将本发明的信息处理装置输出的评分值与企业运营管理系统中的企业运营数据,例如转让次数、许可次数、转让许可领域、质押、融资领域等相结合,来得到该待评专利的评分值。根据本发明,企业可评估其竞争对手或其他公司正在研发的技术的相关价值,并基于上述相关价值来进行投资对象的选择,或与其他对手探讨是否进行共同研发,以较早地抢占市场先机。上面参照附图说明了本发明的实施例,但是本发明的范围并不限于上述实施例,合适地组合或替换各实施例的结构也包含在本发明的范围中。本领域普通技术人员可以根据其知识组合或替换上述各实施例的结构或组成,这些变形的实施方式也包含在本发明的范围中。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1