基于流式大数据处理方式的降雨径流预测计算方法与流程
本发明涉及一种基于流式大数据处理方式的降雨径流预测计算方法,降雨径流预测技术领域。
背景技术:
世界各地,洪涝灾害每年都在不断发生,直到今天,对洪水研究与预测仍然是工程与学术界不断研究的重要课题。其中,降雨径流预测是洪水预报的重要组成部分,在较多的降雨径流预测模型中,SCS(Soil Conservation Service)模型是目前应用最为广泛的模型之一。SCS模型由于计算过程简单,涉及率定的参数较少,需要的资料易于获取,适用于缺乏详细降雨过程资料的农业小流域,又考虑了土壤、植被、土地利用状况等下垫面对产流影响,因此被普遍认可和广泛应用。SCS模型最初是针对小流域水文过程,对大、中尺度流域水文过程的模拟计算没有涉及,针对SCS模型的不足,不少学者与科技工作者提出了各种SCS模型的改进方法。
在基于SCS模型及其改进模型的算法上,各种研究主要集中在算法本身的实现,在考虑算法在实际应用中的性能,尤其是利用SCS模型进行及时洪水预报的系统性能,相关研究涉足较少,同时,SCS模型及其改进模型,需要进行产流计算以及汇流计算,有着较高的算法复杂度。要得到精度较高的流域径流,往往需要结合遥感影像处理、土壤类型图片处理、数字高程模型处理、降雨资料处理、径流资料分析等数据分析处理,这些分析与处理的算法复杂度高,计算时间长,特别是改进后的SCS模型应用于大、中尺度流域的径流计算,计算复杂度更高、时间更长,因此,利用常规计算流程与方法的非集群线性计算模式实现SCS模型及其改进模型在大、中尺度流域的实时洪水预报,性能将会是严重瓶颈,满足不了系统在实际应用中的要求。随着大数据技术的发展,利用流式大数据处理方式实现SCS模型及其改进模型在大、中尺度流域的实时洪水预报,能够有效解决使用SCS模型进行实时洪水预报的系统性能问题。
大数据技术近年来取得快速发展。大数据处理方式主要分为批量型处理方式和流式型处理方式,其中流式型处理方式具有集群非线性、并行处理的特点,且计算能力高效。径流计算的传统计算机计算方式不能满足实际应用的数据计算能力的要求,这是由于径流计算的复杂度以及要取得高精度的计算结果,需要对流域进行更小的网格化,这种更小的网格化将导致计算量的增加,传统计算机技术面临更大的计算能力的瓶颈,因此使用大数据流处理方式,是解决计算能力瓶颈的有效方式。本发明通过把大、中尺度流域在逻辑上划分为不同的子流域,利用大数据流式处理方式,结合每个子流域实时监测的断面流量,通过对每个子流域的并行计算,解决SCS模型及其改进模型在大、中尺度流域的实时洪水预报中的性能问题。
参考文献
[1]JP Patil,A Sarangi,AK Singh.Evaluation of modified CN methods for watershed runoff estimation using a GIS-based interface[J].Biosystems engineering,2008,100(1):137-146.
[2]赵晶,黄强,郝鹏,等.基于SCS模型实时洪水预报系统的研究[J].西安理工大学学报,2013,29(4):21-27.
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种基于流式大数据处理方式的降雨径流预测计算方法。
技术方案:一种基于流式大数据处理方式的降雨径流预测计算方法,首先设计基于实时水量的子流域及时预测算法和基于SCS模型洪水预测算法,然后使用流式大数据处理方式对这两个算法进行处理。
流域划分与断面流量计算原理
在实时洪水预报中,选择任何一个子流域的监测流量,能够预测出下游第N个子流域的断面流量,第N个子流域的断面流量为上一个断面流量与当前子段的SCS模型值的和减去子流域段1的其他流出量。
基于实时水量的子流域及时预测算法
基于流域划分与断面流量的计算原理,通过传感器监测子流域流入断面,实时获取每个子流域的流入量,通过SCS模型计算子流域径流,求出子流域的及时产流。
其中:
Q'n是第n段流域的流出断面流量,Qn"是第n段流域中传感器的监测量,Qn是第n段子流域利用SCS模型的径流,是第n段流域其它流出量,这个是一个参数值。
基于SCS模型洪水预测算法
由两个算法构成,分别是基于上游子流域产流的及时预测与基于上游子流域的迭代预测。
基于上游子流域产流的及时预测
上一子流域到本流域的流出量加本段流域通过SCS模型计算出的模拟量,见公式2。
其中:
Qrn'是第n段子流域的流出断面流量,Qr(n-1)'是第n-1段子流域的流出断面流量,Qn是第n段子流域利用SCS模型的计算值,是第n段子流域其它流出量,这个是一个参数值。
基于上游子流域的迭代预测
设定任意一个流域段为基点,预测后面第n个子流域的水量趋势。这个基点作为第一个流域段,监测第一个流域流出断面的流量,通过公式2,选定的第一个子流域断面的实时流量通过传感器获取并计算出来,计算出的第一个流域段的出水量Q11,则第二个流域段的入水量:
依次类推,求出流域段3、4…n的入水量。
通过SCS模型计算每个子流域段的径流,SCS径流计算如下:
水平衡方程是对水循环现象定量研究的基础,用于描述各水文要素间的定量关系,见公式4。
P=Ia+F+Q (4)
其中:
P:总降雨量(mm);
Ia:初损值(mm),主要指截流、表层蓄水等;
F:累积下渗量(不包括Ia)(mm);
Q:直接径流量(mm)。
通过比例相等假设,地表径流Q与总的降雨量P及入渗量、最大滞留量比值相等,可以得到公式5。
其中:
S:初损值,也就是可能最大滞留量(mm)。
初损值可以通过公式6计算。
Ia=λS (6)
其中:
λ:区域参数,主要取决于地理和气候因子[1]。λ可表达为λ=atp,其中a为Horton常数,tp是降水时刻到地表径流形成的时段,λ的取值范围为0.1≤λ≤0.3。
基于流式大数据的处理方法
大数据流处理技术最主要的开源实现是Storm,本文使用Storm技术实现上述基于SCS模型洪水预测方法。
上述中每个流量预测算法作为Storm框架的拓扑逻辑(topology),在“基于实时水量的子流域及时预测”(公式1)过程中,整个子流域流量及时预测作为一个拓扑逻辑,提交拓扑逻辑后,每一个子流域的及时预测在不同的机器上并行计算。
在“基于上游子流域产流的及时预测”(公式2)过程中,整个子流域流量及时预测作为一个拓扑逻辑,提交拓扑逻辑后,每一个子流域的流量预测过程被提交到不同计算机进行处理,每一个计算节点启动两个worker,一个worker负责SCS模型计算径流,另外一个worker接收上一个子流域的及时预测值,并对本子流域的预测值进行整体计算。
附图说明
图1为流域分段示意图;
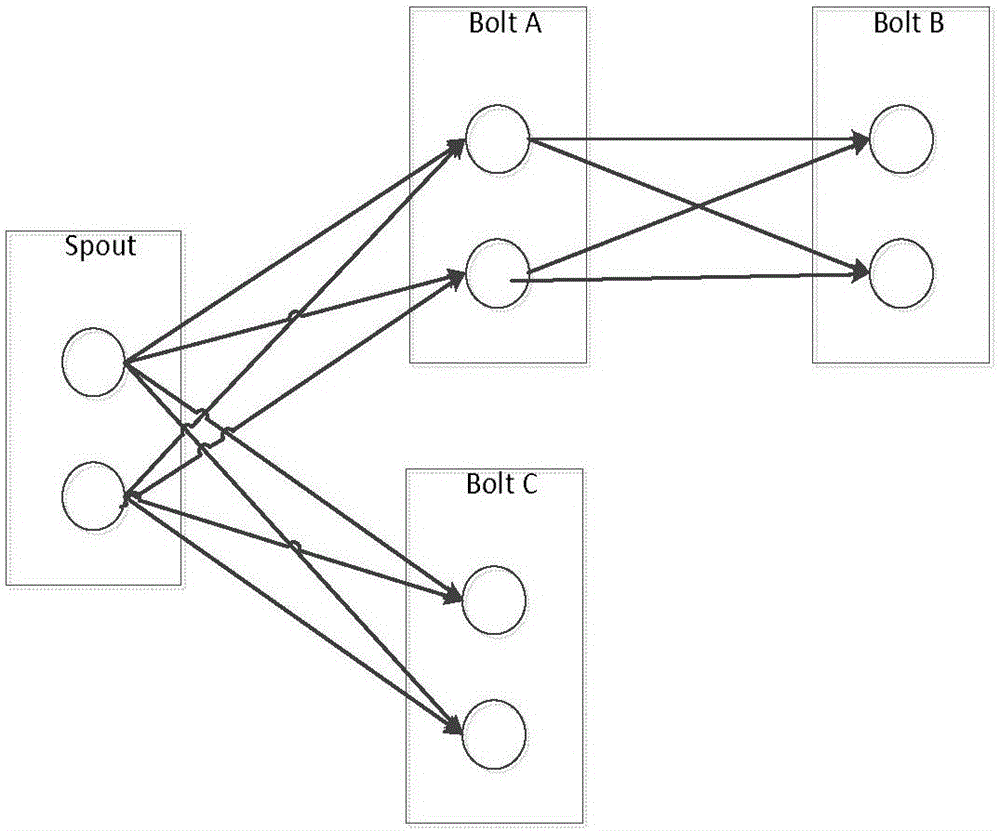
图2为Storm的拓扑逻辑;
图3为Storm拓扑逻辑的执行流程;
图4为基于上游子流域的及时迭代预测;
图5为伊春水系图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
基于流式大数据处理方式的降雨径流预测计算方法,首先设计基于实时水量的子流域及时预测算法和基于SCS模型洪水预测算法,然后使用流式大数据处理方式对这两个算法进行处理。
流域划分与断面流量计算原理
通过把大、中流域划分为不同子流域,利用SCS模型及其改进模型对每个子流域进行径流计算,获取每个子流域的径流。大、中型流域划分为不同子流域的方法抽象为图1。
如图1所示,流域各个断面流量的计算原理:
1.子流域1的流出断面A1的流量为断面A0的流量与子段1的SCS模型值的和减去子流域段1的其他流出量;
2.子流域2的流出断面A2的流量为断面A1的流量与子段2的SCS模型值之和减去子流域段2的其他流出量;
3.以此类推,通过子流域1,计算出流域4的流出断面A4的流量。
以此原理,当我们在实时洪水预报中,选择任何一个子流域的监测流量,能够预测出下游第N个子流域的断面流量。
基于实时水量的子流域及时预测算法
基于流域划分与断面流量的计算原理,通过传感器监测子流域流入断面,实时获取每个子流域的流入量,通过SCS模型计算子流域径流,求出子流域的及时产流。
其中:
Q'n是第n段流域的流出断面流量,Q"n是第n段流域中传感器的监测量,Qn是第n段子流域利用SCS模型的径流,是第n段流域其它流出量,这个是一个参数值。
基于SCS模型洪水预测算法
由两个算法构成,分别是基于上游子流域产流的及时预测与基于上游子流域的迭代预测。
基于上游子流域产流的及时预测
上一子流域到本流域的流出量加本段流域通过SCS模型计算出的模拟量,见公式2。
其中:
Qrn'是第n段子流域的流出断面流量,Qr(n-1)'是第n-1段子流域的流出断面流量,Qn是第n段子流域利用SCS模型的计算值,是第n段子流域其它流出量,这个是一个参数值。
基于上游子流域的迭代预测
设定任意一个流域段为基点,预测后面第n个子流域的水量趋势。这个基点作为第一个流域段,监测第一个流域流出断面的流量,通过公式2,选定的第一个子流域断面的实时流量通过传感器获取并计算出来,计算出的第一个流域段的出水量Q11,则第二个流域段的入水量:
依次类推,求出流域段3、4…n的入水量。
通过SCS模型计算每个子流域段的径流,SCS径流计算如下:
水平衡方程是对水循环现象定量研究的基础,用于描述各水文要素间的定量关系,见公式4。
P=Ia+F+Q (4)
其中:
P:总降雨量(mm);
Ia:初损值(mm),主要指截流、表层蓄水等;
F:累积下渗量(不包括Ia)(mm);
Q:直接径流量(mm)。
通过比例相等假设,地表径流Q与总的降雨量P及入渗量、最大滞留量比值相等,可以得到公式5。
其中:
S:初损值,也就是可能最大滞留量(mm)。
初损值可以通过公式6计算。
Ia=λS (6)
其中:
λ:区域参数,主要取决于地理和气候因子[1]。λ可表达为λ=atp,其中a为Horton常数,tp是降水时刻到地表径流形成的时段,λ的取值范围为0.1≤λ≤0.3。
基于流式大数据的处理方法
大数据处理方式主要分为大数据批处理方式、大数据流处理方式,大数据批处理与大数据流处理方式是当前大数据处理处理技术的两个重要研究方向,基于这方面技术,学者与工程师都进行了大量的研究。其中大数据批处理技术的开源实现是Hadoop,现阶段已经发展到Yarn版本,也就是Hadoop 2.0;大数据流处理技术最主要的开源实现是Storm,本文使用Storm技术实现上述基于SCS模型洪水预测方法。
上述中每个流量预测算法作为Storm框架的拓扑逻辑(topology),基于Storm的拓扑逻辑如图2,拓扑逻辑在Strom中的执行流程如图3。
以图2为例,在“基于实时水量的子流域及时预测”(公式1)过程中,整个子流域流量及时预测作为一个拓扑逻辑,提交拓扑逻辑后,每一个子流域的及时预测在不同的机器上并行计算。
以图2为例,在“基于上游子流域产流的及时预测”(公式2)过程中,整个子流域流量及时预测作为一个拓扑逻辑,提交拓扑逻辑后,每一个子流域的流量预测过程被提交到不同计算机进行处理,每一个计算节点启动两个worker,一个worker负责SCS模型计算径流,另外一个worker接收上一个子流域的及时预测值,并对本子流域的预测值进行整体计算,计算过程见图4。
实验与结果分析
利用SCS改进模型的算法进行洪水预报的常规计算流程与方法是非集群的线性计算模式,比如文献[2]中使用非集群的线性计算模式,利用Visual Basic开发工具实现了SCS模型的洪水预报。通过伊春水系汤旺河4个连续监测站点为参考点来对常规计算流程与方法与本发明提出的方法进行比较验证。
伊春水系是黑龙江汤旺河主要支流之一,图5是伊春水系图,图中圆圈标注是五营、伊新、西林、晨明4个连续监测点,通过这4个监测点,把汤旺河流域分为五段,五营监测点是第一段的流出断面,伊新监测点是第二段的流出断面,西林监测点是第三段的流出断面,晨明监测点是第四段的流出断面。
基于实时水量的子流域及时预测算法比较
编写测试函数SCSTest,函数返回值为100000ms到120000ms的随机时间,基于这四个连续监测点为例进行验证计算,对最终结果耗时进行比较。
常规计算流程与方法:顺序执行每个子流域SCS径流计算的SCSTest函数,获取SCSTest返回值,最后对每个子流域的返回值求和。
流式大数据的处理方法:并行计算,4个子流域的函数被分发到不同的节点进行计算,并行获取SCSTest的返回值,最后取最大值。
基于流式大数据处理时间是常规计算流程与方法处理时间的114285/453287*100=25.21%。
基于SCS模型洪水预测算法比较
编写测试函数SCSTest,函数返回值为100000ms到120000ms的随机时间,模拟SCS模型计算子流域径流的耗时;测试函数testSum用于模拟接收上一个子流域的及时预测值并对本子流域的径流值求和,函数返回值为1000ms到1200ms的随机时间。基于这4个连续监测点为例进行验证计算,对最终结果耗时进行比较。
常规计算流程与方法:顺序执行每个子流域SCS径流计算的SCSTest函数与汇总函数testSum,获取每个子流域的输出时间。
流式大数据的处理方法:并行计算,4个SCS径流计算的SCSTest函数与汇总函数testSum被分发到不同的节点进行计算,并行获取testSum的返回值,最后取最大值。
基于流式大数据处理时间是传统常规计算流程与方法处理时间的119705/450747*100=26.56%。
基于以上实验验证,使用非流式大数据的传统处理方式与使用流式大数据的方式相比,使用流式大数据处理方式的情况下,五营、伊新、西林、晨明4个监测点进行并行同步计算,在同一时间段得到4个监测点的及时预测值,而使用传统处理方式,4个监测点串行计算,计算时间是使用流式大数据计算的4倍,即整体计算时间缩短了大约73%。
表1基于实时监测水量的子流域及时预测比较
表2基于上游子流域的迭代预测比较
- 还没有人留言评论。精彩留言会获得点赞!