基于词间加权关联模式的越英跨语言文本检索方法及系统与流程
本发明属于文本信息检索领域,具体是一种基于词间加权关联模式的越英跨语言文本检索方法及系统,适用于采用越南语查询检索英文文档的跨语言文本信息检索等领域。
背景技术:
跨语言信息检索指的是以一种语言的查询检索其他语言的信息资源的技术。越英跨语言信息检索方法是用越南语查询检索英文文档的跨语言检索问题,其中,表达查询的越南语言称为源语言,所检索的文档的英文语言称为目标语言。随着中国和东盟国家交流越来越密切,面向东盟国家语言的跨语言信息检索方法研究显得迫切和重要。
世界各地学者从不同的角度和方向对跨语言信息检索方法及系统进行了深入探讨和研究,取得了丰富的成果,然而,当前跨语言信息检索研究所存在的问题还没有完全解决,该领域亟待解决和关注度比较高的问题之一是跨语言信息检索过程中存在的严重查询主题漂移问题,面临着比单语言检索更为严重的词不匹配问题,这些问题常常导致跨语言检索性能低下,不如单语言检索性能。针对上述问题,近年来,基于查询扩展的跨语言信息检索研究得到了更多的关注和讨论,其研究主要集中在基于相关反馈的(Parton K,Gao J.Combining Signals for Cross-Lingual Relevance Feedback[C].Proceedings of8thAsia Information Retrieval Societies Conference(AIRS 2012),Tianjin,China.Springer-Verlag Berlin Heidelberg2012,LNCS 7675,Information Retrieval Technology.2012:356-365.Lee C J,Croft W B.Cross-Language Pseudo-Relevance Feedback Techniques for Informal Text[C].Proceedings of 36th European Conference on IR Research(ECIR 2014),Amsterdam,The Netherlands.Advances in Information Retrieval.Springer International Publishing,2014:260-272.)、潜在语义的(闭剑婷,苏一丹.基于潜在语义分析的跨语言查询扩展方法[J].计算机工程,2009,35(10):49-53.宁健,林鸿飞.基于改进潜在语义分析的跨语言检索[J].中文信息学报,2010,24(3):105-111.)、语言模型的和主题模型的(Ganguly Debasis and Leveling Johannes and Jones Gareth J.F.Cross-lingual topical relevance models[C].In:24th International Conference on Computational Linguistics(COLING 2012),2012.;Wang Xuwen,Zhang Qiang,Wang Xiaojie,et al.LDA based pseudo relevance feedback for cross language information retrieval[C].IEEE International Conference on Cloud Computing and Intelligence Systems(CCIS2012).Hangzhou:IEEE,2012:1993-1998.;Xuwen Wang,Qiang Zhang,Xiaojie Wang,et al.Cross-lingual Pseudo Relevance Feedback Based on Weak Relevant Topic Alignment.Proceedings ofthe 29th Pacific Asia Conference on Language,Information and Computation,PACLIC 29,Shanghai,China,2015:529-534.)等跨语言信息检索研究,其语言对象主要是以英语为主,大多都是研究英语和其他语言的跨语言检索问题。
当前,中国南宁市作为中国-东盟博览会永久举办地以来,中国与东盟国家的政治、经济、文化等往来更加频繁和密切,面向东盟国家语言的跨语言信息检索和跨语言信息服务研究显得更加迫切,其重要性日益凸显。
技术实现要素:
本发明的目的在于针对现有技术中的上述问题,将加权关联模式挖掘技术和用户相关反馈结合应用于越英跨语言信息检索,提供一种基于词间加权关联模式的越英跨语言文本检索方法及系统,能提高和改善越英跨语言信息检索性能,有较好的实际应用价值和推广前景。
为实现上述发明目的,本发明采用了如下技术方案:
一种基于词间加权关联模式的越英跨语言文本检索方法,包括如下步骤:
(1)将越南语用户查询通过机器翻译模块翻译为英文查询式检索英文文档;
(2)提取跨语言初步检索结果前列r篇英文文档提交给用户,让用户对初步检索文档进行相关性判断;
(3)根据用户的相关性判断确定初检英文相关文档,构建用户反馈英文相关文档集,文档集中的文档数设为n;
(4)预处理用户反馈英文相关文档集,即进行去除停用词、英文词干提取、计算特征词权值和提取特征词的预处理操作,构建初检英文相关文档库;
(5)扫描初检英文相关文档库,首先计算初检英文相关文档库中所有特征项权值总和W,然后挖掘加权特征词1_候选项集C1,计算C1权值w(C1),统计C1以外的项目的最大权值maxCwi(!C1)和C1的支持计数nc1,ms为最小支持度阈值,计算KIWT(1,2)的值,KIWT(1,2)的计算公式是:KIWT(1,2)=n×1×ms-nc1×maxCwi(!C1);
(6)计算C1的加权支持度ftwISup(C1),如果加权支持度ftwISup(C1)≧ms,则从1_候选项集C1挖掘1_频繁项集L1,并加到特征词加权频繁项集集合L,ftwISup(C1)的计算公式是:
(7)挖掘k_项集,其中所述的k≧2,包括步骤(7.1)至(7.7):
(7.1)比较候选(k-1)_项集Ck-1权值W(Ck-1)和KIWT(k-1,k)值,剪除其W(Ck-1)<KIWT(k-1,k)的候选项集Ck-1;
(7.2)将余下的进行候选(k-1)_项集Ck-1进行Aproiri连接,得到候选k_项集Ck;
(7.3)当k=2时,剪除不含查询项的候选2_项集;
(7.4)扫描初检英文相关文档库,统计Ck以外的项目的最大权值maxCwi(!Ck)和Ck的支持计数nck,计算Ck权值w(Ck)和KIWT(k-1,k)的值,KIWT(k-1,k)的计算公式是:KIWT(k-1,k)=n×k×ms-nck×maxCwi(!Ck);
(7.5)剪除nck为0的候选项集Ck;
(7.6)对余下的候选k_项集Ck,计算Ck支持度ftwISup(Ck),如果ftwISup(Ck)≧ms,则从候选k_项集Ck中挖掘k_频繁项集Lk,并加到特征词加权频繁项集集合L,ms为最小支持度阈值,ftwISup(Ck)的计算公式是:
(7.7)若k大于候选项集长度阈值或者候选k_项集为空集,则挖掘结束,否则,继续循环步骤(7.1)至(7.6);
(8)从特征词加权频繁项集集合L中挖掘含有查询词项的英文特征词加权关联规则,构建英文特征词加权关联规则库;
(9)从英文特征词加权关联规则库中提取与原查询相关的英文扩展词,构建英文扩展词库;
(10)将原查询和扩展词组合成新查询再次检索英文文档,得到最终检索结果英文文档;
(11)将最终检索结果英文文档经机器翻译模块翻译为越南语文档,最后将最终检索结果英文文档和最终检索结果越南语文档返回给用户。
上述步骤(4)中特征词权值的计算采用tf-idf方法,其计算公式是:
其中,tfm,n表示特征词tm在文档dn中的出现次数,dfm表示含有特征词tm的文档数量,N表示文档集合中总的文档数量。
上述步骤(8)的方法包括步骤(8.1)至(8.2):
(8.1)从特征词加权频繁项集集合L中提取某一加权i_频繁项集ftwIi,找出ftwIi的所有真子集,进行步骤(8.1.1)至(8.1.4)的操作:
(8.1.1)从ftwIi的真子集集合中任意取出两个真子集ftwI1和ftwI2,当ftwI1∩并且ftwI1∪ftwI2=ftwIi;
(8.1.2)计算规则(ftwI1→ftwI2)以及(ftwI2→ftwI1)的英文特征项关联规则条件概率比ftARCPIR及其兴趣度ftARI值;
ftARCPIR(ftwI1→ftwI2)和ftARCPIR(ftwI2→ftwI1)的计算公式如下:
ftARI(ftwI1→ftwI2)和ftARI(ftwI2→ftwI1)的计算公式如下:
ftARI(ftwI1→ftwI2)=ftwISup(ftwI1)×ftwISup(ftwI1,ftwI2)×(1–ftwISup(ftwI2)),
ftARI(ftwI2→ftwI1)=ftwISup(ftwI2)×ftwISup(ftwI1,ftwI2)×(1–ftwISup(ftwI1)),
其中,ftwISup(ftwI1)为的加权频繁项集ftwI1支持度,ftwISup(ftwI2)为的加权频繁项集ftwI2支持度,ftwISup(ftwI1,ftwI2)为的加权频繁项集(ftwI1,ftwI2)支持度;
(8.1.3)如果ftARCPIR(ftwI1→ftwI2)≧mc,并且ftARI(ftwI1→ftwI2)≧mi,则挖掘出英文特征词加权强关联规则ftwI1→ftwI2;若ftARCPIR(ftwI2→ftwI1)≧mc,并且ftARI(ftwI2→ftwI1)≧mi,则挖掘出英文特征词加权强关联规则ftwI2→ftwI1,所述的mc为最小置信度阈值,mi为最小兴趣度阈值;
(8.1.4)循环进行步骤(8.1.1)至(8.1.3),直到加权i_频繁项集ftwIi的真子集集合中每个真子集都被取出一次,而且仅能取出一次,则转入步骤(8.2);
(8.2)循环进行步骤(8.1),当特征词加权频繁项集集合L中的项集都被取出一次,而且仅能取出一次,则挖掘结束。
一种适用于上述基于词间加权关联模式的越英跨语言文本检索方法的检索系统,包括如下4个模块和3个数据库:
机器翻译模块:该模块使用必应机器翻译接口,用于将用户提交的越南语用户查询翻译为英文查询式,以及将最终检索结果英文文档翻译为越南语文档提交给用户;
文本检索模块:用于对译后的英文查询式在英文文档集上进行检索,得到跨语言初检英文文档集;
加权关联模式挖掘模块:用于将前列r篇跨语言初检英文文档提交给用户,由用户对这些文档进行相关性判断并确定初检英文相关文档库,然后,采用加权关联模式挖掘技术对初检英文相关文档库挖掘与查询相关的英文扩展词实现跨语言查询扩展,扩展词和原查询组合成新查询再次检索得到最终检索结果英文文档;
最终结果显示模块:用于将最终检索结果英文文档经机器翻译模块翻译为越南语文档,并将最终检索结果英文文档和最终检索结果越南语文档返回用户;
初检英文相关文档库;
英文特征词加权关联规则库;
英文扩展词库。
上述加权关联模式挖掘模块包括以下5个模块:
初检结果用户相关反馈信息提取模块:用于根据用户对初检英文文档进行的相关性判断确定初检英文文档集,构建用户反馈英文相关文档集;
英文文档预处理模块:用于将用户反馈英文相关文档集进行去停用词、词干提取、计算特征词权值和提取特征词的预处理,构建初检英文相关文档库;
加权关联规则挖掘模块:用于对初检英文相关文档库进行英文特征词加权关联规则挖掘,主要挖掘含有原查询词项的加权特征词项频繁项集和关联规则模式,构建英文特征词加权关联规则库;
扩展词生成模块:用于从英文特征词加权关联规则库中提取与原查询相关的英文扩展词,构建英文扩展词库;
查询扩展实现模块:用于从英文扩展词库中提取英文扩展词,将扩展词和原查询组合成新查询,再次检索,得到最终检索结果英文文档。
相比于现有技术,本发明的优势在于:
(1)本发明以越南语和英语为研究对象,将加权关联模式挖掘技术和用户相关反馈结合应用于越英跨语言信息检索,提出基于词间加权关联模式的越英跨语言文本检索方法及系统,与单语言英文文本检索基准MB、越英跨语言检索基准CLB和传统的基于伪相关反馈的跨语言信息检索方法CLR_PRF(文献Jianfeng Gao,JianyunNie,Jian Zhang,et al,TREC-9CLIR Experiments at MSRCN.In:Proc.ofthe 9th Text Retrieval Evaluation Conference,2001:343-353.;吴丹,何大庆,王惠临.基于伪相关的跨语言查询扩展.情报学报,2010,29(2):232-239.)比较,本发明方法的检索性能获得了很大的改善和提高,实验结果表明,其检索结果的各项指标值都高于英文单语言检索基准方法MB、越英跨语言检索基准CLB和传统的伪相关跨语言检索方法VE_CLQE_PRF的值,提高幅度最高可以达到119.5%,最低的增幅也达到23.7%。
(2)实验结果表明,本发明提出的基于词间加权关联模式的越英跨语言文本检索方法及系统是有效的,能改善和提高跨语言信息检索性能。其主要原因分析如下:在跨语言信息检索中,查询翻译结果对跨语言检索结果影响较大,常常导致跨语言初检结果质量不如单语言的初检结果,即出现查询主题漂移问题。而将用户点击行为与完全加权关联模式挖掘融合应用到越英跨语言信息检索模型,可以获得与原查询最相关的反馈信息,通过完全加权关联规则挖掘得到与原查询相关的扩展词实现跨语言查询扩展,避免了跨语言检索中存在的严重主题漂移问题,提高了越英跨语言检索性能。
附图说明
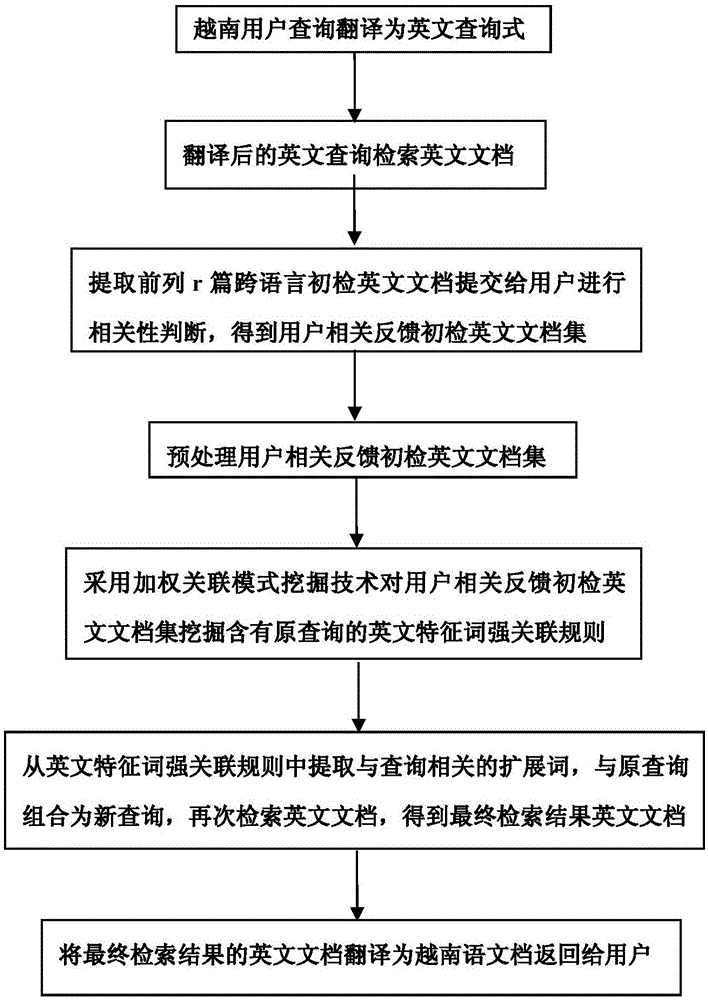
图1为本发明基于词间加权关联模式的越英跨语言文本检索方法的框图。
图2为本发明基于词间加权关联模式的越英跨语言文本检索系统整体流程图。
图3为本发明基于词间加权关联模式的越英跨语言文本检索系统结构框图。
图4为本发明所述的加权关联模式挖掘模块结构框图。
具体实施方式
以下结合实施例及其附图对本发明技术方案作进一步非限制性的详细说明。
一、为了更好地说明本发明的技术方案,下面将本发明涉及的相关概念介绍如下:
假设CLIRdoc={d1,d2,…,dn}是跨语言初检结果的目标语言初检相关文档集,其中,di(1≦i≦n)是目标语言文档集CLIRdoc中的第i篇文档,di={t1,t2,…,tm,…,tp},tm(m=1,2,…,p)称为目标语言特征词项目(Feature-term Item,FTI),简称为特征项,一般是由字、词或词组构成,di中对应的特征项权值集合Wi={wi1,wi2,…,wim,…,wip},wim为第i篇文档di中第m个特征项tm的对应的权值,FTI={t1,t2,…,tk}表示CLIRdoc中全体特征项集合,FTI的各个子集均称为特征项项集(Feature-term Itemsets,ftI),简称项集。对于项集ftI=(ftI1,ftI2),且给出如下基本概念。
定义1特征词加权项集ftwI支持度(Feature-term weighted Itemsets Support,ftwISup)计算公式(周秀梅,黄名选.基于项权值变化的矩阵加权关联规则挖掘[J].计算机应用研究,2015,32(10):2918-2923.)如(1)式所示。
其中,wftwI为完全加权项集ftwI在文档集CLIRdoc中项集权值总和,W为文档集CLIRdoc中所有特征项权值总和,kftwI为项集ftwI中的项目个数(即项集长度)。
定义2加权关联规则条件概率比(Conditional_Probability Increment Ratio,CPIR):条件概率比CPIR是用条件概率和先验概率的比值来表达p(ftwI2/ftwI1)相对p(ftwI2)的递增程度(WU X D,ZHANG C Q,ZHANG S C.Efficient mining of both positive and negative association rules[J].ACM Transactions on Information Systems,2004,22(3):381–405.)。将CPIR模型思想应用于越英跨语言查询扩展领域,给出特征项加权关联规则(Association Rule,AR)ftwI1→ftwI2条件概比(Feature-termAR CPIR,ftARCPIR)计算公式如式(2)所示。
定义3特征项关联规则兴趣度(Feature TermAR Interest,ftARI):兴趣度作为关联模式新度量得到广泛研究和应用,有趣的特征项关联规则(ftwI1→ftwI2)兴趣度计算公式如式(3)所示:
ftARI(ftwI1→ftwI2)=ftwISup(ftwI1)×ftwISup(ftwI1,ftwI2)×(1–ftwISup(ftwI2)) (3)
定义4特征项加权频繁项集:假设最小支持度阈值为ms,若满足:
ftwISup(ftwI1,ftwI2)≧ms,则称特征词项集(ftwI1,ftwI2)为频繁项集。
定义5有趣的特征词强关联规则:假设最小置信度阈值为mc,最小兴趣度阈值为mi,若满足:①特征词项集(ftwI1,ftwI2)是频繁项集,②ftARCPIR(ftwI1→ftwI2)≧mc,③ftARI(ftwI1→ftwI2)≧mi,则称词间关联规则(ftwI1→ftwI2)为有趣的特征词强关联规则。
定义6特征词k_项集权值阈值(k-ItemWeight Threshold,KIWT):特征词k_项集权值阈值是指对包含q_项集ftwIq的后续k_项集ftwIk的权值预测(q<k),记为KIWT(q,k),其计算公式(黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展.软件学报,Vol.20,No.7,July 2009,pp.1854-1865)如式(4)所示。
其中,n为文档集CLIRdoc的总篇数,SC(ftwIq)为特征词q-项集ftwIq在文档集CLIRdoc的支持计数,weighti是指在(ftwIk-ftwIq)项集中前(k-q)个权值最大的项目相应的权值为weight1,weight2,…weightk-q。
定理1设特征词完全加权q-项集ftwIq的权值之和为W(q),包含该q_项集ftwIq的特征词完全加权k_项集权值阈值为KIWT(q,k),如果W(q)<KIWT(q,k),则包含q-项集ftwIq的完全加权k-项集一定是非频繁项集。该定理已在文献(黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展.软件学报,Vol.20,No.7,July 2009,pp.1854-1865)得到了证明。
面向越英跨语言信息检索的支持度-CPIR模型-兴趣度评价框架:
传统的完全加权关联模式挖掘中,普遍都采用支持度-置信度评价架构来评价加权关联规则,这种架构的本质是通过项集在事务数据中发生的先验概率以及关联规则中前件发生时后件发生的条件概率来评价关联模式的有效性。本文提出的面向跨语言查询扩展的支持度-CPIR模型-兴趣度评价架构是在上述传统架构基础上,进一步考虑关联规则中查询前件发生时扩展词后件发生的条件概率相对后件单独发生时后件先验概率的递增程度,同时,还考虑强加权关联规则中的有趣性,原因是:通过传统的评价架构挖掘出的加权强关联规则模式中,还会存在一些用户并不感兴趣的强规则,将这些无趣的强规则剪除后最终得到更有效的加权关联规则模式。
面向越英跨语言信息检索的加权关联模式挖掘剪枝策略:
对于面向跨语言查询扩展的项集加权关联模式挖掘,其最核心问题是挖掘出与原查询相关的扩展词,即最受关注的是含有查询项的项集和关联规则。鉴于此,在挖掘过程中,采用如下的剪枝策略:①当挖掘到2-项集时,剪除不含有查询项的2项集,该剪枝策略可以极大地提高挖掘效率,不会影响其查询扩展效果(黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展.软件学报,Vol.20,No.7,July 2009,pp.1854-1865);②对于每个特征词完全加权候选k_项集(k≧1),将其权值之和W(k)与包含该项集的后续(k+1)_项集权值阈值KIWT(k,k+1)进行比较,根据定理1,若W(k)<KIWT(k,k+1),则剪除该候选k_项集;③对于特征词加权关联规则,将其ftARCPIR值小于最小置信度阈值mc,同时其ftARI值小于最小兴趣度阈值mi的规则剪除。
二、如图1所示,本实施例的基于词间加权关联模式的越英跨语言文本检索方法,包括如下步骤:
(1)将越南语用户查询通过机器翻译模块翻译为英文查询式检索英文文档;机器翻译系统采用必应机器翻译接口,即MicrosoftTranslatorAPI;
(2)提取跨语言初步检索结果前列r篇英文文档提交给用户,让用户对初步检索文档进行相关性判断;
(3)根据用户的相关性判断确定初检英文相关文档,构建用户反馈英文相关文档集,文档集中的文档数设为n;
(4)预处理用户反馈英文相关文档集,即进行去除停用词、英文词干提取、计算特征词权值和提取特征词的预处理操作,构建初检英文相关文档库;
所述特征词权值的计算采用tf-idf方法,其计算公式是:
其中,tfm,n表示特征词tm在文档dn中的出现次数,dfm表示含有特征词tm的文档数量,N表示文档集合中总的文档数量;
(5)扫描初检英文相关文档库,首先计算初检英文相关文档库中所有特征项权值总和W,然后挖掘加权特征词1_候选项集C1,计算C1权值w(C1),统计C1以外的项目的最大权值maxCwi(!C1)和C1的支持计数nc1,ms为最小支持度阈值,计算KIWT(1,2)的值,KIWT(1,2)的计算公式是:KIWT(1,2)=n×1×ms-nc1×maxCwi(!C1);
(6)计算C1的加权支持度ftwISup(C1),如果加权支持度ftwISup(C1)≧ms,则从1_候选项集C1挖掘1_频繁项集L1,并加到特征词加权频繁项集集合L,ftwISup(C1)的计算公式是:
(7)挖掘k_项集,其中所述的k≧2,包括步骤(7.1)至(7.7):
(7.1)比较候选(k-1)_项集Ck-1权值W(Ck-1)和KIWT(k-1,k)值,剪除其W(Ck-1)<KIWT(k-1,k)的候选项集Ck-1;
(7.2)将余下的进行候选(k-1)_项集Ck-1进行Aproiri连接,得到候选k_项集Ck;
(7.3)当k=2时,剪除不含查询项的候选2_项集;
(7.4)扫描初检英文相关文档库,统计Ck以外的项目的最大权值maxCwi(!Ck)和Ck的支持计数nck,计算Ck权值w(Ck)和KIWT(k-1,k)的值,KIWT(k-1,k)的计算公式是:KIWT(k-1,k)=n×k×ms-nck×maxCwi(!Ck);
(7.5)剪除nck为0的候选项集Ck;
(7.6)对余下的候选k_项集Ck,计算Ck支持度ftwISup(Ck),如果ftwISup(Ck)≧ms,则从候选k_项集Ck中挖掘k_频繁项集Lk,并加到特征词加权频繁项集集合L,ms为最小支持度阈值,ftwISup(Ck)的计算公式是:
(7.7)若k大于候选项集长度阈值或者候选k_项集为空集,则挖掘结束,否则,继续循环步骤(7.1)至(7.6);
(8)从特征词加权频繁项集集合L中挖掘含有查询词项的英文特征词加权关联规则,构建英文特征词加权关联规则库;具体方法包括步骤(8.1)至(8.2):
(8.1)从特征词加权频繁项集集合L中提取某一加权i_频繁项集ftwIi,找出ftwIi的所有真子集,进行步骤(8.1.1)至(8.1.4)的操作:
(8.1.1)从ftwIi的真子集集合中任意取出两个真子集ftwI1和ftwI2,当ftwI1∩并且ftwI1∪ftwI2=ftwIi;
(8.1.2)计算规则(ftwI1→ftwI2)以及(ftwI2→ftwI1)的英文特征项关联规则条件概率比ftARCPIR及其兴趣度ftARI值;
ftARCPIR(ftwI1→ftwI2)和ftARCPIR(ftwI2→ftwI1)的计算公式如下:
ftARI(ftwI1→ftwI2)和ftARI(ftwI2→ftwI1)的计算公式如下:
ftARI(ftwI1→ftwI2)=ftwISup(ftwI1)×ftwISup(ftwI1,ftwI2)×(1–ftwISup(ftwI2)),
ftARI(ftwI2→ftwI1)=ftwISup(ftwI2)×ftwISup(ftwI1,ftwI2)×(1–ftwISup(ftwI1)),
其中,ftwISup(ftwI1)为的加权频繁项集ftwI1支持度,ftwISup(ftwI2)为的加权频繁项集ftwI2支持度,ftwISup(ftwI1,ftwI2)为的加权频繁项集(ftwI1,ftwI2)支持度;
(8.1.3)如果ftARCPIR(ftwI1→ftwI2)≧mc,并且ftARI(ftwI1→ftwI2)≧mi,则挖掘出英文特征词加权强关联规则ftwI1→ftwI2;若ftARCPIR(ftwI2→ftwI1)≧mc,并且ftARI(ftwI2→ftwI1)≧mi,则挖掘出英文特征词加权强关联规则ftwI2→ftwI1,所述的mc为最小置信度阈值,mi为最小兴趣度阈值;
(8.1.4)循环进行步骤(8.1.1)至(8.1.3),直到加权i_频繁项集ftwIi的真子集集合中每个真子集都被取出一次,而且仅能取出一次,则转入步骤(8.2);
(8.2)循环进行步骤(8.1),当特征词加权频繁项集集合L中的项集都被取出一次,而且仅能取出一次,则挖掘结束;
(9)从英文特征词加权关联规则库中提取与原查询相关的英文扩展词,构建英文扩展词库;
(10)将原查询和扩展词组合成新查询再次检索英文文档,得到最终检索结果英文文档;
(11)将最终检索结果英文文档经机器翻译模块翻译为越南语文档,最后将最终检索结果英文文档和最终检索结果越南语文档返回给用户。
三、如图2至4所示,适用于本实施例基于词间加权关联模式的越英跨语言文本检索方法的检索系统,包括如下4个模块和3个数据库:
机器翻译模块:该模块使用必应机器翻译接口,即Microsoft Translator API,用于将用户提交的越南语用户查询翻译为英文查询式,以及将最终检索结果英文文档翻译为越南语文档提交给用户;
文本检索模块:用于对译后的英文查询式在英文文档集上进行检索,得到跨语言初检英文文档集;
加权关联模式挖掘模块:用于将前列r篇跨语言初检英文文档提交给用户,由用户对这些文档进行相关性判断并确定初检英文相关文档库,然后,采用加权关联模式挖掘技术对初检英文相关文档库挖掘与查询相关的英文扩展词实现跨语言查询扩展,扩展词和原查询组合成新查询再次检索得到最终检索结果英文文档;
最终结果显示模块:用于将最终检索结果英文文档经机器翻译模块翻译为越南语文档,并将最终检索结果英文文档和最终检索结果越南语文档返回用户;
初检英文相关文档库;
英文特征词加权关联规则库;
英文扩展词库。
其中,所述加权关联模式挖掘模块包括以下5个模块:
初检结果用户相关反馈信息提取模块:用于根据用户对初检英文文档进行的相关性判断确定初检英文文档集,构建用户反馈英文相关文档集;
英文文档预处理模块:用于将用户反馈英文相关文档集进行去停用词、词干提取、计算特征词权值和提取特征词的预处理,构建初检英文相关文档库;
加权关联规则挖掘模块:用于对初检英文相关文档库进行英文特征词加权关联规则挖掘,主要挖掘含有原查询词项的加权特征词项频繁项集和关联规则模式,构建英文特征词加权关联规则库;
扩展词生成模块:用于从英文特征词加权关联规则库中提取与原查询相关的英文扩展词,构建英文扩展词库;
查询扩展实现模块:用于从英文扩展词库中提取英文扩展词,将扩展词和原查询组合成新查询,再次检索,得到最终检索结果英文文档。
四、结合本发明的技术方案,下面通过实验对本发明的有益效果做进一步说明:
编写了本发明方法及系统的源程序进行本发明的实验。采用日本情报信息研究所主办的多国语言处理国际评测会议上的跨语言信息检索标准数据测试集NTCIR-5CLIR的英文语料作为本实验语料,来源于Mainichi Daily News(9.9MB)和Korea Times(25.3MB)新闻媒体2000-2001年新闻文本,共计30530篇英文文本信息。本实验的实验语料是NTCIR-5 CLIR的英文语料中Mainichi Daily News2000年新闻文本,共6608篇英文文本信息。
NTCIR-5提供了完整的评测体系,有查询集、文档测试集和结果集。其中,查询集有50个查询主题,每个查询主题分有TITLE(以名词和名词性短语简要描述查询主题,属于短查询)、DESC(以句子形式简要描述查询主题,属于长查询)、NARR(查询主题的详细说明,指出哪些内容是相关、部分相关或者不相关)和CONC(查询主题相关的关键词表)等4种类型,本实验采用查询主题的TITLE部分。此外,结果集有2种评价标准:Rigid标准---高度相关,相关,Relax标准---高度相关、相关和部分相关。
本文实验中,英文语料的预处理是:词干提取、去除停用词和提取特征词,构建基于向量空间模型的文本信息库、文本特征词索引库和特征词项目库,英文文档词干提取程序采用Porter(见http://tartarus.org/~martin/PorterStemmer)程序,所用的机器翻译系统接口是Microsoft Translator API。
为了进行本文印尼中跨语言信息检索模型的实验,邀请翻译机构专业翻译人士将NTCIR-5CLIR中文版50个查询主题人工翻译为越南语查询。
本实验中,英文文扩展词的权值设置方法是:将加权关联规则的置信度作为扩展词的权值,当多个关联规则含有重复相同的查询项时,取其置信度最高者作为该扩展词权值。
实验的评价指标是:平均查准率的均值(Mean Average Precision,MAP)和前5和15个结果的查准率P@5和P@15,实验评测比较基准是:(1)单语言检索基准(Monolingual Baseline,MB):用英文查询直接检索英文文档得到的检索结果。(2)跨语言检索基准(Cross-language Baseline,CLB):指没经任何相关反馈的首次跨语言检索结果,即越南语查询经机器翻译系统翻译后检索英文文档得到的检索结果。(3)传统的基于伪相关反馈的越英跨语言查询算法VE_CLQE_PRF(Vietnamese-English Cross-Language Query expansion Using Pseudo Relevance Feedback)。本实验中,提取跨语言前列初检文档20篇构建初检相关文档集,提取前列权值(降序排列)的20个特征词为扩展词。
本发明实验参数设置:跨语言英文初检文档前列文档数是50。本文实验中,初检前列50篇中含有已知结果集中的相关文档视为用户相关反馈信息,并提取出来构建用户初检相关文档集。
基准方法实验结果:
提交NTCIR-5CLIR的50个查询主题的TITLE部分进行英文单语言检索、越英跨语言检索和传统的基于伪相关反馈的越英跨语言检索,即运行基准算法MB、CLB和VE_CLQE_PRF,得到基准实验结果如表1所示。
表1:
本发明与基准方法的检索性能比较:
采用NTCIR-5CLIR的50个查询主题的TITLE查询,对支持度变化和置信度变化时两种情况进行检索性能实验,与基准CLB和传统的VE_CLQE_PRF算法,以及单语言检索基准MB进行检索性能比较。实验具体参数如下:n=50,C_length=2,mi=0.0001。支持度变化时实验参数:mc=0.01,ms分别为0.001、0.002、0.003和0.004时得到跨语言检索结果的MAP、P@5和P@15值,取平均值作为其在表2的值;置信度变化时实验参数:ms=0.001,mc分别为0.01、0.04、0.06、0.08和0.1时得到MAP、P@5和P@15值,取平均值作为其表3的值。支持度阈值变化时检索结果的MAP、P@5和P@15值如表2所示,置信度阈值变化时检索结果的MAP、P@5和P@15值如表3所示。
表2:
表3
表2和表3的实验结果可知,当加权支持度阈值变化或者置信度阈值变化时,本发明方法检索结果的各项指标值都高于英文单语言检索基准方法MB、越英跨语言检索基准CLB和传统的伪相关跨语言检索方法VE_CLQE_PRF的值,提高幅度最高可以达到119.5%,最低的增幅也达到23.7%。
综上所述,本发明方法的跨语言检索性能比对比方法的好,具有较好的推广应用价值。
- 还没有人留言评论。精彩留言会获得点赞!