一种数据处理装置及数据处理方法与流程
技术领域
本发明涉及一种数据处理装置及数据处理方法。
背景技术:
目前的计算机模型都是图灵机模型。图灵机的基本功能是:图灵机每次操作是让针头向左或向右每次移动一个格子,并将格子中的数据擦掉,写上自己所需要的数据。从拓扑结构来看,图灵机每运行一次的拓扑结构是长度为1的路,即为这簇图集中某图一条边,可见,图灵机模型是在一次图灵运算中,仅处理一对相邻的数据,因此其处理众多的大数据的效率低、结果不准确,特别是在解决众多NP-完全问题时,该问题更为突出。
在社会需求方面,诸如任务规划问题、船迹规划问题,调度问题等,特别是密码分析问题一直是我国的重点研究领域。目前几乎所有的密码系统都是基于当今图灵机模型的电子计算机来设计的,由于图灵机模型下的电子计算机能力所限,即使采用当今最快速度的巨型计算机也无法撼动现有的密码体系。
目前,提出了仿生计算(人工神经网络、进化计算、PSO计算等)、光计算、量子计算及生物计算等。而目前所有的仿生计算均依靠电子计算机来实现;光计算的计算模型就是图灵机模型,但实现的材料是光器件,因此,很难超越当今的电子计算机;量子计算在处理NP完全问题时的最好结果是:若在图灵机下算法复杂度是n,则量子计算可将复杂度降低为这就是说:量子计算模型实际上仍没有超越图灵机模型。
可见,目前的数据计算均无法高效、准确的解决NP完全问题。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的数据处理装置及数据处理方法。
第一方面,本发明提供一种数据处理装置,所述装置包括:处理指令输入模块、控制器、第一可控开关、第二可控开关、检测器、第一容器、第二容器和第三容器;
其中,所述第一容器用于放置第一反应物,第二容器用于放置第二反应物,第三容器用于放置使所述第一反应物和第二反应物反应的反应介质,所述检测器的检测端与所述第三容器对应设置;所述处理指令输入模块连接所述控制器,所述第一容器和第二容器均与所述第三容器连通,在所述第一容器和第三容器的连接通路上设置所述第一可控开关,在所述第二容器和第三容器的连接通路上设置所述第二可控开关,所述控制器分别连接所述第一可控开关和所述第二可控开关,所述控制器还连接所述检测器;
所述处理指令输入模块,用于向所述控制器输入处理指令;
所述第一可控开关,用于根据所述控制器发送的第一打开控制指令打开,以使所述第一容器中预先存储的第一反应物进入所述第三容器;所述第一反应物为根据待处理数据以及所述待处理数据之间的连接关系制作的;
所述第二可控开关,用于根据所述控制器发送的第二打开控制指令打开,以使所述第二容器内预先存储的第二反应物进入所述第三容器中与所述第一反应物在所述第三容器中预先存储的反应介质的作用下反应生成聚合体;所述第二反应物为根据所述第一反应物制作的,所述第二反应物与所述第一反应物匹配;
所述检测器,用于根据所述控制器发送的检测指令对所述聚合体进行检测,以获得检测结果,并将所述检测结果发送给所述控制器;
所述控制器,用于根据所述处理指令,向所述第一可控开关发送所述第一打开控制指令、向所述第二可控开关发送所述第二打开控制指令、在向所述第一可控开关发送第一打开控制指令或向所述第二可控开关发送所述第二打开控制指令达到预设时间时,向所述检测器发送所述检测指令,以及,在接收到所述检测器发送的所述检测结果时,根据所述检测结果确定聚合体是否为处理结果。
优选的,所述装置还包括:数据获取装置和反应物制作装置;
所述数据获取装置和所述反应物制作装置均与所述控制器连接;
所述数据获取装置,用于获取待处理数据,并将所述待处理数据发送给所述控制器;
所述控制器,用于根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令;
所述反应物制作装置,用于根据所述控制指令制作第一反应物和所述第二反应物。
优选的,所述第一反应物包括纳米颗粒和连接在所述纳米颗粒上的多种DNA单链,所述第一反应物的多种DNA单链中的每种DNA单链设置在所述第一反应物的纳米颗粒的同一连通区域上;
所述第二反应物包括纳米颗粒和连接在所述纳米颗粒上的多种DNA单链,所述第二反应物的多种DNA单链中的每种DNA单链设置在所述第二反应物的纳米颗粒的同一连通区域上;
所述多种DNA单链为具有多种DNA序列的DNA单链。
优选的,所述反应介质为聚合酶。
优选的,所述第三容器为PE容器或玻璃容器。
优选的,所述检测器为原子力显微镜AFM或扫描电镜。
第二方面,本发明还提供一种基于所述数据处理装置的数据处理方法,包括:
所述处理指令输入模块向所述控制器输入处理指令;
所述控制器根据所述处理指令,向所述第一可控开关发送第一打开控制指令,并向所述第二可控开关发送第二打开控制指令;
所述第一可控开关根据所述第一打开控制指令打开,以使所述第一容器中预先存储的第一反应物进入所述第三容器;所述第一反应物为根据待处理数据以及所述待处理数据之间的连接关系制作的;
所述第二可控开关根据所述第二打开控制指令打开,以使所述第二容器内预先存储的第二反应物进入所述第三容器中与所述第一反应物在所述第三容器中预先存储的反应介质的作用下反应生成聚合体;所述第二反应物为根据所述第一反应物制作的,所述第二反应物与所述第一反应物匹配;
所述控制器在向所述第一可控开关发送第一打开控制指令或向所述第二可控开关发送第二打开控制指令达到预设时间时,向所述检测器发送检测指令;
所述检测器根据所述检测指令对所述聚合体进行检测,以获得检测结果,并将所述检测结果发送给所述控制器;
所述控制器在接收到所述检测器发送的检测结果时,根据所述检测结果确定聚合体是否为处理结果。
优选的,所述处理指令输入模块向所述控制器输入处理指令之前,所述方法还包括:
所述数据获取装置获取待处理数据,并将所述待处理数据发送给所述控制器;
所述控制器根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令;
所述反应物制作装置根据所述控制指令制作第一反应物和所述第二反应物。
优选的,所述控制器根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令,包括:
所述控制器将所述待处理数据中的每个数据作为顶点、所述待处理数据之间的连接关系作无向边构建简单无向图;
获取所述简单无向图中任一顶点的顶点覆盖集的二长路并集;
根据所述顶点覆盖集的二长路并集向所述反应物制作装置发送控制指令。
优选的,所述预设时间为10-15微秒。
由上述技术方案可知,在本发明的一次处理中,基于放置模式为空间自由放置模式的第一反应物,在第二反应物和第一反应物反应时,第二反应物可和任意一对第一反应物直接进行信息处理,只需要一次运算即可求出问题的全部解,相对于目前的图灵机模式的只处理相邻数据的问题的处理模式,处理效率高,且得到的结果更全面和准确。
附图说明
图1为本发明一实施例提供的数据处理装置的结构示意图;
图2a为本发明的数据的结构示意图:
图2b为本发明的数据胞的结构示意图;
图3为本发明数据处理过程的示意图;
图4为本发明一实施例提供的数据处理方法的流程图;
图5a为以vi为中心的二长路构成的并集的示意图;
图5b为一个8阶图;
图5c和图5d为利用本发明的方法求图5b中的8阶图的Hamilton圈的两个真解。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图1示出了本发明一实施例提供的一种数据处理装置的结构示意图。
如图1所示,本实施例的一种数据处理装置,所述装置包括:处理指令输入模块11、控制器12、第一可控开关17、第二可控开关18、检测器16、第一容器13、第二容器14和第三容器15;
其中,所述第一容器13用于放置第一反应物,第二容器14用于放置第二反应物,第三容器15用于放置使所述第一反应物和第二反应物反应的反应介质,所述检测器16的检测端与所述第三容器15对应设置;所述处理指令输入模块11连接所述控制器12,所述第一容器13和第二容器14均与所述第三容器15连通,在所述第一容器13和第三容器15的连接通路上设置所述第一可控开关17,在所述第二容器14和第三容器15的连接通路上设置所述第二可控开关18,所述控制器12分别连接所述第一可控开关17和所述第二可控开关18,所述控制器12还连接所述检测器16;
所述处理指令输入模块11,用于向所述控制器12输入处理指令;
所述第一可控开关17,用于根据所述控制器12发送的第一打开控制指令打开,以使所述第一容器13中预先存储的第一反应物进入所述第三容器15;所述第一反应物为根据待处理数据以及所述待处理数据之间的连接关系制作的;
所述第二可控开关18,用于根据所述控制器12发送的第二打开控制指令打开,以使所述第二容器14内预先存储的第二反应物进入所述第三容器15中与所述第一反应物在所述第三容器15中预先存储的反应介质的作用下反应生成聚合体;所述第二反应物为根据所述第一反应物制作的,所述第二反应物与所述第一反应物匹配;
所述检测器16,用于根据所述控制器12发送的检测指令对所述聚合体进行检测,以获得检测结果,并将所述检测结果发送给所述控制器12;
所述控制器12,用于根据所述处理指令,向所述第一可控开关17发送所述第一打开控制指令、向所述第二可控开关18发送所述第二打开控制指令、在向所述第一可控开关17发送第一打开控制指令或向所述第二可控开关18发送所述第二打开控制指令达到预设时间时,向所述检测器16发送所述检测指令,以及,在接收到所述检测器16发送的所述检测结果时,根据所述检测结果确定聚合体是否为处理结果。
下面介绍上述第一容器13、第二容器14、第三容器15和检测器16。
1、第一容器13(可以称为数据库):
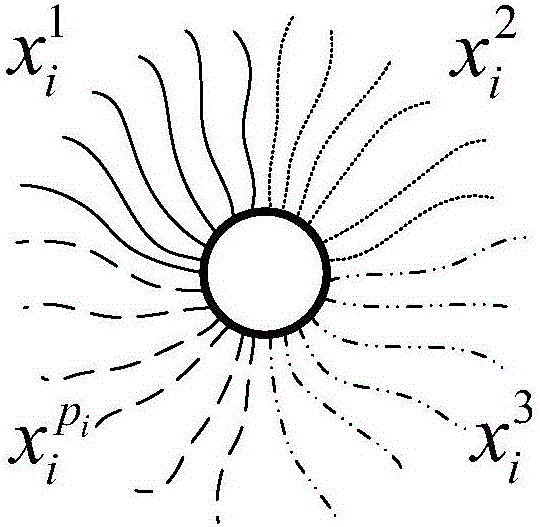
数据库X内可包含由n个非空子集X1,X2,…,Xn,即其中每个子集Xi称为X的一个数据池,该数据池中只存放一种“连接型”的数据xi,如图2a、图2b所示。可表示为X={x1,x2,…,xn}。数据xi由两个部分构成:一个称为数据胞,另一个称为数据纤维。数据胞只有一个;数据纤维有pi(注:pi≠0可以等于n;pi也可不等于n)种:分别记为其中每种数据纤维在该数据中含有海量个相同的拷贝。数据胞与数据纤维相连接,相同种类的数据纤维被连接在同一连通区域。如图2a给出了数据xi的结构示意图:用一小球表示数据胞(如图2b所示),小球的一个区域表示同类的数据纤维(如图2b所示),用不同线型表示pi种不同的数据纤维。
2、第二容器14(可以称为探针库):
探针库内的探针(即本发明的第二反应物)是用于寻找某两个数据(即本发明的第一反应物),并把这两个数据关联起来的“粘合剂”。确切定义如下:
设与是两个数据纤维,与的探针,记作是指能满足下列3个条件的算子(可将此算子称为探针算子):
在计算平台λ中能准确地找到与把此条件称为相邻性;
在计算平台λ中能且只能找到与把此条件称为唯一性;
在找到这两个数据纤维的同时能实施具有某种属性的探针算子(如连接算子、传递算子等),其结果记作把此条件称为可探针性。
若数据库中的两个数据纤维与之间存在探针则称与是可探针的,并把与称为探针的探针对象,同时称数据xl与xt是可探针的;否则,称与是不可探针的,并称xl与xt是不可探针的。设用τ(X′)表示X′中所有可探针数据对对应的探针子集,称为X′的探针子集。
下面,分别给出连接算子的定义与特性。
一个关于与的探针算子称为连接算子,记作是指在计算平台λ上能够找到两个目的数据纤维与并能把这两个纤维连接在一起的探针算子。这个定义可形象地在图3中给予解释。图3中给出了xi与xt数据结构图示;图3中形象地给出了与的连接算子,可视为数据纤维的右半部分与数据纤维的左半部分数据的合成数据的补,该补具有吸附连接与的能力,使得它可以将这两个数据纤维与连接在一起,自然也将数据xi与xt连接在一起,更确切地讲,是通过数据纤维与连接在一起。把此连接算子作用后的结果记为表示数据xi与xt通过它们纤维与之间的算子作用后连接在一起。
把可由连接算子进行信息处理的数据纤维称为连接型数据纤维,并把相应的数据称为连接型数据。在本文中所言的连接型数据通常是指,该数据上的所有数据纤维均为连接型数据纤维。
3、第三容器15(可以称为计算平台)
计算平台,记作λ,把经过探针运算(即在第三容器15中的第一反应物和第二反应物反应的过程)后的两个数据与相应的探针一起的聚合体称为2-数据聚合体。进而,另一个数据与2-数据聚合体中的一个数据可探针,并经过探针运算后的聚合体称为3-数据聚合体,进而,把经过若干次探针运算,且含有m(≥2)个数据的一个聚合体称为m-数据聚合体,或称阶数为m的数据聚合体。通常用M或带有下标的Mi来表示,并用|M|表示M的阶数。特别,将一个数据称为1-数据聚合体。
计算平台λ具有如下2个基本功能:
基本功能1.高聚合性。当一个探针进入计算平台λ上时,该探针总是寻找能产生高阶多探针数据聚合体的两个目的数据纤维与.更细而言,有如下几种选择情况:
若M1,M2,M3是计算平台λ上的3个数据聚合体,M1上含且M2与M3中均含与是可探针的,则当|M2|>|M3|时,计算平台λ下,会选择M1上的与M2中的进行基本探针运算;
若只能在M1与M2这两个数据聚合体上进行基本探针运算,则当|M1|>|M2|时,在会选择在M2中实施基本探针运算;若|M1|=|M2|时,则选择探针数目最多的一个实施基本探针运算;若|M1|=|M2|且它们的探针数目也相同,则任选其一。这里需要注意的是:数据聚合体不能无限的增大,它会受到视为门限值的限制,这是λ的另一个重要特性。
基本功能2.唯一性。对于在计算平台λ上任意阶数≥2的数据聚合体M,同一种数据最多只有一个,且在M的形成过程中,任意一对数据之间最多只有一次基本探针运算;
基本功能3.门限性。计算平台λ上的数据聚合体,经过探针运算后,其阶数需要恰好等于探针运算图G(X′,Y′)的阶数,且基本探针运算的次数需恰等于|E(G(X′,Y′))|.因此,在探针运算中,若两个聚合体的阶数之和大于G(X′,Y′)的阶数,虽然二者之间存在可探针的数据,但在λ控制下,它们不能实施基本探针运算。
本发明的反应过程:分别取出适量的相关数据及适量的相关探针,注入计算平台(即本发明的第三容器15),第一反应物和第二反应物在计算平台(即本发明第三容器15中的反应介质)的作用下,形成多种类型的数据聚合体(即本发明的聚合体)。
计算平台(即本发明第三容器15):可为由PE或玻璃等材料制成的容器(即PE容器或玻璃容器),包含用于使数据与探针自由接触反应的特定溶液(即聚合酶)的容器。
4、检测器16
通过检测技术,只检测出所有与预设的探针运算图(根据待处理数据事先构建的)同构的数据聚合体,即问题的真解(即上述处理结果)。这里要说明的是:目前可在原子力显微镜AFM或扫描电镜来进行检测。
可见,本发明实施例一种数据处理装置的工作原理为:根据待处理数据以及所述待处理数据之间的连接关系,先制作出第一反应物,再根据第一反应物,并将第一反应物存储在第一容器13中,制作出与所述第一反应物匹配的第二反应物,并将第二反应物存储在第二容器14中,并在所述第三容器15中放置使所述第一反应物和第二反应物反应的反应介质。所述处理指令输入模块11向所述控制器12输入处理指令;所述控制器12根据所述处理指令,向所述第一可控开关17发送第一打开控制指令,并向所述第二可控开关18发送第二打开控制指令;所述第一可控开关17根据所述第一打开控制指令打开,则所述第一容器13中预先存储的第一反应物进入所述第三容器15;所述第二可控开关18根据所述第二打开控制指令打开,则所述第二容器14内预先存储的第二反应物进入所述第三容器15中与所述第一反应物在所述第三容器15中预先存储的反应介质的作用下反应生成聚合体;所生成的聚合体中包括处理的真解,也包括一些不合理的,因此,所述控制器12在向所述第一可控开关17发送第一打开控制指令或向所述第二可控开关18发送第二打开控制指令达到预设时间(所述预设时间为10-15微秒。)时,向所述检测器16发送检测指令;所述检测器16根据所述检测指令对所述聚合体进行检测,以获得检测结果,并将所述检测结果发送给所述控制器12;所述控制器12在接收到所述检测器16发送的检测结果时,根据所述检测结果确定聚合体是否为处理结果。
由上述论述可见,在本发明的一次处理中,基于放置模式为空间自由放置模式的第一反应物,在第二反应物和第一反应物反应时,第二反应物可和任意一对第一反应物直接进行信息处理,只需要一次运算即可求出问题的全部解,相对于目前的图灵机模式的只处理相邻数据的问题的处理模式,处理效率高,且得到的结果更全面和准确。本发明适合于处理诸如SAT问题、Hamilton问题、图的顶点着色等NP完全问题。
作为一种优选实施例,所述装置还包括:数据获取装置和反应物制作装置(数据获取装置和反应物制作装置在图中均未示出);
所述数据获取装置和所述反应物制作装置均与所述控制器12连接;
所述数据获取装置,用于获取待处理数据,并将所述待处理数据发送给所述控制器12;
所述控制器12,用于根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令;
所述反应物制作装置,用于根据所述控制指令制作第一反应物和所述第二反应物。
作为一种优选实施例,所述第一反应物包括纳米颗粒和连接在所述纳米颗粒上的多种DNA单链,所述第一反应物的多种DNA单链中的每种DNA单链设置在所述第一反应物的纳米颗粒的同一连通区域上;
所述第二反应物包括纳米颗粒和连接在所述纳米颗粒上的多种DNA单链,所述第二反应物的多种DNA单链中的每种DNA单链设置在所述第二反应物的纳米颗粒的同一连通区域上;
所述多种DNA单链为具有多种DNA序列的DNA单链。
下面详细介绍本实施例。
采用本实施例制作的第一反应物是以纳米颗粒作为数据胞,以DNA单链作为数据纤维所构成的数据。这种数据可以形象地称为“小星星”。
数据的制作方法是:根据该数据上所带数据纤维数pi,将纳米颗粒分成pi个大致相等的连通区域;然后在每个连通区域上连接该连通区域可容纳的对应数据纤维种类的最大量,即DNA序列。实际进行探针运算(即本发明处理)时根据需要的数据量(数据量的确定方法将在下文的数据处理方法中详细介绍)制作相应数量的纳米颗粒作为数据胞,并对不同种类的数据纤维对应的DNA序列进行编码与合成。进而,将DNA单链(数据纤维)嵌入在相应的纳米颗粒(即数据胞)上。其中DNA单链的设计为一半用于与纳米颗粒通过生化反应交联,一半作为数据纤维用于等待被探针(即本发明的第二反应物)识别。
设分别是数据xi与xt上的两个纤维,若这两个纤维可探针(即可与第二反应物反应),其探针记作是用a与b各一半DNA单链(均未与纳米颗粒相连接的那一半)连接的DNA序列之补链构成。
本发明的反应过程:分别取出适量的相关数据及适量的相关探针,注入计算平台(即本发明的第三容器15),经过DNA单链分子间的特异性杂交反应,在计算平台(即本发明第三容器15中的反应介质)的作用下,形成多种类型的数据聚合体(即本发明的聚合体)。
检测器16:通过检测技术,只检测出所有与预设的探针运算图(根据待处理数据事先构建的)同构的数据聚合体,即问题的真解(即上述处理结果)。这里要说明的是:目前可通过原子力显微镜AFM或扫描电镜来进行检测。
在本实施例中,本发明采用生物学方法制作第一反应物和第二反应物。作为数据的DNA分子为纳米级,以及特异性杂交时的巨大并行性使得在较短时间内求解一定规模的NP-完全问题成为可能。
图4为本发明一实施例提供的数据处理方法的流程图。
如图4所示,一种基于所述的数据处理方法,包括:
S41、所述处理指令输入模块向所述控制器输入处理指令;
S42、所述控制器根据所述处理指令,向所述第一可控开关发送第一打开控制指令,并向所述第二可控开关发送第二打开控制指令;
S43、所述第一可控开关根据所述第一打开控制指令打开,以使所述第一容器中预先存储的第一反应物进入所述第三容器;所述第一反应物为根据待处理数据以及所述待处理数据之间的连接关系制作的;
S44、所述第二可控开关根据所述第二打开控制指令打开,以使所述第二容器内预先存储的第二反应物进入所述第三容器中与所述第一反应物在所述第三容器中预先存储的反应介质的作用下反应生成聚合体;所述第二反应物为根据所述第一反应物制作的,所述第二反应物与所述第一反应物匹配;
S45、所述控制器在向所述第一可控开关发送第一打开控制指令或向所述第二可控开关发送第二打开控制指令达到预设时间时,向所述检测器发送检测指令;
S46、所述检测器根据所述检测指令对所述聚合体进行检测,以获得检测结果,并将所述检测结果发送给所述控制器;
S47、所述控制器在接收到所述检测器发送的检测结果时,根据所述检测结果确定聚合体是否为处理结果。
由于上述数据处理装置中已经详细介绍了本发明的数据处理流程,此处不再详述。
根据上述数据处理装置的介绍可知,在本发明的一次处理中,第一反应物的放置模式为空间自由放置模式,因此,在第二反应物和第一反应物反应时,第二反应物可和任意一对第一反应物直接进行信息处理,解决了传统图灵机模型在每次进行信息处理时,只处理相邻数据的问题,本发明在处理诸如SAT问题、Hamilton问题、图的顶点着色等NP完全问题时只需要一次运算即可求出问题的全部解,相对于目前的图灵机模式的处理模式,处理效率高,且得到的结果更全面和准确。
作为一种优选实施例,所述步骤S41之前,所述方法还包括:
所述数据获取装置获取待处理数据,并将所述待处理数据发送给所述控制器;
所述控制器根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令;
所述反应物制作装置根据所述控制指令制作第一反应物和所述第二反应物。
可以理解的是,还可以通过实验制作第一反应物和所述第二反应物,具体制作过程不再详述。
所述控制器根据所述待处理数据以及所述待处理数据之间的连接关系,向所述反应物制作装置发送控制指令,包括:
所述控制器将所述待处理数据中的每个数据作为顶点、所述待处理数据之间的连接关系作无向边构建简单无向图;
获取所述简单无向图中任一顶点的顶点覆盖集的二长路并集;
根据所述顶点覆盖集的二长路并集向所述反应物制作装置发送控制指令。
下面通过一个具体例子对本发明进行详细说明。
要解决的问题:一个旅行售货员想去访问若干城镇,他要选定一条从驻地出发,对每个城镇恰好进行一次访问,最后回到驻地。这个旅行售货员问题用图论术语来描述,就是在一个完全图中,找一个Hamilton圈。
下面,将此抽象成一个数学问题,通过本发明的处理方法进行处理。
设G是简单无向图,V(G)与E(G)分别表示G的顶点集和边集。令V(G)={v1,v2,…,vn},Γ(vi)表示vi的邻域,即与vi相邻的顶点的集合,E(vi)={vivj|vivj∈E(G);i≠j;i,j=1,2,…,n}表示与vi相关联的所有边构成的集合;E2(vi)表示vi为中心的二长路构成并集(如图5a),即
在E2(vi)基础上构建连接型探针机的数据库X(即制作的第二容器14)为
其中每个数据xilj上恰有两个数据纤维,分别记作
现在数据库X(即本发明的第一容器13)的基础上构建探针库Y(即本发明的第二容器14)。总约定图G的阶数≥5.分两种情况讨论:
情况1:vi与vt不相邻。数据库X中任意两个数据xilj与xtab存在探针当且仅当
|{i,l,j}∩{t,a,b}|=|{l,j}∩{a,b}|=1 (1)
此式意味着,i≠t,a,b,t≠l,j且{l,j}∩{a,b}恰有一个数。
情况2:vi与vt相邻,则数据xilj与xtab之间存在探针当且仅当下列条件之一成立:
①|{i,j,l}∩{t,a,b}|=|{j,l}∩{a,b}|=1;
t∈{l,j},i∈{a,b},且|{l,j}∩{a,b}|=0。
用探针机模型求解Hamilton圈时,并不需要把每个顶点vi的二长路集E2(vi)作为数据库子集,只需将G中的一个顶点覆盖集的二长路并集作为数据库即可,当然,最小覆盖集是最优的。
我们将索要解决的旅行售货员问题实例化,以8个城镇为例,将每一个城镇看作一个点,任两个城镇之间有通路就在对应的两个点之间连边,于是,得到图5b中所示的8阶图。所述8阶图包括v1、v2、v3、v4、v5、v6、v7和v88个顶点。
下面,以此为例说明使用连接型探针机模型求解Hamilton圈问题的方法步骤。
步骤1、构建数据库(数据库中包括第一反应物,该步骤可理解为制作第一反应物的步骤):
易见,{x1,x2,x3,x4,x5}是该图一个最小顶点覆盖集,故数据库为
X=E2(v1)∪E2(v2)∪E2(v3)∪E2(v4)∪E2(v5)
其中E2(v1)={x174,x178,x176,x148,x146,x186},E2(v2)={x268},E2(v3)={x358},E2(v4)={x458,x451,x457,x481,x487,x417},E2(v5)={x534,x537,x547},共有17个数据,因此,有34个数据纤维,每个数据上的数据纤维分别为:
步骤2、构建探针库(探针库中包括第二反应物,该步骤可理解为制作第二反应物的步骤)
由34个数据纤维,构造相应的子探针库为:
步骤3、施行探针运算(即施行本发明的第一反应物和第二反应物反应的步骤)
将第一反应物x178,x176,x148,x146,x186,x268,x358,x458,x451,x457,x481,x487,x417,x534,x537,x547放入计算平台λ(即放入第三容器15),将第二反应物Y12,Y13,Y14,Y15,Y23,Y24,Y34,Y45放入计算平台λ,并施行探针运算τ.在λ与τ的作用下,得到问题的解;
步骤4、检测
利用检测器对上述步骤3中得到的问题的解进行检测,并将检测结果发送给所述控制器,所述控制器根据所述检测结果确定与长为4的圈同构的解为本问题的真解(即处理结果),本实施例问题的真解为图5c和图5d所示的结果。
值得说明的是,问题的真解可能只有一个,也可能含成千上万个,它们的拓扑结构图均与G(X′,Y′)同构,但每个真解对应的顶点赋权值不完全相同,所赋权值就是相应顶点上的数据纤维。在一次探针运算过程中,其基本探针运算的次数恰是这簇图集中所有图的边数之和。正因为探针机底层的并行性,使得众多NP-完全问题在求解时,只需一次探针运算即可。诸如Hamilton图问题、图顶点着色问题,以及3-子集划分问题、SAT问题、TSP问题、最大团与最小独立集问题、顶点覆盖问题、固定工序问题等。
探针机的能力分析:随着数据数n的增大,其信息处理能力剧增。一般而言,一次探针运算处理信息的能力是2q,其中q等于Θ中与G(X′,Y′)同构的所有图的边数之和。这就意味着当n=50时,且每个数据之间均有边相邻时,其处理能力已经可以达到225×49=21225。
本领域普通技术人员可以理解:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!