一种面向对象软件的自动化重构方法与流程
本发明涉及软件质量的改善技术领域,尤其涉及一种面向对象软件的自动化重构方法。
背景技术:
:
在软件开发和维护的过程中,不断变更的需求导致系统的原始设计架构被打破,使得结构越发混乱,代码难以理解,软件的重用和维护也变得越来越困难。软件重构是改善软件质量的一种重要手段,它在不改变软件外部行为特性的情况下,通过调整软件内部结构以提高软件的可理解性、可维护性和可扩展性。然而,软件重构是一项耗时且复杂的代码调整活动,要求软件开发人员对代码整体进行感知,并针对“何处、何时以及如何”进行重构做出复杂的决策。因此,自动化重构技术作为降低重构成本、提高重构效果的重要途径,可为开发人员提供决策的辅助支持,进而降低软件重构难度。
“高内聚、低耦合”是程序开发的重要指导准则,研究表明,该准则不仅可以将软件变化引起的波及效应控制在比较小的范围内,而且能够减少后期软件维护的成本。内聚和耦合性问题能够引起如下的代码坏味道:
(1)依恋情结(Feature Envy):函数对某个类的依赖程度高于对自身所在类的依赖程度;
(2)狎昵关系(Inappropriate Intimacy):两个类的函数调用或属性使用关系过于亲密;
(3)过大类(God Class):类包含的过多的函数和属性,实现了过多功能,导致代码的可理解性,可读性变差。
开发人员可以通过搬移函数或属性到与之依赖关系更紧密的类来去除依赖情结和狎昵关系,通过提炼类重构操作,将大类中功能内聚性高的一部分方法和属性提炼到一个新类中,从而分解类的责任。针对于搬移函数重构操作,Czibula等人在《Clustering Based Adaptive Refactoring》文中基于k-means聚类算法定义了实体与类之间的相似性距离,如果实体与其他类的相似性距离小于其自身类,则认为该实体是搬移操作的对象。Bowman等人利用多目标遗传算法结合耦合性、内聚性度量指标实现搬移函数重构,与其他启发式搜索算法相比,多目标遗传算法在迭代过程中可以修正次优的重构建议。Han等人提出了最大依赖集合的概念,利用其可以自动化识别搬移函数重构建议来最大程度地提高软件系统的可维护性。近期,Bavota等人提出了“Methodbook”的新算法用以移除依恋情结和狎昵关系的坏味道,结合语义和结构相似性度量指标共同评估函数之间的“友谊”,寻找到与每个函数关系最亲密的类,作为搬移重构操作的目标类。Fokaefs等人基于层次聚类算法实现了自动化提炼类重构工具JDeodorant,该工具同时集成了Tsantalis提出的搬移函数重构算法,利用entity placement metric(EP)度量指标评估实体之间的耦合程度,进而以此作为指导原则对大类进行分解。Bavota等人利用最大流最小割算法来分解“God class”,该算法与图论相结合,将语义紧密相关的函数和属性提炼出来形成新类。然而,最大流最小割算法只能够将大类分成两个部分,而在实际应用过程中,“God class”可能同时实现了多于两种功能,因此,利用该算法无法完美的进行分割操作。为了克服这个缺陷,Bavota等人实现了自动化重构工具ARIES,可将大类根据其自身结构,以“高内聚、低耦合”为原则分解为多于两个的新类。
上述算法只能实现单一的重构操作来改善系统的内聚性,且提炼类重构操作均属于半自动化的算法,需要开发人员手动输入需要进行分解的大类,从而进行进一步的分析,具有一定的局限性。
技术实现要素:
:
针对现有技术的缺陷,本发明提供一种面向对象软件的自动化重构方法,从整个软件系统全局内聚性及耦合性角度出发,结合语义相似性、结构相似性和层次聚类算法,同时生成搬移函数、搬移属性和提炼类重构操作建议,对待重构软件系统进行自动化重构,从而提高代码的可理解性、可重用性和可维护性。
本发明提供一种面向对象软件的自动化重构方法,包括以下步骤:
步骤1:以类为节点、以类间依赖关系为边,将待重构软件系统构建为类级多层依赖有向网络模型;
步骤2:进行重构预处理;根据类级多层依赖有向网络模型,将非继承体系类节点与继承体系中的叶子节点提取出来,作为重构的对象;
步骤3:依次合并由非继承体系节点与继承体系中的叶子节点构成的类级网络连通片,并且将每个类级网络连通片转换为同种类型的实体集合,实体包括方法和属性两种类型;
步骤4:分析每个实体集合元素之间的语义和结构耦合关系,得到相应耦合关系网络,并对其加权求和,将实体集合构建成方法级耦合无向网络模型;
语义耦合关系是指抽取每个方法的方法名、变量名及注释构建成该方法的词汇库,根据潜在语义相似性算法,将每个方法转化成对应的语义词汇空间向量,计算向量之间的余弦夹角作为此函数对语义相似性的权值;
结构耦合关系包括共享属性关系、方法调用关系和功能耦合关系;如果两个方法同时使用了一个属性,则它们之间存在共享属性关系;当一个方法调用了另一个方法时,它们具有方法调用关系;若将方法体视为一个功能域,则两个方法在同一个功能域中被执行时,称该方法对具有功能耦合关系;
步骤5:确定待重构软件系统的方法级耦合无向网络中节点间不同类型耦合关系权值的最优系数,为待重构软件系统调节出一组最合适的系数;
步骤6:依次遍历每个方法级网络,根据方法间的耦合强度,对每个方法级网络进行社团划分,从而得到待重构软件系统的新的系统结构;
步骤7:将每个由聚类分析得到的方法社团视为一个类,对比新类与原始的结构,设定保证代码行为的重构前提条件,从而生成搬移函数、搬移属性和提炼类的重构建议;
步骤8:按照生成的搬移函数、搬移属性和提炼类重构建议对待重构软件系统执行重构操作。
进一步地,所述步骤1具体包括如下步骤:
步骤1.1:读取待重构软件系统编译后的jar包,通过扫描分析语法分析树结构,解析出待重构软件系统中类、模块、接口、函数、属性和它们之间的依赖关系,过滤掉编译文件中包含的Java虚拟机中的工具类和方法,只保留待重构软件系统自身的类;
步骤1.2:读取待重构软件系统的源文件,抽取源文件中每个方法的变量名、方法名和注释的语义信息,构建每个方法所对应的词汇库;
步骤1.3:分别构建以类为节点、类继承关系为边和类非继承关系为边的有向网络模型,即类级继承关系有向网络和类非继承关系有向网络,有向网络模型中的网络层次之间的节点一一对应。
进一步地,所述步骤2具体包括如下步骤:
步骤2.1:遍历类级继承关系有向网络模型中的每个节点,记录其中所有入度大于零的类节点,并将其视为继承体系中的非叶子节点;
步骤2.2:在非继承关系有向网络中依次移除继承体系中的非叶子类节点以及与这些类相连接的边,所得的剩余网络只包含非继承体系中的类节点以及继承体系中的叶子节点。
进一步地,所述步骤3具体包括如下步骤:
步骤3.1:依次合并由非继承体系节点与继承体系中的叶子节点构成的类级网络连通片,并且将每个类级网络连通片转换为一个实体(方法和属性)集合;
步骤3.2:将集合中的属性视为实现其自身存取操作的取值方法Getter()及赋值方法Setter(),即将集合中不同类型的元素转化为同种类型。
进一步地,所述步骤4具体包括如下步骤:
步骤4.1:分别建立方法级语义耦合、共享属性、方法调用及功能耦合关系加权无向网络,具体确定方法如下,
步骤4.1.1:确定方法之间的语义耦合权值,得到方法级语义耦合关系网络,根据步骤1.2抽取的每个方法的方法名、变量名和注释,构建成方法的词汇库,根据潜在语义相似性算法,将任意方法mk转化成对应的语义词汇空间向量将方法向量之间的余弦夹角作为此方法对语义相似性的权值,即式(1);
其中,mi和mj分别表示两个方法,SSW(mi,mj)表示方法mi和方法mj之间的语义耦合权值,和分别表示方法mi和mj对应的语义词汇空间向量;
步骤4.1.2:确定方法之间的共享属性耦合权值,即式(3),得到方法级共享属性关系网络;
其中,SAW(mi,mj)表示方法mi和mj之间的共享属性耦合权值,Ai和Aj分别表示方法mi和mj使用的属性集合;
步骤4.1.3:确定方法之间的方法调用耦合权值,即式(3),得到方法级方法调用关系网络;
MIW(mi,mj)=max(MIWij,MIWji) (3)
其中,MIW(mi,mj)表示方法mi和mj之间的方法调用耦合权值,MIW(mi,mj)为MIWij与MIWji的最大值;MIWij表示方法mi调用mj的权值,如式(4)所示,MIWij等于I(mi,mj)与方法mj在软件系统中被调用的总次数之比,MIWji表示方法mj调用mi的权值;I(mi,mj)表示方法mi调用方法mj的次数,I(mk,mj)表示方法mi调用方法mj的次数,n表示系统中的方法总数;
步骤4.1.4:确定方法之间的方法功能耦合权值,即式(5),得到方法级功能耦合关系网络;
其中,SEW(mi,mj)表示方法mi和mj之间的方法功能耦合权值,ETij表示方法mi和mj在同一个功能域中执行的次数,ETi和ETj分别表示方法mi和mj执行的总次数;
步骤4.2:将上述步骤4.1得到的方法级语义耦合、共享属性、方法调用及功能耦合关系网络的耦合权值加权求和,得到每对方法节点之间耦合关系的强度,即边权值,从而得到方法级耦合无向网络模型G=(V,E,Z),其中,V为方法节点集合,E为方法间耦合关系集合,Z为方法间耦合权值矩阵,Z=(zij)V|×|V|,zij为方法间耦合权值矩阵Z的矩阵的i行j列的元素,表示每对方法节点之间的边权值,如式(6)所示;
zij=α×SAW(mi,mj)+β×MIW(mi,mj)+γ×SEW(mi,mj)+η×SSW(mi,mj) (6)
其中,α、β、γ和η分别表示方法级语义耦合、共享属性、方法调用和功能耦合关系网络的耦合权值系数,α+β+γ+η=1。
进一步地,所述步骤5具体包括如下步骤:
步骤5.1:随机选取待重构软件系统中Np对内聚度高于平均值且相互依赖的类对进行合并,Np等于系统中类总数的四分之一;
步骤5.2:将每一个人工合并而成的大类建立成方法级耦合无向网络;
步骤5.3:不断变化步骤4中的耦合权值系数,每一组系数下人工大类进行一次聚类划分操作,通过对比聚类后的结果与原始类结构的差异计算出重构的准确率;Np个人工大类平均准确率最高的一组系数,即为该待重构软件系统的最佳耦合权值系数。
进一步地,所述步骤6具体包括如下步骤:
步骤6.1:初始时,将继承体系叶子节点中调用从其父类继承而来的方法节点或重写父类方法的节点绑定为一个社团,方法级耦合网络中的其余方法节点各自视为一个独立社团;
步骤6.2:根据方法对之间耦合关系的耦合权值确定模块度增益矩阵中每一个元素的值,即
其中,CNi和CNj分别表示两个社团,ΔQij表示合并社团CNi和CNj能够为软件系统带来的模块度增益值,W表示方法级耦合无向网络中所有边权值之和,Si和Sj分别表示连接社团CNi和CNj内所有节点的边权值之和,Sin(CNi,CNj)表示连接社团CNi和社团CNj之间所有边的权值之和;
步骤6.3:选择模块度增益最大的一对社团CNp及CNq进行合并,合并为社团CNp,并删除模块度增益矩阵中对应的第q行和第q列,同时更新与合并社团CNp关联的模块度增益值;
步骤6.4:判断模块度增益矩阵中的最大值是否小于或等于零,若否,则重复执行步骤6.3,若是,则合并操作停止,此时所得的社团结构即为最优划分。
由上述技术方案可知,本发明的有益效果在于:本发明提供的一种面向对象软件的自动化重构方法,将待测软件非继承体系中的类节点与继承体系中的叶子节点合并起来,结合语义耦合度量与结构耦合度量方法,将合并的类级连通片建立为方法级加权无向网络同时,为待重构的软件系统定制的最佳方法间耦合权重系数的方法,能获得最佳重构效果;为保证代码行为不变,设定重构的一系列前提条件,利用层次聚类算法得到使得系统模块度增量最大的类划分方式;在通过对比重构前后的社团结构差异,自动化地生成搬移函数、搬移属性及提炼类的多种类型的重构建议,提高了系统的内聚性,同时有益于系统的可理解性、可重用性和可维护性。
附图说明:
图1为本发明实施例提供的面向对象软件的自动化重构方法流程图;
图2为本发明实施例提供的示例代码所对应的类级多层有向网络模型结构示意图;
图3为本发明实施例提供的步骤6的具体流程图;
图4为本发明实施例提供的示例代码所对应的聚类过程示意图;
图5为本发明实施例提供的示例代码所对应的方法级网络重构结果示意图。
具体实施方式:
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本实施例中以如下面向对象软件的实例代码作为待重构的软件系统,经过面向对象软件的自动化重构方法对其进行重构:
本实施例提供的一种面向对象软件的自动化重构方法,如图1所示,具体包括如下步骤。
步骤1:以类为节点、以类间依赖关系为边,将待重构软件系统抽象构建为类级多层依赖有向网络模型,具体包括如下步骤:
步骤1.1:读取待重构软件系统编译后的iar包,通过扫描分析语法分析树结构,解析出待重构软件系统中类、模块、接口、函数、属性以及它们之间的依赖关系,过滤掉编译文件中包含的Java虚拟机中的工具类及方法,只保留待重构软件系统自身的类;
步骤1.2:读取软件系统的源文件,抽取每个方法的变量名、方法名和注释的语义信息,构建每个方法所对应的词汇库;
步骤1.3:分别构建以类为节点、类继承关系为边以及类非继承关系为边的有向网络模型G=G1∪G2,其中,G1=(V,E1)为非继承关系网络模型,G2=(V,E2)为继承关系网络模型,网络层次之间的节点具有一一对应的关系,其中,V表示方法节点集合,E1表示类间非继承关系集合,E2表示类间继承关系集合。
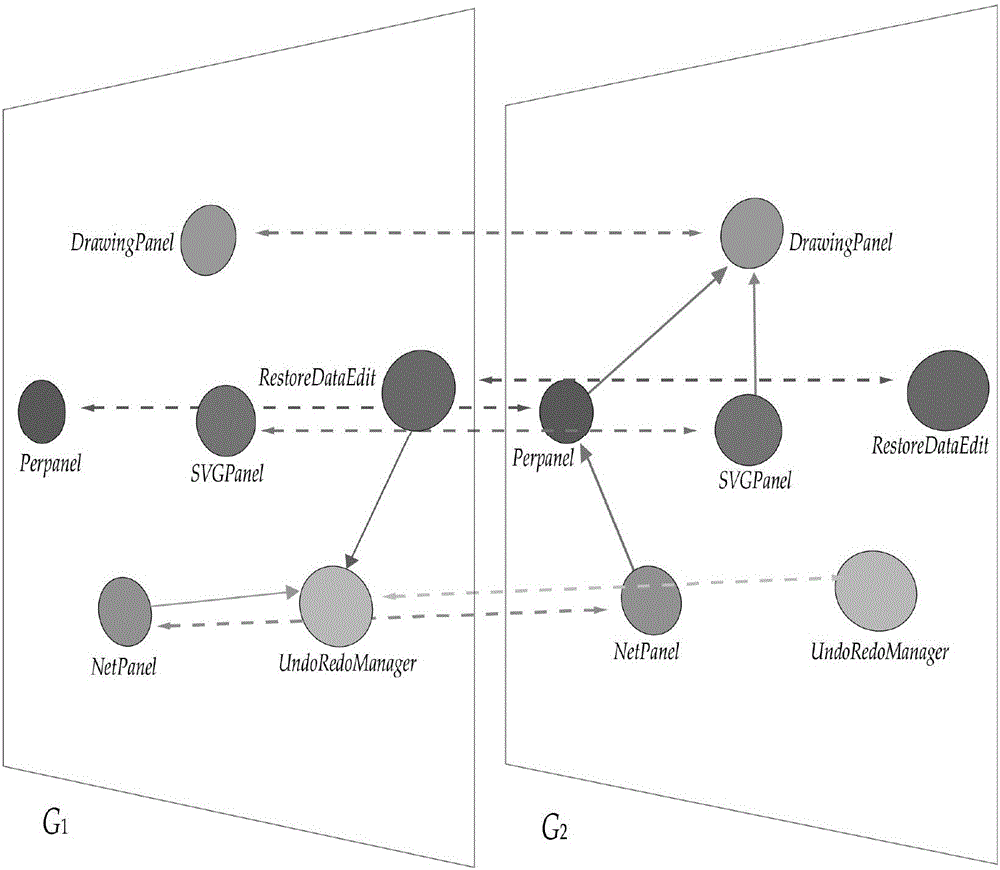
上述的面向对象软件的实例代码中,待重构的软件系统由6个类构成,其中,类DrawingPanel是PerPanel和SVGPanel的父类,类NetPanel继承于PerPanel,而类UndoRedoManager和RestoreDataEdit属于非继承体系,并且类NetPanel和PerPanel依赖于类UndoRedoManager,该软件系统对应的类级多层有向网络模型如图2所示。
步骤2:进行重构的预处理操作,根据类级多层依赖有向网络模型,将非继承体系类节点与继承体系中的叶子节点提取出来,为了保证重构前后代码的行为不发生变化,只对提取出的该部分节点进行重构,具体包括如下步骤:
步骤2.1:遍历类级继承关系网络模型G2中的每个节点,记录其中所有入度大于零的类CLi,CLi∈V,并将其视为继承体系中的非叶子节点,加入到待删除节点集合VD中;
步骤2.2:在非继承关系有向网络中依次移除继承体系中的非叶子类节点以及与这些类相连接的边ED,所得的剩余网络只包含非继承体系中的类节点以及继承体系中的叶子节点,其中,
步骤3:依次合并由非继承体系节点与继承体系中的叶子节点构成的类级网络连通片,并且将每个类级网络连通片转换为同种类型的实体集合,实体包括方法和属性两种类型,具体包括如下步骤:
步骤3.1:依次合并由非继承体系节点与继承体系中的叶子节点构成的类级网络连通片,并且将每个类级网络连通片转换为一个实体集合;
步骤3.2:将集合中的属性视为实现其自身存取操作的取值方法Getter()及赋值方法Setter()方法,即将集合中不同类型的元素转化为同种类型,将属性元素转化成方法元素。
步骤4:分析每个实体集合元素之间的语义和结构耦合关系网络,并对其加权求和,将实体集合构建成方法级耦合无向网络模型,语义耦合关系是指抽取每个方法的方法名、变量名及注释构建成该方法的词汇库,根据潜在语义相似性算法,将每个方法转化成对应的语义词汇空间向量,计算向量之间的余弦夹角作为此函数对语义相似性的权值,结构耦合关系包括共享属性关系、方法调用关系和功能耦合关系,具体包括以下步骤:
步骤4.1:确定方法之间的语义耦合权值,得到方法级语义耦合关系网络,根据步骤1.2抽取的每个方法的方法名、变量名和注释,构建成方法的词汇库,根据潜在语义相似性算法,将任意方法mk转化成对应的语义词汇空间向量将方法向量之间的余弦夹角作为此方法对语义相似性的权值SSW(mi,mj),如式(1)所示;
其中,mi和mj分别表示两个方法,SSW(mi,mj)表示方法mi和方法mj之间的语义耦合权值,和分别表示方法mi和mj对应的语义词汇空间向量;
步骤4.2:如果两个函数同时使用了一个属性,则它们之间存在共享属性关系,确定方法之间的共享属性耦合权值,如式(2)所示,得到方法级共享属性关系网络;
其中,SAW(mi,mj)表示方法mi和mj之间的共享属性耦合权值,Ai和Aj分别表示方法mi和mj使用的属性集合;
步骤4.3:当一个函数调用了另一个函数时,它们具有函数调用关系,确定方法之间的方法调用耦合权值,如式(3)所示,得到方法级方法调用关系网络;
MIW(mi,mj)=max(MIWij,MIWji) (3)
其中,MIW(mi,mj)表示方法mi和mj之间的方法调用耦合权值,MIW(mi,mj)为MIWij与MIWji的最大值;MIWij表示方法mi调用mj的权值,如式(4)所示,MIWij等于I(mi,mj)与方法mj在软件系统中被调用的总次数之比,MIWji表示方法mj调用mi的权值;I(mi,mj)表示方法mi调用方法mj的次数,I(mk,mj)表示方法mi调用方法mj的次数,n表示系统中的方法总数;
步骤4.4:若将方法体视为一个功能域,则两个方法在同一个功能域中被执行时,称该方法对具有功能耦合关系,确定方法之间的方法功能耦合权值,如式(5)所示,得到方法级功能耦合关系网络;
其中,SEW(mi,mj)表示方法mi和mj之间的方法功能耦合权值,ETij表示方法mi和mj在同一个功能域中执行的次数,ETi和ETj分别表示方法mi和mj执行的总次数;
步骤4.5:将上述步骤4.1至步骤4.4得到的四种方法级关系网络的耦合权值加权求和,得到每对方法节点之间耦合关系的强度,即边权值,从而得到方法级耦合无向网络模型G=(V,E,Z),其中,V为方法节点集合,E为方法间耦合关系集合,Z为方法间耦合权值矩阵,Z=(zij)|V|×|V|,zij为方法间耦合权值矩阵Z的矩阵的i行j列的元素,表示每对方法节点之间的边权值,如式(6)所示;
zij=α×SAW(mi,mj)+β×MIW(mi,mj)+γ×SEW(mi,mj)+η×SSW(mi,mj) (6)
其中,α、β、γ和η分别表示方法级语义耦合、共享属性、方法调用和功能耦合关系网络的耦合权值系数,α+β+γ+η=1。
步骤5:确定待重构软件系统的方法级耦合无向网络中节点间不同类型耦合关系权值的最优系数,具体包括如下步骤:
步骤5.1:随机选取待重构软件系统中50对内聚度高于平均值且相互依赖的类对进行合并;
步骤5.2:将每一个人工合并而成的大类建立成方法级耦合无向网络;这里的人工合成,是指不是系统中本来存在的类,将系统中两个原始类,合并成一个大类,人为制造出一个大类,并且将这个人工大类视为必须要分解的类,进行聚类划分,与未合并前的原始结构进行对比,与原始结构越相近,则划分的准确率越高;
步骤5.3:不断变化步骤4中的四个耦合权值系数,每一组系数下进行一次聚类划分操作,即根据高内聚低耦合,将类进行分解操作,将一个大类分解为若干新类,且保证新类之间的耦合性降低,新类内部内聚性较高,通过对比聚类后的结果与原始类结构的差异计算出重构的准确率;50个人工大类平均准确率最高的一组系数,即为该待重构软件系统的最佳耦合权值系数。
不断变化耦合权值系数的过程为:在满足α+β+γ+η=1的条件下,迭代变化四个耦合权值系数:α∈[0,0.1,...,1]、β∈[0,0.1,...,1-α]、γ∈[0,0.1,...,1-α-β]且η∈[0,0.1,...,1-α-β-γ]。
重构准确率利用文献《An effectiveness measure for software clustering algorithms》中提出的度量值MoJoFM(MoJo eFfectiveness Metric)进行评估,将原始类的结构视为标准分割:
式中,MoJoFM(PAnew,PAori)为度量值,表示重构的准确率,在数值上表示两种不同的社团划分结构之间的差异程度,差异越小,其数值越接近于1,若将原始类的结构视为标准划分,那么重构后社团结构与原始结构越接近,则重构准确率越高;PAnew为聚类分析后的划分结构,PAori为原始类的结构,mno(PAnew,PAori)表示从结构PAnew到标准分割PAori的最小距离,而表示从结构PAnew变换成PAori最大元素搬移次数。
步骤6:依次遍历每个方法级网络,根据方法间的耦合强度,对每个方法级网络进行社团划分,从而得到待重构软件系统的新的系统结构,如图3所示,具体包括如下步骤:
步骤6.1:为保证重构前后代码行为不变,初始时,将继承体系叶子类点中调用从其父类继承而来的方法节点或重写父类方法的节点,即不可分割的方法节点绑定为一个社团,方法级耦合网络中的其余方法节点各自视为一个独立社团;
步骤6.2:根据方法对之间耦合关系的耦合权值确定模块度增益矩阵中每一个元素的值;模块度增益按式(7)确定:
其中,CNi和CNj分别表示两个社团,ΔQij表示合并社团CNi和CNj能够为软件系统带来的模块度增益值,W表示方法级耦合无向网络中所有边权值之和,Si和Sj分别表示连接社团CNi和CNj内所有节点的边权值之和,Sin(CNi,CNj)表示连接社团CNi和社团CNj之间所有边的权值之和;
步骤6.3:选择模块度增益最大的一对社团CNp及CNq进行合并操作,合并为社团CNp,由于社团数目的减少,删除模块度增益矩阵中对应的第q行和第q列,同时更新与合并社团CNp关联的模块度增益值;
步骤6.4:重复执行步骤6.3,直到待重构软件系统中模块度增益矩阵中的最大值小于或等于零时,合并操作停止,此时所得的社团结构即为最优划分,每一个社团代表一个类。模块度增量矩阵中的最大值是一个递减过程,在社区划分过程中,两两合并到最后,结构一定会趋于稳定,即模块度增量的最大值小于等零。
本实施例中,待重构的实例软件系统中,合并其非继承体系的类以及继承体系的叶子节点RestoreDataEdit,NetPanel和UndoRedoManager,建立方法级无向耦合网络后,其聚类划分过程如图4所示,首先将使用从父类super方法的实体在聚类划分之前绑定为一个社团;属性与其自身的Getter()或Setter()方法由于具有较高内聚性,因此在聚类的过程中优先被合并在一起;经过19步合并操作后,最终得到如下4个新类:
类1、RestoreDataEdit(...);oldRestoreData_get_set();addEdit(...);getPresentationName();replaceEdit(...);newRestoreData_get_set();
类2、figure_get_set();redoData(...);redoEdit(...);getlabelsRedo();labelsRedo_get_set();RedoactionPerformed(...);redoProgress(...);redoAction_get_set();getRedoAction();
类3、getlabelsUndo();labelsUndo_get_set();undoOrRedo(...);undoOrRedoInProgress;updateActions(...);UndoactionPerformed(...);undoProgress(...);getUndoAction();undoAction_get_set();undoDrawing(...);undoData(...);UndoDrawing_get_set();
类4、NetPanel(...);addDefaultCreationButtonsTo(...);addCreationButtonsTo(...);strokeDecorationPopupButton;addStrokePlacementButtonTo(...);strokeWidthPopupButton;addStrokeDecorationButtonTo(...)。
步骤7:将每个由聚类分析得到的方法社团视为一个类,对比新类与原始的结构,设定保证代码行为的重构前提条件,从而生成一系列包括搬移函数、搬移属性和提炼类的重构建议。
可视化聚类划分结果如图5所示,本实施例的实例软件系统经重构后,为提高系统的模块度,生成的重构建议为:类UndoRedoManager建议被拆分,内聚度较高的方法集合M={getlabelsRedo(),labelsRedo,RedoactionPerformed(...),redoProgress(...),redoAction,getRedoAction()}共同实现了与“Redo”操作相关的功能,应该提炼为新类UndoRedoManagernew1;而方法RestoreDataEdit.redoData(...),RestoreDataEdit.redoEdit(...)和属性RestoreDataEdit.Figure由于被类UndoRedoManagernew1中的方法所频繁使用,建议搬移到UndoRedoManagernew1中,以去除“Feature Envy”的坏味道;同理,NetPanel.undoDrawing(...),NetPanel.undoData(...)及NetPanel.UndoDrawing建议搬移到与其有更紧密关系的类UndoRedoManagernew2中。
步骤8:按照生成的搬移函数、搬移属性及提炼类重构建议对软件系统执行重构操作。
本实施提供的面向对象软件的自动化重构方法,可以直接应用于面向对象软件系统的自动化重构中,辅助程序员做出复杂的重构决策,从而降低重构难度并提高重构效率。为了便于验证所述方法的可行性和优势,该部分从代码被重构前后的可理解性、可重用性、灵活性、可维护性以及内聚度的度量指标的变化情况进行对比分析。
以开源软件系统JHotDraw 7.0.6、JFreeChart 0.9.7、jEdit 2.7、HSQLDB 1.8.1.4和Jmol 9.0分别为例,对重构方案的有效性进行验证,利用文献《A Hierarchical Model for ObjectOriented Design Quality Assessment》提出的QMOOD模型以及《Identification of Move Method Refactoring Opportunities》提出内聚度指标EP评估系统重构前后的质量变化情况。评价指标的计算方法如下:
Reusability=-0.25×Coupling+0.25×Cohesion+0.5×Messaging+0.5×Design Size (11)
Flexibility=0.25×Encapsultion-0.25×Coupling+0.5×Composition+0.5×Polymorphism (12)
Ma int ainability=ko×1/(LCOM×CBO×WMC×DIT×NOC×RFC) (14)
通过上述的公式(11)至公式(16)的评价指标评价本实施例的重构方法得到的集成测试序列与传统方法得到的结果对比分析,如表1所示。
表1 本实施例得到的集成测试序列与传统方法结果对比分析
其中,指标EP可同时度量软件系统的内聚度和耦合度的值,EP的值等于耦合度与内聚度之比,因此,EP的值越小,重构效果越好。通过对比可发现,利用本实施例提供的面向对象软件的自动化重构方法对待重构软件系统进行重构后,系统的各项综合指标均有一定程度的改善,最为明显的是系统的可维护性,平均增长到重构前的2.4倍。由此可见,本实施例的方法能够提高软件质量,降低软件维护成本,是一种有效提高软件质量的手段。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!