一种面向团体的影响最大化方法与流程
本发明属于信息传播领域,尤其涉及一种面向团体的影响最大化方法。
背景技术:
互联网的快速发展促使形成了一种可观测的社会网络,为研究信息传播,疾病扩散等现象提供了极大的便利,同时在舆情控制、电视营销、疾病预防等应用的驱动下,如何从给定网络中寻找一组有限子集,并根据影响的级联传递,使得该子集的影响最大化的问题受到了广泛的关注。目前关于影响最大化的研究对象主要聚焦于实体点(如个人或博客),通过这些实体点的影响关系,设计相关的算法搜索具有最大影响力的k-点组合。但是,在现实生活中,人们的更加趋向于分析团体(如社区或各类人群)组合的影响力,来对即将实施的行为做出指导。
一个团体的影响力通常视为其内所有“感染”(如采纳谣言或购买产品)点的影响力之和。团体间的影响本质上是团体间点的影响,但在基于团体粒度上的影响最大化分析,导致了点影响关系的不可见,从而使得团体间影响存在不确定性,同时团体作为点的集合可能被多个邻居同时影响并且状态为连续取值,使得在动态模拟团体影响传递时需要建立更加复杂的规则来计算影响大小。所以,在基于团体粒度上的影响最大化分析时,如何表达团体的不确定性影响并描述团体影响传递过程是关键与难点。
技术实现要素:
为了解决上述技术问题,本发明提供了一种面向团体影响最大化方法。通过使用概率关联的形式描述团体影响的不确定性,并通过对团体历史“感染”数据进行统计计算得到团体影响的量值。
本发明所采用的技术方案是:
一种面向团体的影响最大化确定方法,其特征在于,定义团体集M的每一个团体mi对应的点集为mi(x),从每个mi(x)中选择一个点组成点集X,记X={x1,...,x|M|}。在疾病cl下,X中任一点xi的是否被感染认为是cl对xi的不确定性影响造成的,记xi感染cl的概率为pl(xi),未感染cl的概率为1-pl(xi)。
步骤1:设定阈值ε,使用团体集M构造一个以团体为结点的完全图IG*(M,I,W)。然后在概率空间D上计算点集X中任意两个点xi、xj的互信息熵Inf(xi,xj),并根据Inf(xi,xj)和阈值ε阈比较结果选择:
若Inf(xi,xj)<ε,说明xi、xj对应的团体mi、mj不存在关联,则直接从图IG*(M,I,W)中删去边Ii,j。
若Inf(xi,xj)≥ε,则计算xi、xj的条件概率独立程度ind(xi,xj)来判断关联类型:若ind(xi,xj)=0,则xi、xj对应的团体mi、mj不存在直接关联,直接从图IG*(M,I,W)中删除边Ii,j;如果ind(xi,xj)>0,说明xi、xj对应的团体mi、mj存在直接关联,则将图IG*(M,I,W)中的边Ii,j的权值设置为wij=ind(xi,xj)。将删除IG*(M,I,W)中所有无关联的边后得到图记为IG(M,I,W)。X中任意两个点xi、xj的条件概率独立程度的具体计算为:
其中ε为给定的阈值;Inf((xi,xj)|(X-(xi,xj)))为xi和xj关于{X-(xi,xj)}的条件互信息熵。
步骤2:初始化一个空集S作为种子集。对于团体集合M中的每一个团体mi,以S∪mi作为备选种子,计算S∪mi的影响范围σ(S∪mi),选取边际影响收益σ(S∪mi)-σ(S)最大的mi加入S并从团体集合M中删除该团体,重复此过程直到种子集S的大小达到预设的大小k。每个网络中不同k值得到的种子集S的影响范围函数σ(S)的计算为:
其中Rj表示团体mj中受感染的个体的比例;N(j)表示在图IG中和mj直接相连的结点集合;n表示N(j)其中的一个结点;child(j)表示集合N(j)中和S之间存在轨的结点的集合;c表示child(j)其中的一个结点;wcj表示结点c和结点j之间的边Ic,j的权值;λ为设定激活因子。
在上述的一种面向团体的影响最大化确定方法,xi被感染或未感染的定义如下:在将同一团体内的点看作同质时,认为pl(xi)=Hli。对于点集X中的每一个点xi,使用一个二元变量ei来表示其状态,ei=1表示xi的状态为感染,ei=0表示xi的状态为未感染。点集X的一个状态取值为Ex=(x1=e1,…,x|M|=e|M|),计算出X在整个疾病集C下以不同状态取值Ex出现的概率p(X=Ex),从而得到在同质性假设下H上点集状态的完备概率空间D。p(X=Ex)的具体计算为:
其中|C|表示在社会网络中总共发生“疾病”的次数;|M|表示团体集M的大小;pl(xi)表示xi“感染”cl的概率;ei是xi的状态取值。
在上述的一种面向团体的影响最大化确定方法,对于疾病cl的定义为:社会网络中,疾病的每次出现引起一次传播过程,第l次疾病使用cl来表示,并将网络中总共发生的|C|次疾病用集合C={c1…c|C|}表示。当cl∈C传播停止后,网络中由|M|个团体组成的团体集M={m1,...,m|M|}受感染程度记为其中表示团体mi在第l次疾病中被感染的比例,并使用一张|C|×|M|二维表H组织整个历史数据,表中l行第i个元素
在上述的一种面向团体的影响最大化确定方法,所述步骤1中,ε∈(0,1)。
在上述的一种面向团体的影响最大化确定方法,所述步骤2中,λ∈[0,1]。
因此,本发明具有如下优点:本发明通过团体在历史数据上的条件概率独立描述团体的结构化关联,进而根据关联强弱推测其间不确定性影响,并结合团体“感染”程度动态计算团体影响范围,最后使用贪心算法搜索最大影响力的k-团体组合。
附图说明
图1是本发明实施例的流程图。
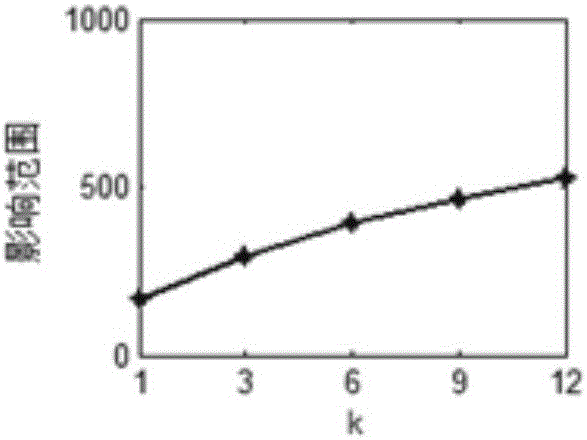
图2a是本发明实施例的网络Net1中k值得到的种子集S的影响范围图。
图2b是本发明实施例的网络Net2中k值得到的种子集S的影响范围图。
图2c是本发明实施例的网络Net3中k值得到的种子集S的影响范围图。
图2d是本发明实施例的网络Dblp中k值得到的种子集S的影响范围图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
在本实施例中,我们使用了四个网络(如表1所示),其中网络Net1,Net2和Net3是采用LFR算法在人工数据集上生成的人工网络,Dblp是一个作者合作网络,其中结点表示作者,边表示两个作者之间存在合作关系。每个网络的历史数据生成过程如下:假定网络中点的传播概率相同,每次“疾病”传播过程中,从测试网络中随机选择1%的点作为“感染”点,并根据IC模型进行影响传播模拟,在传播模拟结束后,记录各个团体的“感染”状态作为一条记录,并生成多条记录作为实验的观测数据集。
表1实验网络
请见图1,本发明包括以下步骤:
步骤1:在社会网络中,“疾病”的每次出现引起一次传播过程,第l次“疾病”使用cl来表示,并将网络中总共发生的|C|次“疾病”用集合C={c1…c|C|}表示。当cl∈C传播停止后,网络中由|M|个团体组成的团体集M={m1,...,m|M|}受“感染”程度记为其中表示团体mi在第l次“疾病”中被“感染”的比例,并使用一张|C|×|M|二维表H组织整个历史数据,表中l行第i个元素
步骤2:设团体集M的每一个团体mi对应的点集为mi(x),从每个mi(x)中选择一个点组成点集X,记X={x1,...,x|M|}。在“疾病”cl下,X中任一点xi的是否被“感染”可认为是cl对xi的不确定性影响造成的,记xi“感染”cl的概率为pl(xi),“未感染”cl的概率为1-pl(xi)。在将同一团体内的点看作同质时(简称为同质性假设),认为pl(xi)=Hli。对于点集X中的每一个点xi,使用一个二元变量ei来表示其状态,ei=1表示xi的状态为“感染”,ei=0表示xi的状态为“未感染”。设点集X的一个状态取值为Ex=(x1=e1,…,x|M|=e|M|),计算出X在整个“疾病”集C下以不同状态取值Ex出现的概率p(X=Ex),从而得到在同质性假设下H上点集状态的完备概率空间D。p(X=Ex)的具体计算为:
其中|C|表示在社会网络中总共发生“疾病”的次数;|M|表示团体集M的大小;pl(xi)表示xi“感染”cl的概率;ei是xi的状态取值。
步骤3:首先使用团体集M构造一个以团体为结点的完全图IG*(M,I,W)。然后在概率空间D上计算点集X中任意两个点xi、xj的互信息熵Inf(xi,xj),如果Inf(xi,xj)小于给定的阈值ε,说明xi、xj对应的团体mi、mj不存在关联,则直接从图IG*(M,I,W)中删去边Ii,j。如果Inf(xi,xj)≥ε,则进一步计算xi、xj的条件概率独立程度ind(xi,xj)来判断关联类型:若ind(xi,xj)=0,说明xi、xj对应的团体mi、mj不存在直接关联,直接从图IG*(M,I,W)中删除边Ii,j;如果ind(xi,xj)>0,说明xi、xj对应的团体mi、mj存在直接关联,则将图IG*(M,I,W)中的边Ii,j的权值设置为wij=ind(xi,xj)。将删除IG*(M,I,W)中所有无关联的边后得到图记为IG(M,I,W)。X中任意两个点xi、xj的条件概率独立程度的具体计算为:
其中ε为给定的阈值;Inf((xi,xj)|(X-(xi,xj)))为xi和xj关于{X-(xi,xj)}的条件互信息熵,其中,ε∈(0,1)。
步骤4:初始化一个空集S作为种子集。对于团体集合M中的每一个团体mi,以S∪mi作为备选种子,计算S∪mi的影响范围σ(S∪mi),选取边际影响收益σ(S∪mi)-σ(S)最大的mi加入S并从团体集合M中删除该团体,重复此过程直到种子集S的大小达到预设的大小k。每个网络中不同k值得到的种子集S的影响范围如图2所示。影响范围函数σ(S)的计算为:
其中Rj表示团体mj中受感染的个体的比例;N(j)表示在图IG中和mj直接相连的结点集合;n表示N(j)其中的一个结点;child(j)表示集合N(j)中和S之间存在轨的结点的集合;c表示child(j)其中的一个结点;wcj表示结点c和结点j之间的边Ic,j的权值;λ为设定激活因子,其中,λ∈[0,1]。
本发明研究了团体影响最大化问题,通过研究使用历史“感染”数据中团体的概率关联给出了一种高效的团体最大化算法。该方法不依赖于点影响关系的获取即可快速定位最有影响力的团体种子集。并且当网络中团体数量远小于点数量时,本文的方法算法较一般算法更高效、更准确。
应当理解的是,本说明书未详细阐述的部分均属于现有技术,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!