一种模拟网页浏览的动态定制检索方法与流程
本发明涉及一种检索方法,特别是涉及一种模拟网页浏览的动态定制检索方法,属于信息检索领域和自动化领域。
背景技术:
传统的搜索引擎的搜索方式很单一,即基于关键词检索的方式,用户输入关键词后,将对检索出的条目进行选择并逐级点击链接查看,最终得到比较符合其初衷的结果。通过对搜索引擎用户使用行为进行分析可知,用户的搜索过程是由输入和连续点击(每个页面可能会点击多个链接)两组动作组成,目前的搜索引擎实现的是基于关键字的检索,即完成了输入的动作,后续一些列点击浏览由用户手动完成,这种设计的原因在于:搜索引擎得到的是可能匹配的结果,因此不能准确预测用户下一步行为。这种不确定性来源是双向的:从用户方面来说,选取的索引词只是其搜索目标的概括,但根据用户的想法与表达是存在偏差的,即所选择的关键词并不能真实的反应用户的需求;从搜索引擎方面来看,通过关键词得到的结果更多的是通过文本相似度选出的,还不能做到精确地从语义上理解用户需求。
由此可知,这种基于关键词检索的方式在不能明确搜索结果、扩大搜索范围时十分有效,但是对于需要批量检索而整个操作过程的比较明确或者说有固定模式的情况并没有提供有效地支持,例如:某公司想要通过东方财富网的数据中心检索获得500家企业的2011年到2015年的年报和半年报,整个过程只需要机械的输入公司的上市代码接着点击固定的几级链接来获取数据,但是如果整个过程由人工不停歇的完成将耗费十几个小时并需要点击几千个页面。
技术实现要素:
本发明的目的在于克服现有技术存在的问题,提供一种模拟人工浏览网页的定制规则检索的方法,提高检索的自动化,节省了人力并提高了采集数据的效率。
通过对搜索引擎用户搜素行为分析可知,用户的搜索过程是由输入关键词查找和连续点击(每个页面可能会点击多个链接)两组动作模块组成。目前的搜索引擎为用户提供的平台只能完成输入关键词查找的功能,而对于后续一系列点击浏览,由于不确定用户的具体选择,所以由用户手动完成。在面对用户点击流程也清晰地情况下,本发明通过动态定制检索规则的方式来拓展检索系统的服务,设计实现了一个模拟人工浏览网页的定制规则检索方法,针对人工使用固定流程的搜索及点击浏览网页来采集信息,排除了不确定性,提高检索的自动化,该检索方式本发明将其称为定制规则检索,节省了人力并提高了采集数据的效率。
本发明提出一种模拟人工检索的定制规则检索方法,该方法对应的工具是对已有搜索引擎功能的扩展,要实现的功能是根据用户定制的规则自动批量检索获得资源,由于是模拟人工检索,因此需要对人工搜索的特征进行分析,总的来说人工检索的流程通常是:首先打开搜索页面,找到搜索框,然后输入检索词,点击查询;根据查询到的结果点击需要的链接链(可能是一组链接链);如果有多个查询词将重复上一步;作为代替模仿人工的方法也应该遵循此流程,如图1,其中具体需要点击的链接链是需要用户动态指定的。
本发明检索方式为定制规则检索,这里的规则指的是,用户从输入查询词到点击各级链接的流程,遵循这个规则就可以模拟人工检索浏览页面并完成用户指定的批量查询任务。
为实现本发明目的,采用如下技术方案:
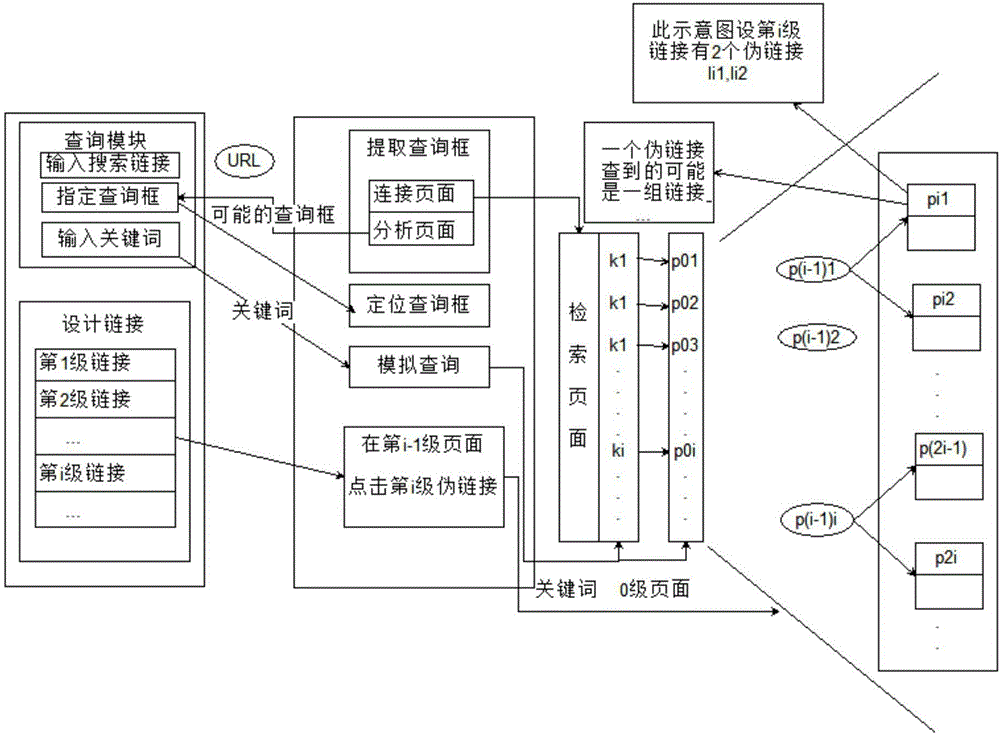
如图2所示,一种模拟网页浏览的动态定制检索方法,包括如下步骤:
1)用户输入查询所在的页面网址;
2)根据用户提供的检索页面的URL对页面解析,对解析出的检索框进行筛选或通过用户选择,确定用户需要的检索框;
3)根据批量查询的任务,确定准备的查询词集;输入检索词集或通过文件定位到检索词集;
4)允许用户逐级设计链接,每一级链接都是在上一级链接得到的基础上进行检索的链接,其中第一层链接的上一层是通过对检索词点击查询得到的页面;
5)对每个步骤3)中的检索词,根据步骤4)设计的链接进行检索,在分析页面查找链接时应采用一些字符串相似度匹配的算法或者使用这些关键词构建正则表达式来查找相应链接,如得到的链接有多个,允许用户限制关键词对应的链接数目;
6)通过步骤4)中逐级链接点击后,最后一级链接点击得到的链接即为检索结果。
2、根据权利要求1所述的模拟网页浏览的动态定制检索方法,其特征在于,所述根据用户提供的检索页面的URL对页面解析是通过页面开源分析工具进行,目的是查找出所有查询框的对象。
为进一步实现本发明目的,优选地,所述页面开源分析工具为jsoup。
优选地,步骤4)中,将通过关键词搜索进入的全体页面称为第0级页面,由第0级打开的页面都标记为第1级页面,在第1级的页面上通过对用户设计的第2级链接点击打开的页面标为第2级页面,以此类推。
优选地,步骤5)中,字符串相似度匹配通过机器学习的语义分析来匹配相似链接;该过程中所有的点击任务由具有JavaScript解析功能的工具HtmlUnit根据查到的链接进行模拟点击。
优选地,步骤6)中,中间过程中生成的页面或链接根据用户的需要返回给用户;所有返回的结果都应该经过查重处理。
本发明与现有的搜索引擎检索相比,具有以下显著优点:
1)节约人力成本及时间。本发明适用于检索流程固定的批量检索需求,传统搜索引擎针对批量检索需求并没有支持,比如想通过东方财富网的数据中心检索获得500家企业的2011年到2015年的年报,如果整个过程由人工不停歇的完成将耗费十几个小时并需要点击几千个页面;如果通过本发明来定制规则实现代替人工检索,用户只需通过以下几步实现定制规则,节约人力成本及时间。
2)提高检索的自动化。本发明在基于传统的关键词检索的方式基础之上,提出的定制规则检索的方式,使得用户可以通过设计关键词集及链接集做到自动检索的效果,可以大大拓展了搜索引擎检索的自动化及用户检索的灵活性。
3)辅助信息收集。传统搜索引擎获取的通常是一个网站的入口,深入的信息并不能直接展现,当需要对某网站内的一些信息进行汇总的时候,只能通过手工方式获取。本发明通过制定基于当前检索结果的深入检索规则来获取网站内部更深层的信息,可将需要的信息汇集展示,辅助信息的收集工作。
附图说明
图1为本发明模拟人工检索的流程图。
图2为本发明动态定制规则检索工具系统架构图。
图3为实施例1所有查询框示意图。
图4为实施例1的第0级页面部分截图。
图5为实施例1设计的链接示意图。
图6为实施例1以洪都航空(600316)为例的运行结果示意图。
图7:实施例2高考网页面的查询框示意图。
图8:实施例2中第0级页面集部分截图。
图9:实施例2设计的链接示意图。
图10:实施例2中50所高校分数线信息结果部分截图。
具体实施方式
下面结合附图和实施例对本发明作进一步的说明,但本发明要求保护的范围并不局限于实施例表示的范围。
实施例1:代替人工批量获取年报
经常会遇到批量获取信息的需求,例如批量获取网页制作搜索引擎,这个过程通常是由网络爬虫完成,爬虫是一种可以沿着链接获取页面,再根据新获取的页面爬取上面所有的链接,以此类推不断获得信息的程序。传统的爬虫不能直接根据用户需求爬取链接,但是基于爬虫爬取到的页面建立的搜索引擎则具备根据用户需求返回信息的能力。然而爬虫爬寻的深度往往是被限制的,并且由于遵循礼貌原则使其不能充分获取更深的页面信息,因此构建于已获得页面库之上的搜索引擎对于已查询到结果的继续深入查询,特别是后继整个浏览点击操作过程比较明确或者说有固定模式的情况并不能提供有效地支持,例如:公司想要通过东方财富网的数据中心检索获得500家企业的2011年到2015年的年报和半年报,整个过程只需要机械的输入公司的上市代码接着点击固定的几级链接来获取数据,已知人工查询并获取一个公司2011年到2015年的年报和半年报大概需要点击12个链接、耗时2分钟(没有包括关闭页面的点击和耗时),因此如果由人工不停歇获取这500家企业年报和半年报将至少耗费46个小时并需要点击6000个页面。
如图2,一种用于代替人工检索,获取上市公司年报和半年报的模拟网页浏览的动态定制检索方法,包括如下步骤:
(1)将模拟网页浏览的动态定制检索方法编写成可执行的程序;程序中要有清晰地说明与提示,辅助用户进行检索规则的设计;
(2)明确并输入获取年报信息的网页URL,此处为东方财富网的数据中心http://data.eastmoney.com/notice/,程序将连接到该URL,得到东方财富网的数据中心网址的页面脚本;
(3)该程序将分析步骤(2)中得到的东方财富网数据中心页面脚本,对所有查询框页面元素提取并以可视方式输出;图3为本实施1所有查询框示意图;如图3所示,包括整个网站信息的查询框,上市公司查询框,公告日期查询框,页码查询框;
(4)用户根据图3返回的查询框的特征选择了上市公司查询框,程序记录下这个查询框的id=notice_StockCode并返回;
(5)根据程序提示,在关键词输入区载入准备好的500家企业的股票代码文件,程序将在步骤(4)获得的查询框中模拟输入这些股票代码并逐一查询,程序将返回查询后的页面URL集,这里称为第0级页面集;图4为本实施例的第0级页面部分截图,如图4所示,各股票代码对应的网址都分别显示。
(6)制定链接。图5为实施例1设计的链接示意图。如图5所示,用户应明确自己点击链接的流程,此处根据实际点击的固定流程,链接应设计为第一级链接设为“定期报告”,第二级链接设为“2011年年报”,“2012年年报”,“2013年年报”,“2014年年报”,“2015年年报”,“2011年半年报”,“2012年半年报”,“2013年半年报”,“2014年半年报”,“2015年半年报”,输入该流程,程序将接收输入的这两级链接并保存。
(7)以洪都航空(600316)为例,如图6所示,程序对第0级页面集上每个页面逐级执行步骤6)设计的链接后,即可获得代替人工检索到的这500家企业的2011年到2015年的年报和半年报链接,共5000条信息。图6为实施例1以洪都航空(600316)为例的运行结果示意图。
本实施例可见本发明代替繁琐的人工过程,实现批量检索获取信息的效果。
实施例2:应用于高考报考院校分数线信息收集
互联网是个巨大的资源网,但是信息庞大复杂,因此信息获取往往是个耗时的过程。对于高考的学生,成绩公布到志愿填报期间的时间是十分珍贵的,这期间他们将进行紧张的院校选取工作,他们更愿意将时间花费在院校信息对比分析而不是信息查询。例如某广东省文科学生想通过高考网查询自己感兴趣的50所学校的历届分数线。为了达到这个目的,他将需要在高考网搜寻50所学校,进入每所学校对应的页面还需要先后点击录取分数、招生地区中的广东和文理分科中的文科这一系列链接。本实施例可以代替上述繁琐耗时的一系列人工操作,将这50所院校的历届分数线信息汇集显示。
如图2所示,一种用于代替人工检索,获取高考报考院校分数线信息收集的模拟网页浏览的动态定制检索方法,包括如下步骤:
(1)将模拟网页浏览的动态定制检索方法流程编写成可执行的程序;该程序可设计为浏览器的辅助功能插件或者单独的客户端程序,此外程序中制定规则的每一步都需要有清晰地说明与提示,方便用户操作;
(2)在程序中输入高考院校历届分数线信息所在的网站URL:http://www.gaokao.com/,程序将连接到这个网站并获取整个网页脚本;
(3)分析步骤(2)得到的页面脚本并返回所有的搜索框元素供用户选择,如图7所示;
(4)用户通过辨识搜索框特征分别点击选择每个网址内需要使用到的院校查询检索框,程序会感知点击并分析被点击元素以记录下id=schname_b1;
(5)在程序提示输入关键词的位置输入50所院校的名称或者链接到50所院校名称所在的文件,在步骤(4)中id对应的元素中逐个模拟读入院校名称并点击查询获得对应的URL,程序将返回这些URL组成的第0级页面集,如图8所示;
(6)如图9所示,设计链接,对(5)中关键词查询得到的第0级页面集的每个页面基础上需要先后点击:进入主页->录取分数->广东、文科,所以链接设计为三级;
(7)完成上述的定制过程后,点击最终的查询按钮即可获得之前输入的50所院校分数线所在的URL集了,如图10所示。
- 还没有人留言评论。精彩留言会获得点赞!