基于基尼指数求解文本相似度的方法与流程
本发明涉及语义网络技术领域,具体涉及基于基尼指数求解文本相似度的方法。
背景技术:
在中文信息处理中,文本相似度的计算广泛应用于信息检索、机器翻译、自动问答系统、文本挖掘等领域,是一个非常基础而关键的问题,长期以来一直是人们研究的热点和难点。目前多数文本相似度算法是以向量空间模型为基础的,但这种方法会引起高维稀疏的问题以及不知特征词汇集合对文本的重要程度和贡献度。而且,这类算法没有很好地解决文本数据中存在的自然语言问题同义词和多义词。这些问题干扰了文本相似度算法的效率和准确性,使相似度计算的性能下降。为了满足上述需求,本发明提供了一种基于基尼指数求解文本相似度的方法。
技术实现要素:
针对于特征向量高维稀疏问题、未考虑特征词汇集合对文本的重要程度和贡献度的问题、存在同义词与多义词问题以及文本相似度算法的效率和准确性不高问题,本发明提供了基于基尼指数求解文本相似度的方法。
为了解决上述问题,本发明是通过以下技术方案实现的:
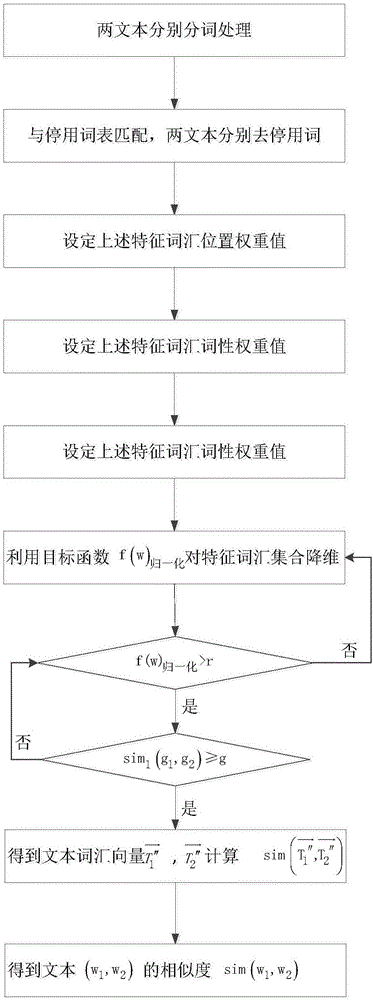
步骤1:利用中文分词技术分别对两文本(w1,w2)进行分词处理;
步骤2:根据停用表分别对两文本(w1,w2)词汇进行去停用词处理,得到文本特征词汇集合T1,T2;
步骤3:根据词汇在文本中的位置得到一系列词汇位置权重值(α1,α2,…,αn);
步骤4:根据词汇在文本中的词性得到一系列词汇词性权重值β1、β2、β3、β4;
步骤5:综合上述步骤,利用目标权重函数f(w)归一化对文本词汇集合进行进一步降维处理,得到文本特征词汇集合分别为T1′、T2′;
步骤6:根据语义相似度条件,合并相似度高的词汇,对两文本特征词汇集合T1′、T2′再降维,此时两文本的特征词汇向量分别为
步骤7:利用文本相似度函数sim(w1,w2),求解两特征向量间的相似度即为文本相似度
本发明有益效果是:
1、此方法比传统的词频-反文档频率方法得到的特征词汇集合的准确度更高。
2、此方法克服了信息增益方法只适合用来提取一个类别的文本特征的缺点。
3、此方法结果更符合经验值。
4、此方法解决了文本特征词汇高维稀疏的问题。
5、此方法解决了同义词与多义词的问题。
6、为后续的文本聚类技术提供良好的理论基础。
7、此算法具有更大的利用价值。
8、此方法计算了特征词汇中不同词汇对文本思想的贡献度。
9、此方法计算文本相似度的准确性更高。
附图说明
图1基于基尼指数求解文本相似度的方法的结构流程图
图2 n元语法分词算法图解
图3中文文本预处理过程流程图
具体实施方式
为了解决特征向量高维稀疏问题、未考虑特征词汇集合对文本的重要程度和贡献度的问题、存在同义词与多义词问题以及文本相似度算法的效率和准确性不高问题,结合图1-图3对本发明进行了详细说明,其具体实施步骤如下:
步骤1:利用中文分词技术分别对两文本(w1,w2)进行分词处理,其具体分词技术过程如下:
步骤1.1:根据《分词词典》找到待分词句子中与词典中匹配的词,把待分词的汉字串完整的扫描一遍,在系统的词典里进行查找匹配,遇到字典里有的词就标识出来;如果词典中不存在相关匹配,就简单地分割出单字作为词;直到汉字串为空。
步骤1.2:依据概率统计学,将待分词句子拆分为网状结构,即得n个可能组合的句子结构,把此结构每条顺序节点依次规定为SM1M2M3M4M5E,其结构图如图2所示。
步骤1.3:基于信息论方法,给上述网状结构每条边赋予一定的权值,其具体计算过程如下:
根据《分词词典》匹配出的字典词与未匹配的单个词,第i条路径包含词的个数为ni。即n条路径词的个数集合为(n1,c2,…,nn)。
得min()=min(n1,n2,…,nn)
在上述留下的剩下的(n-m)路径中,求解每条相邻路径的权重大小。
在统计语料库中,计算每个词的信息量X(Ci),再求解路径相邻词的共现信息量X(Ci,Ci+1)。既有下式:
X(Ci)=|x(Ci)1-x(Ci)2|
上式x(Ci)1为文本语料库中词Ci的信息量,x(Ci)2为含词Ci的文本信息量。
x(Ci)1=-P(Ci)1lnp(Ci)1
上式p(Ci)1为Ci在文本语料库中的概率,n为含词Ci的文本语料库的个数。
x(Ci)2=-p(Ci)2lnp(Ci)2
上式p(Ci)2为含词Ci的文本数概率值,N为统计语料库中文本总数。
同理X(Ci,Ci+1)=|x(Ci,Ci+1)1-x(Ci,Ci+1)2|
x(Ci,Ci+1)1为在文本语料库中词(Ci,Ci+1)的共现信息量,x(Ci,Ci+1)2为相邻词(Ci,Ci+1)共现的文本信息量。
同理x(Ci,Ci+1)1=-p(Ci,Ci+1)1lnp(Ci,Ci+1)1
上式p(Ci,Ci+1)1为在文本语料库中词(Ci,Ci+1)的共现概率,m为在文本库中词(Ci,Ci+1)共现的文本数量。
x(Ci,Ci+1)2=-p(Ci,Ci+1)2lnp(Ci,Ci+1)2
p(Ci,Ci+1)2为文本库中相邻词(Ci,Ci+1)共现的文本数概率。
综上可得每条相邻路径的权值为
w(Ci,Ci+1)=X(Ci)+X(Ci+1)-2X(Ci,Ci+1)
步骤1.4:找到权值最大的一条路径,即为待分词句子的分词结果,其具体计算过程如下:
有n条路径,每条路径长度不一样,假设路径长度集合为(L1,L2,…,Ln)。
假设经过取路径中词的数量最少操作,排除了m条路径,m<n。即剩下(n-m)路径,设其路径长度集合为
则每条路径权重为:
上式分别为第1,2到路径边的权重值,根据步骤1.4可以一一计算得出,为剩下(n-m)路径中第Sj条路径的长度。
权值最大的一条路径:
步骤2:根据停用表分别对两文本(w1,w2)词汇进行去停用词处理,得到文本特征词汇集合T1,T2,其具体描述如下:
停用词是指在文本中出现频率高,但对于文本标识却没有太大作用的单词。去停用词的过程就是将特征项与停用词表中的词进行比较,如果匹配就将该特征项删除。
综合分词和删除停用词技术,中文文本预处理过程流程图如图3。
步骤3:根据词汇在文本中的位置得到一系列词汇位置权重值(α1,α2,…,αn),其具体描述如下:
各个词在文本中的分布是不同的,而不同位置的词对于表示文本内容的能力也是不同的。这个可以根据统计调查得出一系列的位置权重值(α1,α2,…,αn)。
步骤4:根据词汇在文本中的词性得到一系列词汇词性权重值β1、β2、β3、β4,其具体描述如下:
现代汉语语法中,一个句子主要由主语、谓语、宾语、定语和状语等成分构成。从词性的角度看,名词一般担当主语和宾语的角色,动词一般担当谓语的角色,形容词和副词一般担当定语的角色。词性的不同,造成了它们对文本或者句子的表示内容的能力的不一样。根据调查统计得出名词、动词、形容词、副词的权重值依次为β1、β2、β3和β4,且β1>β2>β3>β4。
步骤5:综合上述步骤,利用目标权重函数f(w)归一化对文本词汇集合进行进一步降维处理,得到文本特征词汇集合分别为T1′、T2′,其具体计算过程如下:
目标权重函数为:f(w)=αiβjPW(1-PK)
上述αi、βj分别为位置权重与词性权重,如上所述,i∈(1,2,…,n),j∈(1,2,3,4),PW为特征词汇在文本中的概率,PK为含有特征词汇的文本数在库中的概率。
上式又可写为:
上式nwL为特征词汇TL在文本中出现的次数,Nw为文本中特征词汇集合的总个数,nkL为库中含有特征词汇TL的文本个数,Nk为库中总文本个数。
为了使数据具有更好的标识性,对上式再进行归一化处理,得:
上式L为特征词汇集合中第L个特征词汇,S为特征词汇集合中特征词汇的个数。f(w)归一化越大,词汇在文本中所占的权重越大,区分文本间的能力就越强,越能代表文本的主旨。
设定一个合适的阈值r,对特征词汇集合T1,T2降维处理,有下式选择条件:
f(w)归一化>r
只有满足上述条件,即是该文本的特征词汇集合T1′、T2′,r可以通过迭代试验测试出最恰当的值。
步骤6:根据语义相似度条件,合并相似度高的词汇,对两文本特征词汇集合T1′、T2′再降维,此时两文本的特征词汇向量分别为其具体过程如下:
步骤6.1)利用基于《知网》概念的方法,特征词汇集合T1′、T2′中的词汇映射到概念,求解两两词汇对应的两本体概念(g1,g2)间语义相似度即为词汇相似度。
构造两本体概念(g1,g2)语义相似度sim1(g1,g2)
当两个概念共同直接子节点个数越多,则概念(g1,g2)相似度越大,反之,越小。
从概念(g1,g2)的直接子节点中找出共有的子节点个数N。
为了解决子节点多继承问题,有下式:
α为最长路径L1的权重系数,β为(g1,g2)共有的子节点个数N的权重系数,α+β=1。权重系数可以根据实验结果迭代得到。d1为两本体概念的语义信息距离,d2为从子集中找出概念经共同父节点的最长路径。
上式d1=[I(g1)+I(g2)]-I(ICN)
I(g1)、I(g2)分别为概念g1、g2在本体树中的信息量,I(ICN)为概念g1、g2在本体树中的共有信息量。
步骤6.2)设定阈值g,合并相似度高的词汇,重新分配其权重。
条件:sim1(g1,g2)≥g
合并后的词汇为权重更大的那个,此时词汇的权重mw(ci)′为两词汇权重的平均值,如下所式:
迭代计算两两词汇间的相似度,直到没有满足上述条件的词汇为止。
综上即分别得,文本特征词汇向量
步骤7:利用文本相似度函数sim(w1,w2),求解两特征向量间的相似度即为文本相似度,其具体计算过程如下:
两特征向量间的相似度求解如下:
上式为文本1的特征词汇向量中的词汇个数,为文本2的特征词汇向量中的词汇个数。
基于基尼指数求解文本相似度的方法,其伪代码计算过程如下:
输入:两个文本(w1,w2)
输出:两文本(w1,w2)间的相似度sim(w1,w2)。
- 还没有人留言评论。精彩留言会获得点赞!