基于捆绑约束的分级优化立体匹配方法与流程
本发明属于立体图像领域,涉及计算机视觉领域,特别涉及一种立体图像的视差深度图重建方法。具体讲,涉及基于捆绑约束的分级优化立体匹配方法。
背景技术:
自由视点电视作为目前最流行的多视点图像应用,打破了传统单视点电视只能通过摄像机的角度观看的限制,能够提供给用户自由选择观看角度的能力,给使用者带来不同于传统媒体的新体验。如今已经被广泛使用。然而,自由视点的视频为了能够给用户带来如同现实世界中的体验,需要所有能够观察到的视点的视频信息。实际操作中由于空间资源有限导致只能使用有限数量的摄像机,难以获取如此多的视点的视频信息。为此研究人员开发出了一系列替代的方法,利用虚拟视点合成技术产生虚拟视点,或者利用有限的真实视点,通过图像到图像的映射产生中间视点的信息。由于这些技术的应用,使得自由视点技术不再需要大量的摄像机。其中,对于立体相机来说,图像到图像的映射方法,既是立体匹配。
深度信息的获取是计算机视觉领域的关键问题,也是立体匹配要解决的主要问题。一个先进的计算机视觉系统能够为高分辨率图像的每个像素提供准确的颜色和深度信息。这类系统主要用于解决自动化视觉问题,特别是在机器人导航、语义感知操控和远程监控等领域,以及为室内环境建立密集的三维视图。
立体匹配算法,即通过计算两个或多个位于不同位置的相机拍摄的图片中的对应像素的视差信息,再利用视差和深度的对应关系计算得到图像的深度信息。立体匹配是计算机视觉中的一个重要的研究领域。文献[1][2]概述了现有的技术,并阐述了立体匹配以及三维重建技术近年来的研究进展。其中提到的基于贪婪算法的区域搜索算法具有较快的匹配速度,但在弱纹理和模糊表面区域的重建效果并不理想。另一类全局算法将立体匹配的问题转化为单一目标的最优化问题,通过图像的相似性概率和表面平滑度的先验信息构建马尔科夫(MRF)能量函数,并求解其最小值的过程。全局算法解决了区域算法中的一些难以解决的问题,能够对弱纹理区域和模糊表面区域实现较准确的匹配,但它的计算复杂度非常高,通常一个MRF能量函数的优化过程是一个NP难度(NP-hard)问题。
图像噪声,弱纹理区域和遮挡区域是立体匹配目前面临的主要问题。已有的立体匹配算法都有一定的局限性,因为其中大部分算法默认图像中颜色相同的相邻区域属于相同的视差平面,距离越近的像素属于同一视差平面的可能性越大。然而,当待匹配图像中具有较多的与拍摄平面不平行的倾斜表面或高曲率的表面时,上述假设会对匹配结果产生较大的误导,使得最终的结果出现较多错误。为了解决上述问题,X.Sun和X.Mei在文献[17]中提出一种通过在代价空间传递视差信息的局部立体匹配问题方法,实现了立体匹配的实时性。Y.Wang和E.Dunn在文献[18]中提出一种新的高效立体图像视差估计框架,将空间平滑假设应用与立体问题中,并重新定义平滑约束。C.Pham和J.Jeon[19]提出一种降维局部代价聚合方法,可以降二维的滤波窗口转换成一维的数字序列,与传统的二维滤波算法相比明显减低了计算复杂度和内存的消耗。J.Jiao和R.Wang[20]提出一种基于Census变换(一种应用于图像的非参量变换方法)[28]、绝对截断误差和、颜色梯度相结合的代价聚合方法,并且提出一种后处理方法用来消除初始视差图中的误差点。
自适应支持权值立体匹配算法具有边缘保留和高时间复杂度的特点。E.Psota和J.Kowalczuk[10]提出一种基于自适应权值算法的结果的迭代优化方法,通过优化能够消除窗口匹配的误差,并且不增加计算复杂度。C.Cigla和Q.Yang[12,14]提出一种时间复杂度恒定的边缘感知立体匹配算法,该方法根据支持区域和递归权重自适应的调整窗口的大小。N.Einecke和J.Eggert[15]提出使用各向异性中值滤波法对立体视差图进行优化的方法。其中各向异性中值滤波的思路来源于一般中值滤波去和边缘保留滤波去的结合。
技术实现要素:
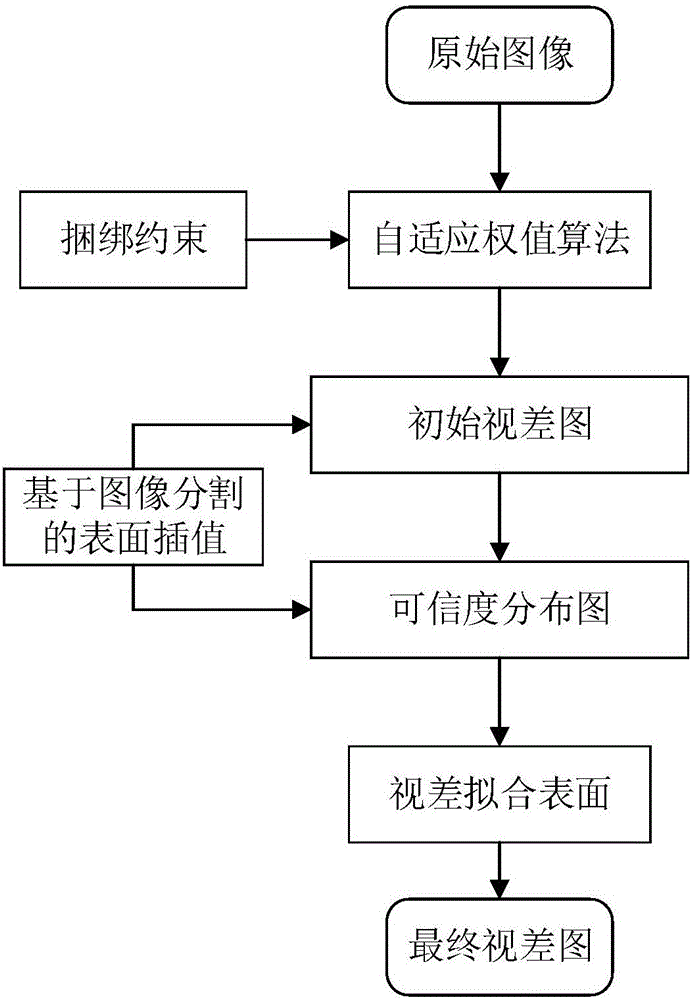
为克服现有技术的不足,本发明旨在提出一种新的立体匹配方法,主要针对传统立体匹配算法在弱纹理区域和遮挡区域无法正常匹配的问题,提出的方法能够得到目标场景准确的视差图,更好的处理立体匹配问题,并且能够得到更加准确的视差信息,在计算机视觉和机器人应用领域具有非常好的应用前景。本发明采用的技术方案是,基于捆绑约束的分级优化立体匹配方法,(1)首先通过ASW局部立体算法得到初始视差图;(2)结合图像一致性约束和几何连续性约束对视差图进行优化,以实现对图像噪声和遮挡区域边界更好的处理;(3)利用图像分割的方法获取需要局部优化的图像和视差图信息;(4)通过二次表面差值的方法对局部视差进行优化得到最终的视差图。
(1)通过ASW局部立体算法得到初始视差图具体步骤是,给定一对校正的立体图像Ir表示右视点视图、Il表示左视点视图,首先使用自适应支持权值算法获得初始视差图,自适应支持权值算法为当前窗口内的每个像素赋予权值,权值大小取决于目标像素与窗口中心像素的空间距离和CIElab颜色空间中的颜色距离相关,其中CIElab颜色空间是一种区别于RGB的颜色空间,它是一种与设备无关的基于生理特征的颜色系统,能够用数字化的方法来描述人的视觉感应,像素的原始匹配代价可以通过截断绝对误差(TAD)进行计算,对应点p'c(i,j-d+d')的代价和为窗口所有像素的加权代价和对权值的总和进行归一化计算,其中i、j为像素的坐标值,d、d’为图像的视差偏移计算公式如下:
其中E(pc,qc)是对应(pc,qc)的总代价,pc,qc分别为左右视图的对应像素,Wl,Wr分别为以pc,qc为中心的支持窗口,pi,qi分别为落在Wl,Wr中的像素,ωl(pi,pc)和ωr(qi,qc)分别为pi,qi的加权系数,e0(pi,qi)为pi,qi的初始匹配代价,在(2)中{r,g,b}为RGB颜色空间的颜色分量,Iv表示c的颜色强度,T决定初始匹配代价的上限值,在(3)中dc(Iv(pi),Iv(pc))表示左视图中像素pi,pc在CIE颜色空间中的颜色距离,ds(pi,pc)表示像素pi,pc之间的空间距离,常数γa,γb为该算法的两个人为设定的参数;
计算代价聚合之后,使用WTA(Winner-Take-All)方法为像素分配匹配代价最小的视差:
其中d表示像素pc,qc对应的视差候选,Sd=dmin,...,dmax为所有可能的视差值的集合。
采用如下衡量视差可信度的方法,以准确的找到初始视差图中错误视差的分布情况:
立体匹配中关于视差可信度定义为:初始视差图中越接近真实视差的像素,其可信度越高,于是可以通过构建像素p的最小匹配代价和仅高于最小匹配代价的代价值之间的关系,定义可信度的计算方法:
其中分别为像素p的最佳(即最小)和仅次于最佳的匹配代价值,Tc是为了防止除数为零而设定的较小阈值,R(d)为可信度,能够用来构建低信噪比模糊匹配模型。
(2)基于同时考虑图像一致性和几何连续性约束的捆绑约束的视差优化方法具体步骤如下:
首先,选取左图像Il上一点pc,根据几何外极线约束,右图像Ir上相匹配的qc点应当位于与之对应的外极线上,同样右图像上的qc在左图像上的对应点pc'根据外极线约束也应该在相对应的外极线上,这里定义以左图像为参考图像时,右图像Ir上对应pc(i,j)点视差为d的点为qc(i,j-d);以右图像为参考图像时,左图像Il上对应qc(i,j-d)点视差为d‘的点为p'c(i,j-d+d');
定义一个新的代价聚合函数(6)
e(pi,qi)=e0(pi,qi)+(d-d')2 (7)
其中E'(pc,qc)为改进后的聚合匹配代价,e(pi,qi)为改进后的初始匹配代价,公式中其他变量含义同上。
(3)图像分割步骤是,假设图像分割之后的每个区域的视差变化是平滑的,而且深度不连续只发生在分割后的区域边界,使用均值漂移图像分割算法对参考图像进行分割,假设支持窗口内所有与中心像素位于同一块分割区域的像素具有近似相同的视差值,因此,为这些点赋予范围内最大的权值,改进的加权函数如下:
这里通过使用图像分割算法获得大量的分割区域,其中Sc为pc所在区域,区域Sc外的所有像素都对pc的代价计算没有影响。
(4)基于图像分割的表面插值具体步骤是,在完成了对像素的立体匹配之后,通过可信度图看出在弱纹理区域仍然存在以下视差估计错误的像素,可信度值低于阈值的区域,接下来基于图像分割和视差图分割的结果,使用二次表面插值法在图像的等级对这些错误像素进行修正:
假设:在三维视差空间内各个表面的视差变化是平滑的,因此正确的匹配结果能够形成平滑的表面,而错误的会形成参差结构。基于这个假设的算法步骤是:
首先使用图像分割选出左视图中较大面积的弱纹理区域,根据可信度图,这些区域中既有可信度高的正确匹配的像素,也有不可信的错误像素,根据正确的像素的视差空间重建三维表面,然后使用表面插值算法重新估计错误像素的视差,
为了确保三维表面是光滑且连续的,使用一个二元三次方程来表示这个表面,公式如下:
其中d(x,y)表示一个三维曲面,a1,…,a10为系数,x,y为坐标。
本发明的特点及有益效果是:
本发明首次采用捆绑约束与分级优化的方法解决立体匹配问题,为立体匹配问题提出了新的思路。将具有复杂几何特征的场景视为一系列视差空间中的三维曲线结构,以求获得准确的匹配结果。实验结果表明,对标准立体测试图像使用本方法得到的视差图在图像尖锐边缘部分很好了还原了物体的视差信息。并且与Middlebury数据库中其他同类算法相比,在弱纹理和边缘区域的匹配效果有了显著的改善。从算法的定量分析结果可以看出,本方法在遮挡区域、视差不连续区域以及所有像素区域的误匹配半分比,相比同类算法都有明显的降低。同时,本算法的时间消耗主要集中在像素级的匹配过程,在视差优化方面可以实现高效的计算。另外,该算法能够为三维立体图像质量评价提供服务。
附图说明:
图1传统的立体匹配平面假设示意图。
图2本发明流程图。
图3极线几何模型。
图4可信度分布图。
图5图像级表面插值过程示例。图中,
(a)venus左视点的原始图像
(b)颜色分割输出图像
(c)初始视差图
(d)初始视差图表面插值结果
(e)视差图分割输出结果
(f)二次表面插值结果。
图6实验结果评估。
具体实施方式
本发明针对三维场景的视差信息提取问题,提出一种新的立体匹配方法。主要针对传统立体匹配算法在弱纹理区域和遮挡区域无法正常匹配的问题,基于捆绑约束的方案,结合像素间的匹配过程和图像整体的表面差值过程,得到目标场景准确的视差图。本发明能够更好的处理立体匹配问题,并且能够得到更加准确的视差信息,在计算机视觉和机器人应用领域具有非常好的应用前景。
本发明提出一种基于捆绑约束的分级优化立体匹配方法。首先对Yoon和Kweon在文献[3]中提出的自适应权值算法进行了改进,该算法是目前最好的局部立体匹配算法。然而,仅根据颜色相似性进行视差估计是远远不够的,因此本发明提出结合图像一致性约束和几何连续性约束对视差图进行优化,以实现对图像噪声和遮挡区域边界更好的处理。通过改进的自适应权值局部立体算法得到初始视差图;利用图像分割的方法获取需要局部优化的图像和视差图信息;通过二次表面差值的方法对局部视差进行优化得到最终的视差图。
本发明的步骤流程是:
(1)首先根据Yoon和Kweon在文献[3]中提出的自适应权值算法对已校正的原始图像进行立体匹配得到视差图(对比视差图,对后面步骤没有影响)。利用公式(5)计算初始视差图中每个像素的可信度,将计算结果转换成可信度分布图。
(2)在自适应权值算法的基础上,同时考虑图像一致性约束和几何外极线约束得到新的匹配代价函数,使用新的代价函数对原始图像进行计算,得到视差图(即初始视差图)。与此同时计算该视差图的可信度分布图,以步骤(1)中的可信度分布图进行对比,显示出该算法的优越性。
(3)使用均值漂移算法对原始图像进行分割,得到代价独立的颜色相似区域。为步骤3中得到的初始视差图的可信度分布图设定阈值,将经过图像分割结果中可信度低于阈值的区域视为误匹配区域。并对这些区域进行后续操作。
(4)建立一个二元三次方程对上述区域进行曲面拟合,并且根据可信度高的像素使用插值算法,将得到的结果填充到误匹配像素上,得到光滑的表面。最后将处理后的部分融合得到最终的视差图。
几个具体步骤如下:
一、自适应权值获取视差图
该步骤具体是利用自适应权值的立体匹配方法获取视差图的具体实施方式,及视差的可信度度量的具体计算方法和表现形式。
给定一对校正的立体图像Ir、Il,首先使用自适应支持权值算法获得初始视差图。该算法为当前窗口内的每个像素赋予权值,权值大小取决于目标像素与窗口中心像素的空间距离和CIElab颜色空间中的颜色距离相关。像素的原始匹配代价可以通过截断绝对误差(TAD)进行计算。对应点p'c(i,j-d+d')的代价和为窗口所有像素的加权代价和对权值的总和进行归一化计算,计算公式如下:
其中E(pc,qc)是对应(pc,qc)的总代价,pc,qc分别为左右视图的对应像素,Wl,Wr分别为以pc,qc为中心的支持窗口,pi,qi分别为落在Wl,Wr中的像素,ωl(pi,pc)和ωr(qi,qc)分别为pi,qi的加权系数,e0(pi,qi)为pi,qi的初始匹配代价,在(2)中{r,g,b}为RGB颜色空间的颜色分量,Iv表示c的颜色强度,T为决定初始匹配代价的上限值的参数,在(3)中dc(Iv(pi),Iv(pc))表示左视图中像素pi,pc在CIE颜色空间中的颜色距离,ds(pi,pc)表示pi,pc之间的空间距离,常数γa,γb为该算法的两个人为设定的参数,p'c(i,j-d+d')为右视图中的像素对应左视图中待匹配像素,i,j-d+d'为其坐标参数,公式为计算该像素与待匹配像素之间匹配代价的公式,d、d’分别为左右视图对应的视差偏移量,在本文中只起到标明像素坐标的作用,不参与公式运算。
计算代价聚合之后,使用WTA(Winner-Take-All)方法为像素分配匹配代价最小的视差:
其中d表示pc,qc对应的视差候选,Sd=dmin,...,dmax为所有可能的视差值的集合。
图3为通过自适应权值算法得到的初始视差图。
由图3可以看出,自适应权值立体匹配方法得到的视差估计在部分区域还有一定的误差,为了准确的找到初始视差图中错误视差的分布情况,本发明提出一种衡量视差可信度的方法。
立体匹配中关于视差可信度可以简单定义为:初始视差图中越接近真实视差的像素,其可信度越高。于是可以通过构建像素p的最小匹配代价和仅高于最小匹配代价的代价值之间的关系,定义可信度的计算方法:
其中分别为像素p的最佳(即最小)和仅次于最佳的匹配代价值,Tc是为了防止除数为零而设定的较小阈值,R(d)为可信度,能够用来构建低信噪比模糊匹配模型。
图3(第3列和第5列)显示了通过对初始视差图进行计算得到的可信度图,其中红色表示0.8≤R≤1的区域,黄色表示0.6≤R≤0.8的区域,绿色表示0.4≤R≤0.6的区域,青色表示0.2≤R≤0.4的区域,蓝色表示0.1≤R≤0.2的区域,黑色表示0≤R≤0.1的区域。R值越大,表示可信度越高。当可信度值大于一定值时,认为该像素的视差值为真实视差。这里根据实验情况将判定是否视为真是时差的阈值设定为0.1。每个图像都有自己的阈值,该阈值随图像变化而变化。
二、捆绑约束优化方法
该步骤具体是捆绑约束即结合图像一致性约束和几何连续性约束对初始视差图进行优化的步骤。
Yoon的自适应支持权值算法能够提供较好的结果。然而,仍然能够在一些区域发现错误匹配点,例如遮挡边缘和两边颜色差距不明显的视差不连续区域。本发明认为不能仅依靠颜色相似度估计视差范围,并提出了一种基于同时考虑图像一致性和几何连续性约束的捆绑约束的视差优化方法。捆绑约束能够实现以下三个目标,第一是为不同深度层次的像素分配特定的深度值。第二是协助减少图像噪声和遮挡区域的影响,使得结果摆脱平滑过度和混合伪影的影响。第三是使得算法能够得到明确的物体边界。
首先,选取左图像Il上一点pc,根据几何外极线约束,右图像Ir上相匹配的qc点应当位于与之对应的外极线上。同样右图像上的qc在左图像上的对应点pc'根据外极线约束也应该在相对应的外极线上。理论上,pc'和pc应该位于相同的位置。但是,实际中由于匹配的错误和遮挡在视差估计中的影响,pc'和pc有可能会得到不同的点。这里定义以左图像为参考图像时,右图像Ir上对应pc(i,j)点视差为d的点为qc(i,j-d);以右图像为参考图像时,左图像Il上对应qc(i,j-d)点视差为d‘的点为p'c(i,j-d+d')。
定义一个新的代价聚合函数(6)。根据公式(1),对原始匹配代价进行了大幅度的修改。
E'(pc,qc)为修改好的匹配代价:
e(pi,qi)=e0(pi,qi)+(d-d')2 (7)
使用捆绑约束之后,从实验结果能够看出匹配效果得到了很大的提升(如图3,图5)。物体边界更明确,过度平滑和混合伪影现象明显减少。另外,视差值更加明确以及为好像素增加了可信度。图4显示捆绑约束算法的匹配结果,可以看出遮挡边缘的视差估计准确度得到了明显的改善。
但是,一些区域仍然存在错误,例如颜色相近的视差不连续区域。根据公式(1),空间距离和颜色差距都较小的像素能够获得较大的权值,但是这些像素并不一定和中心像素位于相同的视差平面。因此需要重新计算这些像素的视差。
三、图像分割
该步骤是利用图像分割的方法获取需要局部优化的图像和视差图信息。
为了降低立体匹配算法中代价分配和颜色相似度的相关性,本发明提出一种利用图像分割对视差平面进行分割的分级立体匹配算法。加入分割之后的算法,在仅仅依靠颜色和距离的基础上增加了像素之间的相关性以及分割之后形状关系对代价分配的影响。
这里假设图像分割之后的每个区域的视差变化是平滑的,而且深度不连续只发生在分割后的区域边界。(事实上,具有相同颜色的表面区域并不总是位于同一深度平面。该问题会在之后进行阐述。)本文使用Comaniciu和Meers在文献[33]中提出的均值漂移图像分割算法对参考图像进行分割,该算法具有较低的计算复杂度以及它在边缘信息的保留方面具有非常好的表现。均值漂移算法基本上可以定义为通过一个在高维特征空间中定义的密度函数寻找最大上升梯度的过程。特征空间包括空间坐标以及在分析过程中考虑到的所有相关属性的综合。
本发明使用的理论假设支持窗口内所有与中心像素位于同一块分割区域的像素具有近似相同的视差值,因此,为这些点赋予范围内最大的权值。改进的加权函数如下:
这里通过使用图像分割算法获得大量的分割区域,其中Sc为pc所在区域。区域Sc外的所有像素都对pc的代价计算没有影响。考虑这些像素并不应该包含在支持窗口内,而这种看似没有根据的假设,对弱纹理区域的匹配很有帮助。
四、基于图像分割的表面插值
该步骤具体为通过二次表面差值的方法对局部视差进行优化得到最终的视差图。
在完成了对像素的立体匹配之后,通过可信度图可以看出在弱纹理区域仍然存在以下视差估计错误的像素(可信度值低于阈值的区域)。因此,接下来我们基于图像分割和视差图分割的结果,使用二次表面插值法在图像的等级对这些错误像素进行修正。
使用二次插值的目的在于为上文提到的错误匹配像素提供修正的视差备选范围。这里定义一个假设:在三维视差空间内各个表面的视差变化是平滑的,因此正确的匹配结果能够形成平滑的表面,而错误的会形成参差结构。基于这个假设提出了下面的算法。
首先使用图像分割选出左视图中较大面积的弱纹理区域。这里仍然使用均值漂移算法对参考图像进行分割。不同在于这时只对弱纹理区域(或视差估计错误的区域)进行分割。根据可信度图,这些区域中既有可信度高的正确匹配的像素,也有不可信的错误像素。我们根据正确的像素的视差空间重建三维表面,然后使用表面插值算法重新估计错误像素的视差。
为了确保三维表面是光滑且连续的,使用一个二元三次方程来表示这个表面,公式如下:
其中d(x,y)表示一个三维曲面,a1,…,a10为系数,x,y为坐标。
为了强化实验结果的视觉舒适度,可以通过初始视差图分割来调整表面平滑。图5显示了图像表面插值算法的全部流程(以Venus为例)。首先分割初始视差图(如图5d),提取三维实体(如图5e)。然后再三维视差空间中,对视差图进行平滑适应(如图5f)得到最终的视差图。
表1本文算法所得结果的视差错误百分比在Middlebury测试平台上的测试结果
下面结合附图和具体实施例进一步详细说明本发明。
本发明选用以下网站提供的标准测试数据集进行测试:vision.middlebury.edu/stereo.其中包括四幅用相同的相机拍摄不同场景得到彩色图像(如图6第一列)。本发明所有算法均通过Matlab实现。
本发明使用多个不同场景对提出的模型进行测试。由于篇幅所限,这里只详细阐述四个不同样本场景的结果,图6为测试结果,所选用的每个场景都尽可能包含不同种类的区域。对于每个场景,通过使用一种名为主动时空立体的系统[10]对该场景拍摄的600幅不同的图像进行处理,能够得到一副近似真实的视差图,作为本发明采用的真实视差图。之后可以通过将测试结果与真实视差图进行比较判断算法的性能。
下面结合技术方案详细说明本方法:
一、基于捆绑约束的初步立体匹配
本发明用来获取初始视差图的方法是基于Yoon等人提出的自适应支持权值局部立体匹配算法的改进算法。在方法实施过程中,加入了对图像一致性约束以及几何相关约束的考虑,得到如公式(6)的改进的代价聚合方法。通过对比原算法与改进算法得到的结果可以看出,加入捆绑约束的匹配算法在深度边缘和弱纹理区域的准确度有了一定的提升。
此外,为了之后的表面插值工作做准备,在这一步骤中还利用得到的初始视差图,通过公式(5)计算得到初始视差的可信度分布图。通过观察图4中加入捆绑约束之后和原始的匹配算法的可信度分布图,也可以看出改进的算法具有的优越性。
二、基于图像分割的视差优化
对待匹配图像和初始视差图分别通过图像分割的方法分割成大量具有相同特性的区域。这里使用Comaniciu和Meers在文献[33]中提出的均值漂移图像分割算法对参考图像进行分割。根据视差图分割结果改进加权函数如式(8)。利用新的加权函数对初始视差图进行视差优化。该步骤的目的在于降低初始视差估计与原始图像颜色间的相关性,以减少误匹配的概率。
三、利用表面插值算法进行视差优化
首先根据图像分割的结果确定目标图像中的实体对象结构。使用二元三次方程在三维视差空间中对所有实体结构进行表面拟合。将拟合之后的曲面还原为视差信息,得到光滑连续的视差图。
为了强化实验结果的视觉舒适度,可以通过初始视差图分割来调整表面平滑。图5显示了图像表面插值算法的全部流程(以Venus为例)。首先分割初始视差图(如图5d),提取三维实体(如图5e)。然后再三维视差空间中,对视差图进行平滑适应(如图5f)得到最终的视差图。
四、数据分析
将实验结果与Middlebury数据库[27]中同样使用Winner-Take-All(WTA)策略的方法进行比较。所有图像对的参数设定为常数:采用Yoon在文献[3]的实验结果中提到算法的参数设定,其中,γa=31,γb=13,windowsize=33×33,(其中windowsize表示实验所选用支持窗口大小),T(parameterforTAD)=60,(TAD算法的最小阈值)。使用相同的参数设定对图像进行均值漂移分割,其中σs=3(spatial radius),σR=3(range radius),minR=35(minimum region size)。
图6给出了标准立体测试图像对以及匹配得到的视差图。通过观察产生的视差图可以看出尖锐的边缘被很好的保存了下来。而且在弱纹理和边缘区域得到了显著的改善。值得注意的是,在Venus和Teddy中弱纹理区域的误匹配大幅度的减少了,而在Cones中几乎消失。另外,遮挡区域的匹配在四幅图中都有显著的改善。最后还可以看到在Tsukuba和Cones中由于重复纹理产生的错误结构也消失了。因次可以证明,本文的算法在这些特殊区域具有一定的鲁棒性。另外,本文还对实验结果的视觉舒适性进行了加强。
实验得到的视差图结果已经提交,并且可以在Middlebury网站上获得。表1给出了本文方法的量化结果(参考本文)和文献[3]的结果(参考自适应支持权值算法),以及其他已经提交结果的最新的局部自适应支持权值相关算法共计7中方法的结果进行了比较,并根据比较结果进行了排名。表1中的数字表示错误像素(视差值的绝对误差大于1的像素)的百分比,分别列出了包括遮挡区域的所有像素(All),不包括遮挡区域的所有像素(Nonocc),以及非遮挡区域的深度不连续区域像素(Disc)。其他方法的数字是由原始文献提供或公开可用的源代码生成的。定性评价表明本文的方法在准确度上由于其他方法。报告中没有提及包含遮挡区域的所有图像区域的误匹配,因为WTA策略不适用与遮挡区域的处理。从表中可以看出,在所有区域的误差量上本文的算法都有了显著的改善,不论是遮挡区域、视差不连续区域或全部图像区域。另外,单独观察不连续区域可以看出该方法普遍的减少了误匹配概率(除了Cones)。在Venus和Tsukuba中的改善尤为明显。
本文算法的时间消耗主要集中在第一步,特别是双边滤波的计算过程。当前有很多提高双边滤波计算速度的算法,包括Paris和Durands提出的快速双边滤波算法[33],以及Yangs的实时双边滤波[34]。因此,本文算法的运算速度是可以解决的问题。
参考文献
REFERENCES
[1]Scharstein,D.,Szeliski,R.:A taxonomy and evaluation of dense two-frame stereo correspondence algorithms.Int.J.Comput.Vis.47(1C3),7C42(2002).
[2]Stefano,L.D.,Marchionni,M.,Mattoccia,S.:A fast area-based stereo matching algorithm.Image Vis.Comput.22(12),983C1005(2004).
[3]Yoon,K.J.,Kweon,I.S.:Adaptive support-weight approach for cor-respondence search.IEEE Trans.Pattern Anal.Mach.Intell.28(4),650C656(2006).
[4]4.Kim,J.,Kolmogorov,V.,Zabih,R.:Visual correspondence using ener-gy minimization and mutual information.In:Proceedings of Ninth IEEE International Conference on Computer Vision,2003,pp.1033C1040.IEEE(2003).
[5]Klaus,A.,Sormann,M.,Karner,K.:Segment-based stereo matching using belief propagation and a self-adapting dissimilarity measure.In:18th International Conference on Pattern Recognition,2006.ICPR 2006,vol.3,pp.15C18.IEEE(2006).
[6]L.Wang and R.Yang.Global stereo matching leveraged by sparse ground control points.CVPR 2011.
[7]C.Zhang,Z.Li,R.Cai,H.Chao,and Y.Rui.As-rigid-as-possible stereo under second order smoothness priors.ECCV 2014.
[8]M.Mozerov and J.van Weijer.Accurate stereo matching by two step global optimization.To appear in TIP2015.
[9]F.Besse,C.Rother,A.Fitzgibbon,and J.Kautz.PMBP:PatchMatch belief propagation for correspondence field estimation.BMVC 2012.
[10]E.Psota,J.Kowalczuk,J.Carlson,and L.Prez.A local iterative refinement method for adaptive support-weight stereo matching.IPCV 2011.
[11]S.Zhu,L.Zhang,and H.Jin.A locally linear regression model for boundary preserving regularization in stereo matching.ECCV 2012.
[12]C.Cigla and A.Alatan.Information permeability for stereo matching.Signal Processing:Image Communication,2013.
[13]L.De-Maeztu,S.Mattoccia,A.Villanueva,and R.Cabeza.Efficient aggregation via iterative block-based adapting support-weights.IC3D 2011.
[14]Q.Yang.Recursive bilateral filtering.ECCV 2012.
[15]N.Einecke and J.Eggert.Anisotropic median filtering for stereo disparity map refinement.VISAPP 2013.
[16]L.Wang,R.Yang,M.Gong,and M.Liao.Real-time stereo using approximated joint bilateral filtering and dynamic programming.Journal of Real-Time Image Processing 9(3):447-461,2014.
[17]X.Sun,X.Mei,S.Jiao,M.Zhou,Z.Liu,and H.Wang.Real-time local stereo via edge-aware disparity propagation.Pattern Recognition Letters,2014.
[18]Y.Wang,E.Dunn,and J.-M.Frahm.Increasing the efficiency of local stereo by leveraging smoothness constraints.3DIMPVT2012.
[19]C.Pham and J.Jeon.Domain transformation-based efficient cost aggre-gation for local stereo matching.IEEE TCSVT 2012.
[20]J.Jiao,R.Wang,W.Wang,S.Dong,Z.Wang,and W.Gao.Local stereo matching with improved matching cost and disparity refinement.IEEE Multimedia 2014.(An earlier version appeared at ICME 2014.)
[21]Y.Lin,N.Lu,X.Lou,F.Zou,Y.Yao,and Z.Du.Matching cost filtering for dense stereo correspondence.Mathematical Problems in Engineering,2013.
[22]S.Damjanovic,F.van der Heijden,and L.Spreeuwers.Local stereo matching using adaptive local segmentation.ISRN Machine Vision 2012.
[23]M.Antunes and J.Barreto.Efficient stereo matching using histogram aggregation with multiple slant hypothesis.IbPRIA 2013.
[24]J.Liu,C.Li,F.Mei,and Z.Wang.3D entity-based stereo matching with ground control points and joint second order smoothness prior.To appear in Visual Computer,2014.
[25]M.Bleyer,C.Rhemann,and C.Rother.PatchMatch stereo–stereo matching with slanted support windows.BMVC 2011.
[26]C.Strecha,R.Fransens,and L.J.Van Gool,Wide Baseline Stereo from Multiple Views:A Probabilistic Account,Proc.IEEE CS Conf.Computer Vision and Pattern Recognition,vol.1,pp.552-559,2004.
[27]S.B.Kang and R.Szeliski,Extracting View-Dependent Depth Maps from a Collection of Images,Intl J.Computer Vision,vol.58,no.2,pp.139-163,2004.
[28]Zabih R,Woodfill J.Non-parametric local transforms for computing visual correspondence.European Conference on Computer Vision,1994:151-158.
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于最小体积与优化约束条件的高光谱解混方法
- 基于不等式约束的辅助电容分布式半桥/单箝位混联mmc自均压拓扑的制作方法
- 基于不等式约束的辅助电容分布式全桥mmc自均压拓扑的制作方法
- 基于不等式约束的辅助电容集中式半桥mmc自均压拓扑的制作方法
- 基于不等式约束的无辅助电容式单箝位mmc自均压拓扑的制作方法
- 基于等式约束的辅助电容分布式单箝位mmc自均压拓扑的制作方法
- 基于等式约束的辅助电容集中式半桥mmc自均压拓扑的制作方法
- 基于等式约束的辅助电容分布式半桥mmc自均压拓扑的制作方法
- 基于等式约束的辅助电容集中式半桥/单箝位混联mmc自均压拓扑的制作方法
- 基于不等式约束的辅助电容分布式单箝位mmc自均压拓扑的制作方法