一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法与流程
本发明涉及模式识别方法,特别是涉及一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法。
背景技术:
分类算法就是基于分类器模型为待检测样本从可选的分类中选取最佳的类别假设,它属于人工智能中机器学习范畴,已经吸引了该领域相关研究者的极大关注。人们投入了大量的时间和精力研究诸如C4.5、支持向量机、贝叶斯算法、AdaBoost算法和K-最近邻分类算法等分类算法,并将它们应用于面部识别、笔迹验证、数据分析和医学应用等不同领域。
AdaBoost一词是来源于Adaptive Boosting(自适应增强)的缩写,是由Yoav Freund和Robert Schapire提出的机器学习元算法。其设计的指导原则为确保当前训练样本有最高分类精度。通过将不同的弱分类器(这里所谓的弱分类器是指分类精度稍稍好于随机猜测)合理的组合起来,形成强分类器,尽管每个弱分类器的分类精度不高,但最终的强分类器在分类性能上得到巨大提升。AdaBoost算法在某种意义上讲是自适应的,通过调整之前被弱分类器错分的样本权值,提高后续弱分类器对错分样本的重视程度,实现最终分类器模型的设计。正是基于此,一组弱分类器的合理设计可以结合成强分类器,获得一个整体上令人满意的分类精度。但是,像任何事情都具有两面性一样,尽管AdaBoost算法优点众多,但其对外点敏感,在一些情况下更容易受此影响而导致分类器整体性能的降级、失效。这是因为不断对不能正确分类的样本进行加权,尤其是对外点的不断加权,使得外点的权值快速增长。过大的外点权值引起分类器算法不断向外点偏离,进而背离大部分正常样本,不可避免的造成所设计分类器模型的降级。
寻找一种有效方式来限制外点权值的持续增长是AdaBoost算法设计分类器模型中亟待解决的问题。近年来人们提出了许多不同的方法用于抑制样本权值的无休止扩张,大多数局限于样本权值设置这一方向,算法或过于简单,对外点与正常样本不加区分;或算法复杂,使操作难度增大。而且因为阈值设置的不当存在着内、外点被误判断的情况,这也阻碍了算法的正确分类,不可避免的导致分类器的降级。为此,有必要寻找一种有效方式从分类模板的构建中去除外点的不利影响。本专利中,利用Ransac算法与AdaBoost算法相结合,解决外点引起的分类器模型训练中出现的降级问题。
技术实现要素:
针对传统的AdaBoost算法的缺陷和阈值设置方法的不足,提出一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法。不同于其他AdaBoost算法在弱分类器构建过程中单纯使用样本加权和权值控制的手段,本算法通过将Ransac算法引入到AdaBoost分类器模型构建过程中,并通过迭代建模的过程搜寻正确的样本,去除潜在外点,有效克服了现有AdaBoost算法中样本加权方法的缺点。
同时,借助于Ransac算法去除外点能力强这一优势,在全部基于AdaBoost算法构建的分类器模型中选取最佳分类模型,不但无需考虑如何为样本加权的问题,而且有效的消除了由外点引起的分类器模型降级。通过上述策略,本文最终实现了基于Ransac算法的鲁棒AdaBoost分类器构建,获得的分类器模型的设计完全不受外点的影响。
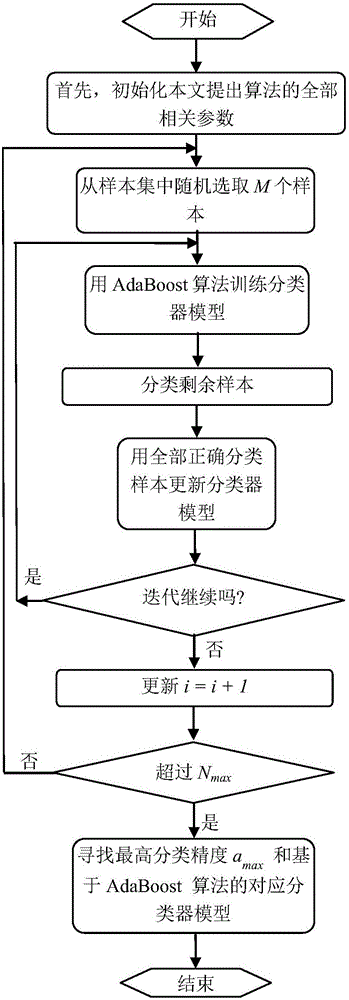
一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法,包括如下步骤:
(1)初始参数设置
初始化本算法全部参数,包括:设置分类模型的最大数为Nmax;设置当前正构建分类器模型为ith,最开始时设置i=1;设置构建每个分类器模型的最大迭代次数为Tmax;设置构建每个分类器模型的迭代次数为j,开始时设置j=1;设置每次初始构建分类器的样本个数为M。
(2)一定量样本随机选取
从样本集中随机的选取M个样本。
(3)基于AdaBoost分类器初始模型构建
基于这些选出的样本,利用AdaBoost算法训练强分类器,即,使得分类器模型最符合当前这M个样本。
(4)分类器模型更新
于AdaBoost算法用构建的分类器模型Ci分类剩余的样本;用所有被该模型正确分类的样本重新基于AdaBoost算法构建分类器模型Ci;用这个新的分类器再次判断满足该新分类器模型的全部样本,更新j=j+1;重复上述步骤4到步骤6直到满足分类器Ci的样本数不再变化或迭代次数已经超过了Tmax;。
(5)构建下一个分类器模型
更新i=i+1,判断建立的分类器模型是否已超过Nmax,如未超过回到步骤(2)。
(6)分类正确率计算
计算全部分类器模型所对应的样本分类精度。
(7)最终分类模型选出
比较全部分类器模型对应的正确分类精度,具有最高分类正确率的分类器模型被确定为最终选取的分类器模型。
与现有技术相比,本发明具有以下明显的优势和有益效果:
(1)本发明一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法,能有效去除外点干扰,不但无需进行样本加权阈值的设置,而且避免了样本加权阈值设置的不当存在着内、外点被误判断的情况。
(2)本发明利用Ransac算法即使在样本中含有大量外点的情况,仍然可以鲁棒的估计分类器模型参数而不受外点的影响的优点,实现了分类模型的准确构建。为验证本分类算法,运用本发明方法到笔迹验证试验中,对笔迹书写人身份进行判断,本文算法即使在样本中出现了15%的外点时,分类精度仍可达到95.67%。
附图说明
图1为本发明所提出的一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法功能框图;
图2为本发明所涉及方法的流程图;
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
如图1、2所示,本发明公开一种改善的基于Ransac算法的鲁棒AdaBoost分类器构建方法,包括以下步骤:
步骤1,初始参数设置
初始化本算法全部参数,包括:设置分类模型的最大数为100;设置当前正构建分类器模型为ith,最开始时设置i=1;设置构建每个分类器模型的最大迭代次数为100;设置构建每个分类器模型的迭代次数为j,开始时设置j=1;设置每次初始构建分类器的样本个数为50。本实验中,根据实验需求每次从HIT-MW样本库随机的选取200个不同人的笔迹样本,并按照一定比例把其中部分笔迹样本类别标错,人为的产生一定比例的外点。
步骤2,一定量样本随机选取
从笔迹样本集中随机的选取初始的50个样本。基于上述样本,利用当前笔迹样本抽取笔迹微结构特征作为AdaBoost算法中弱分类器的样本特征,并基于SVM构建弱分类器。对本文AdaBoost算法和其他AdaBoost算法抗外点干扰能力进行验证,重复本实验多次,求取每种算法在不同比例外点作用下的平均分类精度。
步骤3,基于AdaBoost分类器初始模型构建
基于这些随机选出的笔迹样本及其对应的笔迹微结构特征,使用SVM算法构建弱分类器,同时利用AdaBoost算法训练获得强分类器模型,使得该分类器模型最符合当前这50个笔迹样本的判断。
步骤4,分类器模型更新
基于AdaBoost算法用构建的分类器模型Ci分类剩余的样本;用所有被该模型正确分类的样本重新基于AdaBoost算法构建分类器模型Ci;用这个新的分类器再次判断满足该新分类器模型的全部样本,更新j=j+1;重复上述步骤3到步骤4直到满足分类器Ci的样本数不再变化或迭代次数已经超过了100。
步骤5,构建下一个分类器模型
更新i=i+1,判断建立的分类器模型数是否已超过100,如未超过回到步骤2。
步骤6,分类正确率计算
计算全部基于本专利算法构建的分类器模型对该笔迹样本库中全部笔迹样本的样本分类精度,分类精度Accuracy=(正确分类笔迹样本数)/(全部笔迹样本数)。
步骤7,最终分类模型选出
比较全部分类器模型对应的正确分类精度,具有最高分类精度Amax的分类器模型被确定为最终选取的分类器模型。
为了验证本发明的有效性,将本算法应用于笔迹验证实验,并与另外两种方法进行比较,三种分类方法的正确率如表1所示。
表1本发明方法与两种识别方法的比较结果
表1数据展示了本文提出的改进AdaBoost分类方法与另外两种AdaBoost方法的分类精度,三种方法分别是:本文方法,普通的没有权值控制的AdaBoost算法和固定权值阈值控制的AdaBoost方法。从表1可以看出,当样本中没有外点或外点较少时,三种方法的分类精度很接近。但随着外点在样本中所占比例的增多,另外两种方法分类精度收到很大负面影响,分类精度单调下降。而与这两种方法相比,本文算法凭借Ransac算法良好的去除外点干扰性能,在外点比例不断增加后分类精度依然稳定,对另外两种方法优势明显。对比于另外两种方法,本文算法即使在样本中出现了15%的外点时,分类精度仍可达到95.67%。
- 还没有人留言评论。精彩留言会获得点赞!