一种基于加速度传感器和多视图集成学习的语义化活动识别方法与流程
本发明涉及机器学习和人机交互技术,具体涉及一种基于加速度传感器和多视图集成学习的语义化活动识别方法。
背景技术:
用户的活动是理解用户情境和需求最重要的信息之一,而加速度传感器具有灵敏度高、耗电量低等优势。因此,基于加速度传感器的活动识别是普适计算和人机交互领域最重要的研究内容之一。目前的基于加速度传感器的活动识别研究大多集中在简单的身体活动(如行走、奔跑、站立)识别上。与简单的身体活动相比,语义化活动指吃饭、工作、购物等复杂的日常生活活动。语义化活动可提供更丰富的用户情境信息,同时识别难度更大。
现有语义化活动识别方法主要有以下几类:
(1)在模型层采用与简单身体活动识别类似的方法,在特征层引入更丰富的特征。例如,B.V.Mirchevska、V.Janko等人在“Recognition of high-level activities with a smartphone”(国际会议UbiComp 2015:1453-1461)中从GPS、麦克风、加速度传感器、生理传感器等多种传感器中抽取复杂的特征用于训练语义化活动识别模型。
(2)将语义化活动看成是一系列简单身体活动的组合,采用层次化模型识别语义化活动。例如,L.Liu、Y.Peng、M.Liu等人在“Sensor-based human activity recognition system with a multilayered model using time series shapelets”(Knowledge-Based Systems 90(2015):138-152)中基于时间序列匹配算法从简单身体活动序列中识别出语义化活动。
然而,现有语义化识别方法存在如下问题:
(1)基于单一视图描述语义化活动:单一视图难以适应不同语义化活动在不同日常生活环境下的复杂性,因此存在容易受噪声数据影响、难以覆盖所有语义化活动变化规律等问题。
(2)需要大量有标注样本训练模型:语义化识别模型需要大量有标注样本进行训练。然而,由于语义化活动本身的复杂性,用户难以在日常生活中提供足量的有标注样本。
技术实现要素:
为了克服已有语义化识别方法的识别模型泛化能力和适应能力较差、需要大量有标注样本训练模型的不足,本发明提供了一种提高识别模型泛化能力和适应能力、可利用有限的有标注样本训练模型的基于加速度传感器和多视图集成学习的语义化活动识别方法。
本发明解决其技术问题所采用的技术方案是:
一种基于加速度传感器和多视图集成学习的语义化活动识别方法,所述语义化活动识别方法包括以下步骤:
(1)基于简单身体活动描述语义化活动,构建简单身体活动特征视图,步骤如下:
(1-1)简单身体活动识别模型训练:给定一个简单身体活动训练集,即大量标注了简单身体活动类型、长度为w的加速度数据序列,首先,从每个加速度数据序列中抽取各类时域特征和频域特征,形成运动特征向量;然后,基于运动特征向量和简单身体活动类型标注,训练得到简单身体活动识别模型;
(1-2)简单身体活动序列生成:对每一个语义化活动样本,即一个长度为W的加速度数据序列,其中W>w,首先,将其分割为多个大小为w的数据窗口,形成数据窗口序列;然后,从每个数据窗口中抽取上述运动特征向量,并将其输入训练得到的简单身体活动识别模型,得到简单身体活动识别结果;最后,将数据窗口序列转化为简单身体活动序列;
(1-3)简单身体活动特征视图构建:首先,从每个简单身体活动序列中抽取简单身体活动特征,包括如下三类:
集合特征:计算每种简单身体活动类型出现次数与简单身体活动序列长度的比值;
序列特征:首先,将简单身体活动序列中所有连续出现的同类型多个简单身体活动压缩为1个,得到压缩简单身体活动序列;然后,从压缩简单身体活动序列中挖掘出长度为2到长度为M的所有序列模式;最后,计算每个序列模式在简单身体活动序列所对应的压缩简单身体活动序列中出现的次数;
时间特征:首先,计算每种简单身体活动类型的所有单次持续时间;然后,计算每种简单身体活动类型单次持续时间的均值、中值和标准差;
然后,基于上述简单身体活动特征构建特征向量,并将其作为描述语义化活动的简单身体活动特征视图;
(2)基于潜在主题分布描述语义化活动,构建潜在主题分布特征视图,步骤如下:
(2-1)加速度数据序列窗口化:对每一个语义化活动样本,将其分割为多个大小为w的数据窗口,形成数据窗口序列;然后,从每个数据窗口中抽取上述运动特征向量,并对运动特征向量进行归一化;
(2-2)数据窗口聚类序列生成:首先,基于运动特征向量间的欧式距离度量数据窗口间距离,对数据窗口进行聚类,使得每个数据窗口对应一个数据窗口聚类;然后,将数据窗口序列转化为数据窗口聚类序列;
(2-3)潜在主题分布特征视图构建:首先,将数据窗口聚类看成“词”,将数据窗口聚类序列看成“文档”,基于LDA算法挖掘潜在主题,并得到“文档”的“主题”分布;然后,基于“文档”的“主题”分布得到数据窗口序列包含不同潜在主题的概率向量,并将其作为描述语义化活动的潜在主题分布特征视图;
(3)基于半监督技术对两种特征视图进行协同学习,并对学习结果进行融合得到语义化活动识别模型。
进一步,所述步骤(3)中,给定有标注语义化活动样本集L和无标注语义化活动样本集U,训练语义化活动识别模型的步骤如下:
(3-1)有监督训练:首先,基于简单身体活动特征视图为L中所有样本构建简单身体活动特征向量,并基于语义化活动类型标注和简单身体活动特征向量训练识别模型SM;然后,基于潜在主题分布特征视图为L中所有样本构建潜在主题分布特征向量,并基于语义化活动类型标注和潜在主题分布特征向量训练识别模型TM;
(3-2)半监督训练:首先,基于识别模型SM对U中所有样本进行识别,为每类语义化活动挑选出识别置信度最高的n个样本,将识别结果作为其标注,得到伪标注样本集并放入L;然后,基于识别模型TM对U中所有样本进行识别,为每类语义化活动挑选出识别置信度最高的n个样本,将识别结果作为其标注,得到伪标注样本集并放入L;
(3-3)算法迭代:若U中样本数量不足或迭代次数超过指定阈值,则输出SM和TM,反之,则转向步骤(3-1);
(3-4)模型融合:对有标注语义化活动样本集L中每一个样本,分别使用SM和TM对其进行识别,得到SM和TM识别其为每类语义化活动的概率,进而得到2个概率向量;然后,将这2个概率向量和语义化活动类型标注作为新的样本,构建新的样本集NL;最后,基于NL、采用Logistic Regression算法训练得到最终的语义化活动识别模型FM。
再进一步,所述步骤(1-1)中,采用C4.5算法训练得到简单身体活动识别模型。
更进一步,所述步骤(1-3)中,抽取序列特征过程中,基于Apriori算法从压缩简单身体活动序列中挖掘出长度为2到长度为M的所有序列模式。
所述步骤(2-2)中,基于K-Medoids算法对数据窗口进行聚类。
本发明的有益效果主要表现在:1、基于多视图描述语义化活动,提高了识别模型的泛化能力和适应能力。2、基于协同学习技术利用未标注数据训练识别模型,克服了有标注样本不足的问题。
附图说明
图1为基于加速度传感器和多视图集成学习的语义化活动识别方法的流程图;
图2为简单身体活动特征视图构建的流程图;
图3为潜在主题分布特征视图构建的流程图;
图4为语义化活动识别模型训练的流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图4,一种基于加速度传感器和多视图集成学习的语义化活动识别方法,所述语义化识别方法包括以下步骤:
(1)基于简单身体活动描述语义化活动,构建简单身体活动特征视图。
(2)基于潜在主题分布描述语义化活动,构建潜在主题分布特征视图。
(3)基于半监督技术对两种特征视图进行协同学习,并对学习结果进行融合得到语义化活动识别模型。
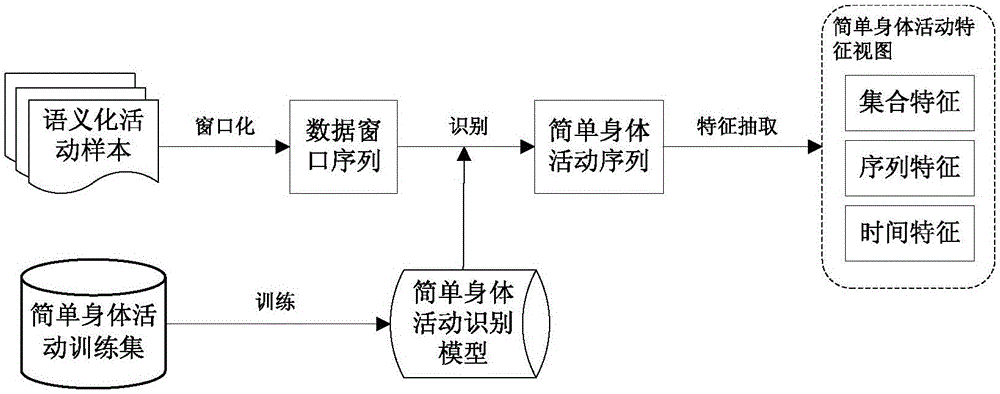
参照图2,所述步骤(1)中,构建简单身体活动特征视图的详细步骤如下:
(1-1)简单身体活动识别模型训练:给定一个简单身体活动训练集(即大量标注了简单身体活动类型、长度为w的加速度数据序列),首先,从每个加速度数据序列中抽取各类时域特征(包括:均值、标准差、四分位差、能量)和频域特征(包括:频率幅值、频域熵),形成运动特征向量。然后,基于运动特征向量和简单身体活动类型标注,采用C4.5算法训练得到简单身体活动识别模型。
(1-2)简单身体活动序列生成:对每一个语义化活动样本(即一个长度为W的加速度数据序列,其中W>w),首先,将其分割为多个大小为w的数据窗口,形成数据窗口序列。然后,从每个数据窗口中抽取上述运动特征向量,并将其输入训练得到的简单身体活动识别模型,得到简单身体活动识别结果。最后,将数据窗口序列转化为简单身体活动序列。
(1-3)简单身体活动特征视图构建:首先,从每个简单身体活动序列中抽取简单身体活动特征,包括如下三类:
集合特征:计算每种简单身体活动类型出现次数与简单身体活动序列长度的比值。
序列特征:首先,将简单身体活动序列中所有连续出现的同类型多个简单身体活动压缩为1个,得到压缩简单身体活动序列;然后,基于Apriori算法从压缩简单身体活动序列中挖掘出长度为2到长度为M的所有序列模式;最后,计算每个序列模式在简单身体活动序列所对应的压缩简单身体活动序列中出现的次数。
时间特征:首先,计算每种简单身体活动类型的所有单次持续时间;然后,计算每种简单身体活动类型单次持续时间的均值、中值、标准差。
然后,基于上述简单身体活动特征构建特征向量,并将其作为描述语义化活动的简单身体活动特征视图。
参照图3,所述步骤(2)中,构建潜在主题分布特征视图的详细步骤如下:
(2-1)加速度数据序列窗口化:对每一个语义化活动样本(即一个长度为W的加速度数据序列),将其分割为多个大小为w的数据窗口,形成数据窗口序列。然后,从每个数据窗口中抽取上述运动特征向量,并对运动特征向量进行归一化。
(2-2)数据窗口聚类序列生成:首先,基于运动特征向量间的欧式距离度量数据窗口间距离,基于K-Medoids算法对数据窗口进行聚类,使得每个数据窗口对应一个数据窗口聚类。然后,将数据窗口序列转化为数据窗口聚类序列。
(2-3)潜在主题分布特征视图构建:首先,将数据窗口聚类看成“词”,将数据窗口聚类序列看成“文档”,基于LDA算法挖掘潜在主题,并得到“文档”的“主题”分布。然后,基于“文档”的“主题”分布得到数据窗口序列包含不同潜在主题的概率向量,并将其作为描述语义化活动的潜在主题分布特征视图。
参照图4,所述步骤(3)中,给定有标注语义化活动样本集L和无标注语义化活动样本集U,训练语义化活动识别模型的详细步骤如下:
(3-1)有监督训练:首先,基于简单身体活动特征视图为L中所有样本构建简单身体活动特征向量,并基于语义化活动类型标注和简单身体活动特征向量训练识别模型SM。然后,基于潜在主题分布特征视图为L中所有样本构建潜在主题分布特征向量,并基于语义化活动类型标注和潜在主题分布特征向量训练识别模型TM。
(3-2)半监督训练:首先,基于识别模型SM对U中所有样本进行识别,为每类语义化活动挑选出识别置信度最高的n个样本,将识别结果作为其标注,得到伪标注样本集USM,n×S并放入L(其中,S为语义化活动类型的数量)。然后,基于识别模型TM对U中所有样本进行识别,为每类语义化活动挑选出识别置信度最高的n个样本,将识别结果作为其标注,得到伪标注样本集UTM,n×S并放入L。
(3-3)算法迭代:若U中样本数量不足或迭代次数超过指定阈值,则输出SM和TM。反之,则转向步骤(3-1)。
(3-4)模型融合:对有标注语义化活动样本集L中每一个样本,分别使用SM和TM对其进行识别,得到SM和TM识别其为每类语义化活动的概率,进而得到2个概率向量(其中,PSM,ik为SM识别样本i为语义化活动类型k的概率,PTM,ik为TM识别样本i为语义化活动类型k的概率,1≤k≤S)。然后,将这2个概率向量和语义化活动类型标注作为新的样本,构建新的样本集NL。最后,基于NL、采用Logistic Regression算法训练得到最终的语义化活动识别模型FM。
- 还没有人留言评论。精彩留言会获得点赞!