解决方案搜寻系统及解决方案搜寻系统的操作方法与流程
本发明涉及一种解决方案搜寻系统,特别涉及一种利用巨量资料及资料探勘技术的解决方案搜寻系统。
背景技术:
一个产品的成功与否除了与研发技术息息相关之外,亦须要大量的测试以确保产品的稳定性,尤其是要求高稳定性、高信赖度的科技产品,如工业仪器、行动装置、工作站、个人计算机或服务器…等产品,对于品管测试的标准即更加严格。而当产品被检测出问题时,必须经由复制问题、搜集及分析相关资料、找出问题可能的成因、提出可能的解决方案并验证所提出的解决方案…等步骤以确保检测出的问题得以被适当地解决,这些过程不仅可能十分耗时,甚至可能导致产品错过进入市场的时机,且实行上又必需仰赖工程师的个人经验及专业程度;亦即工程师的经验及专业程度是否足够将会大大地影响提出解决方案所需要的时间,同时也可能影响了所提出的解决方案是否能够彻底解决问题,导致解决方案的质量不易掌握。另外,由于个人经验不易传承,因此即便欲解决的问题相同或类似,不同的工程师仍可能必须重复上述的过程才能得出解决方案,这样的做法不仅没有效率,也无法确保工程师能找出最适切的解决方案。
此外,对于同类型的产品,其出现相同或相似问题的比例甚高,过去虽亦有将解决方案记录或存档的作法,但由于问题种类繁多,所牵涉到的信息量相当庞大,加上各工程师对于问题描述的方式可能不一致,因此难以系统化地储存,导致在实行上,工程师仍不易搜寻到相关的解决方案,而难以达成使工程师共享经验的目的。
技术实现要素:
本发明的一实施例提供一种解决方案搜寻系统,解决方案搜寻系统包括运算服务器、巨量数据库、数据库服务器、建模服务器及中枢服务器。
当接收到复数个已解决的问题描述档案时,运算服务器将通用标准词对照表与每一已解决的问题描述档案中的问题成因栏位的文字对照以产生已解决的问题描述档案的主要分类代码,根据主要分类代码所对应的子标准词对照表与已解决的问题描述档案中的文字对照以产生已解决的问题描述档案的次要分类代码,至少根据已解决的问题描述档案的主要分类代码及次要分类代码产生已解决的问题描述档案的解决方案代码,及根据已解决的问题描述档案及资料探勘算法产生已解决的问题描述档案的模型输入档案。
数据库服务器根据已解决的问题描述档案的解决方案代码将已解决的问题描述档案中的解决方案储存至巨量数据库。
建模服务器根据资料探勘算法及已解决的问题描述档案的模型输入档案及解决方案代码建立预测模型。
当接收到复数个已解决的问题描述档案时,中枢服务器将复数个已解决的问题描述档案传送至运算服务器。中枢服务器将运算服务器所产生的已解决的问题描述档案所对应的模型输入档案、解决方案代码传送至建模服务器。
本发明的另一实施例提供一种解决方案搜寻系统的操作方法,解决方案搜寻系统包括运算服务器、巨量数据库、数据库服务器及中枢服务器。解决方案搜寻系统的操作方法包括当中枢服务器接收到复数个已解决的问题描述档案时,中枢服务器将复数个已解决的问题描述档案传送至运算服务器,运算服务器将通用标准词对照表与每一已解决的问题描述档案中的问题成因栏位的文字对照以产生已解决的问题描述档案的主要分类代码,运算服务器根据主要分类代码所对应的子标准词对照表与已解决的问题描述档案中的文字对照以产生已解决的问题描述档案的次要分类代码,运算服务器至少根据已解决的问题描述档案的主要分类代码及次要分类代码产生已解决的问题描述档案的解决方案代码,运算服务器根据已解决的问题描述档案及资料探勘算法产生已解决的问题描述档案的模型输入档案,数据库服务器根据已解决的问题描述档案的解决方案代码将已解决的问题描述档案中的解决方案储存至巨量数据库,中枢服务器将运算服务器所产生的已解决的问题描述档案所对应的模型输入档案、解决方案代码传送至建模服务器,及建模服务器根据资料探勘算法及已解决的问题描述档案的模型输入档案及解决方案代码建立预测模型。本发明关联于一种高效率的解决方案搜寻系统,可有效解决现行物联网架构中无法精确命中问题核心的缺陷。
附图说明
图1为本发明一实施例的解决方案搜寻系统的示意图。
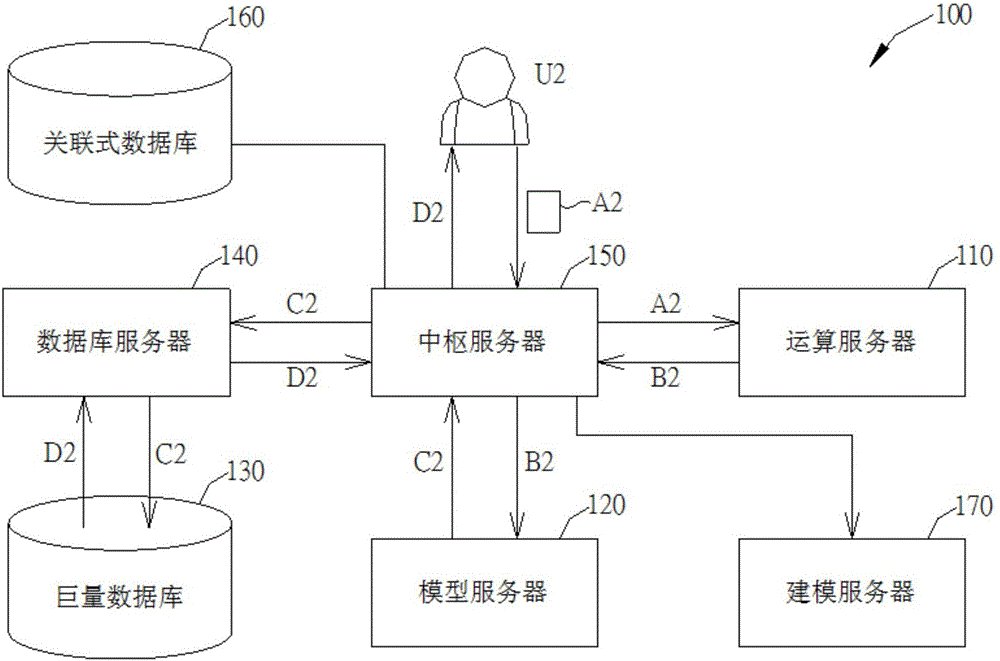
图2为图1的解决方案搜寻系统的使用情境示意图。
图3为本发明一实施例的解决方案搜寻系统的操作方法流程图。
图4为本发明另一实施例的解决方案搜寻系统的操作方法流程图。
图5为本发明一实施例的标准词对照表的部分内容。
图中符号说明:
100:解决方案搜寻系统
110:运算服务器
120:模型服务器
130:巨量数据库
140:数据库服务器
150:中枢服务器
160:关联式数据库
170:建模服务器
A1:第一问题描述档案
B1:第一模型输入档案
C1:第一解决方案代码
D1:第一解决方案
MC:主要分类代码
SC1:第一次要分类代码
SC2:第二次要分类代码
U1、U2:使用者
A2:第二问题描述档案
B2:第二模型输入档案
C2:第二解决方案代码
D2:第二解决方案
300、400:方法
S310至S380、S410至S470:步骤
具体实施方式
图1为本发明一实施例的解决方案搜寻系统100的示意图。解决方案搜寻系统100包括运算服务器110、模型服务器120、巨量数据库130、数据库服务器140、中枢服务器150、关联式数据库160及建模服务器170。
在本发明的部分实施例中,使用者可以将其操作某产品系统时所遭遇到的问题整理成问题描述档案,并将问题描述档案上传到解决方案搜寻系统100之后,解决方案搜寻系统100中的模型服务器120就可以利用其内部的预测模型分析问题描述档案,并找出产品所遭遇到的问题的可能解决方案。
问题描述档案可利用文字的形式来记载与产品系统问题相关的信息,其内容可包括系统的问题描述、观察到的现象及结果、与产品系统问题相关的的子系统为何以及发生问题的经过(亦即,可说明如何能够复制问题),但不限于上述信息。
然而在使用者利用解决方案搜寻系统100搜寻解决方案之前,解决方案搜寻系统100也允许使用者按照之前解决产品问题的相关经验来建立预测模型。在本发明的部分实施例中,当使用者U1欲透过解决方案搜寻系统100来建立预测模型时,使用者U1须先提供复数个已解决的第一问题描述档案A1,每一已解决的第一问题描述档案A1除了包括一般问题描述档案所具有用来记录与系统问题的相关栏位,如系统问题及现象的描述、系统问题所属的子系统、发生问题的经过...等栏位之外,还会包括与解决问题有关的信息,例如系统问题的成因说明栏位、出现问题的子系统栏位、解决方案…等,其中解决方案中除了具有解决问题的建议方法外,还包括对应的解决方案代码。如此一来,解决方案搜寻系统100才能够利用对应的资料探勘算法找寻出各个已解决的第一问题描述档案A1与其解决方案的间的关联,并建立预测模型,在此所使用的资料探勘算法并没有做特别限定,凡是可用来计算关联度的算法皆可用于此计算。在本发明的部分实施例中,解决方案搜寻系统100是透过各个已解决的第一问题描述档案A1的解决方案代码来将各个已解决的第一问题描述档案A1进行分类。
虽然每一个第一问题描述档案A1的第一解决方案D1中原本就可能已包括使用者U1所设定的解决方案代码,然而运算服务器110还可进一步根据第一问题描述档案A1中与解决问题有关的栏位中的信息,如成因说明栏位、出现问题的子系统栏位,来调整最终每一个第一问题描述档案A1的第一解决方案D1中所包括的第一解决方案代码C1。例如可根据成因说明栏位的内容取得关键字的方式以产生解决方案代码,使得凡是具有相同成因说明的解决方案皆可具有相同的解决方案代码。
在本发明的部分实施例中,若已解决的问题描述档案中所预设的解决方案代码包括复数个子代码,如bios.mrc,其中bios表示已解决的问题描述档案与基本输入输出系统(basic input/output system)相关,而mrc表示已解决的问题描述档案系与基本输入输出系统中的存储器参照码(memory reference code)相关,则运算服务器110可以根据其他栏位的信息将已解决的问题描述档案中的解决方案代码bios.mrc扩充至bios.mrc.i2c,表示已解决的问题描述档案系与基本输入输出系统中存储器参照码的内部整合电路(Inter-integrated circuit,I2C)相关。
当解决方案代码所包括的子代码数目越多时,表示解决方案搜寻系统100将问题分类得越细,因此具有相同解决方案代码的已解决的问题描述档案就会越少,而每个解决方案代码所对应到的解决方案通常也会变少。反之,当解决方案代码所包括的子代码数目越少时,表示将问题分类得越粗,因此每个解决方案代码所对应到的解决方案通常也会较多。然而不论是解决方案代码所对应到的解决方案太多或太少,都可能会降低解决方案搜寻系统100的预测准确度。举例来说,若是解决方案代码所对应到的解决方案太多,则不相同类型的问题描述档案很可能仍会被设定具有相同解决方案代码,而使用者则必须在众多可能的解决方案中,逐一尝试才有可能找到合适的解决方案。而若是解决方案代码所对应到的解决方案太少,则即便类型相近的问题描述档案也可能会被设定具有不同的解决方案代码,因此即便在解决方案搜寻系统100中已存在能够解决问题的解决方案情况下,也可能无法适时提供给使用者参考。
为了维持解决方案搜寻系统100的预测准确率,在图1的实施例中,当运算服务器110接收到复数个已解决的第一问题描述档案A1时,运算服务器110可先将通用标准词对照表与每一已解决的第一问题描述档案A1中的问题成因栏位的文字对照以产生已解决的第一问题描述档案A1的主要分类代码MC。通用标准词对照表可能包括与系统相关的词汇,例如「韧体(firmware)」、「基本输入输出系统(bios)」、「基板管理控制器(bmc)」、「电源(power)」、…等等,运算服务器110可先比对已解决的第一问题描述档案A1的问题成因栏位中是否有出现与通用标准词对照表中相同或近似的词汇,并将这些相同或近似的词汇以标准的表示方式产生主要分类代码MC。
举例来说,若是第一问题描述档案A1中的问题成因栏位中说明:「基本输入输出系统中对基板控制器的暂存器设定有误。…」,则由于在这段说明中,出现了「基本输入输出系统」及「基板控制器」,而分别与通用标准词对照表中所述的「基本输入输出系统(bios)」及「基板管理控制器(bmc)」相同或相近,因此运算服务器110即可将主要分类代码MC设定为「bios.bmc」。此外,为了避免第一问题描述档案A1中的问题成因栏位中的说明文字行文顺序有异,而导致实质上相同的内容却得出相异的分类例如「bios.bmc」及「bmc.bios」,在本发明的部分实施例中,通用标准词对照表还可进一步限定每一个标准词的优先权重,因此运算服务器110会按照特定的顺序产生主要分类代码MC。
产生主要分类代码MC之后,运算服务器110会进一步根据主要分类代码MC所对应的第一子标准词对照表与已解决的第一问题描述档案A1中的文字对照以产生已解决的第一问题描述档案A1的第一次要分类代码SC1。举例来说,若第一问题描述档案A1的主要分类代码MC包括代码bmc,表示第一问题描述档案A1可能与基板管理控制器有关,因此运算服务器110会根据与基板管理控制器有关的第一子标准词对照表来继续与第一问题描述档案A1中的文字对照,在此情况下,运算服务器110所利用的第一子标准词对照表就会包括与基板管理控制器相关的字词。接着运算服务器110就可根据已解决的第一问题描述档案A1的主要分类代码MC及第一次要分类代码SC1产生已解决的第一问题描述档案A1的第一解决方案代码C1。透过这样的方式,就能够有效且精准的将各个第一问题描述档案A1进行分类。
为了避免因为解决方案代码所对应到的解决方案太多,而导致解决方案搜寻系统100的预测准确率降低的情况,在本发明的部分实施例中,当对应于第一解决方案代码C1的解决方案的数量大于上限值时,例如大于30个解决方案时,运算服务器110还可根据第一解决方案代码C1中的第一次要分类代码SC1所对应的第二子标准词对照表与已解决的第一问题描述档案A1中的文字对照以产生已解决的第一问题描述档案A1的第二次要分类代码SC2。也就是说,运算服务器110可利用上述产生第一次要分类代码SC1的相似原理,亦即运算服务器110可利用与第一次要分类代码SC1相关的第二子标准词对照表来将第一问题描述档案A1做更精准细致的分类,接着再根据已解决的第一问题描述档案A1的主要分类代码MC、第一次要分类代码SC1及第二次要分类代码SC2更新已解决的第一问题描述档案A1的第一解决方案代码C1。如此一来,就能够将各个第一问题描述档案A1进行更细致的分类,也可以避免预测准确率降低。在本发明的部分实施例中,只要解决方案搜寻系统100中具有足够能对应的子标准词对照表,运算服务器110就可在解决方案代码所对应的解决方案的数量大于上限值时,持续依照上述的方法进行分类,直到解决方案代码所对应的解决方案的数量不大于上限值。
相对地,为了避免因为解决方案代码所对应到的解决方案太少,而导致解决方案搜寻系统100的预测准确率降低,在本发明的部分实施例中,当对应于第一解决方案代码C1的解决方案的数量小于下限值,例如小于10个解决方案,且第一解决方案代码C1的一最近解决分类代码所对应的解决方案的数量与第一解决方案代码C1所对应的解决方案的数量的和不大于上限值时,例如不大于30个解决方案时,运算服务器110即可将第一解决方案代码C1更新为与的最近的解决分类代码,或将第一解决方案代码C1及其最近解决分类代码共同更新为相同的新解决分类代码。
举例来说,第一解决方案代码C1若为「bios.bmc.i2c.mrc.spd」,则与第一解决方案代码C1最近的解决方案代码应与第一解决方案代码C1有最相近的分类,例如可能依序为「bios.bmc.i2c.mrc」、「bios.bmc.i2c.spd」、「bios.bmc.mrc.spd」、「bios.bmc.i2c」…,因此运算服务器110可检查上述这些与第一解决方案代码C1相近的解决方案代码所对应到的解决方案数量为何,若与第一解决方案代码C1最近的解决方案代码所对应到的解决方案数量与第一解决方案代码C1所对应到的解决方案数量的和不大于上限值,此时就可以将两者合并,合并时可考虑沿用其中一者的解决方案代码。例如代码C1为bios.mrc.i2c.spd且其最近的解决方案代码为bios.i2c,且此两者的所对应到的解决方案数量和为10,因其小于上限值30,故可将bios.mrc.i2c.spd代码所对应到的解决方案加入代码bios.i2c。此外也可另外建立新的解决方案代码,例如以两者共有的部分作为两者的新解决方案代码,举例来说,若代码C1为firmware.bios.mrc且其最近的解决方案代码为firmware.bios.i2c,又此两者的所对应到的解决方案数量和为20,因其小于上限值30,故可将此两个代码所对应到的解决方案合并,因此两代码共同keyword为firmware与bios,故新的代码为firmware.bios)。
透过上述的方式解决方案搜寻系统100就可以对每一个解决方案代码进行检查,以避免有解决方案代码所对应到的解决方案太多或太少的情况,进而达到确保预测准确率的效果。
产生各个已解决的第一问题描述档案A1的第一解决方案代码C1之后,运算服务器还会根据已解决的第一问题描述档案A1及欲建立的预测模型所使用的资料探勘算法来产生已解决的第一问题描述档案A1的第一模型输入档案B1。
在本发明的一实施例中,运算服务器110可根据第一问题描述档案A1的文字产生关键词(attributes)描述档案。关键词(attributes)描述档案可由多个关键词(attributes)所组成,每一个关键词是由一对关键词名字(attribute name)与关键词的值(attribute value)所组成,在本发明的一实施例中,可以json的文字格式来描述。当第一问题描述档案A1使用非固定格式文字条列与系统问题相关的信息时,运算服务器110亦可使用正规表示法(regular expression)来识别关键词名字与取得关键词的值。再者,运算服务器110可利用标准词对照表与第一问题描述档案A1的文字对照以产生关键词描述档案,其做法与前述根据通用标准词对照表对照产生第一问题描述档案A1的主要分类代码MC的方式相近。然而第一问题描述档案A1的第一模型输入档案B1是用来测试及训练预测模型,因此在建立关键词描述档案时,运算服务器110将对照第一问题描述档案A1中与解决问题非直接有关的信息,例如解决问题成因或解决方案的栏位以外的其他栏位。
图5为本发明一实施例的标准词对照表的部分内容。透过标准词对照表可以标准化同义的字汇与词汇,如此即可较有效率及正确地表达关键词描述档案的语意。此外,为避免关键词描述档案的语意的混淆,所有关键词的值皆可以小写表示。
完成关键词描述档案后,运算服务器110可自关键词描述档案中优先挑选出权重较高或使用者预设偏好的关键词作为预测因子(predictors)以产生预测因子档案,再根据预测因子档案及预测模型产生第一模型输入档案B1,例如运算服务器110可根据预测模型的特性调整预测因子档案,例如在CBayes模型中,并不考虑数字的相依性,因此可将预测因子档案中的数字部分删除,以产生第一模型输入档案B1,然而不同的预测模型对于输入档案的格式有不同要求,本发明并不以上述实施例为限。
运算服务器110产生每一已解决的第一问题描述档案A1所对应的第一模型输入档案B1、第一解决方案代码C1之后,中枢服务器150会将每一已解决的第一问题描述档案A1所对应的第一模型输入档案B1、第一解决方案代码C1传送至建模服务器170,而建模服务器170则可根据每一已解决的第一问题描述档A1的第一模型输入档案B1及第一解决方案代码C1,以及建模服务器170所对应的资料探勘算法,例如Bayes、CBayes或SGD等算法,来建立预测模型。建模服务器170完成建立预测模型后,解决方案搜寻系统100即可利用建模服务器170所建立的预测模型来搜寻系统问题的可能解决方案。
此外,中枢服务器150会将每一已解决的第一问题描述档案A1所对应的第一解决方案代码C1传送至数据库服务器140,而数据库服务器140则会根据已解决的第一问题描述档案A1的第一解决方案代码C1将已解决的第一问题描述档案A1中的第一解决方案D1储存至巨量数据库130。也就是说,数据库服务器140会将具有相同第一解决方案代码C1的第一问题描述档案A1的第一解决方案D1存放在巨量数据库130中相同的栏位中。因此之后若有其他使用者上传了具有相同解决方案代码的问题描述档案,解决方案搜寻系统100就可以输出栏位中的各个第一解决方案D1,以供其他使用者选择尝试。
举例来说,图2为本发明为解决方案搜寻系统100的另一使用情境示意图。在图2中,当使用者U2将未解决的第二问题描述档案A2上传至解决方案搜寻系统100时,中枢服务器150会将未解决的第二问题描述档案A2传送至运算服务器110。当运算服务器110接收到未解决的第二问题描述档案A2时,运算服务器110会根据第二问题描述档案A2及模型服务器120所使用的资料探勘算法产生第二问题描述档案A2的第二模型输入档案B2。接着中枢服务器150即可将第二问题描述档案A2的第二模型输入档案B2传送至模型服务器120,模型服务器120则可利用先前建模服务器170所建立的预测模型分析第二模型输入档案B2与先前所接收到的复数个已解决的第一问题描述档案中的哪些已解决的第一问题描述档案较为接近,并进而产生第二问题描述档案A2的第二解决方案代码C2。中枢服务器150将第二解决方案代码C2传送至数据库服务器140之后,数据库服务器140则可根据第二解决方案代码C2由巨量数据库130读取第二解决方案D2,最后中枢服务器150则会输出数据库服务器140由巨量数据库130所读取的第二解决方案D2以供使用者U2参考。
在本发明的一实施例中,数据库服务器140及巨量数据库130可为支援Hadoop Distribute File System(HDFS)、Hadoop Map/Reduce及Hive…等系统的数据库服务器及巨量数据库,或可支援其他适合处理巨量资料的数据库系统,以符合解决方案搜寻系统100对于快速处理、储存大量资料的需求。此外,关联式数据库160可例如为MySql、PostgreSql…等关联式数据库,其主要可储存中枢服务器150在运算时所需的小量及/或暂时性的资料。
透过上述本发明实施例的解决方案搜寻系统100,即可使工程师分享彼此过去解决系统问题的经验,而能轻易地搜寻到可能的解决方案以减少解决产品问题的时间,并提升解决方案的质量。此外,透过自动建立解决方案代码以及将解决方案代码持续分类或合并的作法,解决方案搜寻系统100还能够进一步避免因未解决方案代码所对应的解决方案太多或太少,所造成解决方案搜寻系统准确率降低的问题。
图3为本发明一实施例中,解决方案搜寻系统100的操作方法300的流程图。解决方案搜寻系统的操作方法300包括步骤S310至S380:
S310:当中枢服务器150接收到复数个已解决的第一问题描述档案A1时,中枢服务器150将复数个已解决的第一问题描述档案A1传送至运算服务器110;
S320:运算服务器110将通用标准词对照表与每一已解决的第一问题描述档案A1中的问题成因栏位的文字对照以产生已解决的第一问题描述档案A1的主要分类代码MC;
S330:运算服务器110根据主要分类代码MC所对应的第一子标准词对照表与已解决的第一问题描述档案A1中的文字对照以产生已解决的第一问题描述档案A1的第一次要分类代码SC;
S340:运算服务器110至少根据已解决的第一问题描述档案A1的主要分类代码MC及第一次要分类代码SC产生已解决的第一问题描述档案A1的第一解决方案代码C1;
S350:运算服务器110根据已解决的第一问题描述档案A1及资料探勘算法产生已解决的第一问题描述档案A1的第一模型输入档案B1;
S360:数据库服务器140根据已解决的第一问题描述档案A1的第一解决方案代码C1将已解决的第一问题描述档案A1中的第一解决方案D1储存至巨量数据库130;
S370:中枢服务器150将运算服务器110所产生的已解决的第一问题描述档案A1所对应的第一模型输入档案B1、第一解决方案代码C1传送至建模服务器170;
S380:建模服务器170根据资料探勘算法及已解决的第一问题描述档案A1的第一模型输入档案B1及第一解决方案代码C1建立预测模型。
此外,为了避免因为解决方案代码所对应到的解决方案太多,而导致解决方案搜寻系统100的预测准确率降低的情况,在本发明的部分实施例中,方法300还可在对应于第一解决方案代码C1的解决方案的数量大于上限值时,例如大于30个解决方案时,使运算服务器110可根据第一解决方案代码C1中的第一次要分类代码SC1所对应的第二子标准词对照表与已解决的第一问题描述档案A1中的文字对照以产生已解决的第一问题描述档案A1的第二次要分类代码SC2。也就是说,运算服务器110可利用上述产生第一次要分类代码SC1的相似原理,亦即运算服务器110可利用与第一次要分类代码SC1相关的第二子标准词对照表来将第一问题描述档案A1做更精准细致的分类,接着再根据已解决的第一问题描述档案A1的主要分类代码MC、第一次要分类代码SC1及第二次要分类代码SC2更新已解决的第一问题描述档案A1的第一解决方案代码C1。如此一来,就能够将各个第一问题描述档案A1进行更细致的分类,也可以避免预测准确率降低。在本发明的部分实施例中,只要解决方案搜寻系统100中具有足够能对应的子标准词对照表,运算服务器110就可在解决方案代码所对应的解决方案的数量大于上限值时,持续依照上述的方法进行分类,直到解决方案代码所对应的解决方案的数量不大于上限值。
相对地,为了避免因为解决方案代码所对应到的解决方案太少,而导致解决方案搜寻系统100的预测准确率降低,在本发明的部分实施例中,方法300亦可在对应于第一解决方案代码C1的解决方案的数量小于下限值,例如小于10个解决方案,且第一解决方案代码C1的一最近解决分类代码所对应的解决方案的数量与第一解决方案代码C1所对应的解决方案的数量的和不大于上限值时,例如不大于30个解决方案,运算服务器110即可将第一解决方案代码C1更新为与的最近的解决分类代码,或将第一解决方案代码C1及其最近解决分类代码共同更新为相同的新解决分类代码。
图4说明为本发明另一实施例中,解决方案搜寻系统100的操作方法400的流程图。解决方案搜寻系统100的操作方法400包括步骤S410至S470:
S410:当中枢服务器150接收到未解决的第二问题描述档案A2时,将未解决的第二问题描述档案A2传送至运算服务器110;
S420:当运算服务器110接收到未解决的第二问题描述档案A2时,根据未解决的第二问题描述档案A2及资料探勘算法产生未解决的第二问题描述档案A2的第二模型输入档案B2;
S430:中枢服务器150将运算服务器110所产生的第二模型输入档案B2传送至模型服务器120;
S440:模型服务器120根据第二模型输入档案B2及预测模型产生第二解决方案代码C2;
S450:中枢服务器150将模型服务器120所产生的第二解决方案代码C2传送至数据库服务器140;
S460:数据库服务器140根据第二解决方案代码C2由巨量数据库130读取第二解决方案D2;
S470:中枢服务器150输出数据库服务器140由巨量数据库130读取的第二解决方案D2。
透过本发明上述实施例的解决方案搜寻系统100的操作方法300及400,即可利用巨量数据库及资料探勘的算法使工程师分享彼此过去解决系统问题的经验,而能轻易地搜寻到可能的解决方案以减少解决产品问题的时间,并提升解决方案质量。此外操作方法300及400还可以对每一个解决方案代码进行检查,以避免有解决方案代码所对应到的解决方案太多或太少的情况,进而达到确保预测准确率的效果。
综上所述,本发明实施例的解决方案搜寻系统及解决方案搜寻系统的操作方法,可利用巨量数据库及资料探勘的算法,协助使用者分享彼此过去解决问题的经验,而在使用者发现系统问题时,能轻易地搜寻到可能的解决方案以减少解决产品问题的时间。如此一来,就可以避免先前技术中,因为相关的解决方案搜寻不易,而导致解决系统问题的效率及质量难以控制的问题。此外,由于本发明实施例的解决方案搜寻系统及解决方案搜寻系统的操作方法还可以对每一个解决方案代码进行检查,以避免有解决方案代码所对应到的解决方案太多或太少的情况,因此还能进一步达到确保预测准确率的效果。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!