一种高速数据流中top‑n基数数据的估算方法与流程
本发明涉及高速数据流计算领域,具体涉及一种高速数据流中top-n基数数据的估算方法。
背景技术:
随着现代互联网技术与传感器技术的发展,数据规模与日俱增,生产中有很多场景下的数据呈现出快速产生和内容复杂的特征,远超硬件处理性能的增长,导致只能以一种流式的方式处理这些数据。小规模数据环境下使用哈希表精确求解基数与top-n的方法已经不能适应这种高速大规模数据流,因此数据流算法应运而生。通过只使用极小的存储空间,就对基数作出高精度估算的HyperLogLog Counting算法就是这其中一个已经广泛应用的算法。
现有技术中常采用的方法是为每一种数据类型分配一个HLL counter,该数据类型和HLL coutner的对应关系用一个哈希表存储,当新数据D出现时,处理过程为:1、按业务进行分类,设为类型X;2、在X对应的HLL counter中计入D,得到更新后的基数,设为Y;3、将X、Y与现有top-n数据比较:1)该X已经在top-n中,更新X在top-n中的基数值;2)如果top-n数据还不足n个,存入X及Y;3)如果X比top-n中基数最小的分类x的基数y更大,用X和Y替换x和y,如图1所示。
在求top-n时,关心的只有排序前n个数据,但在哈希表中却不得不保存所有数据,在现今数据越趋复杂的背景下,这将成为一个巨大的存储开销。
数据流:只能以事先规定好的顺序被读取一次的数据的一个序列。
基数:指一个集合中不同元素的个数。
top-n:指一个集合在某种排序下的前n个元素,例如“求一个班级里成绩最好的10个学生”就是一个top-10问题。
哈希表:也叫散列表,是根据关键码值而直接访问表中一个位置来加快查找速度的数据结构。
HyperLogLog Counting:一种用极小存储空间对数据流基数进行实时估算的方法。
HLL counter:使用HyperLogLog Counting算法计算基数的计数器。
技术实现要素:
本发明所要解决的技术问题是提供一种高速数据流中top-n基数数据的估算方法,更加简单并方便由硬件并行实现,可以用来计算数据类型的基数却不保存数据类型本身,具有良好的安全性。
为解决上述技术问题,本发明采用的技术方案是:
一种高速数据流中top-n基数数据的估算方法,包括以下步骤:
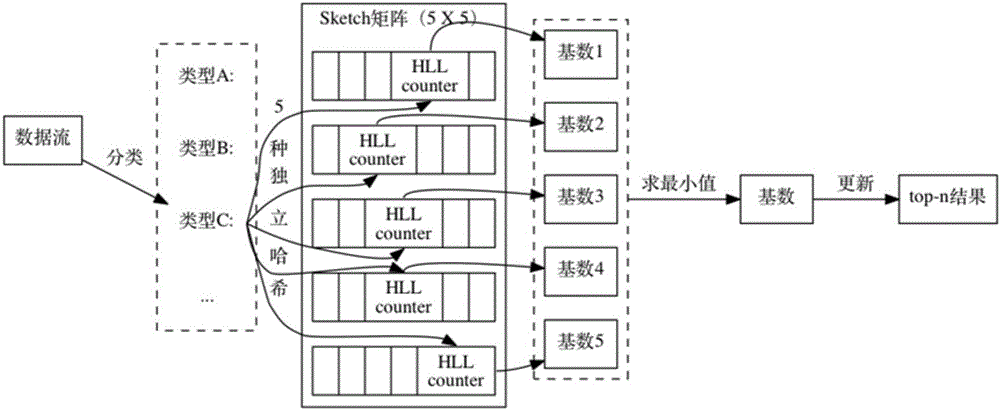
步骤1:定义“HyperLogLog Sketch矩阵”数据结构,设为S,其宽m高n,每个元素为一个HLL counter,对应的,有n个相互独立且哈希值为1~m的哈希函数,设为f1,f2,…,fn;
步骤2:当新数据D出现时,按业务进行分类,设为类型X;
步骤3:计算出xi=fi(X),其中i=1,2,…,n;
步骤4:在S(1,x1),S(2,x2),…,S(n,xn)中的HLL counter中计入D,得到更新后的基数,分别为Y1,Y2,…,Yn,再得到估算基数Y;
步骤5:将数据类型X与估算基数Y更新进top-n。
进一步的,估算基数Y为Y1,Y2,…,Yn的最小值或者Y1,Y2,…,Yn的平均值。
与现有技术相比,本发明的有益效果是:
1、方法简单并方便由硬件并行实现。
2、插入和查询时间都是常数,有稳定的时间效率。
3、由于对占据着大部分空间的非top-n数据,不用存储其数据类型,且在同一个HLL counter中,可能不只是记录一个数据类型的基数而是记录多个数据类型的并集的基数,所以空间效率得到显著优化。
4、本发明方法可以用来计算数据类型的基数却不保存数据类型本身,具有良好的安全性。
附图说明
图1是用哈希表和HyperLogLog Counting估算数据流中基数最大的数据类型。
图2是本发明用HyperLogLog Sketch估算数据流中基数最大的数据类型。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。在数据流中,既不关心非top-n数据的数据类型是什么,又不需要关心其实际基数是多少,而非top-n数据类型的基数相对于top-n数据类型的基数又小得多,即使误加在一起,对于top-n数据类型的基数精度也损伤不大。
本发明中,使用的一个数据结构称为“HyperLogLog Sketch矩阵”,设为S,其宽m高n,每个元素为一个HLL counter。对应的,有n个相互独立并且哈希值为1~m的哈希函数,设为f1,f2,…,fn。如图2所示,当新数据D出现时,按以下步骤处理:
1、按业务进行分类,设为类型X;
2、计算出xi=fi(X),其中i=1,2,…,n;
3、在S(1,x1),S(2,x2),…,S(n,xn)中的HLL counter中计入D,得到更新后的基数,分别为Y1,Y2,…,Yn,为了减少哈希结果相同的数据类型之间的相互影响,其最小值为Y;
4、将数据类型X与估算基数Y更新进top-n,更新方法与现有技术方案一相同。
本发明中,计算一个集合的基数可采用多种算法,包括Bitmap、Linear Counting、LogLog Counting或者Adaptive Counting等。多次哈希后,本发明方法采用了取最小值的方案来得到最终估算值,在使用了非HyperLogLog Counting算法后,还可以调整为取平均值。
- 还没有人留言评论。精彩留言会获得点赞!