一种基于3D卷积神经网络的微表情识别方法与流程
本发明涉及一种基于3D卷积神经网络的微表情识别方法,属于图像处理与模式识别技术领域。
背景技术:
微表情是一种特殊的面部表情,它反应了一个人内心真实的情感。人们用肉眼很难发现微表情,其持续时间很短、强度很弱,大约为1/25s-1/5s。也有研究人员认为其持续时间小于450ms。由于微表情所具有的这些特性,使其在测谎、临床诊断以及审讯等领域有着广泛的应用前景。
在早期,研究人员都是通过心理学的方式在研究微表情,并且都是注重于个体微表情的识别。微表情的第一个训练工具METT(Micro Expression Training Tool)就是由心理学家Ekman在2002年创建的,但是其识别峰值只在40%左右,这远远达不到商用的要求。
随着计算机技术的飞速发展,微表情不再使用早期心理学方法进行研究,更多的是采用计算机视觉、模式识别的方法。在国内,最早开始研究微表情的是中国科学院心理研究所的傅小兰团队。2011年其申请了中国国家自然科学基金委面上项目“面向自动谎言识别的微表情表达研究”,成为国内研究微表情的主力军,并且成功的创建了自发的微表情数据库CASME和CASMEII,为微表情识别研究做出了巨大贡献。2007年,赵国英等人将LBP 扩展到了三维空间,提出动态纹理特征的算法LBP_TOP,LBP_TOP是在三个正交的平面上计算LBP值,并且统计出直方图,其具有高效的计算,可以很好的描述动态的纹理特征,从此以后,LBP_TOP算子被广泛的应用在微表情特征提取上,得到了较好的分类结果。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks,CNN),但是由于其一系列的缺陷,很难得到较大发展。直到2006,加拿大多伦多大学Hinton教授提出了深度学习理论,通过多隐层的人工神经网络对样本进行自主学习,得到的特征数据对样本本身有着本质的刻画,有利于最终的分类。从此以后,深度学习得到了广泛的关注,几乎所有拥有大数据的高科技公司都成立了自己的深度学习项目,都想占领深度学习技术的制高点。2012年,在图像分类大赛ImageNet(图像识别目前最大的数据库)上,HINTON G E等人使用CNN最终取得了非常惊人的结果,其结果相对原来方法好了很多(前5个错误率由25%降低为17%)。由于CNN 可以直接从原始图像数据中自主学习模式特征,避免了复杂的特征提取和数据重建过程,已成功应用于手写字符识别、人脸识别、人眼检测、车牌字符识别、交通信号识别等众多应用领域。
CNN虽然具有强大的功能,广泛的应用在模式识别、计算机视觉的各个领域,但是它仅仅局限于2D的输入,这使得其应用得到了极大的限制。
技术实现要素:
本发明所要解决的技术问题是提供一种针对传统微表情识别存在复杂特征提取以及特征降维等问题,从空间和时间的维度提取特征,进行3D卷积,以捕捉从多个连续帧得到的运动信息,能够有效提高微表情识别性能的基于3D卷积神经网络的微表情识别方法。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于3D卷积神经网络的微表情识别方法,包括如下步骤:
步骤001、针对待识别微表情图像序列中的各帧图像进行像素尺寸归一化处理;
步骤002、分别针对待识别微表情图像序列中的各帧图像,提取灰度通道特征图、水平方向梯度通道特征图、竖直方向梯度通道特征图、水平方向光流通道特征图、竖直方向光流通道特征图,即获得待识别微表情图像序列所对应的一个特征图组;
步骤003、采用预设N1个不同种类、彼此大小相同的3D卷积核,针对特征图组分别进行卷积操作,获得N1个特征图组,其中,3D卷积核对应于空间维和时间维;
步骤004、针对N1个特征图组中的各张特征图,分别采用第一预设水平方向与竖直方向等比例的采样窗口进行降维处理,更新N1个特征图组中各张特征图的像素尺寸;
步骤005、分别针对N1个特征图组,分别采用预设N2个不同种类、彼此大小相同的 3D卷积核进行卷积操作,获得N1*N2个特征图组,其中,3D卷积核对应于空间维和时间维;
步骤006、针对N1*N2个特征图组中的各张特征图,分别采用第二预设水平方向与竖直方向等比例的采样窗口进行降维处理,更新N1*N2个特征图组中各张特征图的像素尺寸;
步骤007、分别针对N1*N2个特征图组,分别采用1个预设种类、大小与特征图像素尺寸相同的2D卷积核进行空间维的卷积操作,更新N1*N2个特征图组;
步骤008、获得N1*N2个特征图组所对应的各个特征向量;
步骤009、采用神经网络技术针对各个特征向量进行分类处理,其中,选取最多特征向量所对应的神经元,获得该神经元所对应的微表情分类,即为待识别微表情图像序列所对应的微表情识别结果。
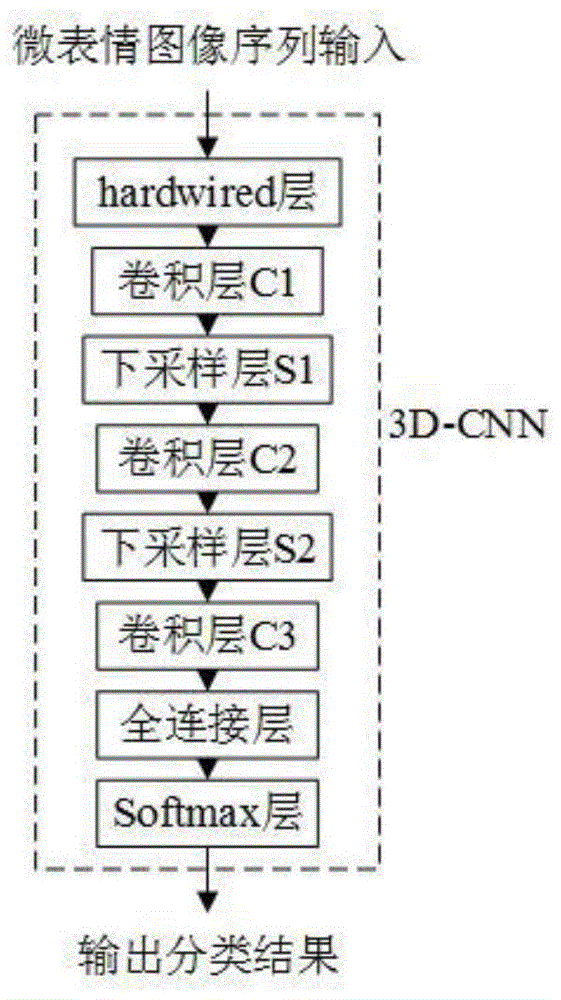
作为本发明的一种优选技术方案:基于3D卷积神经网络模型实现所述微表情识别方法,3D卷积神经网络模型由输入端开始依次包括硬连线层H1、卷积层C1、下采样层S1、卷积层C2、下采样层S2、卷积层C3、全连接层、分类层;执行完步骤001之后,采用3D 卷积神经网络模型针对所述待识别微表情图像序列中的各帧图像进行操作,其中,由硬连线层H1执行所述步骤002,卷积层C1执行所述步骤003,下采样层S1执行所述步骤004,卷积层C2执行所述步骤005,下采样层S2执行所述步骤006,卷积层C3执行所述步骤007,全连接层执行所述步骤008,分类层执行所述步骤009。
作为本发明的一种优选技术方案:采用预设模型训练方法针对所述3D卷积神经网络模型的模型参数进行训练,在执行完所述步骤001之后,采用训练后的3D卷积神经网络模型,针对所述待识别微表情图像序列中的各帧图像执行所述步骤002至步骤009。
作为本发明的一种优选技术方案:所述预设模型训练方法为随机diagonal Levenberg-Marquardt优化方法针对所述3D卷积神经网络模型的模型参数进行训练。
作为本发明的一种优选技术方案:所述卷积层C1按如下公式,执行所述步骤003,
其中,(x,y,z)C1,j表示卷积层C1第j个特征图上任意一个像素点的像素值,表示硬连线层H1第j个特征图经卷积层C1进行3D卷积后的输出,表示卷积层C1 针对第j个特征图进行卷积的3D卷积核,(P-1,Q-1,R-1)C1,j表示卷积层C1对应第j个特征图的3D卷积核的大小,bC1,j表示卷积层C1对应第j个特征图的加性偏置,f(·)表示激活函数,表示硬连线层H1第j个特征图上任意一点;
所述卷积层C2按如下公式,执行所述步骤005,
其中,(x,y,z)C2,i表示卷积层C2第i个特征图上任意一个像素点的像素值,表示下采样层S1第i个特征图经卷积层C2进行3D卷积后的输出,表示卷积层C2针对第i个特征图进行卷积的3D卷积核,(P-1,Q-1,R-1)C2,i表示卷积层C2对应第i个特征图的3D卷积核的大小,bC2,i表示卷积层C2对应第i个特征图的加性偏置,f(·)表示激活函数,表示下采样层S1第i个特征图上任意一点。
作为本发明的一种优选技术方案:所述下采样层S1按如下公式,执行所述步骤004,
vS1,m=f(αS1,mdown1(vC1,m)+βS1,m)
其中,vS1,m表示下采样层S1针对卷积层C1第m个特征图进行降维处理所得的特征图, vC1,m表示卷积层C1的第m个特征图,down1(·)表示下采样层S1函数,αS1,m和βS1,m分别表示下采样层S1对应第m个特征图的乘性偏置和加性偏置,f(·)表示激活函数;
所述下采样层S2按如下公式,执行所述步骤006,
vS2,n=f(αS2,ndown2(vC2,n)+βS2,n)
其中,vS2,n表示下采样层S2针对卷积层C2第n个特征图进行下采样所得的特征图, vC2,n表示卷积层C2的第n个特征图,down2(·)表示下采样层S2函数,αS2,n和βS2,n分别表示下采样层S2对应第n个特征图的乘性偏置和加性偏置,f(·)表示激活函数。
作为本发明的一种优选技术方案:所述卷积层C3按如下公式,执行所述步骤007,
其中,(x,y)C3,k表示卷积层C3第k个特征图上任意一个像素点的像素值,表示下采样层S2第k个特征图经卷积层C3进行2D卷积后的输出,表示卷积层C3针对第k个特征图进行卷积的2D卷积核,(P-1,Q-1)C3,k表示卷积层C3对应第k个特征图的2D 卷积核的大小,bC3,k表示卷积层C3对应第k个特征图的加性偏置,f(·)表示激活函数,表示下采样层S2第k个特征图上任意一点。
本发明所述一种基于3D卷积神经网络的微表情识别方法采用以上技术方案与现有技术相比,具有以下技术效果:本发明所设计基于3D卷积神经网络的微表情识别方法,基于所构造出的3D卷积神经网络(3D-CNN)模型,能够有效识别出高兴、厌恶、压抑、惊讶以及其他5类微表情,并且所设计微表情识别方法简单、高效,不需要对样本数据进行特征提取、特征降维、分类等一系列过程,大大减少了预处理的难度,而且通过感受野和权值共享,减少了神经网络需要训练的参数的个数,大大降低了算法的复杂度,不仅如此,所设计微表情识别方法中,通过下采样层的下采样操作,增强了网络的鲁棒性,能容忍图像一定程度的畸变。
附图说明
图1是本发明所设计基于3D卷积神经网络的微表情识别方法的示意图;
图2是本发明所设计基于3D卷积神经网络的微表情识别方法中3D卷积神经网络架构图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
如图1和图2所示,本发明设计一种基于3D卷积神经网络的微表情识别方法,在实际应用过程当中,基于3D卷积神经网络模型(3D-CNN)实现所述微表情识别方法,3D卷积神经网络模型(3D-CNN)由输入端开始依次包括硬连线层H1(hardwired层)、卷积层 C1、下采样层S1、卷积层C2、下采样层S2、卷积层C3、全连接层、分类层(Softmax分类层);针对下面所设计的步骤001至步骤009,首先采用随机diagonal Levenberg-Marquardt优化方法针对所述3D卷积神经网络模型(3D-CNN)的模型参数进行训练,然后在执行完所述步骤001之后,采用训练后的3D卷积神经网络模型(3D-CNN),针对所述待识别微表情图像序列中的各帧图像执行所述步骤002至步骤009;其中,由硬连线层H1(hardwired层)执行所述步骤002,卷积层C1执行所述步骤003,下采样层S1 执行所述步骤004,卷积层C2执行所述步骤005,下采样层S2执行所述步骤006,卷积层 C3执行所述步骤007,全连接层执行所述步骤008,分类层(Softmax分类层)执行所述步骤009,实际应用中,具体包括如下步骤:
步骤001、针对待识别微表情图像序列中的各帧图像进行像素尺寸归一化处理。
步骤002、由硬连线层H1(hardwired层)分别针对待识别微表情图像序列中的各帧图像,提取灰度通道特征图、水平方向梯度通道特征图、竖直方向梯度通道特征图、水平方向光流通道特征图、竖直方向光流通道特征图,即获得待识别微表情图像序列所对应的一个特征图组。
步骤003、由卷积层C1采用预设N1个不同种类、彼此大小相同的3D卷积核,针对特征图组分别进行卷积操作,获得N1个特征图组,其中,3D卷积核对应于空间维和时间维。
上述卷积层C1按如下公式,执行所述步骤003:
其中,(x,y,z)C1,j表示卷积层C1第j个特征图上任意一个像素点的像素值,表示硬连线层H1(hardwired层)第j个特征图经卷积层C1进行3D卷积后的输出,表示卷积层C1针对第j个特征图进行卷积的3D卷积核,(P-1,Q-1,R-1)C1,j表示卷积层 C1对应第j个特征图的3D卷积核的大小,bC1,j表示卷积层C1对应第j个特征图的加性偏置,f(·)表示激活函数,表示硬连线层H1(hardwired层)第j个特征图上任意一点。
步骤004、由下采样层S1针对N1个特征图组中的各张特征图,分别采用第一预设水平方向与竖直方向等比例的采样窗口进行降维处理,更新N1个特征图组中各张特征图的像素尺寸。
上述下采样层S1按如下公式,执行所述步骤004,
vS1,m=f(αS1,mdown1(vC1,m)+βS1,m)
其中,vS1,m表示下采样层S1针对卷积层C1第m个特征图进行降维处理所得的特征图,vC1,m表示卷积层C1的第m个特征图,down1(·)表示下采样层S1函数,αS1,m和βS1,m分别表示下采样层S1对应第m个特征图的乘性偏置和加性偏置,f(·)表示激活函数。
步骤005、由卷积层C2分别针对N1个特征图组,分别采用预设N2个不同种类、彼此大小相同的3D卷积核进行卷积操作,获得N1*N2个特征图组,其中,3D卷积核对应于空间维和时间维。
上述卷积层C2按如下公式,执行所述步骤005,
其中,(x,y,z)C2,i表示卷积层C2第i个特征图上任意一个像素点的像素值,表示下采样层S1第i个特征图经卷积层C2进行3D卷积后的输出,表示卷积层C2针对第i个特征图进行卷积的3D卷积核,(P-1,Q-1,R-1)C2,i表示卷积层C2对应第i个特征图的3D卷积核的大小,bC2,i表示卷积层C2对应第i个特征图的加性偏置,f(·)表示激活函数,表示下采样层S1第i个特征图上任意一点。
步骤006、由下采样层S2针对N1*N2个特征图组中的各张特征图,分别采用第二预设水平方向与竖直方向等比例的采样窗口进行降维处理,更新N1*N2个特征图组中各张特征图的像素尺寸。
上述下采样层S2按如下公式,执行所述步骤006,
vS2,n=f(αS2,ndown2(vC2,n)+βS2,n)
其中,vS2,n表示下采样层S2针对卷积层C2第n个特征图进行下采样所得的特征图, vC2,n表示卷积层C2的第n个特征图,down2(·)表示下采样层S2函数,αS2,n和βS2,n分别表示下采样层S2对应第n个特征图的乘性偏置和加性偏置,f(·)表示激活函数。
步骤007、由卷积层C3分别针对N1*N2个特征图组,分别采用1个预设种类、大小与特征图像素尺寸相同的2D卷积核进行空间维的卷积操作,更新N1*N2个特征图组。
上述卷积层C3按如下公式,执行所述步骤007,
其中,(x,y)C3,k表示卷积层C3第k个特征图上任意一个像素点的像素值,表示下采样层S2第k个特征图经卷积层C3进行2D卷积后的输出,表示卷积层C3针对第k个特征图进行卷积的2D卷积核,(P-1,Q-1)C3,k表示卷积层C3对应第k个特征图的2D 卷积核的大小,bC3,k表示卷积层C3对应第k个特征图的加性偏置,f(·)表示激活函数,表示下采样层S2第k个特征图上任意一点。
步骤008、由全连接层获得N1*N2个特征图组所对应的各个特征向量。
步骤009、由分类层(Softmax分类层)采用神经网络技术针对各个特征向量进行分类处理,其中,选取最多特征向量所对应的神经元,获得该神经元所对应的微表情分类,即为待识别微表情图像序列所对应的微表情识别结果。
上述技术方案所设计基于3D卷积神经网络的微表情识别方法,基于所构造出的3D卷积神经网络(3D-CNN)模型,能够有效识别出高兴、厌恶、压抑、惊讶以及其他5类微表情,并且所设计微表情识别方法简单、高效,不需要对样本数据进行特征提取、特征降维、分类等一系列过程,大大减少了预处理的难度,而且通过感受野和权值共享,减少了神经网络需要训练的参数的个数,大大降低了算法的复杂度,不仅如此,所设计微表情识别方法中,通过下采样层的下采样操作,增强了网络的鲁棒性,能容忍图像一定程度的畸变。
如图2所示,将本发明所设计基于3D卷积神经网络的微表情识别方法,应用到实际应用过程当中,首先采用随机diagonal Levenberg-Marquardt优化方法针对所述3D卷积神经网络模型(3D-CNN)的模型参数进行训练,然后具体步骤执行如下:
步骤001、针对待识别微表情图像序列中的各帧图像进行像素尺寸归一化处理,使每一帧图像的大小都为60*40像素,且待识别微表情图像序列为7帧图像。
步骤002、由硬连线层H1(hardwired层)分别针对待识别微表情图像序列中的各帧图像,提取灰度通道特征图、水平方向梯度通道特征图、竖直方向梯度通道特征图、水平方向光流通道特征图、竖直方向光流通道特征图,即获得待识别微表情图像序列所对应的一个特征图组,且由于水平和竖直方向的光流信息需要连续两帧的图像计算,所以在硬连线层H1(hardwired层)特征图个数为7*3+6*2=33。
步骤003、由卷积层C1采用2个不同种类、彼此大小相同为7*7*3的3D卷积核(7*7 是空间维,3是时间维),按公式针对特征图组分别进行卷积操作,获得2个特征图组,其中,各个特征图组包含的特征图个数为23=(7-3+1)*3+(6-3+1)*2,特征图大小为54x34=(60-7+1)*(40-7+1)。
步骤004、由下采样层S1针对2个特征图组中的各张特征图,按公式分别采用2*2 的采样窗口进行降维处理,更新2个特征图组中各张特征图的像素尺寸,这样就会得到相同数目但是空间分辨率降低的特征图,下采样后特征图大小为27*17=(52/2)*(34/2)。
步骤005、由卷积层C2分别针对2个特征图组,分别采用预设3个不同种类、彼此大小相同为7*6*3的3D卷积核(7*6是空间维,3是时间维),按公式进行卷积操作,获得6 个特征图组,其中,各个特征图组包含的特征图个数为13=(7-3+1)-3+1)*3+((6-3+1)-3+1)*2,特征图大小为21*12=(27-7+1)*(17-6+1)。
步骤006、由下采样层S2针对6个特征图组中的各张特征图,分别采用3*3的采样窗口,按公式进行降维处理,更新6个特征图组中各张特征图的像素尺寸,其中,下采样后特征图大小为7*4=(21/3)*(12/3),这样就会得到相同数目但空间分辨率降低的特征图。
步骤007、由卷积层C3分别针对6个特征图组,分别采用7*4的2D卷积核,按公式进行空间维的卷积操作,更新6个特征图组,如此,输出的特征图就被减小到1x1的大小。
步骤008、由全连接层获得6个特征图组所对应的各个特征向量,即最终得到一个 128维的特征向量。
步骤009、由分类层(Softmax分类层)采用神经网络技术针对各个特征向量进行分类处理,分类层(Softmax分类层)中每一个神经元输出一个取值在0~1之间的数值,其反应了输入样本属于该类的概率,其中,选取最多特征向量所对应的神经元,获得该神经元所对应的微表情分类,即为待识别微表情图像序列所对应的微表情识别结果。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!