分布式集群上实现科学计算应用部署的方法及系统与流程
技术领域
本发明涉及一种科学计算应用技术领域,具体地说是分布式集群上实现科学计算应用部署的方法及系统。
背景技术:
通常的科学计算应用部署于高性能集群中,高性能集群能最大限度榨取计算资源的能力是高性能集群的一大特点,也是作为科学计算应用所选择的主要集群种类的原因之一。
但要想实现在高性能集群中高效并行,首要条件是用于科学计算应用能并行计算,换言之,该应用是经过并行编程和开发的。就目前的应用市场来看,大多数用于自然科学的应用都是并行程序,而用于社会科学的应用则很少是并行编译的,在高性能集群中它们只能单节点串行计算。
分布式集群也就是我们常提到的hadoop集群,hadoop是一种开源技术, Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储。Hadoop的MapReduce(映射化简)功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。Hadoop 由许多元素构成。其最底部是Hadoop Distributed File System(HDFS分布式文件系统),它存储 Hadoop 集群中所有存储节点上的文件。Hadoop的MapReduce采用Master/Slave(主/从)结构。Master:是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。Slave:负责任务的执行和任务状态的回报,即MapReduce中的TaskTracker。
JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。JobTracker的主要功能:1.作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控;状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控;主要作用:容错和为任务调度提供决策依据。2. 资源管理。
TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。TaskTracker的功能:1.汇报心跳:Tracker周期性将所有节点上各种信息通过心跳机制汇报给JobTracker;信息包括:机器级别信息(节点健康情况、资源使用情况等),任务级别信息(任务执行进度、任务运行状态等);2.执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。3.资源管理。
市场上存在很多商业公司针对应用提供了多种不同的商业化的hadoop产品。而这些不同种类的产品其核心依旧是原来的hadoop,其主体结构与高性能集群存在一定差别,底层的HDFS(Hadoop Distributed File System)文件系统和MapReduce分布式处理是构成hadoop分布式计算的核心。高性能计算依赖于应用自身具有并行的能力,而hadoop集群本身由系统层提供分布式处理的能力。显然,把一些无法并行的科学计算应用程序部署在高性能集群上串行计算,效率其实并不高,不能最大程度利用集群资源。应用本身不具备并行能力,如何对此应用进行并行计算作业是目前需要解决的问题。
技术实现要素:
本发明的技术任务是提供分布式集群上实现科学计算应用部署的方法及系统,来解决如何将本身不具备并行能力的应用进行并行计算作业的问题。
本发明的技术任务是按以下方式实现的,
分布式集群上实现科学计算应用部署的方法,步骤如下:
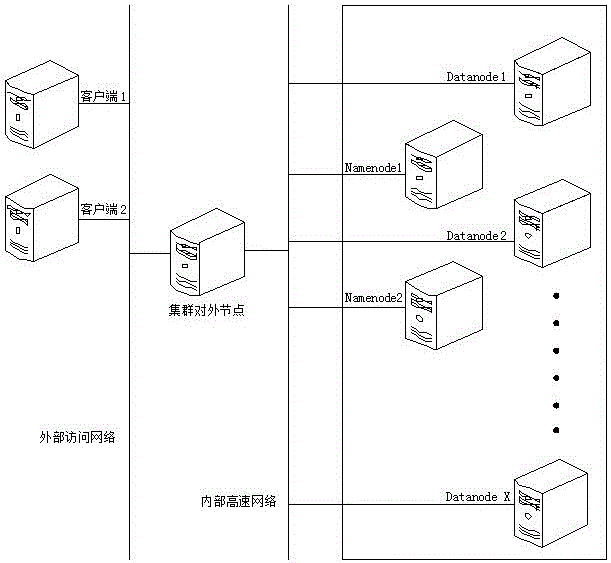
(1)、部署分布式集群,使得分布式集群的用户能正常存储文件和正常的进行Map-Reduce过程;在分布式集群上配置一个集群对外节点、至少两个名称节点(Namenode)和多个进行计算的数据节点(Datanode);客户端通过集群对外节点对集群访问;名称节点用于进行Map过程;数据节点用于进行Reduce过程;
(2)、分布式集群使用的科学计算应用进行调优,包含Map-Reduce函数接口;
(3)、在名称节点中,设置分布式集群的安装共享目录,在安装共享目录中部署应用程序和/或文件;安装共享目录用于将应用程序或者文件进行全局共享,使得能访问该安装共享目录的子节点能调用应用程序或者读写文件;
(4)、切换分布式集群的用户,打开应用程序,出现应用程序接口,在该应用程序接口下进行算例或程序调试操作;
(5)、登陆各个执行Reduce过程的数据节点(Datanode),使用top指令查看应用的Reduce过程是否执行;
(6)、执行完毕后,分布式集群自动收集所有的节点整合反馈给当前用户。
步骤(1)中,分布式集群使用开源hadoop或者商业版hadoop。
步骤(3)中,安装共享目录使用共同的存储空间,或使用NFS共享的目录,如/opt。
步骤(3)中,安装共享目录中部署应用程序和/或文件步骤为:通过上传解压安装三步,安装完毕后测试各节点是否能正常访问和执行相应的应用程序和/或文件。
步骤(4)中,算例或程序调试操作:通过Map-Reduce过程调用所有Datanode的计算资源,调用计算资源的多少是由hadoop配置过程设置;打开应用程序,输入应用程序的算例参数或者相应程序,开始执行。
步骤(6)中,节点整合反馈给当前用户输出方式为:屏幕输出或者文件输出。
分布式集群上实现科学计算应用部署的系统,在分布式集群上配置一个集群对外节点、至少两个名称节点(Namenode)和多个进行计算的数据节点(Datanode);客户端通过集群对外节点对集群访问;名称节点用于进行Map过程;数据节点用于进行Reduce过程。
分布式集群使用开源hadoop或者商业版hadoop。
客户端通过外部网络或公共网络访问集群对外节点,集群对外节点通过内部网络能访问名称节点(Namenode)和数据节点(Datanode),名称节点(Namenode)和数据节点(Datanode)进行数据交互及通信的内部网络为千兆网络或者万兆网络或者Infiniband网络。
本发明的分布式集群上实现科学计算应用部署的方法及系统具有以下优点:
1、在分布式集群上实现基于hadoop开发的应用的跨节点分布式计算,来弥补高性能集群中应用串行作业效率低的缺点;
2、常见的分布式集群如开源的hadoop或者商业版的分布式软件;能实现该种应用经过hadoop调优后的应用在hadoop平台上部署运算,从而具有跨节点分布式运算的能力,提高集群计算效率;
3、简单明了,易于操作,分布式集群是整个架设的基础,实现科学计算应用的分布式计算是架设的核心和目的,集群中存在其他角色类型的节点依旧适用;最终目的是部署的科学计算应用能实现在高性能集群中不能实现的跨节点运算,最大限度将集群资源利用起来,用于科学计算过程中;
4、将应用程序和文件部署在安装共享目录下,可以节省分布式集群下的应用部署时间和难度。
附图说明
下面结合附图对本发明进一步说明。
附图1为分布式集群上实现科学计算应用部署的方法的流程图;
附图2为分布式集群上实现科学计算应用部署的系统的结构框图。
具体实施方式
参照说明书附图和具体实施例对本发明的分布式集群上实现科学计算应用部署的方法及系统作以下详细地说明。
实施例1:
本发明的分布式集群上实现科学计算应用部署的方法, 步骤如下:
(1)、部署分布式集群,使得分布式集群的用户能正常存储文件和正常的进行Map-Reduce过程;在分布式集群上配置一个集群对外节点、至少两个名称节点(Namenode)和多个进行计算的数据节点(Datanode);客户端通过集群对外节点对集群访问;名称节点用于进行Map过程;数据节点用于进行Reduce过程;分布式集群使用开源hadoop;
(2)、分布式集群使用的科学计算应用进行调优,包含Map-Reduce函数接口;
(3)、在名称节点中,设置分布式集群的安装共享目录,安装共享目录使用共同的存储空间;在安装共享目录中部署应用程序和/或文件;安装共享目录用于将应用程序或者文件进行全局共享,使得能访问该安装共享目录的子节点能调用应用程序或者读写文件;安装共享目录中部署应用程序和/或文件步骤为:通过上传解压安装三步,安装完毕后测试各节点是否能正常访问和执行相应的应用程序和/或文件;
(4)、切换分布式集群的用户,打开应用程序,出现应用程序接口,在该应用程序接口下进行算例或程序调试操作;算例或程序调试操作:通过Map-Reduce过程调用所有Datanode的计算资源,调用计算资源的多少是由hadoop配置过程设置;打开应用程序,输入应用程序的算例参数或者相应程序,开始执行;
(5)、登陆各个执行Reduce过程的数据节点(Datanode),使用top指令查看应用的Reduce过程是否执行;
(6)、执行完毕后,分布式集群自动收集所有的节点整合反馈给当前用户;节点整合反馈给当前用户输出方式为:屏幕输出。
实施例2:
本发明的分布式集群上实现科学计算应用部署的方法, 步骤如下:
(1)、部署分布式集群,使得分布式集群的用户能正常存储文件和正常的进行Map-Reduce过程;在分布式集群上配置一个集群对外节点、至少两个名称节点(Namenode)和多个进行计算的数据节点(Datanode);客户端通过集群对外节点对集群访问;名称节点用于进行Map过程;数据节点用于进行Reduce过程;分布式集群使用商业版hadoop;
(2)、分布式集群使用的科学计算应用进行调优,包含Map-Reduce函数接口;
(3)、在名称节点中,设置分布式集群的安装共享目录,安装共享目录使用NFS共享的目录/opt;在安装共享目录中部署应用程序和/或文件;安装共享目录用于将应用程序或者文件进行全局共享,使得能访问该安装共享目录的子节点能调用应用程序或者读写文件;安装共享目录中部署应用程序和/或文件步骤为:通过上传解压安装三步,安装完毕后测试各节点是否能正常访问和执行相应的应用程序和/或文件;
(4)、切换分布式集群的用户,打开应用程序,出现应用程序接口,在该应用程序接口下进行算例或程序调试操作;算例或程序调试操作:通过Map-Reduce过程调用所有Datanode的计算资源,调用计算资源的多少是由hadoop配置过程设置;打开应用程序,输入应用程序的算例参数或者相应程序,开始执行;
(5)、登陆各个执行Reduce过程的数据节点(Datanode),使用top指令查看应用的Reduce过程是否执行;
(6)、执行完毕后,分布式集群自动收集所有的节点整合反馈给当前用户;节点整合反馈给当前用户输出方式为:文件输出。
实施例3:
本发明的分布式集群上实现科学计算应用部署的系统,在分布式集群上配置一个集群对外节点、至少两个名称节点(Namenode)和多个进行计算的数据节点(Datanode);客户端通过集群对外节点对集群访问;名称节点用于进行Map过程;数据节点用于进行Reduce过程。分布式集群使用开源hadoop或者商业版hadoop。客户端通过外部网络或公共网络访问集群对外节点,集群对外节点通过内部网络能访问名称节点(Namenode)和数据节点(Datanode),名称节点(Namenode)和数据节点(Datanode)进行数据交互及通信的内部网络为千兆网络。
通过上面具体实施方式,所述技术领域的技术人员可容易的实现本发明。但是应当理解,本发明并不限于上述的具体实施方式。在公开的实施方式的基础上,所述技术领域的技术人员可任意组合不同的技术特征,从而实现不同的技术方案。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。
- 还没有人留言评论。精彩留言会获得点赞!