基于文本挖掘技术的客户投诉预警监测分析方法与流程
本发明涉及基于文本挖掘技术的客户投诉预警监测分析方法,所属领域为电力行业客户危机管理领域。
背景技术:
随着电力体制改革的逐步深化,电力销售市场竞争加剧,迫切需要供电企业迅速改变传统的思维方式和工作模式,进一步树立市场化服务意识,创新商业化服务模式,提升定制化、个性化服务水平,赢得客户的信任,确保市场份额。同时,随着民众自主意识和维权意识的不断提升,供电企业每一次的电价调整、服务手续变更甚至故障抢修,都受到了广大民众的密切关注。
作为与客户交流、沟通的重要窗口,95598客户服务系统记录了海量的客户信息。该系统中的数据主要分为结构化数据和非结构化数据。目前,针对系统中的结构化数据,系统通过对投诉数量、客户的满意度打分或问题处理时效等方面进行统计分析。对于客户反馈信息非结构化数据主要是以人工抽检梳理为主,不便于及时准确的掌握客户关注热点问题;且仅限于从时间、区域、业务类型等维度进行统计分析,使得监测分析的精细化程度不够;同时对投诉工单的文本数据虽然进行逐一的人工溯源分析,缺乏自动化监测分析,且侧重于事后追责,无法实现事前预警。
技术实现要素:
本发明所要解决的技术问题在于克服现有技术不足,提供一种基于文本挖掘技术的投诉预警监测方法,能够针对专业管理部门及时、准确掌握客户反馈热点问题,以及事前预警客户投诉风险的要求,在客户反馈信息纷繁复杂、表达方式灵活多样下实现对客户投诉风险度的预警,解决了目前人工梳理效率低和事后溯源追责的被动式管理问题,从而保证了对每条工单的投诉风险等级预测,便于及时开展主动服务,提升了客户满意度。
为解决上述技术问题,本发明采用的技术方案是:
一种基于文本挖掘技术的投诉预警监测分析方法,包括:
步骤1,文本数据规范化步骤,将录入的文本数据转成统一规则的规范化数据模式;
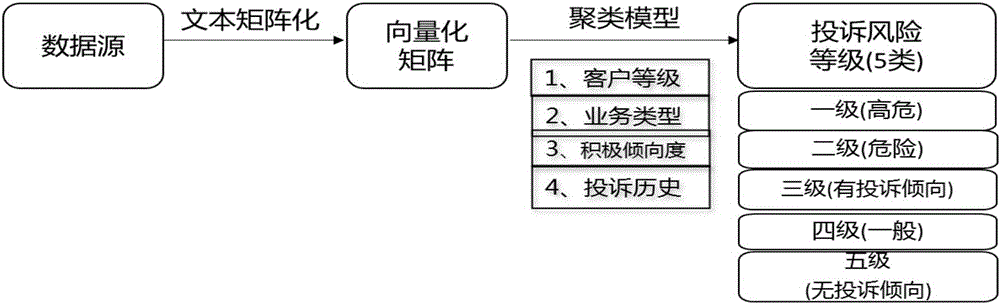
步骤2,规范化数据分析预警步骤,通过建立投诉分析等级聚类模型对规范化数据模式进行分析,根据聚类结果划分投诉风险等级,再根据风险所在等级发出相应的预警。
采用文本数据规范化步骤将文本数据转化为结构化、标准化的规范化表达式,便于后期 处理应用;采用规范化数据分析预警步骤实现对客户投诉风险等级的判定与预警,省去人工梳理和判别,有效提高了工作效率。
作为本发明的进一步限定方案,文本数据规范化步骤包括:
步骤1.1,文本初始处理步骤,对录入的文本数据进行分词和去噪处理,获得各个文本数据中的关键词;
步骤1.2,文本特征向量化步骤,将各个关键词进行向量化并作归一化处理,获得由各个关键词Wi在文件dj中的向量化归一化结果建立的实数值矩阵,关键词Wi在文件dj中的向量化归一化结果为:
式中:N表示文件总数量;Ni表示包含关键词Wi的文件数量;n为关键词总次数;Wi为第i个关键词;dj表示第j个文件;tfij为关键词Wi在文件dj中的词频;为所有关键词在文件dj中的词频平方和;为文件总数量与包含关键词Wi文件的数量比值加上调整项0.01后取对数;
步骤1.3,文本数据相似性匹配步骤,根据建立的实数值矩阵,利用余弦定理计算各关键词间的余弦相似度,并将余弦距离最近的文本数据进行匹配,形成近义词词库;
步骤1.4,规范化数据生成步骤,将匹配好的文本数据按照设定的统一规范化模式生成规范化数据。
作为本发明的进一步限定方案,规范化数据分析预警步骤包括:
步骤2.1,情感倾向度计算步骤,对规范化数据进行情感判断并划分为积极、消极和中心三类;
步骤2.2,投诉风险等级划分步骤,根据客户等级、业务类型、积极倾向度以及投诉历史参数建立投诉分析等级聚类模型,并根据聚类结果制定投诉风险等级规则;
步骤2.3,投诉分析预警步骤,根据制定的投诉风险等级规则,选择模型变量参数,利用贝叶斯分类建立分类学习模型,通过对分类学习模型的训练实现对未知文本数据的投诉风险等级的预测。
作为本发明的进一步限定方案,情感倾向度计算步骤的具体工作步骤为:
(1)建立连词和否定词词典库;
(2)根据连词和否定词词典库从规范化数据中抽取连词和否定词,并标记相应词在规范化数据中的位置;
(3)匹配现有的情感词典库,获得词汇的极性及其情感评分值;
(4)通过连词位置,确定前句与后句所占比重,再根据否定词位置判断双重否定以及邻近词汇的极性反转;
(5)利用词汇的极性及其情感评分值带入连词和否定词后对规范化数据进行累加获得情感计算评分;
(6)循环步骤(2)至(5),若情感计算评分为正则为积极,为负则为消极,否则为中心。
作为本发明的进一步限定方案,投诉风险等级规则用于根据聚类结果将投诉风险等级划分为高危极、危险级、有投诉倾向级、一般级以及无投诉倾向级这五个风险等级。
作为本发明的进一步限定方案,在制定投诉风险等级规则需要对规则进行验证,将验证集数据输入建立的分类学习模型,获得验证集数据中各文本数据的投诉风险等级,并将结果集与验证集数据中对应的等级数据进行比对,计算模型预测的正确率。
本发明的有益效果在于:利用文本挖掘技术,将文本数据转化为结构化、标准化的规范化表达式;其次对客户反馈的文本信息进行情感分析,并计算其情感倾向度;最后利用有监督的分类学习算法,建立投诉预警监测模型,实现对客户投诉风险等级的判定与预警。
附图说明
图1为规范化表达式建立流程示意图;
图2为本发明提出的投诉风险等级计算流程图;
图3为本发明提出的投诉预警模型建立步骤示意图;
图4为本发明提出的投诉预警模型验证流程示意图;
图5为各区域工单数分布图;
图6为各等级工单数据分布图。
具体实施方式
下面结合附图,对本发明作详细说明:
本发明一种基于文本挖掘技术的投诉预警监测分析方法,包括文本数据规范化步骤和规范化数据分析预警步骤,其中,文本数据规范化步骤,用于将录入的文本数据转成统一规则的规范化数据模式;规范化数据分析预警步骤,用于通过建立投诉分析等级聚类模型对规范 化数据模式进行分析,根据聚类结果划分投诉风险等级,根据风险所在等级发出相应的预警。
采用文本数据规范化步骤将文本数据转化为结构化、标准化的规范化表达式,便于后期处理应用;采用规范化数据分析预警步骤实现对客户投诉风险等级的判定与预警,省去人工梳理和判别,有效提高了工作效率。
文本数据规范化步骤包括文本初始处理步骤、文本特征向量化步骤、文本数据相似性匹配步骤以及规范化数据生成步骤。文本数据规范化步骤的具体处理步骤如图1所示,首先将录入的文本数据(95598工单数据)进行分词、去噪处理;接着进行向量化处理成向量矩阵、词相关矩阵;然后进行关联分析生成近义词词库;根据业务类型和近义词词库对文本数据进行规范化表达。
其中,文本初始处理步骤,用于对录入的文本数据进行分词和去噪处理,获得各个文本数据中的关键词;
文本特征向量化步骤,用于将各个关键词进行向量化并作归一化处理,获得由各个关键词Wi在文件dj中的向量化归一化结果建立的实数值矩阵,关键词Wi在文件dj中的向量化归一化结果为:
式中:N表示文件总数量;Ni表示包含关键词Wi的文件数量;n为关键词总次数;Wi为第i个关键词;dj表示第j个文件;tfij为关键词Wi在文件dj中的词频;为所有关键词在文件dj中的词频平方和;为文件总数量与包含关键词Wi文件的数量比值加上调整项0.01后取对数;
文本数据相似性匹配步骤,用于根据建立的实数值矩阵,利用余弦定理计算各关键词间的余弦相似度,并将余弦距离最近的文本数据进行匹配,形成近义词词库;
规范化数据生成步骤,用于将匹配好的文本数据按照设定的统一规范化模式生成规范化数据。
作为本发明进一步公开方案,规范化数据分析预警步骤包括:
情感倾向度计算步骤,用于对规范化数据进行情感判断并划分为积极、消极和中心三类;
投诉风险等级划分步骤,用于根据客户等级、业务类型、积极倾向度以及投诉历史参数建立投诉分析等级聚类模型,并根据聚类结果制定投诉风险等级规则;在制定投诉风险等级 规则需要对规则进行验证,将验证集数据输入建立的分类学习模型,获得验证集数据中各文本数据的投诉风险等级,并将结果集与验证集数据中对应的等级数据进行比对,计算模型预测的正确率;
投诉分析预警步骤,用于根据制定的投诉风险等级规则,选择模型变量参数(如有无投诉历史、业务类型以及客户等级),利用贝叶斯分类建立分类学习模型,通过对分类学习模型的训练实现对未知文本数据的投诉风险等级的预测。
本发明基于文本挖掘技术的投诉预警监测分析系统实现的具体步骤为:
(一)建立规范化表达式
1、中文分词
基于95598工单数据,建立分词语料库和特殊符号表,对预料库中相邻共现的各个字的组合的频度进行统计,计算其相关度。计算公式如下:
其中,M表示预料库字数,NA表示A在预料库中出现的次数,NB表示B在预料库中出现的次数,NAB表示AB在预料库中一起出现的次数。
2、文本特征向量化
从95598工单文本内容中选择出一部分最为有效的特征,使得新特征空间的维度往往远小于原始空间维度,实现对文本特征向量的进一步净化,并在保持原文本含义的情况下,计算最能反馈文本内容,又简洁的特征向量。通过对文本特征项做归一化处理,减轻了不同长度文本对文本相似度计算结果的影响。计算公式如下:
式中:N表示文件总数量;Ni表示包含关键词Wi的文件数量;n为关键词总次数;Wi为第i个关键词;dj表示第j个文件;tfij为关键词Wi在文件dj中的词频;为所有关键词在文件dj中的词频平方和;为文件总数量与包含关键词Wi文件的数量比值加上调整项0.01后取对数。
3、根据词向量转换后的实数值矩阵,利用余弦定理,计算各个词组间的余弦相似度,并将余弦距离最近的词进行匹配,形成近义词词库。
4、建立规范化表达式
结合95598系统业务分类,实现对客户反馈文本信息的规范化表示,形如:投诉-超崔人员-态度。
(二)建立投诉预警监测模型
1、计算情感倾向度
(1)基于大连理工大学情感词典,以95598工单业务类别为表扬文本作为补充修改,同时建立连词和否定词词典,建立情感训练库。
(2)从95598工单中抽取连词和否定词,并标记相应词位置。
(3)匹配情感词典,确定词汇极性及其情感评分值,词汇极性和情感评分值为情感词典中现有的基本参数。
(4)通过连词位置,确定前句与后句所占比重,同时根据否定词位置判读双重否定,以及邻进词汇的极性反转。
(5)累加工单文本情感计算评分。
(6)循环步骤(2)至(5),若为正则为积极,为负则为消极,否则为中心。
2、制定投诉风险等级
通过将工单文本数据转换成向量化矩阵,选取客户等级、积极倾向度、投诉历史等参数,建立投诉分析等级聚类模型,最终根据聚类结果,将投诉风险等级划分为5类,如图2所示。
3、建立投诉分析预警模型
将数据源分为模型训练集和验证集,并根据制定的投诉风险等级规则,选择模型变量(如有无投诉历史、业务类型、客户等级等),利用贝叶斯分类建立分类学习模型,通过模型训练实现对未知工单的投诉风险等级的预测,模型训练的步骤如图3所示。
4、模型验证
如图4所示,将验证集数据输入分类学习模型,通过模型预测各工单的投诉风险等级,并将结果集与验证集中的数据进行比对,计算模型预测的正确率。
实施例
收集95598系统南京市8月份工单数据,共计87359条。包括业务咨询、故障报修、建议、意见、投诉、举报等九类工单的数据。其中南京市区产生工单最多为58151条,其次为江宁区为13248条,各区域工单数分布详见图5。
1、8月份主动服务等级工单监测分析
通过模型计算,将8月份南京市工单分为五类主动服务等级。其中一级工单为232条,二级工单为208条,由于一级、二级工单的主动服务等级较高,需要进行及时处理,所以以 下重点分析一级、二级工单在各区域的分布情况以及模型验证监测分析。各等级工单数据分布详情见图6:
(1)各等级工单在区域的监测分析
根据模型监测结果,南京市区一级、二级工单数量最多分别为109条和90条;其次为江宁区分别为66条和62条;浦口、六合、溧水相对较少,其中浦口分别为20、24条,六合分别为14、14条,溧水区分别为14、10条;高淳区最少分别为9、8条。各等级工单在区域的业务和数量分布详见下表:
(2)一级、二级工单内容分析
根据模型监测结果,各区域一级工单内容排名最高的为报修-无电,占比分别为江宁约占26%,浦口约占28%,市区约占22%,六合约占31%,高淳约占26%,溧水约占31%;一级工单内容排名第二的为设备-故障和报修-多户-无电,其中江宁、浦口和南京市区排名第二的内容是设备-故障,分别占16%、18%和21%,六合、高淳和溧水排名第二的内容为报修-多户-无电,分别占18%、19%和25%。二级工单内容在各区域的占比排名情况与第一等级类似。
2、模型预警监测分析
在监测周期内,利用主动服务预警模型,共预警一级、二级工单440条(投诉类工单128条,非投诉类工单312条)。经过验证发现,在一级、二级非投诉类工单中有35条最终引起客户投诉,其中有13条工单(一级工单7条,二级工单6条)直接引起客户投诉,主要业务类型是故障报修5条、服务申请3条、业务咨询5条;剩余22条(一级工单12条,二级工单10条)工单是通过关联最终引起客户投诉,共9条。在这35条工单中,业务咨询占比最高约为54%,其次是故障报修和服务申请,分别约为34%、12%。
通过对模型预警结果的监测分析,在实际发生的128条投诉工单中,有106条是客户在没有历史行为的情况下直接进行投诉。剩余工单是客户在投诉前有相应的故障报修、业务咨询等历史行为,且全部包含在本次监测结果中。验证了模型对监测周期内非投诉类工单后期转化为投诉工单的捕获能力。
利用投诉预警模型,及时捕获投诉风险度较的工单,便于业务部门及时开展主动服务,从而降低投诉工单数据,提升客户的满意度。
- 还没有人留言评论。精彩留言会获得点赞!