基于表面缺陷分布特征的钢卷表面缺陷判定方法与流程
本发明涉及一种钢卷表面缺陷判定方法,特别是涉及一种基于表面缺陷分布特征的钢卷表面缺陷判定方法。
背景技术:
在宝钢智慧制造的大背景下,宝钢搭建了以大数据技术为基础的工序质量数据平台。工序质量数据平台中将生产过程中所有与工序质量、工艺流程相关的数据放到一起组成工序质量数据中心。工序质量数据平台,并不是简单的完成数据的获取和存储,并供分析使用,可以通过数据还原生产过程。
目前,在宝钢的质量管理体系中,表面缺陷的有效判定对稳定生产、减少表面类缺陷质量异议、质量缺陷原因查找和改进发挥了重要作用。针对钢卷表面缺陷判定的工作,主要由宝钢的质量专家团队依靠表面缺陷检测设备提供的图片、缺陷分类、描述等信息综合分析,通过人工经验及检化验手段判定完成。在整个判定过程中,缺乏对检测信息和生产信息系统应用。
宝钢工序质量数据平台中包含表面缺陷检测设备信息以及完整的生产过程信息,为钢卷表面缺陷判定提供了数据基础,亟需充分利用数据分析方法及大数据平台的数据信息,以创新性视角审视表面缺陷,分析表面缺陷,从而提升表面缺陷判定效率,降低人为因素对缺陷判定的影响。
技术实现要素:
本发明所要解决的技术问题是提供一种基于表面缺陷分布特征的钢卷表面缺陷判定方法,其利用规则,完成了基于分布特征的钢卷表面缺陷量化描述,为表面缺陷分析增加了新的分析视角,完成了基于表面缺陷分布特征的缺陷分类;在多批次、跨机组的缺陷分析中为技术专家在回溯缺陷成因的过程提供数据支撑,从而提升表面缺陷判定效率,降低人为因素对缺陷判定的影响。
本发明是通过下述技术方案来解决上述技术问题的:一种基于表面缺陷分布特征的钢卷表面缺陷判定方法,其包括以下步骤:
步骤一,确定数据范围;
步骤二、噪音数据过滤;
步骤三、钢卷缺陷位置标准化:将缺陷在钢卷上的坐标,均转换为0至1之间,钢卷的长度和宽度均标准化为1;
步骤四、钢卷网格化:将钢卷划分为头部、尾部、传动侧、操作侧、中心线,及钢卷内部六个大的区域;
步骤五、通过数据探索确定各区域的划分范围;
步骤六、头部、尾部、传动侧、操作侧及中心线集中度判定方法;
步骤七、网格区域缺陷分布判定;
步骤八、聚类分析。
优选地,所述步骤一包括以下步骤:
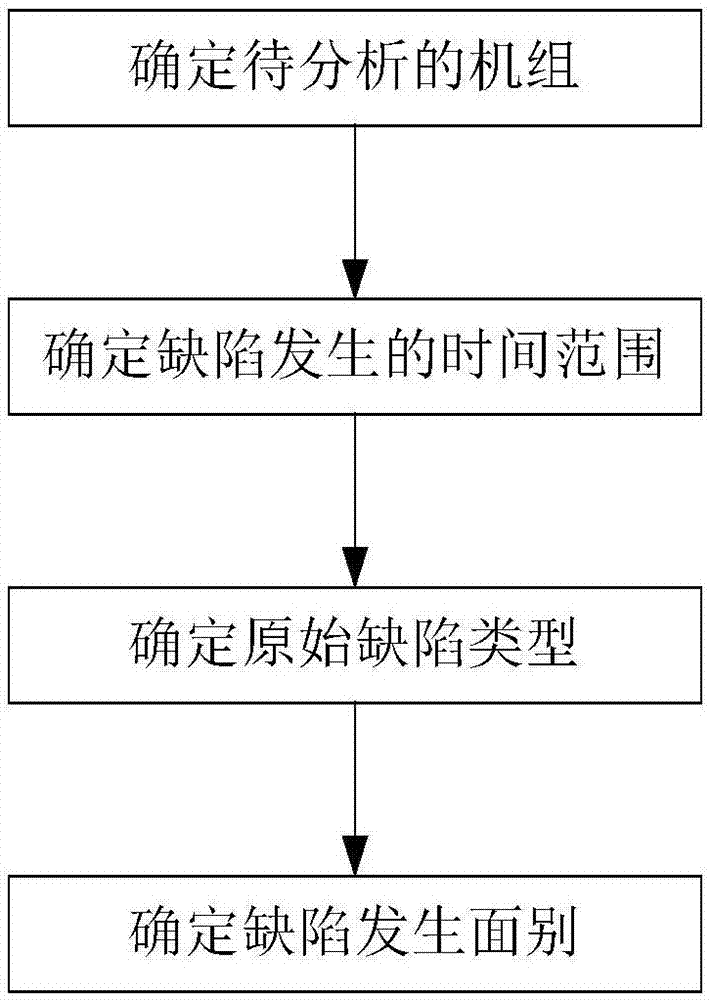
步骤十一,确定待分析的机组;
步骤十二,确定缺陷发生的时间范围;
步骤十三,确定原始缺陷类型;
步骤十四,确定缺陷发生面别。
优选地,所述步骤二包括以下步骤:
步骤二十一,过滤超过钢卷宽度范围的缺陷;
步骤二十二,过滤超过钢卷长度范围的缺陷;
步骤二十三,过滤卷号为空的卷。
优选地,所述步骤五中划分的范围包括头部区域:0<=y<=0.05,尾部区域:0.95<=y<=1,传动侧区域:0<=x<=0.1,操作侧区域:0.9<=x<=1,中心线区域:0.45<=x<=0.55,内部区域:0.1<x<0.9and0.05<y<0.95。
优选地,所述步骤六中的判定方法包括区域划分和集中度判断,其中:
区域划分,头部、尾部:以0.1为步长,将头部、尾部区域平均分成10份;传动侧、操作侧、中心线:以0.05为步长,将传动侧、操作侧、中心线区域平均分成200份;
集中度判断,在分析中,对于区域划分得到的小格子,以其中格子内的缺陷个数、钢卷缺陷总数,作为每个格子的数值描述;数据抽样获得参考值,随机抽取50%的钢卷,分别计算头部、尾部、传动侧、操作侧及中心线区域,每个格子的数值;分别求出各个区域中,每个格子的均值和方差;通过数据探索确定集中度判定规则;通过数据探索确定集中度判定规则采用头/尾部集中度判定规则,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对头部、尾部有效格子数在十分之三以上的判定为集中;传动侧、操作侧集中度判定规则:格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对传动侧、操作侧有效格子数在二十分之三以上的判定为集中;中心线集中度判定规则:格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对中心线上有效格子数在二十分之三以上的判定为集中。
优选地,所述步骤七包括区域划分、网格区域宽度方向集中度的判定规则、网格区域长度方向集中度的判定规则,其中:
区域划分,进行网格分布判定的区域为前述的钢卷内部区域,0.1<x<0.9and0.05<y<0.95;在宽度方向上,以0.1为步长,平均分为8块;在长度方向上,以0.009为步长,平均分为100块;按以上规则,将全部内部区域,划分为8*100个网格;
网格区域宽度方向集中度的判定规则,与中心线集中度判定类似,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对网格区域宽度方向每一列有效格子数在十分之三以上的判定为集中,只要有八分之一列集中,该卷网格区域宽度方向上集中;
网格区域长度方向集中度的判定规则,与宽度方向上判定类似,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对网格区域长度方向每一行有效格子数在四分之三以上的判定为集中,只要有一百分之一行集中,该卷网格区域长度方向上集中。
优选地,所述步骤八包括层次聚类和k-means聚类,层次聚类用于定义距离的统计量包括了欧氏距离、马氏距离、两项距离、明氏距离,k-means聚类根据层次聚类结果热力图显示的簇类数目确定k-means中的聚类簇数目,利用快速聚类的简洁和快速性,对钢卷表面缺陷进行聚类分析。
本发明的积极进步效果在于:本发明利用规则,完成了基于分布特征的钢卷表面缺陷量化描述,为表面缺陷分析增加了新的分析视角,完成了基于表面缺陷分布特征的缺陷分类;在多批次、跨机组的缺陷分析中为技术专家在回溯缺陷成因的过程提供数据支撑,从而提升表面缺陷判定效率,降低人为因素对缺陷判定的影响。
附图说明
图1为本发明基于表面缺陷分布特征的钢卷表面缺陷判定方法的流程示意图。
图2为本发明中步骤一的流程示意图。
图3为本发明中步骤二的流程示意图。
具体实施方式
下面结合附图给出本发明较佳实施例,以详细说明本发明的技术方案。
如图1所示,本发明基于表面缺陷分布特征的钢卷表面缺陷判定方法包括以下步骤:
步骤一,确定数据范围;
步骤二、噪音数据过滤;
步骤三、钢卷缺陷位置标准化:将缺陷在钢卷上的坐标,均转换为0至1之间,钢卷的长度和宽度均标准化为1;
步骤四、钢卷网格化:将钢卷划分为头部、尾部、传动侧、操作侧、中心线,及钢卷内部六个大的区域(区域间有重叠);
步骤五、通过数据探索确定各区域的划分范围;
步骤六、头部、尾部、传动侧、操作侧及中心线集中度判定方法;
步骤七、网格区域缺陷分布判定;
步骤八、聚类分析。
所述步骤一包括以下步骤:
步骤十一,确定待分析的机组;
步骤十二,确定缺陷发生的时间范围;
步骤十三,确定原始缺陷类型;
步骤十四,确定缺陷发生面别(钢卷上表面或下表面)。
所述步骤二包括以下步骤:
步骤二十一,过滤超过钢卷宽度范围的缺陷;
步骤二十二,过滤超过钢卷长度范围的缺陷;
步骤二十三,过滤卷号为空的卷。
所述步骤五中划分的范围包括头部区域:0<=y<=0.05,尾部区域:0.95<=y<=1,传动侧区域:0<=x<=0.1,操作侧区域:0.9<=x<=1,中心线区域:0.45<=x<=0.55,内部区域:0.1<x<0.9and0.05<y<0.95。
所述步骤六中的判定方法包括区域划分和集中度判断,其中:
区域划分,头部、尾部:以0.1为步长,将头部、尾部区域平均分成10份;传动侧、操作侧、中心线:以0.05为步长,将传动侧、操作侧、中心线区域平均分成200份;
集中度判断,在分析中,对于区域划分得到的小格子,以其中格子内的缺陷个数、钢卷缺陷总数,作为每个格子的数值描述;数据抽样获得参考值,随机抽取50%的钢卷,分别计算头部、尾部、传动侧、操作侧及中心线区域,每个格子的数值;分别求出各个区域中,每个格子的均值和方差;通过数据探索确定集中度判定规则;通过数据探索确定集中度判定规则采用头/尾部集中度判定规则,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对头部、尾部有效格子数在十分之三以上的判定为集中;传动侧、操作侧集中度判定规则:格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对传动侧、操作侧有效格子数在二十分之三以上的判定为集中;中心线集中度判定规则:格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对中心线上有效格子数在二十分之三以上的判定为集中。
所述步骤七包括区域划分、网格区域宽度方向集中度的判定规则、网格区域长度方向集中度的判定规则,其中:
区域划分,进行网格分布判定的区域为前述的钢卷内部区域,0.1<x<0.9and0.05<y<0.95;在宽度方向上(x轴),以0.1为步长,平均分为8块;在长度方向上(y轴),以0.009为步长,平均分为100块;按以上规则,将全部内部区域,划分为8*100个网格;
网格区域宽度方向集中度的判定规则,与中心线集中度判定类似,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对网格区域宽度方向每一列有效格子数在十分之三以上的判定为集中,只要有八分之一列集中,该卷网格区域宽度方向上集中;
网格区域长度方向集中度的判定规则,与宽度方向上判定类似,格子里的数值为非空,且根据均值和方差,落在每块格子的缺陷概率在20%以上的格子才有效,对网格区域长度方向每一行有效格子数在四分之三以上的判定为集中,只要有一百分之一行集中,该卷网格区域长度方向上集中。
所述步骤八包括层次聚类和k-means(硬聚类算法)聚类,层次聚类用于定义距离的统计量包括了欧氏距离、马氏距离、两项距离、明氏距离,k-means聚类根据层次聚类结果热力图显示的簇类数目确定k-means中的聚类簇数目,利用快速聚类的简洁和快速性,对钢卷表面缺陷进行聚类分析。
算法选择,聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法,它们讨论的对象是大量的样品,要求能合理地按各自的特性来进行合理的分类,没有任何模式供参考或依循,是在没有先验知识的情况下进行的。
其基本思想是:样本(或变量)间存在着相似性,根据多个观测指标,找出能度量样本之间相似程度的统计量,以其为依据,把相似程度较大的样本聚合为一类,关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有样本都聚合完毕,把不同的类型一一划分出来,形成一个由小到大的分类系统。聚类的原则是同一类中的个体有较大相似性,不同类中的个体差异很大。
基于聚类分析的以上特点,在这里我们使用聚类分析相关算法对钢卷表面缺陷进行特征归类,得到每类钢卷的缺陷分布特征。
聚类分析有两种主要计算方法,分别是层次聚类和k-means聚类。
层次聚类又称为系统聚类,首先要定义样本之间的距离关系,距离较近的归为一类,较远的则属于不同的类。用于定义“距离”的统计量包括了欧氏距离、马氏距离、两项距离、明氏距离。还包括相关系数和夹角余弦。
其优点是:
a)对初始数据集不敏感;
b)能很好的处理孤立点和噪声数据;
c)不需要指定簇的个数。
缺点是:复杂度高;一旦一个合并或分裂被执行,就不能修正;重叠的点往往很难决定要合并或者分裂。
k-means是一种基于距离的迭代式算法。它将n个观察实例分类到k个聚类中,以使得每个观察实例距离它所在的聚类的中心点比其他的聚类中心点的距离更小。
它一般从一个初始划分开始,然后通过重复的控制策略,使某个准则函数最优化。k-means的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。k-means的目标是要将数据点划分为k个cluster(群),找到这每个cluster的中心。
该算法最大优势在于简洁和快速,对于处理大数据集,该算法是相对可伸缩和高效率的。缺点是簇的数目必须人为的指定,并且对初值敏感,对于不同的初值,可能会导致不同结果,而且不适于发现非凸面形状的簇或者大小差别很大的族,它对于噪声和孤立点是敏感的。
综上所述,需要利用层次聚类和k-means聚类的优点,利用层次聚类确定k-means聚类簇的数目,以达到最好的聚类效果。
在本发明中,基于宝钢工序质量数据平台提供的表面缺陷检测设备信息及生产信息,结合专家经验,利用数据挖掘方法,实现基于缺陷分布特征的钢卷表面缺陷的判定方法,提升业务专家的缺陷判定效率,为缺陷原因回溯的更多数据支持。目前,本发明可以应用于工序质量管理平台,具体如下:
1)面向成因的表面缺陷再定义分类。分别从单个缺陷、卷和批次三个层次,对现有表面缺陷进行特征聚类,重新定义缺陷的类别。如原来是从归户或业务角度命名的钢质缺陷、氧化铁皮等,现在通过对缺陷的特征和拓展属性,进行重新聚类,如通过聚类分为位置缺陷、随机缺陷等,自定义的缺陷类别可作为业务规则、专家经验的有效补充。
2)基于表面缺陷分布特征的缺陷判定。质量缺陷分析的过程中,对于某种或某几种缺陷,可以通过缺陷发生的位置(缺陷在钢卷上的分布),对缺陷进行分类,结合质量分析的业务信息,可从面别、钢卷长度、宽度、网格化等维度,将表面缺陷细分上/下表面倾向性缺陷,边部缺陷、头尾缺陷、距中心线位置相对固定缺陷、不同网格缺陷密度分布缺陷(高原、山地、丘陵、平原)等。基于缺陷发生位置的判断结果是业务专家进行缺陷发上原因分析的线索之一。
本发明举出一个例子进行说明,具体过程如下:
一、确定数据范围:选取2015.1至2015.5期间,宝钢热轧机组h031、h032、h033生产的钢卷的上表面,对已知缺陷hd钢质保护渣系夹渣,进行基于缺陷分布特征的缺陷判定。
二、噪音数据过滤:分析数据包含钢卷(个数):162446、缺陷(个数):4361904。
三、根据步骤三至步骤七所述规则对钢卷表面缺陷特征进行离散化标记:
a)每个卷的特征包括面别倾向性(face_def):1为上表面缺陷集中,2为下表面缺陷集中,0为无面别倾向性;
b)传动侧分布集中度(left_def):1为具有传动侧分布集中度,0为无该特征;
c)操作侧分布集中度(right_def):1为具有操作侧分布集中度,0为无该特征;
d)中心线位置分布集中(mid_def):1为具有中心线位置分布集中,0为无该特征;
e)头部分布集中度(top_def):1为具有头部分布集中度,0为无该特征;
f)尾部分布集中度(bot_def):1为具有尾部分布集中度,0为无该特征;
g)宽度方向分布集中度(col_def):1为具有宽度方向分布集中度,0为无该特征;
h)长度方向分布集中度(row_def):1为具有长度方向分布集中度,0为无该特征。
以上所述的具体实施例,对本发明的解决的技术问题、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!