一种适用于键值对数据的存储方法与流程
本发明属于数据存储技术领域,更具体地,涉及一种适用于键值对数据的存储方法。
背景技术:
键值对(Key-Value,KV)数据在近年得到广泛应用,基于日志归并树(LSM-tree)的KV系统适用于写频繁的场合。基于LSM-tree结构的KV应用通常在内存中维护一个0级表,当0级表插满时,将其合并到1级表,若1级表总尺寸或表个数超过设定,则选择并入2级表,依此类推;这种结构通过插入删除符实现删除操作;由于对数据的读取总是从0级向下依次进行,在读取时新插入的数据会屏蔽掉老的数据;如果读取到了删除符,则表明该数据已经被删除。
传统的KV应用运行于文件系统之上,由于文件系统需要维护路径等索引信息,对一个数据表文件的写操作不只是对内容的写,还包括对索引信息的写,且索引信息通常与内容数据相距较远,对磁盘而言会导致寻道上的开销;另外,文件系统通常以块为基本管理单位,而基于LSM-tree的KV通常会生成较大的数据表文件,文件系统不能保证为数据表文件分配连续的块。
当前基于LSM-tree的存储系统如LevelDB、RocksDB通过文件系统将数据存储于持久性存储设备;这种存储方式无法充分将LSM-tree形成的对存储设备友好的数据反应到存储设备上。文件系统使用索引块和数据块的对存储请求在设备空间内进行组织,索引块用来定位数据块,数据块存储实际的用户数据。对数据块的更新会引起索引块的更新,读取某个数据块必须先读取索引块。
LSM-tree的设计并未考虑文件系统级的对数据的重新组织,而只是考虑存储设备的特性——对连续的请求更友好。虽然其生成的数据请求是连续的,这种连续的请求经过文件系统后,在存储设备上产生了不连续的请求,当文件系统较满时,不连续比例升高。基于log的文件系统虽然在写的时候不会导致不连续,但是为了实现这个目的引入了更多的负面效果:如回溯式更新、读性能降低、高代价的垃圾回收。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种适用于键值对数据的存储方法,其目的在于使用数据表文件的序列号对物理设备进行寻址,省去传统文件系统中的路径索引,由此解决逻辑连续的数据在物理存储上不连续的问题。
为实现上述目的,按照本发明的一个方面,提供了一种适用于键值对数据的存储方法,具体包括如下步骤:
(1)将存储区域划分为日志区和数据区;并将数据区划分为大小固定的存储槽;
(2)根据文件名将日志归并树合并操作中生成的数据表文件一一映射到存储槽上;所述数据表文件具有唯一的序列号,所述存储槽具有一个描述符块;
(3)将日志类型的键值对数据存储到所述日志区;将数据表请求类型的键值对数据插入内存中的数据表并在数据表达到预设尺度是进行内存表合并。
优选地,上述适用于键值对数据的存储方法,其步骤(3)包括如下子步骤:
(3.1)将日志类型的键值对数据以追加的方式写入日志区;
(3.2)将数据表请求类型的键值对数据插入内存中的数据表,当数据表达到预设尺度,则进入步骤(3.4);否则进入步骤(3.3);
(3.3)接收新的键值对数据,进入步骤(3.2);
(3.4)启用后台线程,将内存表与硬盘上的第一层表进行合并;若合并后的第一层表的数据未超过预设尺度,则结束;否则将第一层表合并至第二层,直到所有层的数据都在预设尺度之内。
优选地,上述适用于键值对数据的存储方法,在步骤(3.4)中,将合并产生的数据表进行缓存,直至生成一个完整的数据表;在内存中将该完整的数据表组装构成一个slot数据包,然后将该slot数据包写入对应的存储槽。
优选地,上述适用于键值对数据的存储方法,在步骤(3.4)的合并操作中,将归并操作与读写操作并行处理,以提高系统吞吐率。
优选地,上述适用于键值对数据的存储方法,以单向的方式、按照序号从0、1、2……、N-1、0、1、2……、N-1的方式循环分配存储槽;当某个存储槽已经被占用,则向后顺延至最近的空闲存储槽;若遍历所有存储槽都未发现空闲槽,则报告存储器已满。
优选地,上述适用于键值对数据的存储方法,所述存储槽的描述符内容包括存储槽使用状态、数据表长度和校验码;其中,存储槽使用状态占用1字节,数据表长度占用8字节,校验码占用8字节。
优选地,上述适用于键值对数据的存储方法,采用物理块作为描述符块;描述符块预留有用作扩展功能的空间。
优选地,上述适用于键值对数据的存储方法,在键值对数据应用请求对slot数据包进行写请求的同时对描述符进行存储。
优选地,上述适用于键值对数据的存储方法,对合并操作所产生的slot数据包写请求与log操作产生的写请求分开处理;
对log请求则直接读写并以读写数据单位进行存储;
对Slot数据包请求则一次发送整个Slot数据包大小的数据,以尽可能提高存储设备的利用率。
优选地,上述适用于键值对数据的存储方法,以512字节作为log请求里的数据单位。
优选地,上述适用于键值对数据的存储方法,在系统启动时,根据描述符在内存中生成一个位图用于指示所有存储槽的使用状态,在分配存储槽时通过查询该位图快速查找空闲的存储槽,以加快分配过程。
优选地,上述适用于键值对数据的存储方法,通过在内存中维护一个空闲表用于保存空闲slot序列用以存储槽分配,以避免分配存储槽时的读写。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明所提供的适用于键值对数据的存储方法,消除了LSM-tree在通用文件系统上的目录级和文件级索引,使得LSM-tree产生的连续数据写请求能够反映到存储介质层;
(2)本发明所提供的适用于键值对数据的存储方法,对LSM-tree的请求类型进行了抽象,将其简化为log写和数据表写;其中log写是小而频繁的追加写请求,而数据表存储是大块的写请求;本发明所提供的这种方法对log写使用512字节的单位进行写盘以减小log写带来的写放大;对数据表请求使用以slot为单位进行写盘以尽可能利用存储介质的带宽;
(3)本发明所提供的适用于键值对数据的存储方法,由于在键值对应用请求对缓存进行写请求的同时对描述符进行存储,无需使用额外的读写进行描述符信息写入,使得数据表的写操作在存储介质上在时间上和空间上都是连续的,解决了逻辑连续的数据在物理存储上不连续的问题;
(4)本发明所提供的适用于键值对数据的存储方法,由于对slot的写和删除操作都是整体操作,不需要进行垃圾回收操作,一个slot被删除后变为空闲slot以等待被分配,极大地提高了存储性能。
附图说明
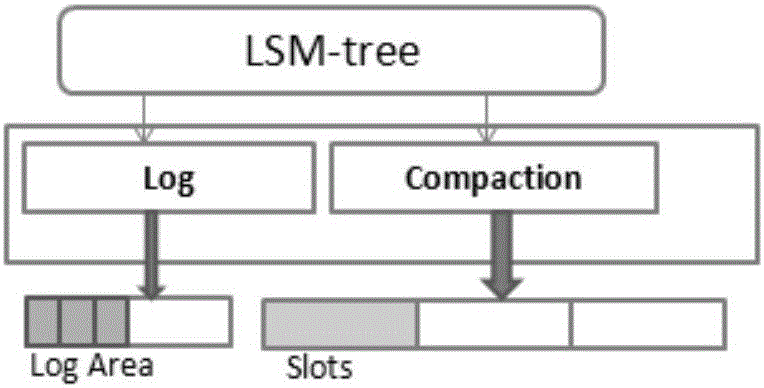
图1是LSM-tree的结构示意图;
图2是本发明实施例所提供的存储方法的示意图;
图3是本发明实施例对存储设备的划分示意图;
图4是本发明实施例中slot的内部结构;
图5是本发明实施例中slot的分配方式;
图6是本发明实施例中的合并方式示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
图1所示,是实施例里LSM-tree的结构示意图;基于LSM-tree的KV系统在每个写请求到达时产生log请求,并将请求缓存在一个内存表里(C0),当这个内存表达到预设的大小(4MB)时,将其写入永久性存储设备的中的一层(C1);当C1达到预设的大小时,会选择部分数据将其归并到C2。图2所示为本发明所提供的存储方法的示意图;基于LSM-tree的KV产生两种类型的写请求,包括由log操作产生的log数据存储,由compaction操作产生的chunk表数据存储;实施例所提供的存储方法,对这两类写请求采用不同的处理方式。
图3所示,是实施例里对存储设备进行划分的示意图;在本实施例中,将存储对象划分为三个存储区域:保留区、log区、以及chunk区;对存储对象的划分不限于该实例,在实际使用中,可根据需求进行其他划分,譬如:将log区也放入chunk区或者使用不同的存储设备。
在本实施例中,LSM-tree本身的全局管理数据存储在保留区,LSM-tree产生的log数据和chunk数据分别存储在log区和chunk区;log区以循环的方式使用;每次compaction操作产生新的chunk。在实施例中,将LSM-tree的所有产生chunk的操作都认为是compaction操作。为新的chunk分配空闲的slot,并按照slot的位置为chunk赋予号码;如此设置使得从chunk到slot的映射不涉及额外的索引信息。当对chunk进行存储时,首先对chunk进行封包,封包处理根据chunk的尺寸填充描述符块,实施例里的封包处理过程如图4所示;
在实施例里,根据描述符块构建一个位图以指示所有slot的使用状态;通过维护一个如图5所示的空闲表,保存一串空闲的slot序列。每次对新的chunk进行存储时,首先从空闲表进行slot分配;一个线程读取位图以对空闲表进行填充;本实施例中,位图和空闲表的设置均是为了加快slot的分配速度。
在进行compaction操作时,将merge过程与dump过程进行分离;merge过程不断产生新的chunk,dump过程将这些chunk存入设备,其过程如图6所示。相比于传统LSM-tree,本实施例所提供的存储方法在HDD和SSD上均能提高键值对的存储性能;在HDD上的存储性能可提高1~2倍,在SSD上可提高2~3倍;本存储方法对数据表进行了紧凑存储并消除了从数据表ID到物理位置之间的索引,提高了读性能;经过实际测试,对于大小为100GB、平均键值对长度为100字节的数据集,采用本实施例所提供的适应于键值对数据的存储,可将读性能提高约20%。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!