一种基于程序切片的功能可复用性度量方法与流程
本发明涉及软件演化领域中的功能可复用性度量领域,尤其是一种基于程序切片的功能可复用性度量方法。
背景技术:
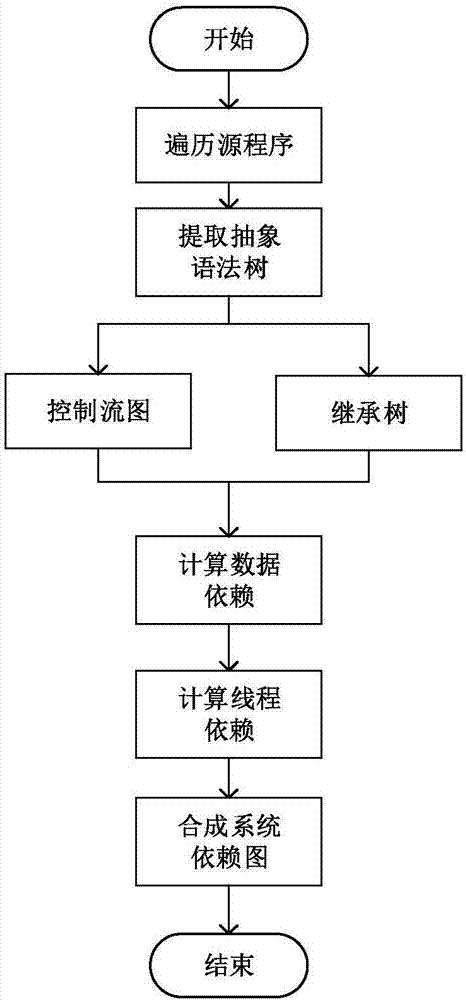
:模块化开发已经成为软件开发过程中重要的核心思想,其目的是在大规模、业务逻辑复杂的软件产品中能够有效的降低模块之间的耦合度,便于软件后期维护,同时也能够便于功能模块的提取,有效的复用在其他软件中,达到降低开发成本和缩短开发周期的目的,对提高软件可靠性和开发质量具有十分现实的意义。对软件中相关代码可复用性的度量通常包括两步,首先是提取或者定位到复用的代码,然后是从依赖关系复杂性等多方面进行度量。现有的代码复用性在实际应用过程中所存在不足是:(1)复用对象粒度较大。对复用性度量的对象大多是组件,没有细化到组件中某一个指定的功能,增加了复用对象规模的同时提高了复用风险。(2)复用对象的关联代码精准度较低。通过建立的uml图将复用对象与相关功能或组件进行关联,不能准确定位到具体语句,从而易造成复用代码规模的冗余和缺漏;(3)缺少全体复用对象的复用难易程度对比。对源程序中复用对象的复用难易程度缺少全局角度的考虑,与源程序中其他的复用对象没有鲜明的对比。技术实现要素:发明目的:为解决上述技术问题,本发明提供一种基于程序切片的功能可复用性度量方法。本发明能够实现对复用对象的细粒度提取和代码依赖关系的精准计算与提取,并对源程序中所有功能模块的可复用性进行对比,从而筛选出复用难度较低的功能模块。技术方案:为实现上述技术效果,本发明提出的技术方案为:一种基于程序切片的可复用性度量方法,该方法包括以下步骤:步骤1:构建系统依赖图,并将系统依赖图存入依赖图知识库;所述系统依赖图包括语句之间的依赖关系和变量之间的依赖关系,所述依赖关系包括控制依赖和数据依赖;步骤2:对源程序进行遍历,提取源程序中所有功能模块的功能接口代码;将功能接口代码作为对应功能模块的起始语句,并将每个起始语句所在的文件路径和行号作为二元组存入接口知识库中;步骤3:将步骤2中提取到的功能接口代码作为提取各个功能模块的切片准则计算源程序的切片结果,并将切片准则和切片结果相对应的存入切片知识库中;每个切片结果对应一个功能模块,切片结果中包括对应功能模块中与切片准则相关联的语句;步骤4:根据步骤2中提取到的功能接口代码和步骤3中得到的切片结果分别构建用于评价各功能模块可复用性的度量指标,并计算各功能模块在度量指标上的度量值;对于任意一个功能模块,其度量指标为该模块的群聚度、内聚度、圈复杂度、公共方法数、最大嵌套层数以及耦合度均值,所述耦合度均值为该功能模块与其他功能模块的耦合度平均值;步骤5:根据步骤4构建出的度量指标,计算每一项度量指标的度量值总和为:式中,valueij表示功能模块i在度量指标j中的度量值;步骤6:构建功能模块可复用性度量值计算公式为:relativevalue(i)=clustering(i)per+cohesion(i)per-complexity(i)per-summethod(i)per-maxnextinglayer(i)per-coupling(i)per式中,relativgvalue(i)表示功能模块i的可复用性度量值,clustering(i)per表示功能模块i的群聚度占群聚度总和的百分比,cohesion(i)per表示功能模块i的内聚度占内聚度总和的百分比,complexity(i)per表示功能模块i的圈复杂度占圈复杂度总和的百分比,summethod(i)per表示功能模块i的公共方法数占公共方法数总和的百分比,maxnextinglayer(i)per表示功能模块i的最大嵌套层数占最大嵌套层数总和的百分比,coupling(i)per表示功能模块i的耦合度均值占耦合度均值总和的百分比;步骤7:根据功能模块可复用性度量值选取功能模块,复用值越大,表示对应功能模块的可复用性越高。进一步的,所述群聚度的计算方法为:式中,clustering(rfmi)表示功能模块i的群聚度;rfmi表示功能模块i对应的切片结果,i∈[1,n],n表示功能模块的总数;k表示rfmi中聚集块的个数,所述聚集块为rfmi中的语句划分块,定义rfmi中任意一个聚集块为cbk,cbk满足:从rfmi中划分出一个聚集块的方法为:对rfmi中的语句进行编号,定义rfmi中属于文件s的第a条语句编号为sa;判断rfmi中属于文件s的任意两条语句sa、sb是否同时满足以下条件:sa-1(da-1)≠sa(da)-1sb(db)=sa(da)+b-a式中,da-1、da和db分别表示语句sa-1、sa、sb在源程序中的行号;若判断结果为满足,则将文件s的第a~b条语句划分为一个聚集块。进一步的,所述内聚度的计算方法为:式中,cohesion(rfmi)表示功能模块i的内聚度,m表示rfmi中包含的方法的总数;x表示rfmi中的第x个方法,v(x)表示方法x中的所有变量的集合,|slice(x,v(x))|method表示运算步骤:以v(x)中的变量为切片准则对功能模块i的切片结果进行第二次切片,统计所有二次切片结果中的方法数之和。进一步的,所述圈复杂度的计算方法为:complexity(rfmi)=p+1式中,complexity(rfmi)表示功能模块i的圈复杂度,p表示rfmi中判定节点的个数;所述判定节点包括语句:for、foreach、if、while、do...while、switch。进一步的,所述公共方法数的计算方法为:summethod(rfmi)=∪mq式中,summethod(rfmi)表示功能模块i中的公共方法数,∪表示求联合集运算符号,mq表示以rfmi中第q个公共方法中的变量为切片准则计算得到的第二次切片结果中所包含的公共方法数之和。进一步的,所述最大嵌套层数的计算方法为:maxnextinglayer(rfmi)=max(nl(mq))式中,maxnextinglayer(rfmi)表示功能模块i中的最大嵌套层数,nl(mq)表示取公共方法mq的嵌套层数,max()表示取最大值。进一步的,所述耦合度均值的计算方法为:式中,coupling(rfmi)表示功能模块i与源程序中其他功能模块的耦合度的均值,|rfmi∩rfmt|表示rfmi和rfmt中完全相同的语句的个数,|rfmi∪rfmt|表示rfmi和rfmi中所有语句的总数。进一步的,当切片结果中仅包含1个方法时,其内聚度为1。进一步的,在执行步骤1之前,还包括步骤:对源程序进行预处理,识别源程序代码中的空行和注释行并删除,将所有源代码处理为全部为有效代码行。进一步的,所述步骤1中构建系统依赖图的方法为:对源程序进行遍历,提取源程序的抽象语法树,根据抽象语法树建立控制流图和继承树,再基于控制流图和继承树计算语句之间和变量之间的数据依赖和线程依赖,最后将依赖关系集成为系统依赖图。有益效果:本发明将程序切片技术应用于功能模块度量,与现有技术相比,具有以下优势:(1)本发明实现对细粒度对象的分析,可具体到某一语句甚至变量,因此可适用于不同粒度对象的可复用性度量;(2)本发明基于程序切片技术计算功能模块的关联语句,通过语句和变量之间的依赖遍历,针对复用对象所提取的关联的语句具有更高的准确性,从而度量结果更具有可靠性;(3)实现批量化度量,对所有的功能模块自动化批量化进行可复用性的度量,降低操作复杂性,提高的平均度量时间。(4)对所有功能模块可复用性进行相比较,通过可复用性相对值,筛选出源程序中可复用性相对较高的功能模块,提高复用效率。附图说明图1为本发明实施例的原理流程图;图2为实施例中程序依赖图的构造流程图。具体实施方式下面结合附图对本发明作更进一步的说明。本发明的原理流程如图1所示,包含以下步骤:s1:对源程序进行遍历,删除无效代码行,例如空行、注释行等。通过预处理,实现有效代码行排列的紧凑性,降低在度量过程中产生的误差;s2:对源程序进行解析,构造程序依赖图。依赖图中包含语句之间的依赖关系和变量之间的依赖关系,依赖关系主要包括控制依赖、数据依赖等,通过语句之间的直接依赖和间接依赖可以获取与指定语句或变量运行结果相关的语句集合;s3:对源程序进行解析,将所有接口作为功能模块的起始语句,并将所有语句所在的文件路径和行号作为二元组存入接口知识库中;s4:利用s2中的程序依赖图和步骤3中获取到的功能接口集合,将功能接口集合中的所有接口的代码作为准则,计算其切片,获取关联语句集合并存入切片知识库中;s5:利用s3和s4中获取到的功能模块接口和其关联语句集合,进行如下计算:(1)群聚度clustering:通过切片结果中原始相邻接语句所组成的聚集块的数量度量切片语句在源程序中上下文紧密程度。rfmi表示功能模块i的切片结果包含的语句,i∈[1,n],n表示切片的总数,即s3中的接口总数集合。h为切片的规模,即切片中语句的条数,h=|rfmi|。cbk是rfmi的一个代码划分块,记为聚集块。从rfmi中划分出一个聚集块的方法为:对rfmi中的语句进行编号,定义rfmi中属于文件s的第a条语句编号为sa;判断rfmi中属于文件s的任意两条语句sa、sb是否同时满足以下条件:sa-1(da-1)≠sa(da)-1sb(db)=sa(da)+b-a式中,da-1、da和db分别表示语句sa-1、sa、sb在源程序中的行号;若判断结果为满足,则将文件s的第a~b条语句划分为一个聚集块,即有|cbk|=b-a+1。k是rfmi中聚集块的个数,且群聚度的计算公式为:(2)复杂度complexity:表示为具体某一功能接口切片得到相应的圈复杂度、公共方法数和以及最大嵌套层数。(a)圈复杂度:定义p为判定节点的个数,判定节点包括for,foreach,if,while,do...while,switch语句。圈复杂度的计算公式为:complexity(rfmi)=p+1(b)公共方法数:通过度量功能模块切片结果中的方法总数,说明复用该功能模块所涉及到的公共方法数量。r表示功能模块i中的公共方法总数,mq表示以rfmi中第q个公共方法中的变量为切片准则计算得到的第二次切片结果中所包含的公共方法数之和,q∈[0,r],∪表示求联合集运算符号。公共方法数的计算公式为:summethod(rfmi)=∪mq(c)最大嵌套层数maxnestinglayer:通过度量最大嵌套层数表明功能模块的逻辑的复杂程度。方法中的嵌套方式包括所有的for,foreach,if,while,do...while,switch语句。nl(mq)表示取公共方法mq的嵌套层数,max()表示取最大值。最大嵌套层数的计算公式为:maxnextinglayer(rfmi)=max(nl(mq))(3)耦合度coupling:通过切片重合程度计算模块之间的耦合度。rfmi∩rfmt为rfmi和rfmt中,完全相同的语句的集合;|rfmi∩rfmt|表示rfmi和rfmt中完全相同的语句的个数;rfmi∪rfmt为rfmi和rfmt中所有语句的集合,|rfmi∪rfmt|表示rfmi和rfmi中所有语句的总数。功能模块i和功能模块t之间的耦合度的计算公式为:(4)内聚度cohesion:表示功能模块内方法间的紧密程度,内聚度范围为[0,1],内聚度越接近于1越好。m表示rfmi中的方法总数,x表示rfmi中的第x个方法,v(x)表示方法x中的所有变量的集合,|slice(x,v(x))|method表示运算步骤:以v(x)中的变量为切片准则对功能模块i的切片结果进行第二次切片,统计所有二次切片结果中的方法数之和。s6:统计并计算功能模块在当前源代码中的可复用性相对值,进行如下计算:(1)统计所有度量指标总和为了衡量功能模块的度量指标在相对于其他功能模块的大小,统计所有度量指标的总和。sumvaluej是度量指标j的度量值总和,valueij表示功能模块i在度量指标j中的度量值。度量指标总和sumvaluej的度量公式为:(2)计算功能模块可复用性相对值统计各个功能模块的度量指标占该项度量指标总和的百分比,从而说明指定的功能模块在项目整体中可复用性的相对值。relativevalue(i)表示功能模块i的可复用性度量值,clustering(i)per表示功能模块i的群聚度占群聚度总和的百分比,cohesion(i)per表示功能模块i的内聚度占内聚度总和的百分比,complexity(i)per表示功能模块i的圈复杂度占圈复杂度总和的百分比,summethod(i)per表示功能模块i的公共方法数占公共方法数总和的百分比,maxnextinglayer(i)per表示功能模块i的最大嵌套层数占最大嵌套层数总和的百分比,coupling(i)per表示功能模块i的耦合度均值占耦合度均值总和的百分比。在以上的六个度量指标中,群聚度和内聚度与可复用性为正相关,而圈复杂度、公共方法数和最大嵌套层数与可复用性负相关。可复用性的相对值的度量公式为:relativevalue(i)=clustering(i)per+cohesion(i)per-complexity(i)per-sunmethod(i)per-maxnextinglayer(i)per-coupling(i)per下面结合附图与具体实施方式对本技术方案进一步说明。为了方便描述,我们以一个功能模块a切片结果为例对本技术方案进行详细描述。设在源程序中,以文件tryvisitor.java中的第26行语句为切片准则进行切片,得到功能模块a的切片结果如表1所示:表1由上表可知,功能模块a的切片结果中包含9条语句,这9条语句分别属于两个文件:tryvisitor.java和compileunit.java;将9条语句按照所属文件分为两组,并对每一组语句进行编号。按照以下步骤进行功能模块a的可复用性度量:步骤1:对源程序进行预处理,为减小度量结果的误差,识别源代码中的空行和注释行并删除,将所有源代码处理为全部为有效代码行;步骤2:对源程序进行遍历,提取程序的抽象语法树,根据抽象语法树建立控制流图和继承树,再基于以上信息计算语句之间和变量之间的数据依赖和线程依赖,最后将依赖关系集成为系统依赖图并存入依赖图知识库,具体处理流程如图2所示;步骤3:对源程序进行遍历,根据源程序关键字判断功能模块的起始语句,通过对源程序的遍历,提取功能模块;记录功能接口的基本信息,例如所在的文件路径和行号等;步骤4:将步骤2中提取到的功能接口作为提取各个功能模块的切片准则,计算各切片准则对应的切片结果,每个切片结果关联一个功能模块;一个功能模块的切片结果为关联该功能的必要语句的集合;将切片准则和切片结果相对应存入切片知识库中;步骤5:对功能模块的可复用性进行度量,以功能模块a为例,进行以下计算:(1)群聚度:通过切片结果中原始相邻接语句所组成的聚集块的数量度量切片语句在源程序中上下文紧密程度。rfma表示功能模块a的切片结果,rfma包含9条语句,即上表中tryvisitor.java的26,28-30行和32行,compileunit.java的11-12行和17-18行。rfma中的切片规模h为9,在属于文件tryvisitor.java的5条语句中,s2,s4分别第2条和第4条语句,且满足1≤2≤h,1≤4≤h,分别对应s(28)和s(30),即源代码文件中的28和30行。s2-1(26)≠s2(28)-1且s4(30)=s2(28)+(4-2),因此s2~s4为一个聚集块。按照上述原理,rfma中包含5个聚集块,即k=5。依据群聚度的度量公式计算功能模块a的群聚度:(2)复杂度:度量功能模块本身和与其他模块关联的复杂程度,主要包括三个方面:圈复杂度、公共方法数、和最大嵌套层数。(a)圈复杂度:通过度量圈复杂度,说明判定结构的复杂程度和独立线性路径条数。在rfma中,p为1。依据圈复杂度的度量公式计算:complexity(rfma)=p+1=2(b)公共方法总数:通过度量方法总数,说明复用该功能模块所涉及到的方法规模。在属于compileunit.java文件的4条语句中,mq=2,在属于tryvisitor.java文件的5条语句中,mq=1;因此,依据公共方法数的度量公式计算:sunmethod(rfma)=∪mq=3(3)最大嵌套层数:通过度量最大嵌套层数表明功能模块的逻辑的复杂程度。nl方法表示取方法的嵌套层数,max方法表示取方法中嵌套层数的最大值。依据最大嵌套层数maxnestinglayer的度量公式计算:maxnextinglayer(rfma)=max(nl(mq))=1(c)耦合度:通过切片重合程度计算模块之间的耦合度。由于耦合度是度量两个模块之间的关联程度,因此下表以源程序中的功能模块b为例,计算功能模块b与功能模块a的耦合度。以源程序中文件tryvisitor.java的第10行为切片准则计算得到功能模块b对应的切片结果,如表2所示。表2表2中包含14个语句,这14个语句分别属于三个文件:tryvisitor.java、compileunit.java和astfileastrequestor.java,将这14个语句按照所属文件进行分组,并对每个分组中的语句进行编号,编号的结果如表2所示。rfmb表示功能模块b包含的语句集合,则:rfma={<tryvisitor,{26,28,29,30,32}>,<compileunit,{11,12,17,18}>}rfmb={<tryvisitor,{10,11,12,13,14,17,19,20}>,<compileunit,{17,18}>,<astfileastrequestor,{13,14,24,25}>}rfmb∪rfma={<tryvisitor,{10,11,12,13,14,17,19,20,26,28,29,30,32}>,<compileunit,{11,12,17,18}>,<astfileastrequestor,{13,14,24,25}>}rfmb∩rfma={<compileunit,{17,18}>}依据耦合度均值的度量公式计算:(4)内聚度:表示功能模块内方法间的紧密程度,内聚度范围为[0,1],内聚度越接近于1越好。m表示功能模块rfma中的方法总数,即为3,x表示第x个方法,此处x取2,v(2)表示方法2中的变量集合,即getfilepath方法中的变量filepath,以filepath为切片准则进行切片,再统计切片中包含的方法数,记为|slice(x,v(x))|method。此准则下方法总数为3,依据内聚度的度量公式计算:步骤6:依据度量结果对功能模块的可复用性进行整体评估。为说明整体评估流程,以下两个表格中列出了功能模块a和功能模块b的可复用性度量指标的度量结果,如表3所示。表3(1)统计所有度量指标的度量值之和为了衡量功能模块的某项指标在相对于其他功能模块的大小,统计各项度量指标的总和。经过统计,各项度量指标的总和如表4所示:表4(2)计算功能模块可复用性相对值,以模块a为例计算可复用性相对值。依据可复用性相对值的度量公式计算:relativevalue(a)=clustering(a)per+cohesion(a)per-complexity(a)per-summethod(a)per-maxnextinglayer(a)per-coupling(a)per=0.4550+0.3752-0.3333-0.5000-0.6667-0.5000=-1.1698依据可复用性相对值的度量公式计算功能模块a和b的可复用性相对值,结果如表5所示:表5功能模块编号可复用性相对值funcmodulea-1.1698funcmoduleb-0.8302按照可复用性相对值由大到小排列,功能模块b的可复用性相对值>功能模块a的可复用性相对值。因此,功能模块b的可复用性高,容易被复用,相比之下功能模块a可复用性低,复用难度较大。以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 新式程序切片技术的面向商业地产行业高速分组传输网络的可编程数据通信适配器的制造方法
- 新式程序切片技术的面向商业地产行业的网络经纪人服务平台的制作方法
- 新式程序切片技术的面向商业地产行业的数据收集引擎的制作方法
- 新式程序切片技术的面向电商网站行业高速分组传输可编程数据通信适配器的制造方法
- 新式程序切片技术的面向商业地产行业的网页采集与分析数据系统的制作方法
- 新式程序切片技术的面向电商网站行业的经纪人服务平台的制作方法
- 新式程序切片技术的面向商业地产行业的内部通讯系统的制作方法
- 新式程序切片技术的面向电子竞技的游戏可编程数据通信适配器的制造方法
- 新式程序切片技术的面向电子竞技的游戏信息管理处理系统的制作方法
- 新式程序切片技术的面向电子竞技的游戏服务平台的制作方法