基于神经网络与随机前沿分析的碳排放效率预测方法与流程
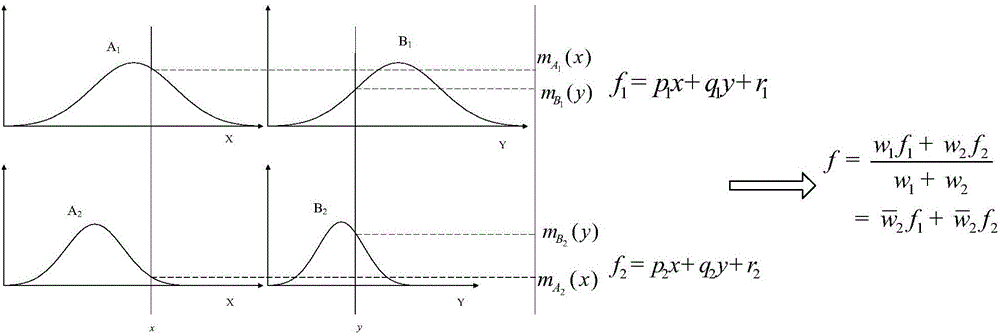
本发明属于区域碳排放预测分析领域,尤其涉及一种神经网络与随机前沿分析的碳排放效率预测方法。
背景技术:
全球气候变化把碳排放推向“风口浪尖”,低碳减排成为各个国家、地区都在考虑的热点问题。为了实现可持续发展,缓解温室效应,关于区域碳排放的研究受到越来越多的关注。
中国目前正处于高速的工业化和城市化进程中,经济发展与能源资源约束的矛盾越来越突出,加上全球温室气体减排带来的巨大外部压力,使得中国必须走低碳发展之路。摸清中国发展过程中碳排放的变化趋势以及影响条件的贡献效率,是探索低碳发展路径的前提,不仅符合全球“低碳化”的发展趋势,也是落实国家提出的温室气体减排目标的必然要求。
可见,我国现阶段存在很大的减排压力,要圆满完成减排任务,首先要明确我国碳排放的变化规律以及增长趋势。传统的碳排放预测主要采用时间序列模型和数学核算的方法,这些方法需要精确地数据和明确的内在关系,但是整个社会的碳排放系统是个复杂的系统,存在太多的不确定性和系统内部复杂非线性关系,这是传统方法无法解决的问题。
技术实现要素:
为了解决现有技术的缺点,本发明的第一目的是提供一种基于神经网络与随机前沿分析的碳排放效率预测方法。
本发明的基于神经网络与随机前沿分析的碳排放效率预测方法,包括:
步骤1:选取碳排放的影响因子GDP和人口数量POP;其中,GDP与POP是相互独立的变量因子;
步骤2:获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
步骤3:利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
步骤4:根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后用技术无效率项的条件期望分别作为GDP和POP分别对区域碳排放量的技术效率。
在所述步骤2中,还包括将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
一般训练组占到总数据的70%以上,本发明利用训练组的数据来构建自适应模糊神经网络模型,当自适应模糊神经网络模型训练完成后,利用验证组的数据来验证自适应模糊神经网络模型的准确性。
所述步骤4中的随机前沿分析模型由Cobb-Douglas生产函数来确定。这样能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
所述步骤2中自适应模糊神经网络模型为基于Sugeno模型的模糊推理系统。
将模糊推理和神经网络有机的结合,其模糊隶属度及模糊规则是通过大量数据的学习完成的,采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解。
本发明基于神经网络与随机前沿分析的碳排放效率预测方法采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时本方法结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
本发明的第二目的是提供了一种基于神经网络与随机前沿分析的碳排放效率预测系统。
本发明的基于神经网络与随机前沿分析的碳排放效率预测系统,包括:
影响因子选取模块,其用于选取碳排放的影响因子GDP和人口数量POP;其中,GDP与POP是相互独立的变量因子;
自适应模糊神经网络模型构建模块,其用于获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
区域碳排放量预测模块,其用于利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
区域碳排放量的技术效率计算模块,其用于根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后分别用GDP和POP的技术无效率项的条件期望作为各自对区域碳排放量的技术效率。
所述自适应模糊神经网络模型构建模块,还用于将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
所述区域碳排放量的技术效率计算模块中的随机前沿分析模型由Cobb-Douglas生产函数来确定。
本发明基于神经网络与随机前沿分析的碳排放效率预测系统采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时该系统结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
本发明的第三目的是提供了另一种基于神经网络与随机前沿分析的碳排放效率预测系统。
该基于神经网络与随机前沿分析的碳排放效率预测系统,包括:
数据采集装置,其用于从数据库内获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;其中,GDP与POP是相互独立的变量因子;
存储器,其用于存储获取的历史GDP和POP数据以及相应时期内区域碳排放量CE;
服务器,其被配置为:
从存储器内获取历史GDP和POP数据以及相对应时期内区域碳排放量CE,再将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后分别用GDP和POP的技术无效率项的条件期望作为各自对区域碳排放量的技术效率。
所述服务器还被配置为将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
所述随机前沿分析模型由Cobb-Douglas生产函数来确定。
本发明的有益效果为:
(1)本发明基于神经网络与随机前沿分析的碳排放效率预测方法采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时本方法结合随机前沿分析方法(SFA)能够进行过去和未来时段内碳排放的效率分析,随机前沿分析方法(SFA)能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
(2)本发明基于神经网络与随机前沿分析的碳排放效率预测系统采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时该系统结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
附图说明
图1是本发明的基于神经网络与随机前沿分析的碳排放效率预测方法流程图;
图2是两输入一阶模糊推理模型;
图3是自适应模糊神经网络模型运算示意图;
图4是随机前沿分析模型的技术效率;
图5是本发明一种基于神经网络与随机前沿分析的碳排放效率预测系统结构示意图;
图6是本发明另一种基于神经网络与随机前沿分析的碳排放效率预测系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
本发明属于区域温室气体排放预测分析领域,特别涉及一种基于自适应神经网络的预测方法实现对区域温室气体排放的预测,以及基于随机前沿分析的区域温室气体排放影响因素的技术效率分析方法。
图1是本发明的一种基于神经网络与随机前沿分析的碳排放效率预测方法流程图。如图1所示的本发明的基于神经网络与随机前沿分析的碳排放效率预测方法,包括:
步骤1:选取碳排放的影响因子GDP和人口数量POP;其中,GDP与POP是相互独立的变量因子。
步骤2:获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
在步骤2中,还包括将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
一般训练组占到总数据的70%以上,本发明利用训练组的数据来构建自适应模糊神经网络模型,当自适应模糊神经网络模型训练完成后,利用验证组的数据来验证自适应模糊神经网络模型的准确性。
步骤2中自适应模糊神经网络模型为基于Sugeno模型的模糊推理系统。
将模糊推理和神经网络有机的结合,其模糊隶属度及模糊规则是通过大量数据的学习完成的,采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解。
在步骤2的具体实施过程中:
人口数量(POP),GDP作为自适应模糊神经网络模型(ANFIS)的输入,输出为区域碳排放量(CE)。ANFIS是一种基于Sugeno模型的模糊推理系统,将模糊推理和神经网络有机的结合,其模糊隶属度及模糊规则是通过大量数据的学习完成的,经典的两输入网络结构如图2所示。ANFIS结构第一层是输入参数和模糊化,x、y是输入变量;Ai、Bi是与该节点相关的模糊变量;O1,i,O2,i分别是模糊集Ai,Bi的隶属函数,其中:
此时i=1,2;
此时i=3,4;
确定了给定输入满足量Ai、Bi的程度。这里Ai、Bi的隶属度可以是任意合适的参数化隶属函数,如高斯隶属函数、钟型隶属函数等。
第二层,计算模糊激励强度wi,计算公式如下:
第三层,计算第i个激励强度与总的激励强度的比值
本层节点进行各条规则适用度的归一化计算,即:计算第i条规则的wi与全部规则适用度之和∑wi的比值。
第四层,该层所有的节点都是自适应的,计算输出O4,i:
其中,pi,qi,ri是模型参数集,称为模糊推理的后件参数,可通过最小二乘法或者似然估计得到;fi为Sugeno型模糊系统的后项(结论)输出函数,当其为线性函数则称为“一阶系统”,若为常量则称为“0阶系统”。
第五层计算第四层输入信号。
构造如图3所示的自适应模糊神经网络模型。
步骤3:利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
在步骤3中,由于GDP与人口数量(POP)是相互独立的变量,利用时间序列模型进行预测GDP和POP,此处为了方便说明采用简单自回归模型来解释。自回归模型为:
Xt,i=aXt-1,i+b;i=1,2
其中,Xt,1为GDP;Xt,2为POP;a和b均为常系数;t为时间序列{1,2,3,….}。
利用预测的未来一定时期内的GDP、POP作为ANFIS的输入,对未来一定时期内区域的碳排放量进行预测。
步骤4:根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后分别用GDP和POP的技术无效率项的条件期望作为各自对区域碳排放量的技术效率。
在步骤4中的随机前沿分析模型由Cobb-Douglas生产函数来确定。这样能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
为了进行温室气体排放的行为分析,利用随机边界分析方法分析GDP和POP对于温室气体排放的技术效率。此发明中技术效率为相同碳排放量下,最理想状况下的GDP、POP分别与实际情况下的GDP、POP的比率,由此来评估区域的减排潜力。
随机前沿分析模型以下简称为SFA模型。
本发明中引入时间的概念后,使SFA模型可以对样本数据进行效率评价。具体模型如下:
Yjt=f(xjt,β)exp(vjt)exp(-ujt),j=1,...N,t=1,...T(1)
在式中,Yjt是第j个决策单元的t时期碳产出(即t时期区域j碳排放量),xjt是第j个决策单元的t时期的全部影响因素(本发明中为GDP、POP),f(xjt,β)为投入产出模型的确定性部分,即不考虑随机扰动的模型,β为模型待估参数,T为时期t的最大值。
将随机扰动εj分为两部分:一部分用于表示统计误差,又被称为随机误差项,用vjt来表示;另一部分用于表示技术的无效率,又被称为非负误差项,该模型中ujt=uj exp(-η(t-T))为非负误差项,η是估计参数,其大小与误差随时间的扰动程度有关。
本发明把碳排放看作是社会生产活动的产出,模型中的生产函数选择以Cobb-Douglas生产函数为例,式(1)可写成下面的线性形式:
其中k表示变量个数,此例中k=1为GDP,k=2为POP。β0,βk为模型待估参数,Yjt为区域j在t时期的碳排放量,xjt为区域j在t时期对碳排放量有较大影响的因子。
本发明模型有如下假设:
(1)随机误差项即vjt是均值为0、方差是的独立正态分布,主要是由不可控因素引起,如自然灾害等。(iid:independent identically distributed独立同分布)
(2)非负误差项其中,ujt是均值为0、方差是的独立正态分布,取截断正态分布(N+表示截去<0的部分),代表着生产效率,此例中为碳排放的效率,且有ujt与vjt相互独立。
(3)ujt、vjt与变量xjt相互独立。
本发明中SFA技术效率为:
所以,在ut的分布已知的情况下,可以计算出技术效率的平均值TEt=E[exp(-ujt)],即t时期GDP、POP对于碳排放(CE)的技术效率,基于此可以分析未来碳排放的趋势,特别是受GDP和POP影响的变化趋势,为政策的制定提供理论基础。
SFA方法通过极大似然法估计出各个参数值,然后用技术无效率项的条件期望作为技术效率值。SFA方法充分利用了每个样本的信息并且计算结果稳定,受特殊点影响较小,具有可比性强、可靠性高的优点。
如图4所示,以Cobb-Douglas生产函数为例,显示了SFA模型技术效率测度的优点(为了方便说明采用了单投入,即x)。图中,由Cobb-Douglas生产函数确定的生产前沿面为:
lnYt=β0+β1lnxt
其中,Yt为t时期的产出,该发明中为碳排放量;xt为t时期的投入,该发明为GDP或者POP;β0,β1为模型估计参数,可通过最小二乘法、极大似然估计等方法得到。
而基于这个确定生产前沿面的随机前沿模型为:lnYt=β0+β1lnxt+vt-ut,也可以表示为:Yt=exp(β0+β1lnxt+vt-ut)。其中,vt为随机误差项,ut为非负误差项。
其中,A、B两点分别表示随机影响为正或为负的情况:
A点表示随机影响为正,则随机误差项vA为正数,生产前沿面上移到:样本的技术效率为B点表示随机影响为负,则随机误差项vB为负数,生产前沿面下移到样本的技术效率为
本发明基于神经网络与随机前沿分析的碳排放效率预测方法采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时本方法结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
图5是本发明的一种基于神经网络与随机前沿分析的碳排放效率预测系统结构示意图。如图5所示的本发明的基于神经网络与随机前沿分析的碳排放效率预测系统,包括:
影响因子选取模块,其用于选取碳排放的影响因子GDP和人口数量POP;其中,GDP与POP是相互独立的变量因子;
自适应模糊神经网络模型构建模块,其用于获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
区域碳排放量预测模块,其用于利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
区域碳排放量的技术效率计算模块,其用于根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后分别用GDP和POP的技术无效率项的条件期望作为各自对区域碳排放量的技术效率。
其中,自适应模糊神经网络模型构建模块,还用于将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
区域碳排放量的技术效率计算模块中的随机前沿分析模型由Cobb-Douglas生产函数来确定。
本发明基于神经网络与随机前沿分析的碳排放效率预测系统采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时该系统结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
图6是本发明的一种基于神经网络与随机前沿分析的碳排放效率预测系统结构示意图。如图6所示的本发明的基于神经网络与随机前沿分析的碳排放效率预测系统,包括:
数据采集装置,其用于从数据库内获取历史GDP和POP数据以及相对应时期内区域碳排放量CE;其中,GDP与POP是相互独立的变量因子;
存储器,其用于存储获取的历史GDP和POP数据以及相应时期内区域碳排放量CE;
服务器,其被配置为:
从存储器内获取历史GDP和POP数据以及相对应时期内区域碳排放量CE,再将历史GDP和POP数据作为输入,相对应时期内区域碳排放量CE作为输出来构建自适应模糊神经网络模型;
利用获取的历史GDP和POP数据及时间序列模型来预测未来一定时期内的GDP和POP,将预测的GDP和POP输入至自适应模糊神经网络模型中,预测得到未来相应时期内的区域碳排放量;
根据预测的未来一定时期内的GDP和POP以及区域碳排放量,构建随机前沿分析模型,通过极大似然法估计出随机前沿分析模型各个参数值,然后分别用GDP和POP的技术无效率项的条件期望作为各自对区域碳排放量的技术效率。
其中,数据采集装置和存储器均为现有结构。
服务器还被配置为将获取的历史GDP和POP数据以及相应时期内区域碳排放量CE分成两组,一组作为训练组,另一组作为验证组。
随机前沿分析模型由Cobb-Douglas生产函数来确定。
本发明基于神经网络与随机前沿分析的碳排放效率预测系统采用自适应神经网络来预测未来区域碳排放量,能够避开系统内的复杂性和不确定性,通过自主学习不断修正,能够得到最优解;同时该系统结合SFA能够进行过去和未来时段内碳排放的效率分析,SFA能够很好地处理数据的随机性,能够对过去的技术效率进行评估和对未来进行预测,并且分析结果能够作为研究碳排放行为的基础,为减排政策的制定提供理论依据。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random AccessMemory,RAM)等。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!