一种基于深度学习的多视图外观专利图像检索方法与流程
本发明涉及一种图像检索领域,尤其是一种基于深度学习的多视图外观专利图像检索方法。
技术背景
在我国深入实施创新驱动发展战略大背景下,我省提出加快优势传统行业升级换代。专利技术是引导技术产业发展的引擎,专利包含世界全部科技信息的90%-95%,且技术信息公开较其他载体早1~2年。外观设计专利已成为保护企业知识产权、维护自身权益、保护发明创造重要途径。
目前基于外观专利图像检索主要有两大类,第一类是基于文字检索,这是最为常用的一类方法,存在的主要缺陷是无法用合适的文字来对图像进行标注,也即是所谓的一幅图画抵千言。这种检索的结果导致无法检索的结果偏差很大。
第二种方法是采用以图搜图的方法,传统使用的方法是通过如Gabor滤波器、SIFT等所谓“最优特征提取算法”来提取图像的特征,如形状、纹理、颜色等,进一步采用特征之间的距离来进行相似度比较。这些方法中将外观设计专利图像的各个视图作为相互独立的图像来进行特征处理,导致的检索准确率低。
外观设计专利图像通常采用多视图(如4视图或者6视图)来表示发明对象的外观。外观专利图像的多视图是有机的整体,因此,设计有机使用这些视图的外观专利图像的检索是本技术领域中需要解决的一个问题。
技术实现要素:
针对现有技术中的不足,本发明提供一种基于深度学习的多视图外观专利图像检索的方法,构建多视图卷积神经网络深度学习架构,利用预训练的网络参数作为学习网络的初始权值,同时将图像按照视图来分通道特征提取,按照视图的空间位置关系进行池化融合,并进行后续的特征提取与分类。该方法大大提高了图像检索结果的准确性,解决外观专利图像检索过程多视图之间的特征缺乏有机融合的问题。
按照本发明所提供的设计方案,一种基于深度学习的多视图外观专利图像检索方法,具体包含以下步骤:
步骤1.外观专利图像预处理,将外观专利图像尺度归一化,图像维度归一化,同时将外观专利图像的各个视图进行区分分类;将外观专利图像数据集分为测试数据集和训练数据集两部分。
步骤2.构造多视图深度学习网络,按照七视图七路分支为每一类视图构造包含3层卷积的网络,在之后采用池化进行融合,然后为3层全连接,最后通过Softmax进行分类输出,利用预训练的网络参数作为网络的初始权重。
步骤3.图像特征提取及分类,利用训练样本对多视图深度卷积神经网络进行训练,对网络参数权重进行调整,得到训练网络后的多视图深度学习网络模型。将测试集和训练级的图像通过网络模型,计算得到图像的特征表示及其分类。
步骤4.检索结果相似度排序输出,将待检索的图像经过图像预处理之后,经过深度学习网络,提取出图像的特征与类别,与同类的图像特征之间的进行距离比较,按照距离的数值从小到大排序反馈输出,并将对应的图像输出。
本发明的有益效果:本发明针对现有外观专利图像检索缺乏对专利图的多维视图的有机应用,利用深度卷积神经网络构造多视图的卷积神经网络,将对应的视图按照视图的通路进行卷积处理,考虑视图的空间位置关系的基础上进行池化融合处理,挖掘了视图之间的内在联系,大大提高了图像检索的准确性。
附图说明
图1.本发明的流程示意图
图2.本发明实施例提供的流程图。
具体实施方式
为了使本发明的目的、技术方案即优点更加清楚明白,以下结合附图及实施例,对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例一,参考图1所示,一种基于深度学习的多视图外观专利图像检索方法,其特征在于,包括:
在步骤101中,对外观专利图像预处理,将外观专利图像尺度归一化,图像维度归一化,同时将外观专利图像的各个视图进行区分分类;将外观专利图像数据集分为测试数据集和训练数据集两部分。
上述,步骤101中,图像尺度归一化是将图像调整为相同的尺度。
优选地,尺度为128*128。
上述,步骤101中,图像维度归一化是将二维的灰度图像变为三维的类似RGB格式的图像。
优选地,将增加新的图像的R、G、B通道对应像素的取值与灰度图像对应像素取值相同。
在步骤102中,构造多视图深度学习网络,按照七视图七路分支为每一类视图构造包含3层卷积的网络,在之后采用池化进行融合,然后为3层全连接,最后通过Softmax进行分类输出,利用预训练的网络参数作为网络的初始权重。
上述,步骤102中,七视图七路分支的分别为主视图,左视图、右视图、俯视图、仰视图、后视图以及立体视图分支。
上述,步骤102中,预训练的网络参数采用的是基于ImageNet训练的到的网络参数。
优选地,选择VGG-M模型作为网络参数。
上述,步骤102中,七路网络分支的初始参数和网络架构相同。
上述,步骤102中,采用池化进行融合采用基于pad的最大值方式融合。
优选地,融合的规则按照视图空间位置的相邻性进行融合。
优选地,pad的尺寸为2*2。
在步骤103中,图像特征提取及分类,利用训练样本对多视图深度学习网络进行训练,对网络参数权重进行调整,得到训练网络后的多视图深度学习网络模型。将测试集和训练级的图像通过网络模型,计算得到图像的特征表示及其分类。
上述,步骤103中,图像的特征是在Softmax之前的ReLU之后输出的多维图像特征xi,在Softmax之后得到图像的类别Ck。
进一步,对于多维图像特征xi进行压缩编码。
在步骤104中,检索结果相似度排序输出,将待检索的图像经过图像预处理之后,经过深度学习网络,提取出图像的特征与类别,与同类的图像特征之间的进行距离比较,按照距离的数值从小到大排序反馈输出,并将对应的图像输出。
上述,步骤104中,待检索的图像通过深度学习网络得到的类别为Cn,则后续的相似性比较时仅仅考虑Cn类别图像先前计算存储的多维图像特征。采用的距离可以采用欧式距离、马氏距离等。
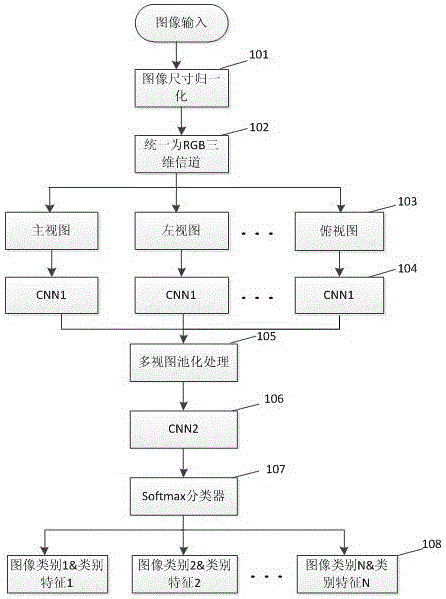
实施例二:参考图2所示,一种基于深度学习的多视图外观专利图像检索方法,其特征在于,包括:
在初始图像输入,对于网络参数调整训练过程,每次输入的图像为多幅外观专利的多视图。在检索时,可以输入至少一幅待检索图像。
在步骤201中,图像尺寸归一化,将输入的图像尺寸统一,方便后续的特征分析与提取。
在步骤202中,统一为RGB三信道,对输入的图像为RGB的图像不做处理;对灰度图像,构建一幅新图像,新图像的R、G、B通道对应像素的取值与灰度图像对应像素取值相同。
步骤203中,视图分类,即将输入的图像按照其视图标签分别输入到对应的通道中。
在步骤204中,CNN1,将图像采用3层神经卷积网络对图像的特征进行提取。在初始是,各路通道的CNN1网络参数相同,根据训练之后,各路通道的网络参数可能出现不一致。
在步骤205中,多视图池化处理,将各路视图通道按照其空间位置采用2*2的Pad极大值方式进行池化融合。
在步骤205中,CNN2,采用3层全连接的深度卷积方式提取图像特征,CNN2的最后一层的激活函数采用ReLU,在其之后输出图像的高层特征,将该特征与图像名称进行关联存储。
在步骤207中,Softmax分类器,将步骤205的特征进行分类,获得图像的类别。
在步骤208中,将图像的类别与步骤205中得到的特性进一步关联存储。在后续的图像检索时,首先判断图像的类别,然后,在该类别下比较图像特征的距离,按照计算得到的距离,从小到大输出指定的图像数目。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!