标准差的分布式计算方法与流程
本发明涉及标准差计算技术领域,特别涉及一种标准差的分布式计算方法。
背景技术:
标准差被定义为:总体各单位标准值与其平均数离差平方的算术平均数的平方根。在统计学中,标准差常常用来度量一组数值的差异大小和分散程度,标准差越大,代表大部分数值和其平均值之间差异越大,例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。现有技术中主要有以下几种获得标准差的方法:
一、标准差的抽样计算方法,即对总体数据抽取一定的样本,并对样本进行样本标准差的计算,用以代替总体的标准差。
但是抽样方法存在着抽样偏差,尤其是在大数据的环境下,这种偏差会更加明显。
二、总体标准差的传统计算方法:
根据标准差的定义,标准差是各个数据分别与均值之差的平方的和的平均数的平方根,其中
均值μ的计算公式:
标准差σ的计算公式:
由公式(2)可以推导出公式(3),其推倒过程省略;
在大数据的环境下,传统标准差计算方法的计算量非常大,操作起来不现实。
三、标准差的迭代计算方法:
当有新的数据进入时,标准差的传统计算方法要重新调用原来的所有数据值和新增数据一起来计算新的标准差,针对这一问题,人们提出了标准差的迭代计算方法:
假设有一个时间序列的数据:
x1,x2,x3,x4,...,xn,xn+1,...
在时间点n时,得到数据xn,并在时间点n+1,得到数据xn+1。每当一个新的数据流入时,就要在一个长为n的时间窗口内计算包括该新数据在内的n个数的标准差。
其关键步骤如下:首先计算
然后,通过迭代的方式计算出新增一个数据时总体的和Xn+1及标准差STD.Sn+1:
Xn+1=Xn+xn+1-x1 (6)
公式(6)迭代地计算一个长为n的窗口内数据的总和,公式(7)迭代地计算一个长为n的窗口内数据的标准差。
通过把分母(n-1)更换为n,得到总体标准差的迭代计算方法:
针对流数据的总体标准差的迭代计算方法,可以对新增数据进行简便计算,但当有新的数据进入时,仍需重新对所有数据进行计算,造成计算冗余。
三、标准差的增量计算方法
为了解决传统标准差计算量大的技术问题,人们还提出了标准差的增量计算方法:
该方法首先在公式(1)的基础上推倒出以下两个关系式:
xn-μn-1=n(μn-μn-1) (9)
又由于:
因而,结合公式(9)、(10)推倒出:
Sn=Sn-1+(xn-μn-1)(xn-μn) (12)
继而得到:
标准差增量计算方法只需要根据已往总体数据的标准差和方差及单个新增数据,便可计算出新总体的标准差。但当面对分布式存储的大数据时,需要将其他分布式存储的局部总体中的每个值作为后续增量,逐个代入计算,而不能直接利用各个局部总体已有的均值和标准差,计算效率依旧不高。
综上可知,根据标准差定义的传统计算标准差的方法需要将每个数据值的离均差平方算出,当数据量很多时计算量大,当有新的数据进入时,就要重新计算总体的均值及新的离均差平方和,故其计算存在冗余。现有的标准差的增量计算方法虽不用访问所有以前的输入数据从而利用了已知的条件,但如果之后输入的数据数量比较大时,要将之后进入的每个数据值逐一进行增量计算,则其计算量也不能得到明显降低。
技术实现要素:
有鉴于此,本发明的目的是提供一种标准差的分布式计算方法,只要知道各局部总体的均值、标准差及个数,就能计算出总体的标准差,从而解决现有标准差计算方法计算量大的技术问题。
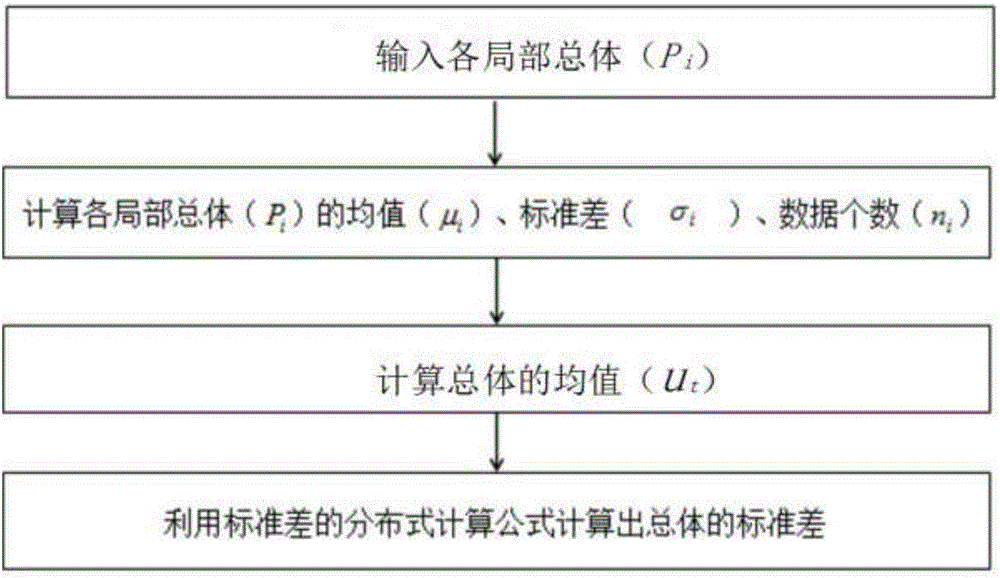
本发明标准差的分布式计算方法,包括以下步骤:
1)输入各个局部总体Pi;
2)计算各局部总体Pi的均值μi、标准差σi、以及局部总体的数据个数ni;
3)根据公式计算出输入总体的均值;
4)利用公式计算出输入总体的标准差。
本发明的有益效果:
本发明标准差的分布式计算方法,只要知道各局部数据的均值、标准差及个数,就能计算出总体数据的标准差;这种方法使计算量显著减少,且由于不用频繁读取各分散储存的所有数据,节省了大量的查询访问时间,实际计算效率会有更大的提高。
附图说明
图1为本发明标准差的分布式计算方法的流程图;
图2为本发明标准差的分布式计算方法的计算模型图。
具体实施方式
下面结合附图和实施例对本发明作进一步描述。
本实施例标准差的分布式计算方法,包括以下步骤:
1)输入各个局部总体Pi;
2)计算各局部总体Pi的均值μi、标准差σi、以及局部总体的数据个数ni;
3)根据公式计算出输入总体的均值;
4)利用公式计算出输入总体的标准差。各局部总体的标准差σi可采用背景技术中所述的标准差的传统计算方法或者标准差的增量计算方法获得。
下面通过具体实例将标准差的分布式计算方法与标准差的传统计算方法、标准差的迭代计算方法、以及标准差的增量计算方法在计算的复杂性上进行对比,以证明本发明标准差的分布式计算方法的优越性。
先输入各局部总体:
局部总体P1:{4,16,14,13,16,-7,-3,16,10,-19,1,-6,9,-4,17,12,3,8,18,9}
局部总体P2:{-3,-12,3,4,7,13,-15,16,-15,19}
局部总体P3:{-18,-7,17,-18,-6,-13,-2,-18,-2,-12,10,0,10,9,20}
计算输入的各局部总体Pi的均值μi、标准差σi、数据个数ni为:
各局部总体Pi的均值μi分别为:μ1=6.35,μ2=1.7,μ3=-2
各局部总体Pi的标准差σi分别为:σ1=9.763580286,σ2=11.97539143,σ3=12.35043859
各局部总体Pi的数据个数ni分别为:n1=20,n2=10,n3=15。
比较一:通过标准差的传统计算方法计算局部总体P1、局部总体P2和局部总体P3这三者总体的标准差
总体的数据总个数为:nt=n1+n2+n3=45,此步骤包括2个加法。
计算总体的均值:
此步骤包括44个加法,1个除法。
计算总体的标准差:
此步骤需要进行45个乘法或平方,1个除法,44个加法,45个减法,1个开方运算。
可知,用传统的计算方法计算标准差时共需要45个乘法,2个除法,90个加法,45个减法,1个开方运算。
比较二:通过标准差的迭代计算方法计算局部总体P1、局部总体P2和局部总体P3这三者总体的标准差
已知局部总体P1的标准差σ1=9.763580286,设数据窗口的长度为数据量最多的数据块的长度20。
根据公式(4)计算出前20个数的和:
此步骤包括19个加法。
根据公式(6)计算新增第21个数据后的后n个数和:
X21=X20+x21-x1=127+(-3)-4=120
此步骤包括1个加法,1个减法。
根据公式(8)计算出总体的标准差:
此步骤共包括3个乘法或平方,2个除法,3个加法,2个减法,1个开方。
当新增1个数据值时,迭代的方法共需要进行3个乘法,2个除法,23个加法,3个减法和1个开方运算。
将后面进入的全部数据依次按以上步骤进行计算,得出总体的标准差为σ=13.37310734。
在已知局部总体P1的均值及标准差的情况下,用迭代的计算方法计算总体的标准差共需要进行75个乘法,50个除法,594个加法,75个减法,25个开方运算。
此算法的时间复杂度与数据块中的数据量相关,为O(n-a),n为总体的数据个数,常量a为第一个数据块中的数据个数。只新增一个数据时,该算法相比传统的计算方法具有优势,但是当新增数据量很大时,计算量的与n正比例关系,甚至超过了传统方法的计算量。另外,此方法的计算结果与正确结果之间存在差异,只能作为近似计算方法。
比较三:通过标准差的增量计算方法计算局部总体P1、局部总体P2和局部总体P3这三者总体的标准差
已知局部总体P1的均值μ1=6.35,标准差σ1=9.763580286,数据个数n1=20,
根据公式(11),计算出局部总体P1的离均差平方和的值
此步骤包括2个乘法。
计算新增第21个数据的平均值
此步骤需要进行2个乘法,1个除法,2个加法运算。
根据公式(12),计算出新增第21个数据以后的离均差平方和
S21=S20+((-3)-μ1)((-3)-μ21)=1989.809524
此步骤包括1个乘法,1个加法,2个减法。
根据公式(13),计算出:
此步骤包括1个除法,1个开方。
当新增1个数据值时,共包括5个乘法,2个除法,3个加法,2个减法,1个开方运算。
将后面进入的全部数据依次带入以上步骤进行计算,得出总体的标准差σ=11.77115118。
在已知局部总体P1的均值及标准差的情况下,用增量的计算方法计算标准差共需要计算125个乘法,50个除法,75个加法,50个减法,25个开方。
此方法计算出的结果与准确结果无误差。当有单个新的数据进入时,能充分利用已知条件,减少计算冗余。但可以看到,当新增的数据量增大时,计算量呈倍数增加,可能会超过传统计算所需的计算量,但比迭代的计算方法所需的计算量要少。标准差的增量计算算法的时间复杂度与总体中的数据量相关,为O(n-a),n为总体的数据个数量,常量a为第一个局部总体中的数据个数。
比较四:通过标准差的分布式计算方法计算局部总体P1、局部总体P2和局部总体P3这三者总体的标准差
根据公式:
计算出整体的均值μt,为此步骤包括3个乘法,1个除法,4个加法。
利用分布式标准差算法计算总体的标准差:
此步骤包括12个乘法,9个除法,14个加法,9个减法,1个开方。
将标准差的分布计算方法带入到上述数据中计算,总共需要计算15个乘法,10个除法,18个加法,9个减法,1个开方。
此算法计算出的结果准确无误。当知道每个局部总体的均值和标准差时,能简便地计算出总体的标准差,充分地利用了每个数据块的已知条件,使计算效率得到极大提高。该方法的计算复杂度与数据个数无关,只与局部总体的个数有关。此算法的时间复杂度为O(l),常数l为局部总体的个数。
从上述各种标准差计算方法所需要的计算步骤可知,本发明标准差的增量计算方法使计算量显著减少,优势明显,且由于不用频繁读取各分散储存的所有数据,节省了大量的查询访问时间,实际计算效率会有更大的提高。
下面是将本实施例标准差的分布式计算方法用于股市稳定性分析的实例。
股票价格的波动是股票市场风险的表现,因此股票市场风险分析就是对股票市场价格波动进行分析。波动性代表了未来价格取值的不确定性,这种不确定性一般用方差或标准差来刻画。表1是中国和美国部分时段的股票统计指标。
表1:上证及标准普尔指数
通过计算可以得到:
上证指数业绩期望值
=(1144.08+1686.75+4328.92+2912.42+2736.50+2795.42+2639.19+2211.11+2182.53+2279.74)/10≈2491.6660
上证波动率期望值≈0.3323
标准普尔业绩期望值≈1356.2570
标准普尔波动率期望值≈0.17118
而标准差的计算公式则根据背景技术中的公式(12)计算:
上证指数的业绩标准差≈800.5983
上证波动率标准差≈0.1032
标准普尔指数业绩标准差≈267.4948
标准普尔波动率标准差≈0.0736
因为标准差是绝对值,不能通过标准差对中美直接进行对比,而变异系数可以直接比较。计算可得:
上证业绩变异系数≈800.5983/2491.6660≈0.3213
上证波动率变异系数≈0.1032/0.3323≈0.3105
标准普尔业绩变异系数≈267.4948/1356.2570≈0.1972
标准普尔波动率变异系数≈0.0736/0.17118≈0.4301
通过比较可以看出上证波动率变异系数要大于标准普尔波动率变异系数,说明长期来讲中国股市稳定性相对较差,还是一个不太成熟的股票市场。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!