一种面向RGBD数据流的相机位姿估计方法与流程
本发明属于计算机视觉与计算机图形图像处理领域,具体地说是一种面向RGBD数据流的相机实时位姿估计方法,该方法可在输入数据分辨率较低、深度数据存在空洞和噪声、设备运算能力较低的情况下实时地估计相机位姿,对于SLAM和实时三维重建技术的研究有着重要意义。
背景技术:
随着深度传感器的普及和三维重建技术的发展,近年来基于深度数据的三维模型重建的研究正在兴起。与传统基于RGB数据的三维重建相比,深度数据提供了场景的三维信息,极大地提高了三维重建的可行性和精度。而相机位姿的估计在三维重建等相关应用场景中起到了至关重要的作用。
目前在三维重建中相机位姿估计方法可以分为以下三类:一是基于RGB图像的方法,这类方法大多利用RGB图像进行特征点匹配,然后估计两幅图像的变换矩阵,由于没有深度信息,这类方法估计的变换矩阵精度较低;二是基于深度图像的方法,或是基于RGBD的方法,这类方法借助深度数据提供的三维信息,进行三维点云配准,精度相对较高;三是基于惯性传感器的方法,这类方法利用加速度计、电子罗盘和陀螺仪等惯性导航设备,有的也结合视觉估计相机位姿,鲁棒性和精度一般较高,但对硬件设备的需求较高。
上述相机位姿估计方法有的耗时较大,比如特征点的提取,能量方程的优化等步骤,有的对输入数据的质量要求较高,如光照一致、分辨率较高等,通常难以在移动设备等运算效率较低的平台上达到实时性的要求。
技术实现要素:
为克服上述缺点,本发明的目的在于根据RGBD数据流的特点,结合三维重建的需求,提供一种相机位姿实时估计方法,其能够在现有的移动设备上实时运行,并能够在输入数据分辨率较低时也能得到良好的结果。
为了达到上述目的,本发明提出了一种面向RGBD数据流的相机位姿实时估计方法,其特征在于包括以下步骤:
步骤(1)、对原始RGBD数据流中的深度数据作预处理操作,得到平滑的深度数据;同时对原始RGBD数据流中的RGB图像去模糊;
步骤(2)、对平滑的深度数据,根据相机内部参数,将所述深度数据中的每一个像素点的深度转化为相机坐标系下的三维坐标;利用相邻像素的三维坐标值计算每一个像素对应的三维点云的法向量;由所述三维坐标和法向量构成三维点云映射图;
步骤(3)、对于当前帧和上一帧的两组三维点云映射图,利用当前估计的相机位姿和上一帧的相机位姿,将当前帧三维点云映射图中每一个像素的三维点云坐标P1转化到上一帧相机坐标系下的坐标,再利用相机内部参数投影到像素坐标系下,获得上一帧三维点云映射图中对应像素坐标的点云数据P2;将P1与P2分别计算在世界坐标系下的三维坐标和法向量以及颜色值,其中三维坐标的距离、法向量的夹角及颜色的差值均在设定阈值范围内的对应点对视为匹配;
步骤(4)、将两帧三维点云映射图之间的相机变换矩阵表示为六个参数,根据点到平面的距离误差函数,利用步骤(3)所得的对应点对构造系数矩阵,求解所述六个参数的线性方程组,将所述六个参数转化为当前估计的两帧三维点云映射图之间的相机变换矩阵;
步骤(5)、根据步骤(4)所得的两帧三维点云映射图之间的相机变换矩阵,及上一帧的相机位姿,估计当前帧的相机位姿,再将估计的当前相机位姿代回到步骤(3)中,迭代步骤(3)~(4)直到设定次数或误差在设定范围内。
所述(1)中,预处理操作包括阈值分割和滤波去噪,所述滤波去噪采用快速双边滤波,对带有噪声的深度数据进行滤波去噪;对RGBD数据流中带有运动模糊的RGB图像通过维纳滤波进行去模糊操作。
所述(5)中,迭代步骤(3)~(4)的次数为6次。
本发明的原理在于:首先结合深度相机采集精度的分布特征,对深度图像进行阈值分割,保留深度值在一定范围内的像素点。采用快速双边滤波,对带有噪声的深度数据进行滤波去噪。对预处理后的深度图像,根据相机内部参数计算每一个像素对应的相机坐标系下的三维坐标,构成初步的三维点云映射图。基于相邻像素的点云在三维坐标系下也相邻的假设,利用相邻像素的三维坐标的差值,计算每一个像素对应的点云法向量,构造三维点云映射图。为了找到两幅三维点云映射图的对应点,首先利用当前估计的相机位姿和上一帧的相机位姿,将当前帧每一个像素的三维点云坐标转化到上一帧相机坐标系下的坐标,再利用相机内部参数投影到像素坐标系下,获得上一帧三维点云映射图中对应像素坐标的数据,法向量的夹角、三维坐标的距离以及灰度值的差值在一定阈值范围内的对应点视为匹配。为了得到两帧数据的相机变换矩阵,根据点到平面的距离误差函数,求解关于相机位姿六个参数的线性方程组,然后利用上一帧的相机位姿估计当前的相机位姿。迭代对应点匹配和误差距离函数优化的过程优化当前帧的相机位姿。
本发明中深入分析了三维重建中对相机位姿估计的需求,与现有的一般针对三维重建的相机位姿估计方法相比的优点在于:
(1)对低分辨率的深度数据能够得到比较精确的相机位姿估计结果。现有的相机位姿估计算法大多针对640*480分辨率的深度数据,本发明在输入低分辨率的深度数据(如320*240)时,结合了颜色信息,弥补了深度数据分辨率低的缺点,提高了相机位姿估计的精确度。
(2)考虑移动设备等计算能力有限的应用场合,能够在现有的移动平台下使相机位姿估计达到实时。本发明将三维点云的配准转化为二维的点云映射图的配准,大大减小了计算量,并且所有步骤均可在GPU下加速执行,能够空出CPU的资源用于其他模块。经过实验,在移动设备上相机位姿估计的帧率能够达到15fps,而现有的大多数位姿估计算法只能在PC机上达到实时。
附图说明
图1为本发明中输入低分辨率(320*240)RGBD数据时,相机位姿估计在不同迭代次数下的相对误差值(以1000帧数据为例);
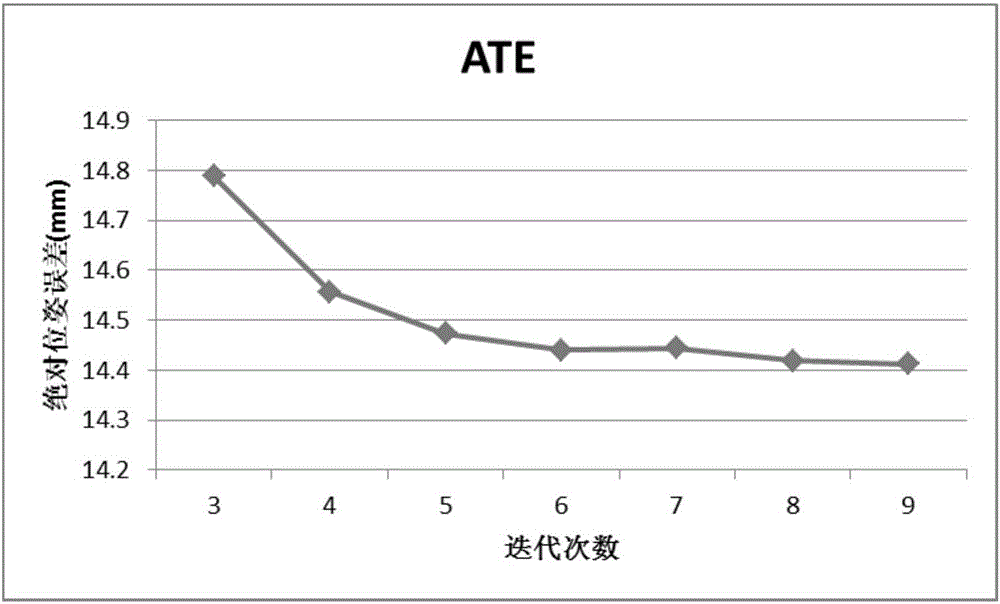
图2为本发明中输入低分辨率(320*240)RGBD数据时,相机位姿估计在不同迭代次数下的绝对误差值(以1000帧数据为例);
图3为本发明中移动平台下输入低分辨率(320*240)RGBD数据时,相机位姿估计算法在各个不同阶段的平均耗时情况,每一步都在GPU上执行,步骤(3),(4)以迭代6次耗时为例;
图4为本发明的一种面向RGBD数据流的相机位姿估计方法的原理图。
具体实施方式
结合附图对本发明实施例进行详细的描述。
如图4所示,本发明的实施过程主要分成四个步骤:深度数据预处理、构建三维点云映射图、对应点匹配、优化距离误差。
步骤一、深度数据预处理
其主要步骤为:
(1)对于给定的输入RGBD(彩色+深度)数据流中的深度数据,根据深度相机的误差范围设定阈值wmin,wmax,深度值在wmin与wmax之间的点视为可信值,只保留阈值范围内的深度数据I。
(2)对深度数据的每一个像素做快速双边滤波,具体如下:
其中pj为像素pi的邻域内的像素,s为邻域内有效像素的个数,σ1与σ2为预设参数,dpi为像素pi滤波后的深度值。
(3)对给定的输入RGBD数据流中的RGB数据作维纳滤波去模糊。
步骤二、构建三维点云映射图
其主要步骤为:
(1)根据相机内部参数,对滤波后的深度数据图中的每一个像素,计算其在相机坐标系下的三维坐标:
p(x,y,z)=K*(u,v,d)T (2)
其中,p为映射后的三维点坐标,u,v为滤波后的深度数据图中的像素坐标,d为对应的深度值,K为深度相机的内参矩阵。
(2)对每一个像素在相机坐标系下的三维坐标,根据其相邻像素的三维坐标,计算其法向量:
n(u,v)=normalize(cross(p(u+1,v)-p(u-1,v),p(u,v+1)-p(u,v-1))) (3)
其中,normalize为向量的单位化,cross为向量的叉乘运算,p(u,v)为像素坐标u,v处的三维点坐标。
最终的三维点云映射图是一组二维数据,每一个像素存储对应三维点云在相机坐标系下的三维点坐标p以及对应的法向量n。
步骤三、对应点匹配
假设当前为第i帧,那么按照如下所述的方式匹配第i帧与第i-1帧数据的对应点对。
(1)根据当前估计的相机位姿矩阵,将第i帧的三维点云映射图中的每一个像素在世界坐标系下的三维坐标和法向量。具体对每一个像素作如下操作:
其中,表示第i帧数据第k次迭代估计的相机位姿,p_gi和n_gi分别为第i帧三维点云映射图对应像素的三维坐标和法向量。
(2)计算每一个像素上由式(4)计算所得的三维坐标在上一帧坐标系下对应的像素:
sp=K-1*(Ti-1-1*p_gi) (5)
其中,Ti-1表示上一帧的相机位姿,K为深度相机的内参矩阵,sp为三维点向上一帧像素坐标系投影得到的像素坐标。
(3)根据第i-1帧的相机位姿矩阵按照式(4)计算第i-1帧三维点云映射图在像素sp处世界坐标系下的点云坐标p_gi-1和法向量n_gi-1。
(4)按照如下所述的方式计算三维坐标和法向量的差值筛选对应点:
其中,ci为对应像素的RGB值,cross为向量的叉乘运算。dist_p表示对应点三维坐标的距离,dist_n表示对应点法向量的夹角正弦值,dist_c表示对应点颜色的差值。dist_p、dist_n、dist_c均在一定阈值范围内的点对视为第i帧与第i-1帧的对应点对。
步骤四、优化距离误差
其主要步骤为:
(1)对每一组对应点对,计算一个六维系数向量具体为:
其中,cross为向量的叉乘运算,表示系数向量的前三维,表示系数向量的后三维。
(2)对每一组对应点对,构造其系数矩阵和目标向量
其中,dot为向量的点乘运算,A为线性方程组的系数矩阵,为目标向量。
(3)将所有对应点对的系数矩阵和目标向量相加,求解变换矩阵系数:
其中,是代表相机变换矩阵的六个参数,前三维代表旋转参数,后三维代表平移参数。
(4)根据上述所得的六个参数构造变换矩阵:
其中,Tinc为当前估计的第i-1帧与第i帧点云向量映射图的相机变换矩阵,是变换矩阵的六个参数。
步骤五、迭代
如式(11)所述更新第i帧估计的相机位姿矩阵,迭代步骤三与步骤四若干次,最终得到第i帧的相机位姿矩阵:
Tk=Tinc·Tk-1 (11)
其中,Tk表示第k次迭代时估计的相机位姿矩阵。
如图1所示,为本发明在不同迭代次数下的相对位姿误差RPE,该指标衡量局部相机位姿的漂移程度,输入为320*240的深度图像和640*480的RGB图像,数据长度为1000帧,轨迹长度大约20m,可以发现迭代步骤(3)(4)6次以上时,RPE基本保持稳定,即基本收敛。
如图2所示,为本发明在不同迭代次数下的绝对位姿误差ATE,该指标衡量相机轨迹的全局误差,输入为320*240的深度图像和640*480的RGB图像,数据长度为1000帧,轨迹长度大约20m,可以发现迭代步骤(3)(4)6次以上时,ATE基本保持稳定,即基本收敛。
如图3所示,为本发明在步骤(3)(4)迭代次数为6时,各步骤的耗时情况,实验在移动设备iPad Air2上进行,可以发现本发明相机位姿估计的平均帧耗时约为66ms,已达到实时,其中步骤(3)(4)耗时最大。
总之,本发明与现有技术相比,能够适应输入深度数据分辨率较低的场景,并且具有较高的时间效率,能够在移动设备上实时运行。
- 还没有人留言评论。精彩留言会获得点赞!