文档结构化方法和设备与流程
本发明涉及一种文档管理技术,尤其是涉及一种文档结构化方法和设备。
背景技术:
目前上海计量中心的结构化文档及非结构化文档,存放分散,随着计量业务的发展,各种计量标准、技术文件越来越多,没有一种集中存放及快速搜索的软件,已经无法支撑计量业务的正常发展及无法满足国家电网推动信息化产业、快速、高效的工作理念。长期以来,上海计量中心的结构化和非结构化数据,都是存储在各应用人员各自电脑或是存储设备中,无法共享资料,对于新发布的文件、规则制度,只能通过邮件或是硬盘共享的方式提供给他人使用,这种方式往往会造成安全保密度低,寻找一份文档繁琐,甚至出现文档丢失的情况,而原先旧文档服务器,搜索效率慢,树形结构不合理,且无备份就权限控制的功能,对于用户重要机密文件无法安全、可靠的保存,相关人员也无意愿继续使用。
随着互联网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找自己所需的信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题。搜索引擎是指互联网上专门提供检索服务的一类网站,这些站点的服务器通过网络搜索软件或网络登录等方式,将Intenet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库,从而对用户提出的各种检索作出响应,提供用户所需的信息或相关指针。用户的检索途径主要包括自由词全文检索、关键词检索、分类检索及其他特殊信息的检索。而我们将这种技术运设计开发出一套符合计量标准化信息管理的系统,使得计量中心内部的结构化和非结构化数据能够集中存储,同时能够快速响应并找到目标文件。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种文档结构化方法和设备。
本发明的目的可以通过以下技术方案来实现:
一种文档结构化方法,包括:
步骤S1:接收文档,创建该文档的结构化描述文件,并将文档保存至文档服务器中;
步骤S2:创建数据库,并存储所有文档的结构化描述文件;
步骤S3:在数据库中检索得到结构化描述文件后,于文档服务器中提取对应的文档。
所述步骤S1具体包括步骤:
步骤S11:接收文档;
步骤S12:提取文档已有标签;
步骤S13:生成文档的摘要;
步骤S14:用标记描述文档的标签和摘要生成该文档的结构化描述文件;
步骤S15:将文档保存至文档服务器中。
所述文档已有标签至少包括文档大小、文档来源、文档类别、文档修改时间、文档所属标准体系。
所述步骤S13具体包括步骤:
步骤S131:判断是否存在支持该文档的阅读模块,若为是,则执行步骤S132,若为否,则执行步骤S133;
步骤S132:采用该阅读模块打开该文档并提取文档中的部分文本作为文档的摘要;
步骤S133:接收由用户端输入的对该文档的摘要。
所述步骤S3具体为:在数据库中检索得到结构化描述文件后,判断当前用户是否存在对对应文档的操作权限,若为是,则于文档服务器中提取对应的文档,若为否,则返回错误信息。
一种文档结构化设备,包括:
用于接收文档,创建该文档的结构化描述文件,并将文档保存至文档服务器中的第一装置;
用于创建数据库,并存储所有文档的结构化描述文件的第二装置;
用于在数据库中检索得到结构化描述文件后,于文档服务器中提取对应的文档的第三装置。
所述第一装置包括:
用于接收文档的第一模块;
用于提取文档已有标签的第二模块;
用于生成文档的摘要的第三模块;
用于用标记描述文档的标签和摘要生成该文档的结构化描述文件的第四模块;
用于将文档保存至文档服务器中的第五模块。
所述文档已有标签至少包括文档大小、文档来源、文档类别、文档修改时间、文档所属标准体系。
所述第三模块包括:
用于判断是否存在支持该文档的阅读模块的第一单元;
用于采用该阅读模块打开该文档并提取文档中的部分文本作为文档的摘要的第二单元;
用于接收由用户端输入的对该文档的摘要的第三单元。
其特征在于,所述第三装置包括
用于在数据库中检索得到结构化描述文件后,判断当前用户是否存在对对应文档的操作权限的第六模块;
用于于文档服务器中提取对应的文档的第七模块;
用于返回错误信息的第八模块。
与现有技术相比,本发明具有以下优点:
1)为文档生成一个结构化描述文件,便于对文档进行平台化管理,响应速度更快,各种简单操作<0.5秒,查询统计<1秒。
2)在描述文件中用标记语言描述文档的摘要,支持关键字、模糊字、文件类型等多种查询方式。
3)支持的文件更多,包括:WORD、EXCEL、PDF、CEB、RMVB、AVI等多种文档及流媒体文件。
4)文档保密性高,通过各种权限的配置,是不同级别的用户访问。
附图说明
图1为本发明的主要步骤流程示意图;
图2为基于发明的文档管理系统的架构示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
一种文档结构化方法,如图1所示,包括:
步骤S1:接收文档,创建该文档的结构化描述文件,并将文档保存至文档服务器中,具体包括步骤:
步骤S11:接收文档;
步骤S12:提取文档已有标签,文档已有标签至少包括文档大小、文档来源、文档类别、文档修改时间、文档所属标准体系;
步骤S13:生成文档的摘要,具体包括步骤:
步骤S131:判断是否存在支持该文档的阅读模块,若为是,则执行步骤S132,若为否,则执行步骤S133;
步骤S132:采用该阅读模块打开该文档并提取文档中的部分文本作为文档的摘要;
步骤S133:接收由用户端输入的对该文档的摘要。
步骤S14:用标记描述文档的标签和摘要生成该文档的结构化描述文件;
步骤S15:将文档保存至文档服务器中。
步骤S2:创建数据库,并存储所有文档的结构化描述文件;
步骤S3:在数据库中检索得到结构化描述文件后,于文档服务器中提取对应的文档,具体为:在数据库中检索得到结构化描述文件后,判断当前用户是否存在对对应文档的操作权限,若为是,则于文档服务器中提取对应的文档,若为否,则返回错误信息。
基于本申请可以开发出一套信息系统,能够通过关键字、模块查询等条件快速响应搜索,能通过登陆权限的设置对各种级别的文档的访问权限进行控制,且定期对文档进行备份,以免数据丢失。其设计理念如下:
(一)标准化结构设计
设计出一套符合计量标准化的树形结构,可以持续扩充,用来展示结构化和非结构化数据,如表1所示:
表1
(二)功能设计
设计系统功能模块,包括:标准查阅模块、标准管理、系统管理等模块及其下属子模块。详细如下:
1、用户和功能范围
标准化管理系统的用户覆盖范围为中心的所有内网用户,支持(1)免登录标准查阅、(2)登录后进行对应角色的标准化管理操作两种使用模式,系统所包含的各个功能模块及其子功能如表2所示。
表2
系统整体架构
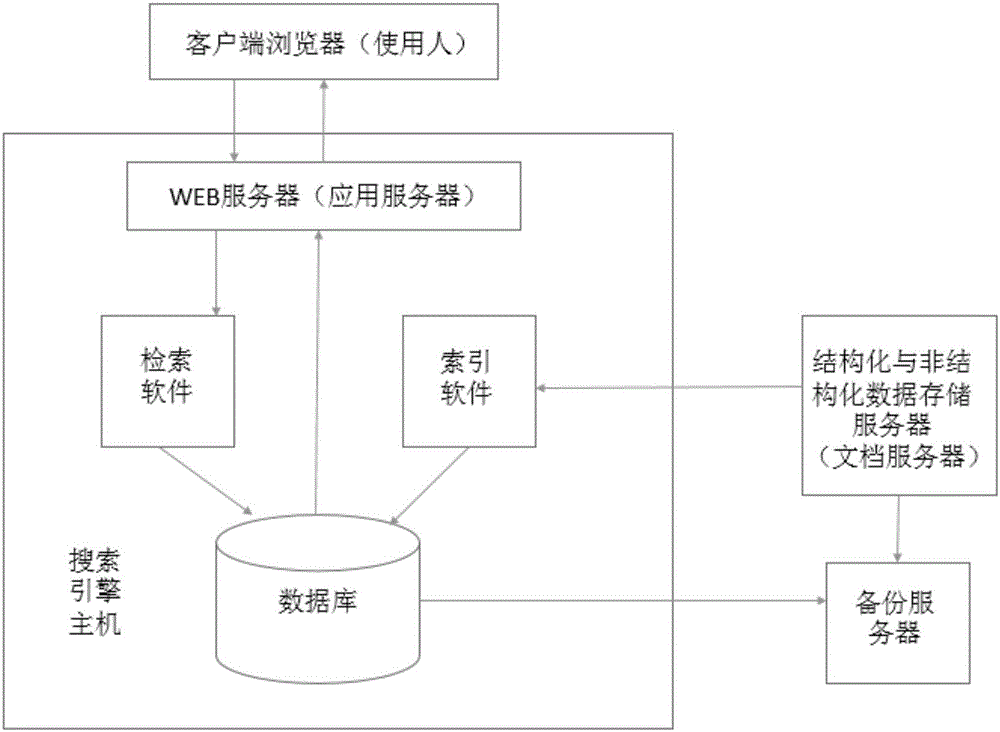
系统采用浏览器/服务器的结构。客户端通过IE浏览器来访问系统。
整体架构如下图所示:
3、功能设计
1)标准文档建立管理
(1)标准发布
根据计量标准化工作过程的管理需要,由综合室负责发布在线的正式版本到相应的文件目录,文件目录可以由档案管理员进行增加/删除,并设置文档的浏览查阅权限。档案管理员可在此基础上整理接收相关档案资料,支持文档、扫描图片等各种文档类型附件的管理。
文件编号和文件名的唯一性限制功能,可以通过系统自动生成建议的文件编号的基础上支持手工修改;文件名唯一性限制通过系统检索来提示。
(2)标准更新
可依据业务需要,根据多种组合查询出符合条件的标准信息列表,从中选取需要更新的记录,重新编辑、增加或删除。可调整排列顺序;支持历史记录的管理,如存在历史标准修改记录,系统支持存储历史版本信息,根据时间顺序进行排列和管理。
所有新建、更改和删除的操作均计入日志,可以根据操作人员、时间跨度、户号、户名等条件进行查询检索。
(3)标准作废
标准隐藏:对需要暂时停用的标准信息进行隐藏操作,并支持档案的恢复启用。
标准废止:对经过审批需要废止的标准资料进行废止操作,并进行废止登记,保留历史资料。
(4)标准备份
对更新和废止的标准,保留历史操作记录的同时,进行历史版本备份,供管理员查询。
2、标准查阅模块
以在线浏览的模式,根据不同的权限设置,提供标准化信息的查询、浏览、下载操作。
(1)标准浏览和检索
普通访问用户可以登录浏览页面,通过关键字查询、模块查询、文件目录选择等方式,对具备普通开放浏览权限的电子信息浏览,并支持下载、打印功能。
(2)高权限浏览
注册访问用户可以通过用户登录浏览页面,通过关键字查询、模糊查询、文件目录选择等方式,实现高级全权限浏览功能,并支持下载、打印功能。
3、系统用户权限管理
(1)系统设置
主要进行权限管理、日志管理和查询、系统参数管理等功能。
能够根据操作人员的工作岗位不同,设置不同的操作权限,如标准分类管理、上传、修改等。
(2)用户管理
定义系统的管理员用户和普通用户,并提供账户新增、删除修改等功能。
以web形式,依据用户名/密码的验证,登录系统,根据不同授权权限访问系统资源。
(3)标准体系管理
初始化标准阅览室的文件目录,并提供对目录的新增、删除等修改功能。
(4)组织管理
对日志管理:各类标准信息的增加、删除、修改等操作记入日志。
模板管理:根据计量标准化工作需要,提供标准电子文件模板,包括:标准化工作规范指导性文件发布,标准化管理文件模板发布和下载及其他政策性文件的发布。
(三)备份恢复
对于结构化、非结构化的数据备份及恢复策略。
1、数据库备份
使用逻辑备份,由系统定期对数据进行逻辑备份,如下表所示。
2、非结构化文档备份
前台增加备份功能模块,每天进行文档备份,将文档服务器上的传输到备份服务器上,若出现备份失败则会告警,第二天人工备份。
3、数据恢复
有了上述几种备份方法,即使计算机发生故障,如介质损坏、软件系统异常等情况时,可以通过备份进行不同程度的恢复,使数据库系统尽快恢复到正常状态。
(1)数据文件损坏
这种情况可以用最近所做的数据库文件备份进行恢复,即将备份中的对应文件恢复到原来位置,重新启动数据库,运行恢复命令就可以完成恢复。
(2)控制文件损坏
由于控制文件是数据库中是多重镜像的,单个文件的损坏不影响系统正常运行,但若数据库系统中的全部控制文件损坏,则数据库系统将不能运行,那么,只须将数据库系统关闭,然后从备份中将相应的控制文件恢复到原位置,重新启动数据库系统,运行恢复命令就可以完成恢复。
(3)整个文件系统损坏
由于磁盘或磁盘阵列的介质不可靠或损坏是经常发生的,这将导致整个数据库系统崩溃,这种情形只能:
a)将磁盘或磁盘阵列重新初始化,去掉失效或不可靠的坏块
b)重新创建文件系统
c)利用备份将数据库系统恢复到备份时间点
d)重新启动数据库系统
e)运行恢复命令恢复到损坏点
f)将最近的数据重新录入
如图2所示的搜索引擎系统架构。其核心的文档处理和查询处理过程与传统信息检索系统的运行原理基本类似,但其所处理的数据对象的繁杂特性决定了搜索引擎系统必须进行系统结构的调整,以适应处理数据和用户查询的需要。
1、用户在搜索引擎界面输入关键词,单击“搜索”按钮后,搜索引擎程序即对搜索词进行处理,如中文特有的分词处理,去除停止词,判断是否需要启动整合搜索,判断是否有拼写错误或错别字等情况。搜索词的处理必须十分快速。
2、对搜索词处理后,搜索引擎程序便开始工作,从索引数据库中找出所有包含搜索词的结构化或非结构化数据,并且根据日期、文档结构大小等默认方法计算出哪些文档应该排在前面,然后按照一定格式返回到“搜索”页面。
3、用户根据展示出的数据进行在线阅览、下载或是打印。
4、定期的备份为整个套系统做好安全保障。
- 还没有人留言评论。精彩留言会获得点赞!