一种基于距离测度学习的AP聚类图像标注方法与流程
本发明属于图像标注技术领域,具体涉及一种基于距离测度学习的AP聚类图像标注方法。
背景技术:
近年来,人类一直致力于让计算机实现对图像语义理解的研究。而图像标注作为计算机理解图像语义的重要途径之一,一直是计算机智能视觉领域的研究热点。图像标注就是让计算机自动识别出能够反映图像内容的语义关键词,比如:对象(人、植物、建筑等)、场景(自然景观(高山、道路、树林等)、室内(办公室、家、健身会所等)、行为(度假、聚会、休闲等)以及情感(开心、难过、兴奋等)等。面对如此海量的语义关键词类型,图像标注工作存在着很大的困难,同时也极具挑战性。这也吸引了很多研究人员和组织致力于图像标注工作,包括ImageNet,ImageCLEF等,经过这些组织和研究人员的不懈努力,图像标注工作取得了一定的进展,然而存在一些语义相同的图像外观差别可能很大,语义不同的两个图像外观却很相似。对于这些图像,现有的图像标注方法效果并不理想。提高这些图像的标注精度,是当前图像标注的研究热点。
现有技术中,研究人员一般利用图像的底层特征来进行图像标注。然而图像底层特征和人理解的图像的高层语义之间存在着“语义鸿沟”,存在着一些底层特征相似但高层语义差别很大以及底层特征不相似但高层语义差别很小的图像。现有的利用图像底层特征的标注方法对这些图像的标注效果较差。如何提高这些图像的标注精度成为近几年图像标注领域的亟待解决的技术问题。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的基于距离测度学习的AP聚类图像标注方法。
为了实现上述发明目的,本发明提供的技术方案如下:
一种基于距离测度学习的AP聚类图像标注方法,包括以下步骤:
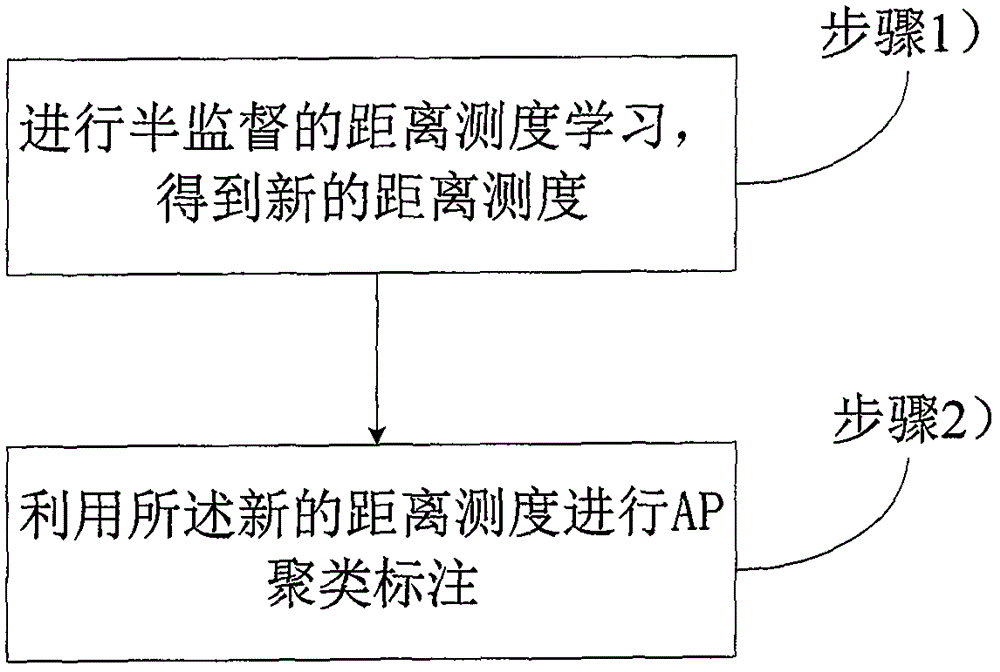
步骤1)进行半监督的距离测度学习,得到新的距离测度。
步骤2)利用所述新的距离测度进行AP聚类标注。
进一步地,所述步骤1)包括:借助图像类别标注信息,采用半监督的距离测度学习方法,学习到新的距离测度矩阵M;所述步骤1)具体为:
选取语义相同的图像和语义不同的图像作为训练样本;
假设语义相同图像的训练样本集合表示为A{(fi1,fi2)}m(其中i=1……m,m表示相同语义图像训练样本个数,fi1和fi2分别表示语义相同的两个图像的底层特征)。A集合中每一对训练样本按照式(3)表示为
语义不同的图像的训练样本集合B{(fj1,fj2)}n(其中j=1……n,n表示不同语义图像训练样本的个数,fi1和fi2分别表示语义不同的两个图像的底层特征)。B集合中每一对训练样本按照所述式(3)表示为
定义如下目标函数:
根据式(5)将式(4)中的和近似转化为和
最后,求解新测度矩阵M,将(4)式转化为如下形式:
M>0 (7),
trace(M)=1 (8)。
进一步地,求解新测度矩阵M的步骤具体为:
1)输入同语义训练集A{(fi1,fi2)}m(m为A训练集个数),输入不同语义训练集B{(fj1,fj2)}n(n为B训练集个数);
2)输入学习因子γ;
Repeat
3)其中代表训练集A中每一对样本的距离,代表训练集B中每一对样本的距离。计算函数G’(M)关于M的梯度
4)更新M:
5)约束条件:其中λi为M第i个特征值,为M的第i个特征向量(M>0);
6)约束条件:
Until循环结束或结果收敛。
进一步地,所述步骤2)包括:
步骤一:对每一类图像应用所述新的距离测度进行AP聚类,确定每一类图像的聚类中心,将每一类图像按照聚类结果分类。
步骤二:计算待标注图像到每一类图像聚类中心的平均距离,求得平均距离最小的图像类别作为待标注图像类别,平均距离公式如式(9)所示,
其中A代表待检测图像,Bij代表第i类图像第j个聚类中心,d(A,Bij)表示待检测图像到第i类图像第j个聚类中心的距离,mi代表第i类图像聚类中心个数;
步骤三:在确定的类别内计算待标注图像到类内各聚类中心的距离,求得距离最小的图像类别作为待标注图像类内类别。统计该类别下图像的标注词汇,作为待标注图像的标注词。改进的AP聚类标注模型,是对于每一类图像进行聚类,避免了对整个训练集聚类时因训练数据集太大造成的聚类精度的缺失。
本发明提供的基于距离测度学习的AP聚类图像标注方法,提出了一种基于距离测度学习的AP聚类标注模型,将图像底层视觉特征和图像的语义特征融合起来,有效解决了一些相同语义的图像底层特征差别却很大,语义不同的图像底层特征却相似所造成的“语义鸿沟”,明显提高了标注精度,并且本发明改进的AP聚类标注模型较其他基于分类器的标注模型在多种特征中mAP值都提高了至少0.03,可以很好地满足实际应用的需要。
附图说明
图1为传统距离测度与新距离测度对比示意图;
图2为本发明的流程图;
图3为本发明的AP聚类标注模型过程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
AP聚类算法(以下简称AP算法)是划分聚类方法的一种,它根据数据对象之间的相似度对数据进行自动聚类。N个数据对象的相似度组成N×N的相似度矩阵S。AP算法本身不需要事先确定聚类数目,它将每一个数据对象都作为候选的聚类中心。AP算法以相似度矩阵S对角线上S(k,k)(其中k=1....N)值的大小作为判断k点是否可以作为聚类中心的标准,S(k,k)值越大,k点作为聚类中心的可能性就越大,该值又称为参考度p。初始选取的p值一般取相同的值,即每一个数据对象作为聚类中心的概率相同。聚类中心的数目受到初始参考度p的影响,通常情况下选取所有数据对象相似度的中值作为p的初始输入。
AP算法数据对象之间传递两种信息,分别是吸引度(Responsibility)和归属度(Availability)这两种信息的传递过程,可以认为是每一个数据对象竞争成为聚类中心的过程。R(i,k)表示从点i发送到候选聚类中心k的信息,反映k点作为i点的聚类中心的适合程度。A(i,k)表示从候选聚类中心k发送到i的信息,反映i点选择k作为其聚类中心的可能程度。R(i,k)与A(i,k)越大,则k点作为聚类中心的可能性就越大,并且i点属于以k点为聚类中心的聚类的可能性也越大。AP算法通过迭代过程不断更新每个数据点的吸引度和归属度值,直到产生m个高质量的聚类中心,同时将其余的数据点分配到相应的聚类中。其迭代公式如下所示:
(1)吸引度迭代公式:Rt+1(i,k)=(1-λ)·Rt+1(i,k)+λ·Rt(i,k) (1)
其中,
(2)归属度迭代公式:At+1(i,k)=(1-λ)·At+1(i,k)+λ·At(i,k) (2)
其中,
当t为0时R(i,k)与A(i,k)为0。式(1)和式(2)中参数λ,称为阻尼系数,它主要是起收敛作用的,一般取值为[0.5,1]。它表示每次迭代完,吸引度和归属度要根据上一次的吸引度和归属度和当前的吸引度和归属度进行加权更新。
常用的距离度量方法主要有欧式距离、马氏距离等。假设a和b,是数据集中两个样本,它们之间的距离平方可用式(3)表示,其中M是一个对称的半正定矩阵,称为距离矩阵。如M=I(单位阵)时,式(3)为两个样本间的欧式距离平方。当M是样本的类内离散矩阵的逆阵时,式(3)为样本之间的马氏距离平方。
无论马氏距离还是欧式距离,其描述的是图像底层特征的相似性,然而图像底层特征的相似性和人理解的高层语义的相似性是不同的。而图像还有一些不可忽略的信息,即图像标注信息(例如图像类别信息),在一定程度上描述了图像的部分高层语义。如果可以从这些标注信息中学习到某种距离测度,减少图像底层特征与图像高层语义之间的差异,便可提高聚类算法的精度。
距离测度学习算法的基本思想就是借助数据点的标注信息,学习到一个新的距离测度,使得相同类别的数据点互相靠近,不同类别的数据点互相远离。如果用(3)式表示,那么距离测度学习就是利用数据点标注信息学习到新的距离测度矩阵M。
由图1可见,对于样本点A1,如果使用传统的距离测度(例如欧氏距离)时,它的近邻样本点有A2、A3、A4、B1、B2,其中A1、A2、A3和A4属于Class1,B1、B2属于Class2,如果进行聚类,B1、B2样本点很可能被错分到Class1内,而使用距离测度学习得到的新距离测度,A1与其同类样本点A2、A3、A4的距离被缩短,与其异类样本点B1、B2的距离被扩大,避免B1、B2样本点被错分到Class1,提高了聚类算法的精度。
如图2所示,本发明的基于距离测度学习的AP聚类图像标注方法,提出了基于距离测度学习的AP聚类标注模型,本发明具体分为两个步骤:步骤1)是半监督的距离测度学习,得到新的距离测度;步骤2)是利用新的距离测度进行AP聚类标注。
本发明提出一种半监督的距离测度学习算法,借助图像类别标注信息,学习到新的距离测度矩阵M。同时本发明将距离测度学习转化为一个凸优化问题。
距离测度学习的目的是保证同类图像之间距离尽量小,不同类图像之间距离尽量大。因此,需要选取语义相同的图像和语义不同的图像作为训练样本,这个过程中实际上利用了图像的语义信息。假设语义相同图像的训练样本集合表示为A{(fi1,fi2}m(其中i=1……m,m表示相同语义图像训练样本个数,fi1和fi2分别表示语义相同的两个图像的底层特征)。A集合中每一对训练样本按照式(3)距离公式是表示为语义不同的图像的训练样本集合B{(fj1,fj2)}n(其中j=1……n,n表示不同语义图像训练样本的个数,fi1和fi2分别表示语义不同的两个图像的底层特征)。B集合中每一对训练样本按照式(3)距离公式是表示为定义如下目标函数:
考虑到式(4)中min(max)函数是不可微的,本发明对距离测度学习算法进行了近似转化,通过式(5)所示的不等式将距离测度学习转化为一个凸优化问题。
根据式(5)将式(4)中的和近似转化为和最终(4)式转化为如下形式:
M>0 (7)
trace(M)=1 (8);
式(6)中G’(M)里面的和是凸函数,因此可以将(6)-(8)看成一个凸优化问题。式(7)的约束条件M>0用来限定M必须是半正定的对称矩阵,这个是式(3)的条件。式(8)是防止G’(M)的值被优化为负无穷。
本发明在训练距离测度矩阵M时,采用一种半监督的训练方法,仅选取部分图像训练。选取相同语义训练样本集A{(fi1,fi2)}m时,考虑到目标函数G(M)要求同类图像的最大距离尽量小,因此只需要选取同类图像中距离较大的图像作为训练图像。而对于每一类图像,其各聚类中心之间的距离是这一类图像中距离较大的,因此利用AP聚类算法将每一类图像进行聚类,对每一类图像其聚类中心两两组合作为训练样本。选取不同语义训练样本集B{(fj1,fj2)}n时,考虑到目标函数G(M)要求不同类图像的最小距离尽量大。因此只需要选取不同类图像中距离较小的图像作为训练图像。因此对于每一类图像,选取与其外观上相似的几类图像的聚类中心与该类图像聚类中心两两组合作为训练样本。这种半监督的训练方法在不影响训练精度的情况下,除去一些对目标函数G(M)没有影响的训练样本,减小了训练过程的计算量,提高了训练效率。
(6)-(8)求解新测度矩阵M的过程可以用随机梯度算法实现,具体算法的过程如下:
1)输入同语义训练集A{(fi1,fi2)}m(m为A训练集个数),输入不同语义训练集B{(fj1,fj2)}n(n为B训练集个数);
2)输入学习因子γ;
Repeat
3)其中代表训练集A中每一对样本的距离,代表训练集B中每一对样本的距离。计算函数G’(M)关于M的梯度
4)更新M:
5)约束条件:其中λi为M第i个特征值,为M的第i个特征向量(M>0);
6)约束条件:
Until循环结束或结果收敛。
通过半监督距离测度学习算法,训练得到新的距离测度。新的距离测度将被应用到下面介绍的AP聚类标注模型当中。
本发明提出一种AP聚类标注模型。在选取聚类模型时,最先考虑的是应用最广泛的最近邻模型,但在本发明需要对每一类图像内部聚类,而最近邻模型需要事先确定聚类中心的数目。对于每一类图像其内部图像之间距离分布是不一样的,显然如果事先对每一类图像确定相同的聚类中心数目是不合适的,而本发明应用的AP聚类算法本身不需要事先确定聚类中心数目,其根据数据点的分布自动确定聚类中心数目。
使用聚类模型进行图像标注的常规思路是先对训练集图像进行聚类,将训练集图像按照聚类结果进行分类。然后再根据待检测图像到各聚类中心的距离确定待检测图像类别。最后借助图像标注信息,统计该类别下的图像标注词汇,作为待标注图像标注词。而聚类算法是无监督学习,因为缺少先验知识,当数据集较大时,效果普遍不佳。如果将聚类算法应用在整个训练集图像中,会导致聚类精度较差,影响标注效果。因此本发明提出了改进的AP聚类标注模型,不再将聚类算法应用到整个训练集上,而是对每一类图像进行AP聚类。
本发明提出的改进的AP聚类标注模型主要分为三个过程。如图3所示,过程1是对每一类图像应用新的距离测度进行AP聚类,确定每一类图像的聚类中心,将每一类图像按照聚类结果分类;过程2是计算待标注图像到每一类图像聚类中心的平均距离,求得平均距离最小的图像类别作为待标注图像类别,平均距离公式如式(9)所示,
其中A代表待检测图像,Bij代表第i类图像第j个聚类中心,d(A,Bij)表示待检测图像到第i类图像第j个聚类中心的距离,mi代表第i类图像聚类中心个数;过程3是在确定的类别内计算待标注图像到类内各聚类中心的距离,求得距离最小的图像类别作为待标注图像类内类别。统计该类别下图像的标注词汇,作为待标注图像的标注词。改进的AP聚类标注模型,是对于每一类图像进行聚类,避免了对整个训练集聚类时因训练数据集太大造成的聚类精度的缺失。
本发明采用的数据集包括:Corel5K数据集和NUS-WIDE-OBJECT数据集,这两种数据集在图像标注领域应用较为广泛,具体信息如表1所示。
表1实验数据集信息
Corel5k数据集包含50类语义图像,每一类包含100张图像,每个图像包含1~5个标注词,一共371个标注词,在本发明实验中选取至少标注8张以上图像的标注词进行实验,共计260个。NUS-WIDE-OBJECT数据集包含31类语义图像,一共587个标注词,本发明实验选取至少标注5张以上图像的标注词进行实验,共计393个。
本发明根据对标注结果分析,在Corel5K数据集上,当选取出现超过三次的标注词作为图像标注词时标注效果较好,在NUS-WIDE-OBJECT数据集上,当选取出现超过两次的标注词作为图像标注词时标注效果较好。本发明实验采用的性能评价标准是平均标注准确率mAP(mean Average Precision),即先统计每个标注词的平均标注精度AP(Average Precision),然后在对求得的每个标注词的标注精度求和取平均。该评价标注是图像标注中经常应用的标准,能够精确的反映标注效果的好坏,具体公式如式(10)所示。
本发明实验选取三种图像底层视觉特征:分块HSV颜色直方图,哈希感知,基于SURF局部特征视觉词袋直方图。其中分块HSV颜色直方图描述图像的颜色特征,哈希感知算法提取的是图像的整体外观特征,SURF局部特征是SIFT算法的改进,提取SURF特征时,先将图像分成固定大小的块,提取各个块的SURF局部特征,然后对所有训练图像各个块根据SURF特征进行聚类,最终生成视觉词袋直方图特征。这三种特征从不同的方面描述了图像的信息,因此可以验证本发明方法在不同特征上的有效性。
为验证本发明方法有效性,现将本发明方法和其他方法进行对比实验,实验一是比较本发明通过距离测度学习得到的新距离测度与传统距离测度对标注精度的影响。实验二是比较本发明改进的AP聚类标注模型与传统基于分类器的标注模型对标注精度的影响。
本发明实验通过距离测度学习得到新的距离测度。因此,首先将本发明得到的新距离测度与传统距离测度进行对比实验。分别使用三种图像底层特征(分块HSV直方图(AHSV),哈希感知(HASHS),SURF视觉直方图(SURFW))进行实验,其中对于哈希感知算法,采用汉明距离和DML距离(本发明)进行实验,而分块HSV颜色直方图和SURF视觉词袋直方图都属于直方图特征,因此增加更适合直方图的距离测度与DML距离(本发明)进行对比。表2、表3分别给出了在Corel5K数据集和NUS-WIDE-OBJECT数据集的标注结果。
表2 Corel5K数据集标注结果
表3 NUS-WIDE-OBJECT数据集标注结果
从实验结果中可以看出,在Corel5K和NUS-WIDE-OBJECT数据集上,本发明通过距离测度学习得到的新距离测度相较于其他几种传统距离测度在多个特征上的标注精度都有了一定的提高,在Corel5K数据集上,本发明方法在SURF视觉直方图特征实验中,mAP值达到了0.295。在NUS-WIDE-OBJECT数据集上本发明方法在SURF视觉直方图特征实验中,mAP值达到了0.38。这充分说明本发明的新距离测度,融合了图像的语义信息,减小了图像底层特征与图像高层语义之间的差异,对于图像语义准确理解有重要意义,能够有效提高图像标注精度。
本发明提出改进的AP聚类标注模型,属于基于分类器的标注模型,因此本实验将本发明模型与其他基于分类器模型的标注方法进行对比试验,比如:支持向量机(SVM),K近邻算法(KNN),AP聚类算法,贝叶斯模型(NB)。对于每一种方法都使用本发明提出的新的距离测度,对于每一种方法分别使用三种特征(分块HSV直方图,哈希感知,SURF视觉直方图)进行实验,然后再将三种特征组合起来进行实验。
从实验结果中可以看出,在Corel5K和NUS-WIDE-OBJECT数据集上,本发明改进的AP聚类标注模型在四种特征上都取得了较其他分类模型好的标注效果,在Corel5k数据集上,本发明模型在三种特征融合的情况下标注精度最高,mAP值达到了0.31。而且四种图像特征的mAP值都比其他方法高出最少0.03。在NUS-WIDE-OBJECT数据集上,本发明模型在三种特征融合的情况下标注精度最高,mAP值达到了0.4。而且在四种图像特征上的mAP值都比其他方法高出最少0.05。这表明相比于其他基于分类器的标注模型,本发明的改进的AP聚类标注模型能够有效提高标注精度。同时,从实验结果中发现,在Corel5K和NUS-WIDE-OBJECT数据集上,本发明的改进的AP聚类标注模型相比于传统AP聚类标注模型在各个特征上的mAP值都有不同程度的提高。这充分说明了本发明对于AP聚类算法的改进是有重要意义的,可以在一定程度上提高标注精度。
本发明提出了一种融合语义信息的图像标注方法,即基于距离测度学习的AP聚类标注模型。首先提出一种半监督的距离测度学习方法,融合图像语义信息,进行距离测度学习,生成新的距离测度,新的距离测度缩小了同语义类别下图像距离,同时扩大了不同语义类别下的图像距离。同时本发明优化了距离测度学习训练过程,采用半监督的训练过程,选取同语义但图像底层特征差别大,不同语义但图像底层特征相似的图像作为训练图像,这种设置有效消除了无效训练样本,提高了训练效率。其次提出一种改进的AP聚类标注模型。将AP聚类算法应用在每一类图像上,而不是整个训练集上,这种设置避免了对整个训练集聚类时因训练数据集太大造成的聚类精度的缺失。在Corel5K和NUS-WIDE数据集上进行了实验,经验证,本发明有效提高了标注精度。
本发明提供的基于距离测度学习的AP聚类图像标注方法,提出了一种基于距离测度学习的AP聚类标注模型,将图像底层视觉特征和图像的语义特征融合起来,有效解决了一些相同语义的图像底层特征差别却很大,语义不同的图像底层特征却相似所造成的“语义鸿沟”。在Corel5K和NUS-WIDE-OBJECT数据集上的实验表明,新的距离测度较其他传统的距离测度明显提高了标注精度。并且改进的AP聚类标注模型较其他基于分类器的标注模型在多种特征中mAP值都提高了至少0.03。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!