一种对高校网站上的会议稿进行知识抽取的方法与流程
本发明属于中文信息处理技术领域,具体涉及一种对高校网站上的会议稿进行知识抽取的方法。
背景技术:
近些年,随着信息技术的迅猛发展,对原有的教育产业模式产生了深远的影响,高校建设逐渐趋于信息化,高等院校的门户网站也成为高校发布各种校园通告和新闻的主要平台和实现高校办公自动化的重要手段,因此,对于高校网站的知识抽取研究也逐渐成为学术界的热点。如果能准确高效的抽取出高校网站上的会议和讲座的相关内容的知识,比如会议或讲座的时间、地点、专家名称和举办机构等,将直接影响着检索和办公自动化的效率以及准确率,为自动搜索提供更大的便利。
高校会议稿是一种特定的报告形式,在文章的开头直接写明会议的名称,起始段落一般仅包含开会的地点、时间和主要参会人员以及主持人等内容,然而,有一些高校会议稿并不是按照该特定形式出现,比如,在文章的开头并未写明会议名称或起始段落中未明确包含开会的地点,时间和主要参会人员等实体内容,这样,就不能按照基于规则的方式来抽取实体。以上两种会议稿有较大的区别,因此,需要在抽取实体前对语料进行自动分类,分类后分别对规则语料和非规则语料进行知识抽取。
20世纪80年代末,消息理解会议的举行,为知识抽取奠定了基础。该会议的举行召开,推动着知识抽取技术不断向前发展,使知识抽取慢慢发展为自然语言领域的一个重要部分。目前,知识抽取主要有两大技术,机器学习和自然语言处理,这两种技术各自发展,而且,在相互融合和借鉴方面得到了较大的发展。
高校网站上的会议稿是一种特定的报告形式,在文章的开头直接写明会议的名称,起始段落一般仅包含开会的地点、时间和主要参会人员以及主持人等内容,并且写作形式也比较固定;然而,有一些高校会议稿并不是按照该特定形式出现,比如,在文章的开头并未写明会议名称或起始段落中未明确包含开会的地点,时间和主要参会人员等实体内容,或者包含的实体内容并不在固定的位置。这样,就不能按照基于规则的方式来抽取实体。以上两种会议稿有较大的区别,因此,在抽取实体前对语料进行自动分类,分类后分别对规则语料和非规则语料进行知识抽取。在规则会议稿中,特定的部分包含了标题,时间,地点和参会人员等实体,但在非规则会议稿中,并不能完全包含这些内容,这也是导致实体抽取效果不甚理想的原因之一。
现有技术中对会议稿进行知识抽取的方法主要是基于规则的方法和基于统计的方法。基于规则的方法的缺陷是在于人为编写规则需要语言专家对语言规则进行深入的理解,在此基础上编写规则,构造规则对语言知识要求较高,需要很大的人力物力,另外,规则较多时还会引起规则之间的冲突,各语言间移植困难、通用性不强。基于统计的方法例如用隐马尔可夫模型并使用角色标注的方法来进行实体识别,存在一些固有缺陷与不足,需要做出严格的独立性假设,然而事实上,大多数序列数据都不能被表示成一系列独立的元素。因此现有技术中对会议稿进行知识抽取的方法是存在很多缺陷的。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的对高校网站上的会议稿进行知识抽取的方法。
为了实现上述发明目的,本发明提供的技术方案如下:
一种对高校网站上的会议稿进行知识抽取的方法,包括以下步骤:
步骤1):采用基于规则的方式对会议稿进行分类;
步骤2):对会议稿进行实体抽取;
步骤3):采用四词位标记法对训练集中的每一个字进行标注;
步骤4):选择特征模板;
步骤5):采用基于贝叶斯的实体条件概率对语料进行二次识别。
进一步地,所述步骤1)具体为:应用正则表达式将高校会议稿分为两类,规则会议稿和非规则会议稿;符合正则表达式规则的,则为规则会议稿,不符合的就自动归为非规则会议稿。
进一步地,所述步骤2)中,当会议稿为规则会议稿时,通过基于规则的方法来进行实体抽取;当会议稿为非规则会议稿时,采用基于统计的方法对非规则会议稿进行实体抽取。
进一步地,所述步骤2)中,当会议稿为非规则会议稿时,采用条件随机场模型对非规则会议稿进行实体抽取。
进一步地,所述步骤3)中的四词位标记法的特征标记如下表所示:
进一步地,所述特征模板为:
进一步地,所述步骤5)的基于贝叶斯的实体条件概率的公式为:
表示字wordi的出现频率,P(wordi+1|wordi)表示在字wordi的前提下出现字wordi+1的概率,P(name)为查询串的条件概率。
本发明提供的对高校网站上的会议稿进行知识抽取的方法,对高校网站上的会议稿进行知识抽取的效率高、效果好,所获得的准确率、召回率及调和参数值均比现有技术更加理想,可以很好地满足实际应用的需要。
附图说明
图1为本发明的流程图;
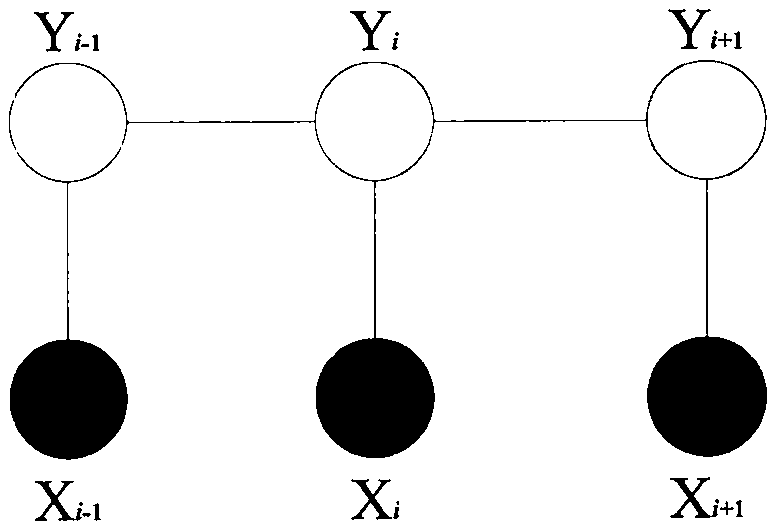
图2为线性链结构的条件随机场无向图模型示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明提供了一种对高校网站上的会议稿进行知识抽取的方法,包括以下步骤:
步骤1):采用基于规则的方式对会议稿进行分类;
应用正则表达式将高校会议稿分为两类,规则会议稿和非规则会议稿;符合正则表达式规则的,则为规则会议稿,不符合的就自动归为非规则会议稿。
基于规则的自动分类的基本方法为:通过观察语料,利用语料中各个实体的位置信息编写分类规则,进而得到语料样本所述的类别。
本发明应用正则表达式来分类和抽取实体,在编写规则的过程中,每条规则可以由多项组成。在有特定规律的文本中,用正则表达式能够快速准确的匹配并抽取出特定位置的实体,而一个正则表达式一般是由普通字符以及特殊字符(元字符)组成,描述了待识别串的匹配模式。普通字符包含大小写的字母和数字,而元字符在正则表达式中具有特殊含义的专业字符。
对于实体的抽取规则,根据会议稿内容抽出一些关键词,比如“主讲人”、“讲座人”、“报告人”等等,在距离这些关键词最近的人名则定为主讲人名,其他实体的抽取规则也是如此。
通过制定有关的规则,则能够采用正则表达式抽取的会议稿自动分为规则会议稿,不符合规则的将自动归为非规则会议稿,从而将得到的语料自动分为规则高校会议稿和非规则高校会议稿。
步骤2):对会议稿进行实体抽取;
针对规则会议稿和非规则会议稿采取不同的方法抽取实体;规则会议稿有特定的书写形式和明显的规则,因此,可以通过基于规则的方法来进行实体抽取;非规则会议稿则采用基于统计的方法来进行实体抽取。
规则会议稿的实体抽取方法:根据规则会议稿的特点,需要抽取的特征实体大致有如表1所示几类:
表1特征实体分类
由于在非规则会议稿中,特征实体比较复杂,识别难度较大,抽取出的正确率不高,所以,在本发明中,进行知识实体抽取的过程采用多层识别来提高抽取的正确率;非规则会议稿的实体抽取方法如下:
采用条件随机场模型对非规则会议稿的实体进行首次抽取;
在高校会议稿中,人名、地名、主要参会人员和会议时间等前后存在一定的识别特征关系,因此,可以将实体识别的问题转化成序列的标记问题。而条件随机场正是解决该问题的模型,因此,本发明采用条件随机场模型进行首次抽取。
条件随机场(Conditional Random Fields,CRFs)是一种无向图模型。它没有隐马尔可夫模型那样强的独立性假设,同时也克服了标记偏置问题。
条件随机场最简单和普遍的结构是线性链结构,如图2所示。在图形模型中的各输出结点被连接成一条线性链的特殊情形下,CRFs假设在各个输出结点之间存在一阶马尔可夫独立性,二阶或更高阶的模型可类似扩展。
在给定观察序列X=(X1,X2,...,Xn)的条件下,标记序列Y=(Y1,Y2,...,Yn)的条件概率分布P(Y|X)构成条件随机场。
设X和Y均为线性链表示的随机变量序列,则P(Y|X)称为线性链条件随机场。在
X取值为x的条件下,Y取值为y的条件概率满足:
式中,fk和gk是特征函数,λk和uk是通过参数估计确定的参数。
步骤3):采用四词位标记法对训练集中的每一个字进行标注;
四词位标记法的特征标记如表2所示:
表2四词位标记法
通过以上的标注定义,对训练集中的每一个字进行标注,因此,特征实体识别的任务就成了对测试集中每个字的B,I,E,O序列标记问题。对训练集标注完毕后,通过CRF模型对已经标注好的训练集进行训练,对测试语料进行识别。识别完成后,将测试集中标记有BIE或者BE的字的组合提取出来,进行还原组合,则抽取出了特征实体。
步骤4):选择特征模板;
特征模板在命名实体识别时用来匹配信息构成具体特征,选择合适的特征模板显得尤为重要。特征模板是根据所选用的特征设计出来的模板,CRF++工具会在语料训练的过程中根据不同的特征模板生成不同的特征函数,针对高校网站上的会议稿的特点,选取的一组特征模板如下所示:
Word(0)表示当前词;POS(0)表示当前词的词性;括号中的数字表示与当前词的距离,负数表示当前词左侧,正数则表示当前词右侧;多个特征表示组合模板。
步骤5):采用基于贝叶斯的实体条件概率对语料进行二次识别;
由于语料规模限制,条件随机场在学习过程中很难学习到高校会议稿的全部特点,这直接导致条件随机场漏识了部分信息量少的实体,进一步研究这些实体多为少见实体,即其字之间的组合比较少见,且其在整个语料中出现频率低。为此定义基于贝叶斯的实体条件概率如下:
其中,P(wordi)表示字wordi的出现频率,P(wordi+1|wordi)表示在字wordi的前提下出现字wordi+1的概率,P(name)为查询串的条件概率。n=1时,实体长度为2,n=2时表示实体长度为3。
较为生僻的实体,实体之间字的组合很少连续,导致实体与实体之间的条件概率值小于语料中词的条件概率值。
本发明进行实验的训练语料选择1998年1月的人民日报作为基准语料,计算每个字的概率和以该字为基准的条件概率,得到一个概率参数表。利用概率参数表计算实体条件概率值,对长度为2和3的查询串分别设定阈值TVO2(Threshold Value of 2 Words)和TVO3(Threshold Value of 3 Words),按照阈值筛选候选实体,在保证准确率的前提下,提高实体召回率。
本实验的训练语料是1998年1月的人民日报,此语料的方式是粗分词,而且还进行了词性标注,这样,在实验中就很容易从中获得BIEO标注类型,在实验过程中也很容易进行操作。测试语料来自于北京师范大学高校网站的会议稿内容,在本次实验中,选取了5000条会议稿内容。
实验以准确率、召回率作为分析结果的评价指标,并以F调和参数值作为综合评价。将分析结果中正确的个数记为setA,测试集中抽取出的个数记为setB,分析结果中的总个数记为setC,则准确率为P=setA/setC,召回率R=setA/setB,调和参数值F=2PR/(P+R)。
分别以现有技术和本发明的方法进行两组实验,其中,以现有技术进行实验的实验结果为:识别出的人名的P、R、F值分别为95.28%,86.25%,90.63%,地名的P、R、F值分别为85.65%,88.85%,83.65%,会议名的P、R、F值分别为87.77%,91.36%,89.54%;以本发明的方法进行实验,对实体进行了召回,并进行了二次识别,识别效果有了很大的提高,其中人名的P、R、F值分别为95.33%,91.48%,91.05%,地名的P、R、F值分别为88.97%,89.68%,85.74%,会议名的P、R、F值分别为90.37%,92.89%,91.61%。
从实验结果可以看出,总体来说,本发明的效果比现有技术的效果有明显的提高。
本发明提供的对高校网站上的会议稿进行知识抽取的方法,对高校网站上的会议稿进行知识抽取的效率高、效果好,所获得的准确率、召回率及调和参数值均比现有技术更加理想,可以很好地满足实际应用的需要。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!