一种基于多元线性回归模型的餐馆评分预测方法与流程
本发明涉及数据挖掘与数据分析技术,特别是涉及一种基于多元线性回归模型的餐馆评分预测方法。
背景技术:
星级是对餐馆的综合评价,餐馆的星级很大程度依赖于评价人对餐馆的主观评价。因此通过对评价文本的分析来预测评价人将要给出的星级,通过对评价人的评价文本内容、评价的长度、评价的情感值、餐馆当前的平均星级、评价人的特点等因素的分析,从而得到各个因素与最后评价人给出的星级之间的关系。
线性回归算法是数据挖掘领域中比较重要的算法,它通过给定数据集D={(x1,y1),(x2,y2),...,(xm,ym)},其中xi=(xi1;xi2;...;xid),试图得到一个线性模型以尽可能准确地预测实值输出标记。
随着数据量的急剧增加,在UGC(User Generated Content用户原创内容)网站上用户留下的评论和其他客观条件,这些数据作为构成了UGC的评分基础,借助这些数据,我们可以对餐馆星级做出预测,一般我们可以采取线性回归的方法。简单线性回归法是用来度量一个自变量对因变量的影响程度的。
技术实现要素:
为了克服现有的餐馆评分预测方式的可靠性较差的不足,本发明提出了一种基于多元线性回归模型的餐馆评分预测方法。UGC类网站上,用户会通过自身的体验对商户进行评分与评价。而每个用户在评分后会给出评论。每个用户的评论文字的长短,所附加的情感,餐馆当前的星级以及用户自身的特点都影响了用户会给出的评分情况。用户最终给出的评分与其写的评论有直接的关系,所以通过分析其评论的各个特点可以一定程度上预测评分(或者说星级)。该方法通过餐馆网站中选取若干指标(来自网站中直接提供的特征加上我们语义分析获得主观性和极性),进行线性回归方程建模,从而为餐馆的星级提供了可供预测的公式。
本发明解决其技术问题所采用的技术方案如下:
一种基于线性回归的餐馆星级评价方法,包括以下步骤:
S1:从餐饮网站上抓取数据,并对数据进行分析,最后获得三个相关的数据表,分别是user、business、review这三张表;
S2:在review表中提取相关的用户评论数据,分析评论文本的语义极性和主观性,所述语义极性包括褒义、中性或者贬义;
S3:在网站提供的特征和语义分析获得的主观性和极性中,同时考虑用户和餐馆对评分预测的影响,选择需要的特征变量;
S4:把相关的数据表导入数据库中,用SQL语句获得我们选择的特征变量的数据集,并将数据集分成若干个更小的数据集;
S5:对于获得的数据,进行克伦巴赫系数均衡数据的置信度分析,得到可信度较高的数据作为分析的数据样本,选取alpha系数大于预设阈值的数据集,若不存在这样的数据集转移到S3;
S6:构造理论模型,设定各个自变量与因变量之间的关系是线性的,从而建立多元线性回归模型,借助工具进行多元线性回归处理得到数据;
S7:对模型进行检验,一个指标是拟合度,设定拟合阈值为拟合程度很高,第二个指标为DW检验,通过T显著性指标大于指标阈值,对设置的指标进行筛选,获得回归方程,否则如果无法获得我们想要的模型,就转移到S3;
S8:运行模型,进行共线性诊断,查看VIF方差扩大因子,若VIF小于门限值则判断自变量之间不存在共线性,否则我们需要进行主成分分析处理共线性问题,之后分析残差,若残差不满足要求就转移到S3;
S9:若满足上述步骤的要求,则说明该线性回归方程模型满足该数据集,利用得到的线性回归方程,同时结合用户和餐馆信息,得出尚未有星级的餐馆的评价星级。
本发明的技术构思为:多元线性回归有多个自变量或者回归元。对于影响餐馆评分的特征变量,通过线性回归,就能够预测出相应的评分。
在多元回归模型中,我们还需要对模型进行统计诊断,一般有残差值(residuals)、杠杆值(leverage)、学生化残差(residuals of studentized)和强影响值(cook),对相应的统计量对模型进行优化。在用回归法时,需要数值型数据,标称型数据将转成二值型数据,因此我们把用户评价做了一个语义分析。
在评价网站上,用户会对光顾过的餐馆进行评价并给出评分,他们给出的评论很大程度上影响最后的评分,而用户在寻找餐馆时往往会看重餐馆的评分。评价文本与用户给出的星级密切相关,用户的评论属于一种自然语言,在对用户的评价文本进行分析时,我们借助python的自然语言包,获得评价文本的长度和评价的情感值。用户在评论中必然会使用一些描述情感的形容词,表现情感强度的副词、标点符号,通过抓取这一系列的关键词汇可以数值化评论中所包含的情感值,这样用户的情感就能量化成定性的数据。自然语言工具包(Natural Language Toolkit),它是一个将学术语言技术应用于文本数据集的Python库。我们可以获得用户评价的极性(褒义、中性或者贬义)和主观性这两个属性。
本发明的有益效果如下:通过对评价人的评价文本内容、评价的长度、评价的情感值、餐馆当前的平均星级、评价人的特点等因素的分析,得到各个因素与最后评价人给出的星级之间的关系,从而可以推测出尚未有星级的餐馆可能获得的星级。
附图说明
图1为基于线性回归模型的餐馆星级评价方法的回归建模步骤流程图;
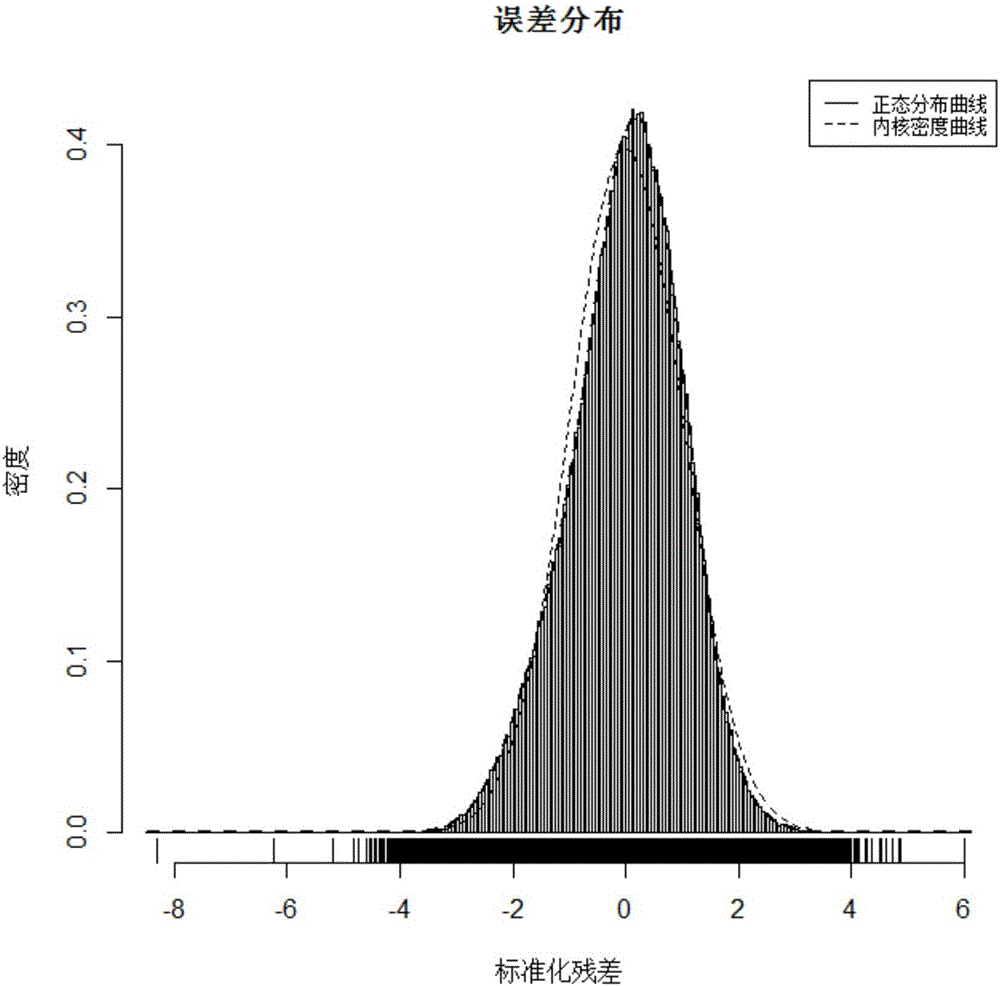
图2为标准化残差直方图;
图3为标准化预测值—标准化残差散点图;
图4为回归标准化残差的正态Q-Q图。
具体实施方式
下面结合附图对本发明做进一步说明。
参照图1~图4,一种基于线性回归模型的餐馆星级评价方法,本专利以研究yelp中的用户和餐馆为例,原始数据记录了各个餐馆的信息、用户的特点以及用户评价文本的信息,相应特征进行餐馆星级的建模分析。
以下实施方式结合附图对本发明进行详细的描述,如图1所示,本发明包括以下步骤:
S1:我们从餐饮网站上抓取数据,并对数据进行分析,最后获得三个相关的数据表,分别是user、business、review这三张表;
S2:在review表中提取相关的用户评论数据,分析评论文本的语义极性和主观性,语义极性包括褒义、中性或者贬义;
S3:在网站提供的特征和语义分析获得的主观性和极性中,同时考虑用户和餐馆对评分预测的影响,选择我们需要的特征变量;
S4:把相关的数据表导入数据库中,用SQL语句获得我们选择的特征变量的数据集,并将数据集分成若干个更小的数据集;
S5:对于获得的数据,进行克伦巴赫系数均衡数据的置信度分析,去除干扰数据,得到可信度较高的数据作为分析的数据样本,选取alpha系数大于0.5(预设阈值为0.5)的数据集,若不存在这样的数据集转移到S3;
S6:构造理论模型,设定各个自变量与因变量之间的关系是线性的,从而建立多元线性回归模型,这里借助工具进行多元线性回归处理得到数据;
S7:对模型进行检验,一个指标是拟合度,拟合度60%(拟合阈值取60%)为拟合程度很高,第二个指标为DW检验,通过T显著性指标大于0.05(指标阈值为0.05),对我们设置的指标进行筛选,获得回归方程,否则如果无法获得我们想要的模型,就转移到S3;
S8:运行模型,进行共线性诊断,主要看VIF方差扩大因子,若VIF小于5(门限值取5)则判断自变量之间不存在共线性,否则我们需要进行主成分分析处理共线性问题,之后分析残差,若残差不满足要求就转移到S3;
S9:若满足上述步骤的要求,则说明该线性回归方程模型满足该数据集,利用得到的线性回归方程,同时结合用户和餐馆信息,可以得出尚未有星级的餐馆的评价星级。
所述步骤S1中,UGC类网站上,用户会通过自身的体验对商户进行评分与评价。而每个用户在评分后会给出评论。每个用户的评论文字的长短,所附加的情感,餐馆当前的星级以及用户自身的特点都影响了用户会给出的评分情况。用户最终给出的评分与其写的评论有直接的关系,所以通过分析其评论的各个特点可以一定程度上预测评分(或者说星级)。我们从餐饮网站上抓取三张数据表格user、business、review。User表为用户信息,包括用户粉丝数、用户平均星评及用户评价数等信息。Business表为餐馆信息,包括餐馆评价数、餐馆星级等信息。Review表为评论信息,包括评论cool、评论funny、评论useful、评论星评及评价文本等信息;
所述步骤S2中,用户在评论中会使用一些描述情感的形容词,表现情感强度的副词、标点符号,通过抓取这一系列的关键词汇可以数值化评论中所包含的情感值。因为用回归法时,需要数值型数据,需要将标称型数据转成二值型数据,因此我们把用户评价做了一个分析。在review表中提取相关的用户评论数据,使用语义分析,获得评论文本的语义极性(褒义、中性或者贬义)和主观性;
所述步骤S3中,同时考虑用户自身体验的指标和商户已经存在的客观指标,以及我们语义分析得到特征,选定影响餐馆评分的13个重要特征:评论cool、评论funny、评论useful、极性、主观性、评论字母数、评论不重单词数、餐馆评价数、餐馆星级、评论星评、用户粉丝、用户平均星级、用户评价数;
所述步骤S4中,把user、business、review中的数据导入数据库中,之后用SQL语句获得我们想要的13个指标的一张汇总表。然后把汇总表导出,并随机分成20份;
所述步骤S5中,对20张表格中已提取的评价长度和评价情感值进行可靠性分析,这里我们借助克伦巴赫信度系数来衡量数据的置信度。克伦巴赫信度系数公式为:
同时结合F检验,对数据进行筛选,去除干扰数据,避免大量数据处理对模型造成的困难,得到可信度较高的数据作为分析的数据样本,当alpha系数大于0.5,该数据集可靠,进入下一步。否则,转到S3;
所述步骤S6中,模型建立,我们这个评分模型把星级作为因变量,评论cool、评论funny、评论useful、极性、主观性、评论字母数、评论不重单词数、餐馆评价数、餐馆星级、用户粉丝、用户平均星级、用户评价数作为自变量。我们借助一般的多元线性回归模型:
y=β0+β1x1+β2x2+...+βpxp+ε,
其中y为因变量,β0是P个可以精确测量并可控制的自变量。因变量y由两部分决定:一部分是误差项随机变量ε,另一部分是P个自变量的线性函数β0+β1x1+β2x2+...+βpxp,其中β0,β1,β2...,βp是P+1个未知参数,β0称为回归常数,β1,β2,...,βp称为偏回归系数,他们决定了因变量y与自变量x1,x2,…,xp的线性关系的具体形式。ε是随机变量;
所述步骤S7中,对模型进行多元线性回归处理,调整后的R平方相比较于R平方,更能反映数据的拟合程度,一般60%为拟合程度很高。利用DW来判断正负相关,DW公式为:
DW小于2代表正相关,大于2代表负相关,DW统计量约等于2时表明数据不存在序列相关,即不存在伪回归。利用T的显著性,大于0.05的自变量认为对模型没有显著性影响,其他自变量对模型有显著性影响。对于系数过小的自变量也不进行考虑,得到回归方程。之后可以对数据进行可视化,能够更直观地看出模型的合适程度。例如图2所示的标准化残差直方图,残差具有正态分布的趋势,说明该回归模型是合理恰当的。如图3所示的标准化预测值—标准化残差散点图,残差的分布不是散乱的分布,说明存在一定的可优化性。如图4所示的正态Q-Q图,拟合曲线与实际曲线较为相近,说明拟合度较高;
所述步骤S8中,运行模型,进行共线性诊断,主要看VIF方差扩大因子,若VIF小于5则判断自变量之间不存在共线性,如果两个变量之间存在很强的共线性,则可以将两个变量整合成一个,因为两个自变量反映的是同一内容,共线性强将会影响矩阵的运算。若VIF大于5则模型存在共线性,需要共线性优化。检测多重共线性的最简单方法是计算模型各自变量之间的相关系数,并对各相关系数进行显著性检验。这里我们利用主成分分析处理共线性问题。主成分分析是将共线性强的指标聚合成一个指标,降维并进行因子分析。一般选取特征值大于1的作为一个主成分,按照60%以上就可以成为一个主成分的要求,只选择一个主成分即可。再次进行多元线性回归并分析相应指标。之后分析残差,若残差不满足要求就转移到步骤S3,重新整理数据;
所述步骤S9中,若满足上述步骤的要求,则说明该线性回归方程模型满足该数据集。利用得到的线性回归方程,同时结合用户和餐馆信息,可以得出尚未有星级的餐馆的评价星级。
如上所述为本发明在yelp餐饮平台的基于多元线性回归模型的餐馆评分预测方法的实施例介绍,本发明选择餐饮网站提供的特征和语义分析获得的主观性和极性,采用多元线性回归模型,最终的预测结果较高,达到了实际使用的要求。对发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!